【重学 MySQL】二十七、七种 join 连接
- `union` 的使用
- UNION 的基本用法
- 示例
- UNION ALL 的用法
- 七种 `join` 连接
- 代码实现
- 语法格式小结

union 的使用
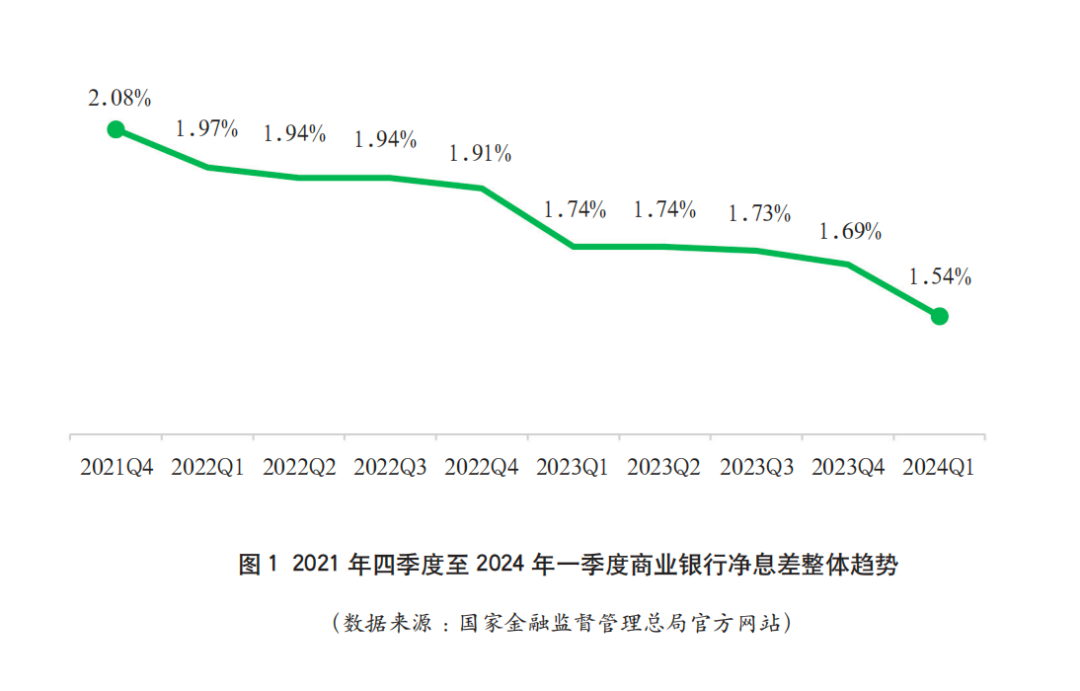
UNION 在 SQL 中用于合并两个或多个 SELECT 语句的结果集,并默认去除重复的行。如果希望包含重复行,可以使用 UNION ALL。
UNION 的基本用法
当你想要将两个或多个 SELECT 语句的结果合并成一个结果集时,可以使用 UNION。每个 SELECT 语句必须拥有相同数量的列,并且对应列的数据类型也需要兼容。
语法:
SELECT column_name(s) FROM table1
UNION
SELECT column_name(s) FROM table2;
- 默认情况下,
UNION会从结果集中删除重复的行。 - 如果要包含所有重复行,请使用
UNION ALL。
示例
假设我们有两个表,employees_usa 和 employees_europe,它们都有 employee_id 和 employee_name 这两列。
employees_usa 表:
| employee_id | employee_name |
|---|---|
| 1 | John Doe |
| 2 | Jane Smith |
employees_europe 表:
| employee_id | employee_name |
|---|---|
| 3 | Peter Brown |
| 2 | Jane Smith |
如果我们想要合并这两个表的结果,但不包含重复的行,我们可以这样做:
SELECT employee_id, employee_name FROM employees_usa
UNION
SELECT employee_id, employee_name FROM employees_europe;
这将返回:
| employee_id | employee_name |
|---|---|
| 1 | John Doe |
| 2 | Jane Smith |
| 3 | Peter Brown |
注意,尽管 Jane Smith 在两个表中都出现,但在结果集中只出现了一次,因为 UNION 默认去除了重复的行。
UNION ALL 的用法
如果你想要包含所有重复的行,可以使用 UNION ALL。
语法:
SELECT column_name(s) FROM table1
UNION ALL
SELECT column_name(s) FROM table2;
使用 UNION ALL 重复上面的例子:
SELECT employee_id, employee_name FROM employees_usa
UNION ALL
SELECT employee_id, employee_name FROM employees_europe;
这将返回:
| employee_id | employee_name |
|---|---|
| 1 | John Doe |
| 2 | Jane Smith |
| 3 | Peter Brown |
| 2 | Jane Smith |
现在,Jane Smith 出现了两次,因为 UNION ALL 保留了所有行,包括重复的行。
七种 join 连接

代码实现
#中图:内连接 A∩B
SELECT employee_id,last_name,department_name
FROM employees e JOIN departments d
ON e.`department_id` = d.`department_id`;
#左上图:左外连接
SELECT employee_id,last_name,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`;
#右上图:右外连接
SELECT employee_id,last_name,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`;
#左中图:A - A∩B
SELECT employee_id,last_name,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL
#右中图:B-A∩B
SELECT employee_id,last_name,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE e.`department_id` IS NULL
#左下图:满外连接
# 左中图 + 右上图 A∪B
SELECT employee_id,last_name,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL
UNION ALL #没有去重操作,效率高
SELECT employee_id,last_name,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`;
#右下图
#左中图 + 右中图 A ∪B- A∩B 或者 (A - A∩B) ∪ (B - A∩B)
SELECT employee_id,last_name,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL
UNION ALL
SELECT employee_id,last_name,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE e.`department_id` IS NULL
语法格式小结
- 左中图
#实现A - A∩B
select 字段列表
from A表 left join B表
on 关联条件
where 从表关联字段 is null and 等其他子句;
- 右中图
#实现B - A∩B
select 字段列表
from A表 right join B表
on 关联条件
where 从表关联字段 is null and 等其他子句;
- 左下图
#实现查询结果是A∪B
#用左外的A,union 右外的B
select 字段列表
from A表 left join B表
on 关联条件
where 等其他子句
union
select 字段列表
from A表 right join B表
on 关联条件
where 等其他子句;
- 右下图
#实现A∪B - A∩B 或 (A - A∩B) ∪ (B - A∩B)
#使用左外的 (A - A∩B) union 右外的(B - A∩B)
select 字段列表
from A表 left join B表
on 关联条件
where 从表关联字段 is null and 等其他子句
union
select 字段列表
from A表 right join B表
on 关联条件
where 从表关联字段 is null and 等其他子句