一、事情起因
一般来说数据库与缓存一致性的方案大致有以下几种:

其中Cache-Aside Pattern,也被称为旁路缓存模式应该是使用的比较广泛
Cache-Aside Pattern,也被称为旁路缓存模式,是一种常见的缓存设计模式,其中缓存的管理由应用程序显式处理。在这种模式下,应用程序负责决定何时读取、写入和使缓存失效,而不是由缓存系统自动处理。
以下是 Cache-Aside 模式的基本工作流程:
读取数据: 当应用程序需要从数据库中获取数据时,它首先检查缓存是否已有。
未命中缓存: 如果缓存中没有,应用程序从数据库中读取数据,并将其放入缓存。
写入数据: 当应用程序对数据进行写入操作时,它首先更新数据库,然后删除缓存。
此方案与大多数据方案有个共同点,就是删除缓存而不是更新缓存。
二、产生问题

在缓存与数据库(DB)同步的过程中,通常会先更新数据库再删除缓存,而不是直接更新缓存?
主要有以下几个原因:
- 数据一致性: 直接更新缓存可能导致缓存与数据库之间的数据不一致。如果在更新缓存的同时有其他请求正在读取或修改数据库,就可能出现数据不一致的情况。删除缓存后,下一次读取会从数据库中获取最新数据,从而保证数据的一致性。
- 简化操作: 更新缓存需要处理缓存中的数据结构,这可能比简单地删除缓存更复杂。删除缓存后,可以避免复杂的同步逻辑,简化系统的维护。
- 避免竞态条件: 在高并发的系统中,多个进程或线程可能同时操作缓存和数据库。如果直接更新缓存,可能会出现竞态条件,导致数据不一致。删除缓存可以减少这种风险。
- 性能考虑: 有时候,直接从数据库中重新加载数据到缓存可能比更新缓存更高效,尤其是当缓存数据结构复杂或者缓存更新操作成本较高时。
三、剖析问题
让我们深入探讨一下为什么说"删除缓存比更新缓存操作更简单"
1、操作复杂度
- 删除操作通常只需要一个简单的命令,如 Redis 的 DEL 命令。
- 更新操作可能涉及多个字段的修改,需要处理部分更新的情况。
一般来说我们存储在缓存中的数据以json为主,大多数json还是以string类型存储在redis中。
可以看到String类型时更新与删除时间复杂度都是O(1)一样的
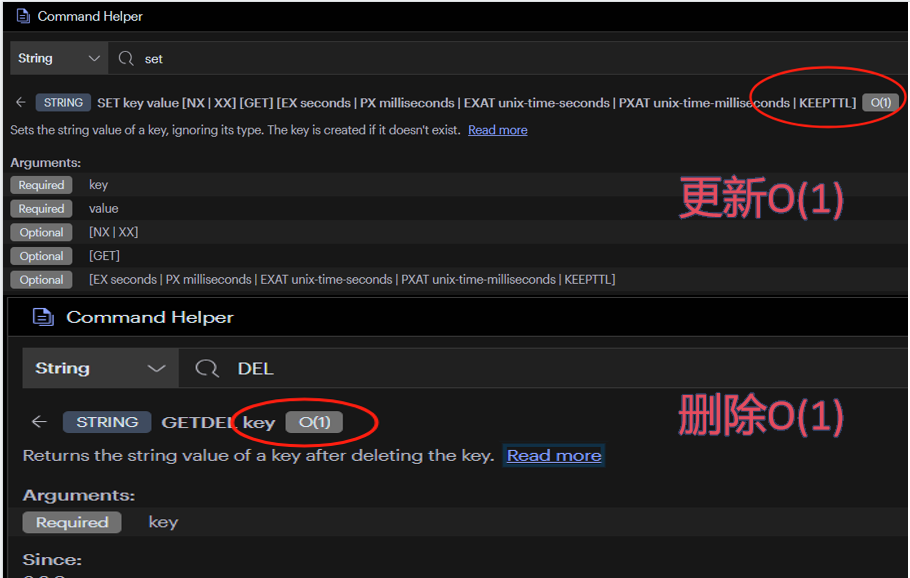
当然现在redis也已经支持json类型了,json类型时,set要复杂一点是O(M+N),del是O(N)

json set复杂度:
当路径(path)被评估为单个值时,复杂度为 O(M+N),其中 M 是原始值的大小(如果存在),N 是新值的大小。
当路径被评估为多个值时,复杂度也是 O(M+N),其中 M 是键的大小,N 是新值的大小乘以键中原始值的数量。
2、避免并发更新
在高并发环境中,更新缓存可能会引入并发问题,例如多个线程同时更新缓存时可能导致不一致的状态。而删除缓存则可以简单有效地避免并发与顺序性的问题,把原本复杂的问题简单化、异步化,拆解了并发的问题,让所有请求能重新获取最新数据,避免这类问题的发生。
删除缓存可以确保下次请求会获取到最新的数据,尤其是在数据更新频繁、对数据实时性要求高的场景下,这种策略能够保证数据的一致性。

3、简单直接
"简单"在这里不仅指操作命令本身的简单(del key/set key value ),还包括整个系统在处理缓存时的简单性和可靠性。
当然在命令本身方面整个缓存的删除还是要加上增加缓存的命令才完整。
当更新缓存后就有查询请求时:
删除缓存=del+set
更新缓存=set当更新缓存后无查询请求时:
删除缓存=del
更新缓存=set当有多更新缓存操作后,并无查询请求时:
删除缓存=del+del+del
更新缓存=set+set+set+(并发与顺序控制)相对并发与顺序的控制而言,删除缓存是一种直接有效的方式,确保下次请求时,服务器会从新的数据源获取最新的数据,而不会受到旧缓存的影响。相比之下,更新缓存可能涉及到更复杂的逻辑,如判断何时进行更新、如何保证并发请求下的一致性,如是否需要加锁等限制。
我是栈江湖,如果你喜欢此文章,不要忘记关注+点赞哦!你的支持是我创作的动力。如果你有任何意见或建议,欢迎在下方留言。若转载,请注明文章来源。