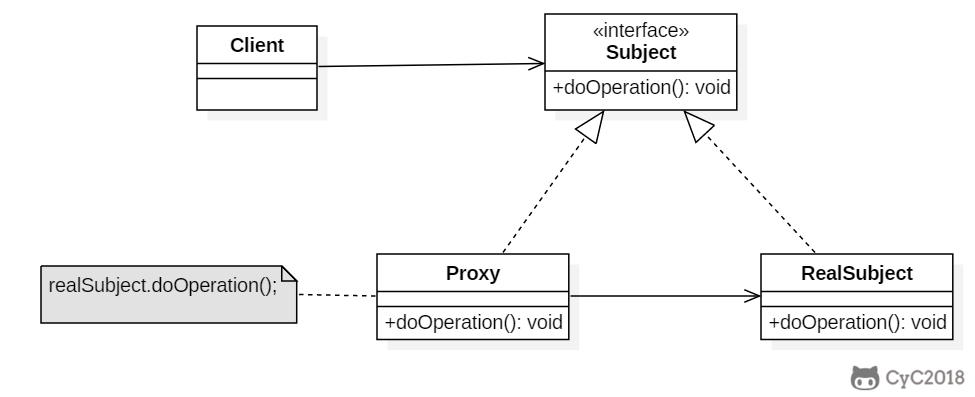
Comment: accepted by CVPR2023
基于知识引导上下文优化的视觉语言提示学习
摘要
提示调优是利用任务相关的可学习标记将预训练的视觉语言模型(VLM)适应下游任务的有效方法。基于CoOp的代表性的工作将可学习的文本token与类别token相结合,来获得特定的文本知识。然而,这些特定的文本知识对不可见类别的泛化性较差,因为它忘记了具有强泛化能力的通用知识。
为了解决这个问题,本文引入了KgCoOp(Knowledge-guided Context Optimization)来增强可学习提示对不可见类别的泛化性。KgCoOp的关键是通过减少可学习提示与手工提示之间的差异来缓解对通用知识的遗忘。特别地,KgCoOp最小化可学习提示和手工提示生成的文本嵌入之间的差异。最后,在对比损失的基础上加入KgCoOp,对可见任务和不可见任务做出区分性提示。通过对多个基准测试程序的评估表明,本文提出KgCoOp是一种有效的快速调优方法,即以更少的训练时间获得更好的性能。
Introduction
在大规模图像文本对上训练的视觉语言模型(VLM )包含了通用知识,对其他任务具有较好的泛化能力。近年提出了许多视觉语言模型,如CLIP ),Flamingo,ALIGN 等。虽然VLM是提取视觉和文本特征的有效模型,但训练VLM需要大规模的高质量数据集。但是在真实的视觉语言任务中收集大量数据用于训练模型是困难的。为了解决上述问题,提示调优已经被提出,以使预训练的VLM适应下游任务,取得了惊人的效果。
提示调优通常使用任务相关的文本标记来嵌入任务特定的文本知识进行预测。使用CLIP 中手工制作的模板" a photo of a [ Class ] "对基于文本的类嵌入进行建模,进行零样本预测。将固定提示(手工提示)捕获的知识定义为通用的文本知识,对不可见任务具有较高的泛化能力。然而,由于没有考虑每个任务的具体知识,通用的文本知识对下游任务的描述能力较低。为了获得具有判别性的特定任务知识,CoOp,CoCoOp和ProGrad 用一组可学习提示来代替手工设计的提示。由可学习提示生成的判别性知识被定义为特定文本知识。然而,基于CoOp的方法对具有相同任务的不可见类别的泛化性较差,例如,在未见类上获得了比CLIP更差的性能,如表1所示。

由于特定的文本知识是从带有标签的少样本中推断出来的,因此它对可见的类别具有判别性,而对不可见的类别具有偏向性,导致在不可见领域上的性能更差。CLIP在不可见类上获得了比基于CoOp的方法更高的准确率,如CLIP / CoOp / CoCoOp分别为74.22% / 67.99% / 71.69%。CLIP在不可见类上的优越性能验证了其通用文本知识对不可见类具有更好的泛化性。然而,基于CoOp的方法所推断的特定文本知识遗忘了一般性文本知识,称之为灾难性知识遗忘,即灾难性遗忘越严重,性能下降越大。
为了解决这个问题,本文引入了一种新颖的提示调优方法KgCoOp,通过减少对一般文本知识的遗忘来提高对未见类的泛化性。KgCoOp的重点是减少可学习提示和手工提示之间的差异,来缓解对一般文本知识的遗忘。两种提示的差异与性能之间关系也验证了这一观点。解释图1:可学习提示和手工提示生成的文本嵌入之间的距离越大,性能下降越严重。将手工提示" a [ Class ]的照片"被输入到CLIP的文本编码器,以生成通用的文本嵌入,即通用的文本知识。并且优化一组可学习的提示来生成任务特定的文本嵌入。此外,KgCoOp最小化通用文本嵌入和特定文本嵌入之间的欧氏距离,用于记忆必要的通用文本知识。与CoOp和CoCoOp类似,使用任务特定的文本嵌入和视觉嵌入之间的对比损失来优化可学习提示。

本文在11个图像分类数据集和ImageNet4种类型上进行了从基类到新类的泛化设置、少样本分类和领域泛化的全面实验。评估表明,本文提出的KgCoOp是一种有效的方法:使用更少的训练时间获得更高的性能,如表1所示。
解释表1:综上所述,本文提出的KgCoOp获得:1 )更高的性能:KgCoOp获得了比现有方法更高的最终性能。特别地,KgCoOp在New class上对CoOp、CoCoOp和ProGrad有明显的改进,证明了考虑一般文本知识的合理性和必要性。2 )训练时间少:KgCoOp的训练时间与CoOp相同,快于CoCoOp和ProGrad。
Method
Preliminaries
在现有的视觉语言模型中,对比语言-图像预训练模型( CLIP )是具有4亿图像-文本关联对训练的代表性模型,对零样本图像识别具有强大的泛化能力。由于CLIP基于图像-文本对进行训练,因此它包含两种编码器:视觉编码器和文本编码器,其中视觉编码器用于将给定的图像映射为视觉嵌入,文本编码器用于嵌入相应的文本信息。通过冻结CLIP中预训练的视觉和文本编码器,提示调优使用手工提示或可学习的提示,使预训练的CLIP适应下游任务。
φ代表视觉编码器,θ代表文本编码器。
CLIP:
(1)对于包含Nc个类别的下游任务,CLIP使用手工设计的提示来生成文本类别嵌入。![]() 代表所有类别的文本嵌入,其中Wi表示第i个类别的文本嵌入。第i个类别的提示“A photo of [class name]”,文本编码器θ和基于transformer的编码器e(),e()以单词序列作为输入,输出文本向量表示,即单词嵌入。因此,第i个类模板“A photo of [classname]”的文本嵌入定义为
代表所有类别的文本嵌入,其中Wi表示第i个类别的文本嵌入。第i个类别的提示“A photo of [class name]”,文本编码器θ和基于transformer的编码器e(),e()以单词序列作为输入,输出文本向量表示,即单词嵌入。因此,第i个类模板“A photo of [classname]”的文本嵌入定义为
![]()
![]() 。
。
![]() 通过文本编码器θ进一步投影到文本类别嵌入
通过文本编码器θ进一步投影到文本类别嵌入![]()
(2)给定一个图像I和相应的类标签y,通过视觉编码器提取器视觉嵌入:φ(·): x = φ(I)。
(3)然后计算图像嵌入x和文本嵌入之间的预测概率:
![]()
CoOp:
尽管Eq1很容易地应用于zero-shot预测,但是使用固定的人工提示来生成文本嵌入,导致在下游任务种泛化性差。为了解决这个问题,CoOp提出学习一组连续的上下文向量,用于生成与任务相关的文本嵌入。具体来说,CoOp就是引入M个上下文向量V = {v1, v2, ..., vM }作为可学习的提示。最后,将第i个类别对应的类嵌入ci与可学习的上下文向量V进行串联,生成提示:
![]()
然后将可学习提示送到文本编码器θ得到文本嵌入:

![]()
因此,所有类别的最终文本嵌入为:
![]()
在给定的少样本条件下,CoOp通过最小化图像特征x与其类别文本嵌入之间的负对数似然来优化可学习的上下文标记:

在CLIP和CoOp的训练过程中,视觉编码器φ和预训练的文本编码器θ被冻结。与CLIP使用固定提示不同,CoOp只推断合适的任务相关提示以提高其通用和辨别力。
Knowledge-guided Context Optimization

尽管现有基于CoOp的提示调优方法可以有效地将预训练的CLIP适配到下游任务中,但由于只使用了少量带标签的图像进行训练,因此很容易过拟合所见类别。例如,在基类预测中,CoOp比CLIP获得了显著提升,如69.34 % ( CLIP ) vs 82.89 % ( Co Op )。然而,在未见类上,CoOp获得了比CLIP更差的新类准确率,例如,74.22 % ( CLIP ) vs 63.22 % ( CoOp )。通过在11个数据集上进一步分析CLIP和CoOp的新类准确率,一个有趣的现象是,在不可见类上的性能下降与可学习提示和固定提示之间的距离一致。在本文中,CLIP和CoOp之间性能下降的相对比率表示性能下降的程度。此外,使用可学习提示( CoOp )和固定提示( CLIP )之间的距离来衡量两类提示之间的相似性。如图1所示,距离越大,性能下降越严重。例如,在所有11个数据集中,CoOp在DTD数据集上获得了20.63 %的最大降幅,而其特殊的类嵌入与CLIP相比也具有最大的距离。基于以上结果得出结论,增强可学习提示和固定提示之间的相似性可以缓解对一般文本知识的遗忘,从而提高不可见域的通用,这也是本文工作的核心动机。本文提出KgCoOp提示调优方法,使其在可见类别上具有较高的判别性,在不可见类别上具有较高的泛化性。
对于CLIP,给定一张图像和它相应的文本,通过计算视觉嵌入和文本嵌入之间的相似度来得到预测结果。由于CLIP和KgCoOp使用不同的文本嵌入来匹配视觉嵌入,因此通用文本知识和特定文本知识主要是由CLIP和KgCoOp中的文本嵌入来控制。此外,通用文本知识和特定文本知识之间的差异可以通过相应文本嵌入之间的距离来衡量。
本文将CLIP中的文本嵌入定义为:![]()
将KgCoOp中的文本嵌入定义为:![]()
其中![]() 表示CLIP中向量化的文本嵌入,
表示CLIP中向量化的文本嵌入,![]() 代表第i个类别的可学习提示。
代表第i个类别的可学习提示。
特定文本知识和通用知识之间的差别在于计算Wi和Wi(CLIP)之间的欧距离,距离与性能退化正相关,距离越小,性能退化越低。
因此本文提出最小化Wi和Wi(CLIP)之间的欧式距离来提高对未见类别的通用性:

其中||·||表示欧式距离,Nc表示可见类别的个数。
此外,标准的对比损失(其中y代表图像嵌入的标签)为:

最终目标损失为:
![]()
Conclusion
为了克服现有基于CoOp的提示调优方法在未见类泛化性差的缺点,本文引入一种提示调优方法KgCoOp,通过最小化一般文本嵌入和可学习的特定文本嵌入之间的差异来提升未见类的通用性。在多个基准测试的广泛评估表明,本文提出的KgCoOp是一种高效的提示调优方法。虽然使用KgCoOp可以提高未见类上的通用性,但是会降低已见类上的判别能力,例如KgCoOp在Base类性能较差。