目录
1、背景和问题
2、高清-低清 数据集构建
3、Real-ESRGAN模型结构
4、源码分析
5、不足与局限性
6、资料
一、背景和问题
图像超分一直是一个活跃的研究课题,旨在从低分辨率(LR)重建高分辨率(HR)图像。在数据集构建方面:之前很多方法都假设了理想的双三次下采样核,但实际情况远比此复杂,当我们用手机拍照时,照片可能有多种退化,如相机模糊、传感器噪声、锐化伪影和 JPEG 压缩,然后我们进行一些编辑并上传分享,这会引入进一步的压缩和不可预测的噪声,当图像在网上多次分享时,上述过程会变得更加复杂。如何对退化过程建模来模拟复杂的真实世界中图像退化的过程是一个问题。另外,许多超分辨率模型在超分放大时会丢失细节纹理或产生过于锐化导致失真的结果也是一个问题。
Real-ESRGAN通过一系列创新性的改进,有效地解决了图像超分辨率领域的多个关键问题。主要的改进包括:
-
更真实的模拟图像退化过程,使模型能更好地处理真实世界的低质量图像。
-
更有效地处理JPEG等压缩算法引入的伪影。
-
提高了纹理保真度,能更好地保留和重建细节。

名词解释
盲超分(Blind Super-Resolution, BSR):在不知道低分辨率(LR)图像降质过程的情况下,对其进行超分辨率处理以恢复高分辨率(HR)图像的技术。
二、高清-低清 数据集构建
2.1 经典的退化模型:
先对输入的高清图像进行blur模糊处理(采用卷积处理),然后进行下采样,再加入噪声,最后使用JPEG进行压缩 产生退化的低清图像
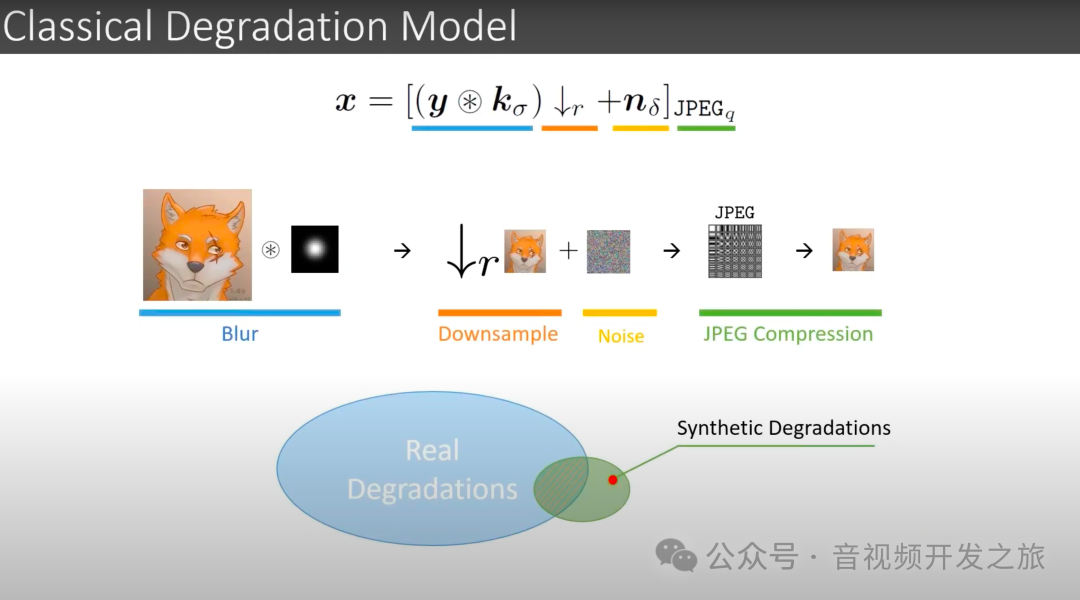
但现实世界中的场景更加复杂:初次生产、二次编辑、端侧压缩、云侧压缩、多次传输压缩等等

2.2 Real-ESRGAN退化模型
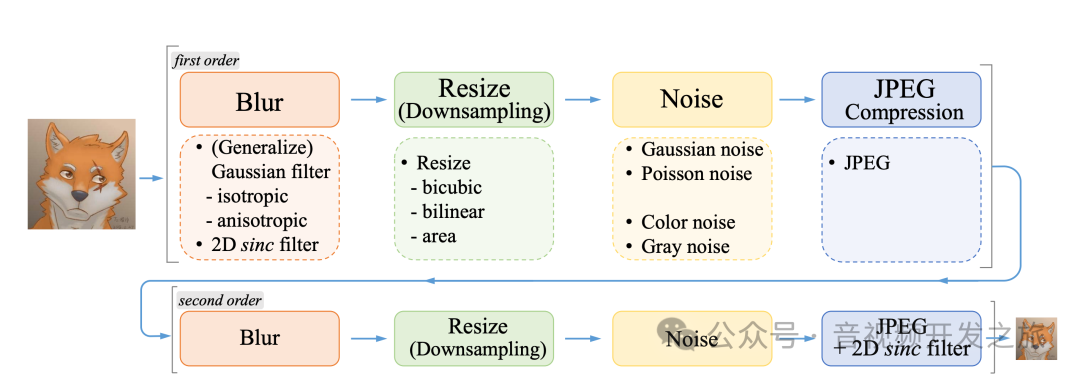
引入了一个二阶退化建模过程,以更好地模拟复杂的现实世界退化。还通过sinc filter模拟了常见的振铃和过冲伪影,如下图所示

三、RealESRGAN模型结构
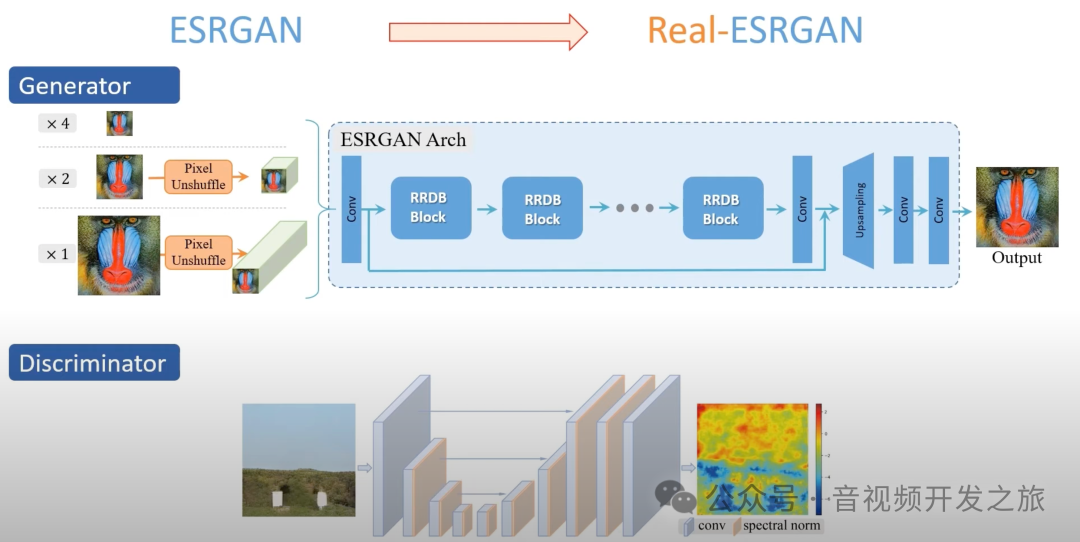
生成器
将低分辨率(LR)图像转换成高分辨率(HR)图像
Real-ESRGAN的生成器沿用了ESRGAN的架构,流程如下:
1、Pixel Unshuffle:用于减少图像的宽高、同时增加图像的通道数,减少计算的复杂度
2、特征提取:输入图像首先通过一系列的卷积层进行特征提取。这些卷积层通过密集连接的方式,使得每个卷积层的输出都能为后续的卷积层提供信息,从而增强了网络对图像细节的捕捉能力。
3、RRDB(Residual in Residual Dense Block)残差密集块:由多个残差密集连接的卷积层组成,有助于捕获更深层次的特征并提高网络的性能。
4、Upsampling:在通过一系列RRDB模块后,网络会通过上采样(如最近邻插值、双线性插值等)将特征图的尺寸放大到目标高分辨率图像的大小
5、ConvBlock卷积块:通过一个或多个卷积层将上采样后的特征图转换为目标高分辨率图像。
判别器
判断一个图像是真实的高分辨率图像还是由生成器生成的
Real-ESRGAN的判别器使用的是U-Net网络,而不是ESRGAN中使用的VGG网络,因为U-Net具有更强大的空间捕捉能力,可以更精准的评估图像的局部纹理和细节,U-Net的精确梯度反馈有助于生成器学习如何减少振铃(Ringing)和过冲(Overshoot)伪影,从而产生更真实、自热的高分辨率图像。
Real-ESRGAN为了训练的稳定性,引入频谱归一化(Spectral Normalization)通过限制权重矩阵的谱范数来防止梯度消失或爆炸
RRDB
Real-ESRGAN和ESRGAN的生成器基本一致,其主干沿袭自SRResNet,如下图所示
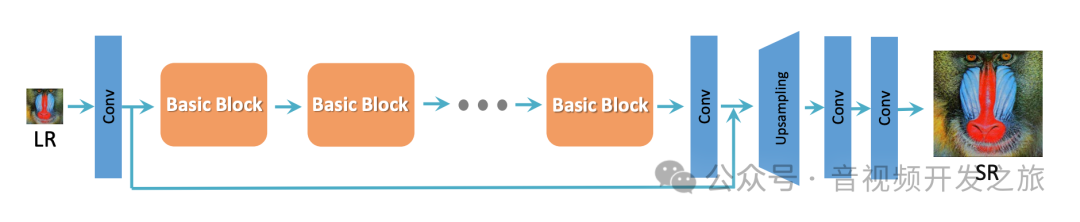
然后把SRResNet中的BasicBlock改为RRDB
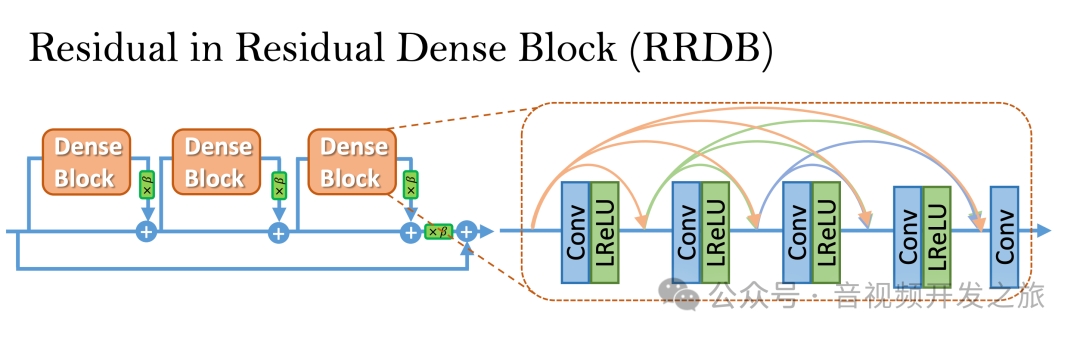
RRDB的核心思想是将残差学习和残差密集块RDB(Residual Dense Blocks)连接相结合,以提高网络的特征提取能力和训练稳定性
RDB 残差密集层(Residual Dense Layer)
-
密集连接:在每个残差密集层中,每个卷积层的输出都会作为后续所有卷积层的输入。这种设计使得网络能够从浅层到深层逐渐累积特征,增强了网络的特征提取能力。
-
残差连接:每个残差密集层的输入和输出之间有一个残差连接。这种设计有助于缓解梯度消失问题,提高网络的训练稳定性。
四、源码分析
4.1 推理代码
model = RRDBNet(num_in_ch=3, num_out_ch=3, num_feat=64, num_block=23, num_grow_ch=32, scale=4)netscale = 4model_path='RealESRGAN_x4plus.pth'# restorer 构建RealESRGan类upsampler = RealESRGANer(scale=netscale,model_path=model_path,dni_weight=None,model=model,tile=None,tile_pad=args.tile_pad,pre_pad=args.pre_pad,half=not args.fp32,gpu_id=args.gpu_id)output, _ = upsampler.enhance(img, outscale=args.outscale)
4.2 RRDB网络
class ResidualDenseBlock(nn.Module):"""残差密集模块,Residual Dense Block.使用在ESRGAN的骨干网络RRDB中,RealEsrGan继承了这个生成框架"""def __init__(self, num_feat=64, num_grow_ch=32):super(ResidualDenseBlock, self).__init__()self.conv1 = nn.Conv2d(num_feat, num_grow_ch, 3, 1, 1)self.conv2 = nn.Conv2d(num_feat + num_grow_ch, num_grow_ch, 3, 1, 1)self.conv3 = nn.Conv2d(num_feat + 2 * num_grow_ch, num_grow_ch, 3, 1, 1)self.conv4 = nn.Conv2d(num_feat + 3 * num_grow_ch, num_grow_ch, 3, 1, 1)self.conv5 = nn.Conv2d(num_feat + 4 * num_grow_ch, num_feat, 3, 1, 1)self.lrelu = nn.LeakyReLU(negative_slope=0.2, inplace=True)# initializationdefault_init_weights([self.conv1, self.conv2, self.conv3, self.conv4, self.conv5], 0.1)def forward(self, x):x1 = self.lrelu(self.conv1(x))x2 = self.lrelu(self.conv2(torch.cat((x, x1), 1)))x3 = self.lrelu(self.conv3(torch.cat((x, x1, x2), 1)))x4 = self.lrelu(self.conv4(torch.cat((x, x1, x2, x3), 1)))x5 = self.conv5(torch.cat((x, x1, x2, x3, x4), 1))# Empirically, we use 0.2 to scale the residual for better performancereturn x5 * 0.2 + xclass RRDB(nn.Module):"""RRDB blck模块, 每个RRDB block有三个ResidualDenseBlock组成"""def __init__(self, num_feat, num_grow_ch=32):super(RRDB, self).__init__()self.rdb1 = ResidualDenseBlock(num_feat, num_grow_ch)self.rdb2 = ResidualDenseBlock(num_feat, num_grow_ch)self.rdb3 = ResidualDenseBlock(num_feat, num_grow_ch)def forward(self, x):out = self.rdb1(x)out = self.rdb2(out)out = self.rdb3(out)# Empirically, we use 0.2 to scale the residual for better performancereturn out * 0.2 + x@ARCH_REGISTRY.register()class RRDBNet(nn.Module):"""ESRGAN和REAL-ESRGAN生成器使用RRDB组成的网络"""def __init__(self, num_in_ch, num_out_ch, scale=4, num_feat=64, num_block=23, num_grow_ch=32):super(RRDBNet, self).__init__()self.scale = scaleif scale == 2:num_in_ch = num_in_ch * 4elif scale == 1:num_in_ch = num_in_ch * 16self.conv_first = nn.Conv2d(num_in_ch, num_feat, 3, 1, 1)self.body = make_layer(RRDB, num_block, num_feat=num_feat, num_grow_ch=num_grow_ch) #构造有num_block(23)RRDB组成的bodylayerself.conv_body = nn.Conv2d(num_feat, num_feat, 3, 1, 1)# upsampleself.conv_up1 = nn.Conv2d(num_feat, num_feat, 3, 1, 1)self.conv_up2 = nn.Conv2d(num_feat, num_feat, 3, 1, 1)self.conv_hr = nn.Conv2d(num_feat, num_feat, 3, 1, 1)self.conv_last = nn.Conv2d(num_feat, num_out_ch, 3, 1, 1)self.lrelu = nn.LeakyReLU(negative_slope=0.2, inplace=True)def forward(self, x):if self.scale == 2:feat = pixel_unshuffle(x, scale=2) #pixel_unshuffle 用于降低图像的wh,增加通道数.将一个形状为 (N, C, H×r, W×r) 的张量重组成形状为 (N, C×r^2, H, W) 的张量,其中 r 是降采样因子(downscale_factor)else:feat = xfeat = self.conv_first(feat)body_feat = self.conv_body(self.body(feat))feat = feat + body_feat #残差连接# upsamplefeat = self.lrelu(self.conv_up1(F.interpolate(feat, scale_factor=2, mode='nearest')))#上采样采用临近插值feat = self.lrelu(self.conv_up2(F.interpolate(feat, scale_factor=2, mode='nearest')))out = self.conv_last(self.lrelu(self.conv_hr(feat)))return out
4.3 构建RealESRGNer
class RealESRGANer():"""A helper class for upsampling images with RealESRGAN.Args:tile:过大的图像会导致 GPU 内存不足的问题,tile会先将输入图像裁剪成分块,然后处理每一个分块。最后,合并成一张图像"""def __init__(self,scale,model_path,dni_weight=None,model=None,tile=0,tile_pad=10,pre_pad=10,half=False,device=None,gpu_id=None):self.scale = scaleself.tile_size = tileself.tile_pad = tile_padself.pre_pad = pre_padself.mod_scale = Noneself.half = half# initialize modelself.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') if device is None else device#这里模型load 为什么要map_location到cpu?#提高兼容性,即使模型在GPU上训练导出,也可以通过map_location制定device在cpu上加载和使用loadnet = torch.load(model_path, map_location=torch.device('cpu'))# prefer to use params_ema 指数移动平均(Exponential Moving Average,简称EMA)用于计算数据点的加权平均值,其中最近的数据点被赋予更大的权重,可以用来平滑模型的参数,使得模型在训练过程中更加稳定,并且通常能够提高模型在测试集上的性能keyname = 'params_ema'model.load_state_dict(loadnet[keyname], strict=True)model.eval()self.model = model.to(self.device)#这个很第一次见到,get,针对显存不足的很有帮助if self.half:self.model = self.model.half()def process(self):# model inferenceself.output = self.model(self.img)@torch.no_grad()def enhance(self, img, outscale=None, alpha_upsampler='realesrgan'):h_input, w_input = img.shape[0:2]img = img.astype(np.float32)max_range = 255img = img / max_range #[0,255] -->[0,1]img_mode = 'RGB'img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)output_img =self.process()output_img = output_img.data.squeeze().float().cpu().clamp_(0, 1).numpy() #clamp_(0, 1)将张量中所有元素值限定在(0, 1),小于0置为0,大于1置为1output_img = np.transpose(output_img[[2, 1, 0], :, :], (1, 2, 0)),#output_img[[2, 1, 0], :, :]先把C的RGB转为BGR, 然后在CHW转为HWCoutput = (output_img * 255.0).round().astype(np.uint8) #把[0,1]转为[0,255],保留整数return output, img_mode
五、不足与局限性
尽管Real-ESRGAN在图像超分辨率领域取得了重大进展,但它仍然存在一些不足:
1、模型可能会过度锐化图像,导致不自然的边缘和纹理;
2、可能会生成不存在于原始图像中的伪细节
六、资料
1、论文:https://arxiv.org/pdf/2107.10833
2、ESRGAN论文:https://arxiv.org/pdf/1809.00219
3、源码:https://github.com/xinntao/Real-ESRGAN
4、https://www.youtube.com/watch?v=fxHWoDSSvSc&ab_channel=XintaoWang
5、https://www.bilibili.com/video/BV14541117y6
感谢你的阅读
接下来我们继续学习输出AI相关内容,欢迎关注公众号“音视频开发之旅”,一起学习成长。
欢迎交流
















![[CocosCreator]全栈接入微信支付宝SDK(V3)](https://i-blog.csdnimg.cn/direct/00388e471c5e4cc08bffb7e182ef57ca.png)