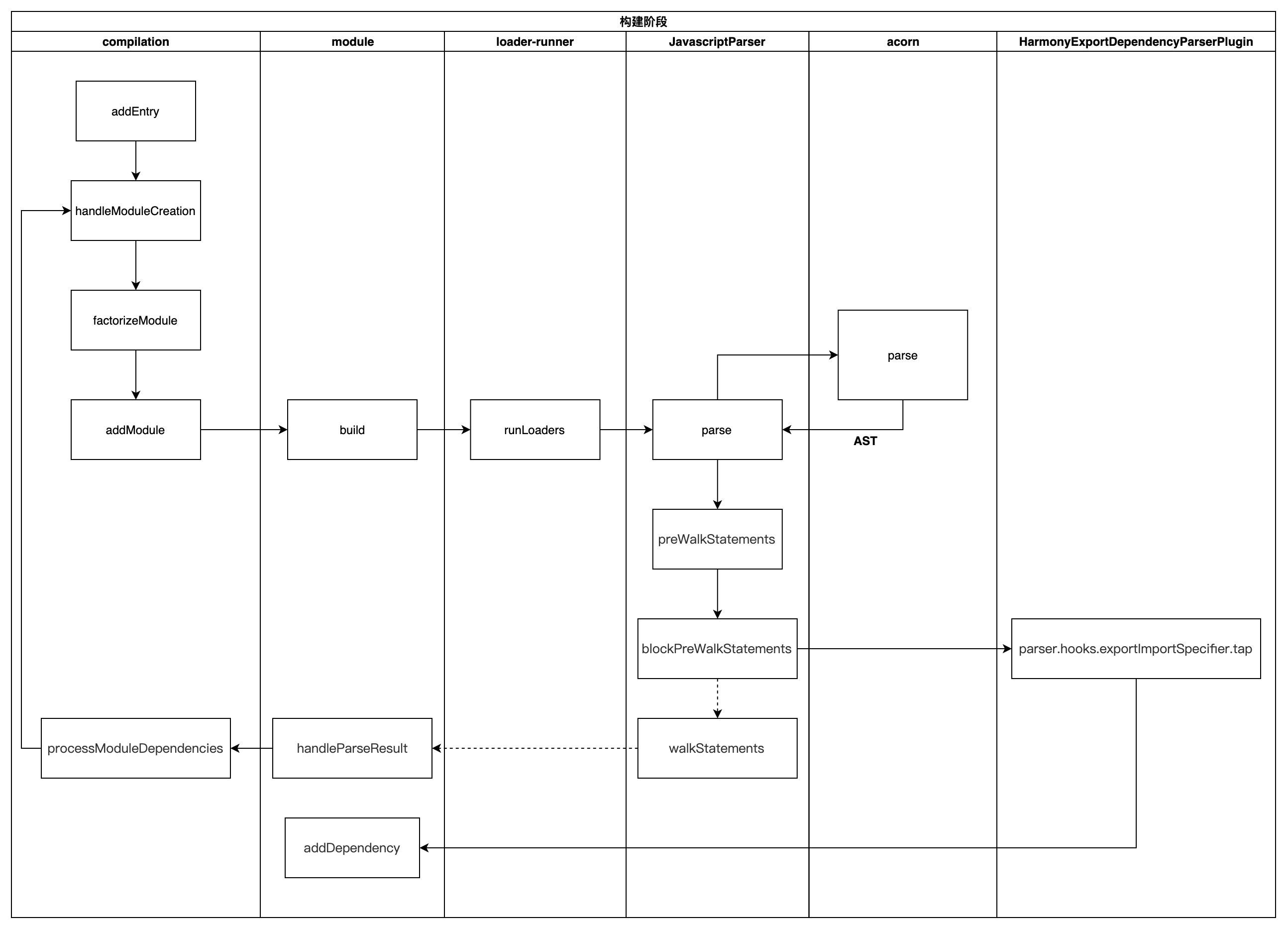
- 本文译自 《In-Context Learning Creates Task Vectors》 —— 论文中的作者也在用LLaMA模型,笔者自我感觉拉近和世界顶级人才的距离,哈哈
- 内容较长,如想看结论直接看 摘要、介绍与结论几个章节即可,看细节请看目录索引。
- 经验风险最小化 (Empirical Risk Minimization ERM): 这也是理论…
摘要
在大语言模型(LLMs)中的上下文学习(In-Context Learning,ICL) 成为一种强大的新学习范式(learning paradigm),然而我们对它的底层机制仍不够明确清晰。尤其是将其映射到传统的机器学习框架 就很具挑战性,其中我们使用 训练集S 在特定的假设类别中去寻找一个最佳拟合 函数f(x) 。我们发现,ICL可以学习到的函数通常具有非常简单的结构:他们直接表现近似于Transformer架构的LLMs,仅有的输入是 查询x 和 由训练集计算而得的单个’任务向量(task vector)', 因此 ICL可以看成是将 训练集S 压缩成一个单个任务向量(task vector) θ(S),然后利用该任务向量来调控Transformer以生成输出。为了验证上述观点,我们进行了一系列的综合实验,涵盖各种模型和任务。
原始信息
- 论文:In-Context Learning Creates Task Vectors
- 作者:Roee Hendel(Tel Aviv University), Mor Geva(Google DeepMind), Amir Globerson(Tel Aviv University, Google)
- 地址:arxiv.org/pdf/2310.15…
介绍
什么是In Context Learning (ICL)
近年为大模型飞速发展,它的显著特点是可以从少量的示例集合(demonstrations)中就学到新规则。例如,我们向模型输入苹果->红色, 青柠->绿色 , 玉米 -> 就得到玉米对应的黄色输出。
上述过程至少涉及LLM的’ICL’与’Promot’的两大主题。 好像整篇就上述这段话有用,其他用途不大的感觉啊,太理论了,可花了时间不啥得删啊。
上述例子中模型仅基于两个例子就可学会了目标映射关系,这种能力我们称之为上下文学习 InContext Learning (ICL)。 ICL已经被广泛应用且效果显著。ICL如此神奇,人们开始探寻ICL背后潜在的机制,即模式内部是实现通过 示例集S 和查询 x 来生成所需要的输出?

Figure 1: ICL as learning in a Hypothesis Class(是ICL在假设类中的学习过程)
我们通过使用上图所示方法来处理该问题。在ICL中,我们给LLM一个含有特定任务的示例集S 提示(prompt) 和一个查询x,这个模型为 查询x 产生了输出, 如该示例中的输出’Yellow’。我们发现其内部的处理过程可以分解为两个部分(如上图所示): 第一部分是学习算法(learning algorithm) ‘, 用于计算 未知查询向量θ(S)θ(S),该学习算法我们称之为 在假设类中函数参数,上图中的蓝色部分。第二部分是由θ定义的规则在查询x上的应用,我们用ff表示,该规则不直接依赖于 示例集’S’, 如上图所示的黄色区域。
ICL的预测函数
ICL的预测函数是T([S,x])T([S,x]) , 其中T是自回归的语言模型(auto-regressive transformer), S表示用作ICL输入的训练示例集,x是查询参数, ICL根据输入x得到最终输出。而[S, x]表示为ICL对x和S串联后的输出。因此,在一般情况下,该预测函数可以是对S和x进行运算以产生输出的任意函数,这包括"非参数(non-parametric)"方法,诸如 最近邻法(nearest-neighbor)。
ICL解决了什么问题
来自统计学习理论的假定类概念。 在学习理论的表示中,通常我们将假定类看成H,H的每个元素都是函数H(x;θ)H(x;θ), 表示为对输入x进行参数为向量θ 运算。 例如,如果x∈Rdx∈R**d ,那么假定类H 就是线性分类器(linear classifier)的集合, h(x;θ)=θ⋅xh(x;θ)=θ⋅x, θ为系数向量,输入为输入。学习算法在探索一个元素h, 且 h∈Hh∈H,该h可以更好的适应训练集,也就是所所谓的 经验风险最小化(Empirical Risk Minimization ERM)。
ICL是否以这种方式执执目前并不十分清楚,最近已有机构正在探寻该问题。
例如:我们从头开始训练一个语言模型(Transformer)并在上下文中以线性回归方法执行, 这种新兴的学习方法类似于梯度下降法(Stochastic Gradient Descent SGD)。 然而对于要执行更多复杂任务的自然语言任务的LLMs来说,其假设空间可能是什么还不是特别明确。
在本论文中,我们证实了,在许多任务中,LLM的ICL都可以工作在假设空间中。给定一个训练集S,模型将其映射为任务向量θ(S),该向量表示为训练集S中映射/规则的描述。即给定模型T和一个向量θ,我们可以构造出一个用于完成指定任务的新函数f(x;θ)*f*(*x*;*θ*)。该函数f近似于原始模型,直接应用于输入x,无需示例集合直接由θ*θ*激活, 如下图。

- Figure 2: Separating A and f. (分离A和f)
- 该图在文章的讲到具体章节时还贴了一张, 主要是为了查看方便,在此多贴一张
我们的观点也与软提示有关,因为这两种方法都会针对特定任务调整转换器的功能。然而,在ICL中,任务向量是在前向传播中计算的,而不是经过微调。
论文贡献
我们的贡献包括:
- 我们提出一种基于假设类的ICL机制, 并利用公开可用的大模型进行了一系列的不同任务试验以此来验证我们观点可靠性
- 我们的研究进一步加深了对ICL的理解,可能对LLM执行特定任务的具有实际意义。
ICL框架
ICL的假设空间观点 - A Hypothesis Class View of ICL
受学习理论的假设类观点的启动, 我们的主要目标是理解ICl是否将一个示例集S映射到一个关于输入x(Query x)的函数及该映射是如何产生的。我们特别探寻了ICL是否将 示例集S 转化为 一个θ —— 某个特定假设空间内函数的"参数"。实验结果的确证明了 ICL是运行在假设空间上的。
理论框架 - Theoretical Framework
我们用T表示decoder-only transformer(仅解码器的模型)大语言模型(LLM), S表示作用于ICl输入的一组示例集(如训练样本) , x表示为要求ICl提供输入的查询值。 我们使用T([S,x])T([S,x])表示ICl在S和x串联后的输出。
为了证实ICL是在一个假设空间内执行,我们将其内部机制两个不可或缺的部分:
- 第一部分: “学习算法(learning algorithm,)",用A表示,该算法不依赖于查询x, 用于将示例集S映射到任务向量θ。因为注意力层可以访问到S和x,不依赖查询x的独立性并不明显(后来会讲到解决办法)。
- 第二部分:规则应用(Rule Application),用f表示, 基于θ≡A(S)θ≡A(S),主要用于将将查询x映射为输出。该规则同样独立于示例集S。同样独立性有待提高(后来会讲到解决办法)。
我们将 示例集S+查询x 至 预测输出 的整体映射关系定义为公式: T[S;x]=F[x;A(S)]T[S;x]=F[x;A(S)]
如果我们可以将LLM的前向传播分按上述分为两个部分,我们可以将ICL看成在H=f(⋅;θ)∣θH=f(⋅;θ)∣θ的假设类中执行。
假设类 - A Proposed Hypothesis Class
如上图(Figure 2)所示框架,根据A和f的不同选择,假设类会有许多可能的实现。我们将描述重点在以Transfomer框架为基础的实现上。
首先我们以(Figure 1)所示的方式来设置ICL, 其中输入一个x(i.e., Corn)外加一个 → 符号。 学习过程我们分为两个部分:
- 基于训练集S的参数向量x,并将由该参数向量定义规则应用于查询x。
- 前L层计算得到的 A 和 → 符号负责更新参数向量 θ ,然后用参数向量 θ 和查询x作为剩下的层的输入并产生输出。上上图(Figure 1).
解决示例集S和查询x 在transformer中的任务层都可见的问题.

Figure 2: Separating A and f. (分离A和f)
Figure 2展示了分离的A和f的图示。为了让θ独立于查询x, 我们引入了一个虚拟变量 x‘x‘ (i.e. x’Plumx’Plum) 以及 使用L层的→符号来表示向量θ,以防止f直接依赖于S。下面章节将详细描述
A和f的隔离 - Separating A and f
在常规的前向传播过程中,我们面对的挑战是:
- 对应于A的初始L层, 更新→符号去创建参数向量θ以及处理Query x。该过程有可能存在对x的依赖,以至于会让θ对x也有了不必要的依赖。
- 对应于f的剩余层, 因为可直接访问示例集S,因此在计算中存在不仅使用了x和θ的情况。
为解决上述问题,我们采用了如下措施
- 针对第1个问题,我们引入了 “dummy query(虚拟查询)” x’x’ ,并使用x’x’来计算→符号。在第一个L层之后我们使用由x′计算的→符号来表示向量θ(如Figure 2的左侧部分)。
- 针对第2个问题,为了解决 计算f(x,θ)f(x,θ)时不依赖S的情况,我们 仅在x 和 → 上执行transformer的前向传播,并且“修补(patch)” 参数向量θ。(如Figure 2的右侧部分)。

任务与模型 - Tasks and Models
任务:我们一共准备了18项目任务,这些任务一共分为4类:算法、翻译、语言和知识。 为了简单起来,我们限制其为单个token输出。 上表1展示了这些任务中有代表性的任务情况。
更多的试验数据见论文原文
模型:我们使用了多个大语言模型: LLaMA 7B, 13B, and 30B(Touvron et al., 2023), GPT-J 6B (Wang and Komatsuzaki, 2021), and Pythia a 2.8B, 6.9B, and 12B (Biderman et al., 2023)。
探寻L层 - Finding L
在第二章节我们在描述其内部机制时,提到了一个自由参数 —— L层,该层作为A的结束与f的开始。我们使用用(A,f)(A,f)实现对L的不同选择,并通过评估以找到最佳层数。

更多的显示见论文原文。
图3展示了不同参数的LLaMA模型上,针对L层的不同选择其开发集的准确度。有趣的是,所有的模型在相似的中间层都展示了一个相似的性能峰值,无关模型的参数与层数的多少。
基于假设的预测的准确度 - Accuracy of Hypothesis Based Prediction
接下来,我们将执行ICl的常规的前向传播与 (A, f) 机制的精确度做了比较。模型与任务我们都分别经历了以下三个过程:
- Regular: LLM在示例集S和查询x的常规应用, 即T([S,x])T([S,x]) 在常规的ICL的
- Hypothesis:我们根据A和f的机制编写了一套程序,实现了A通过使用虚拟x′(dummy x′)生成 θ认
- Baseline: LLM仅仅在查询x上进行前向传播,而不需要依赖于 示例集S。 即T([x,→])T([x,→])。 这与我们分离过程中f的应用相同,但并没有修补θ。

上图显示了每个模型在这3个过程中所有任务的平均精度。完整结果原论文更详细的数据分析及其A.2-表6数据。一切结果表示,我们提出 对A和f的分离为ICL提供了更好的执行过程。
任务向量的鲁棒性 - Robustness of Task Vectors
在我们的设置场景下,θ是来自于 示例集S 和 虚拟x’(dummy query x′)。 检查θ对输入变量的鲁棒性(稳定性)是一个必要事情。正常情况下,如果他表示任务,他应该在不同的S与x′值间保持稳定。为了做上述鲁棒性的测试,我们使用了LLaMA 7B的模型为每一个任务生成50个不同的S和x′的任务向量, 并且进行了如下分析。
Geometry of θ
Figure 5是一个任务向量的t-SNE图, A t-SNE降维图 展示了任务向量形成不同的簇,每个簇包含单个任务的任务向量。论文中的图9将进一步显示了相同类别的任务间的接近性。

Variability of θ 下图是一个展示任务内部及任务间的距离的直方图。 可以看出同一个任务内与不同任务间的距离更靠近一些。这表明θ在任务中是稳定的,不受x′或S的高度影响。

θ补丁的优势 - Dominance of θ Patching

在第三章节,我们讨论了阻止f直接访问S示例集。然后,在ICL期间一个常规的前向传播过程,最后一个token是可以关注到S的。 这里我们验证了这种情况的存在, f主要使用任务向量θ且不直接访问示例集S。 最后我们使用了一对名为A和B的任务,他们共享了输入空间但有不同的输出。我们首先使用了“Regular"的前向传播, 其中我们为模型提供了任务A的示例集S(我们把它表示为SA), 以验证模型可以使用ICl执行该任务。然后我们又进行了"Conflicting"的前向传播, 仍然是SA作为模型任务的数据集, 同时注入θ。
For more details, refer to Fig. 6 in §A.1.

上表2, 这个"Regular"的前向传播中在任务A中表现了很高的精度,然而这个“Conflicting”的前向传播产在任务B中产生了高精度,该任务对应于注入了向量θ。这意味道着这个任务主要依赖于θ,而忽略了为任务A的示例集S。 我们注意到任务B的准确度较低,可能与图6(Figure 6)的性能下降有关,可能进一步受到S存在的影响。

对θ的解析 - Interpreting θ
学习到了向量θ直接观地捉了关于示例集S所展示的任务信息。这里我们提供了支持这一解析的证明数据。由于向量θ是transformer的中间隐藏状态,我们可以使用词汇投影法(vocabulary projection method,nostalgebraist,2020;Dar et al. ,2022) 。即,我们检查由隐藏状态引起的分布在词汇表上的顶层token。
下表展示了 LLsMA 13B下三个任务的顶层token.

更多的请看 论文附 A 中的表7.
在多种情况下,我们观察到能直接描述任务的token。而更重要的是,这些术语从未明确出现在上下文中。例如,在从法译英的任务中,我们观察到诸如“英语”和“翻译”之类的token。这支持了我们的观点,即θ携带了关于任务的重要、非琐碎的语义信息(θ carries significant, non-trivial semantic information about the task)。
结论 Conclusions
本文通过对LLM中ICl的探索,我们为ICL学习机制的供了新的视角。 我们展示了一个简单而优雅的结构:ICL通过将一个给定的训练集压缩为一个单任务向量来发挥作用,用来指导transformer根据给定的查询x去成最优输出。我们的工作为LLM如何执行ICL过程提供了理论阐述,由此我们预测,未来的工作可能会侧重在任务向量如何构建以及如何使用他来评估输出上。
术语中英对照
- 线性分类器(linear classifier): 通过线性映射,将数据分到对应的类别中。f(xi,W,b)=W∗xi+bf(x**i,W,b)=W∗x**i+b, W为权值(weights),b为偏移值(bias vector),x_i为数据。
- 经验风险最小化(Empirical Risk Minimization ERM): 是统计学习理论中的一个原则,它定义了一系列学习算法,并用于给出其性能的理论界限。
END
如果您也对AI大模型感兴趣想学习却苦于没有方向👀
小编给自己收藏整理好的学习资料分享出来给大家💖
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码关注免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉如何学习AI大模型?👈
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。