七 集合(List)
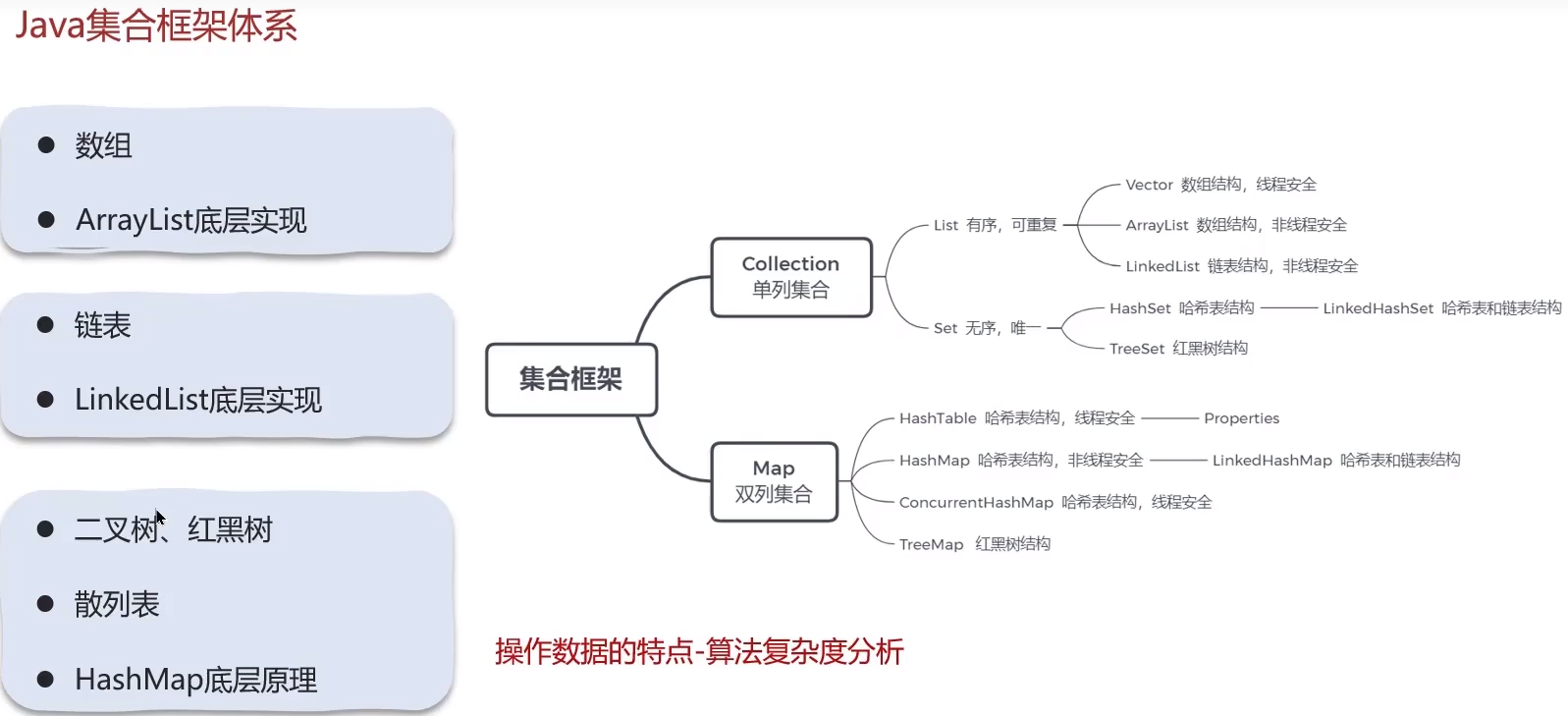

7.1 复杂度分析

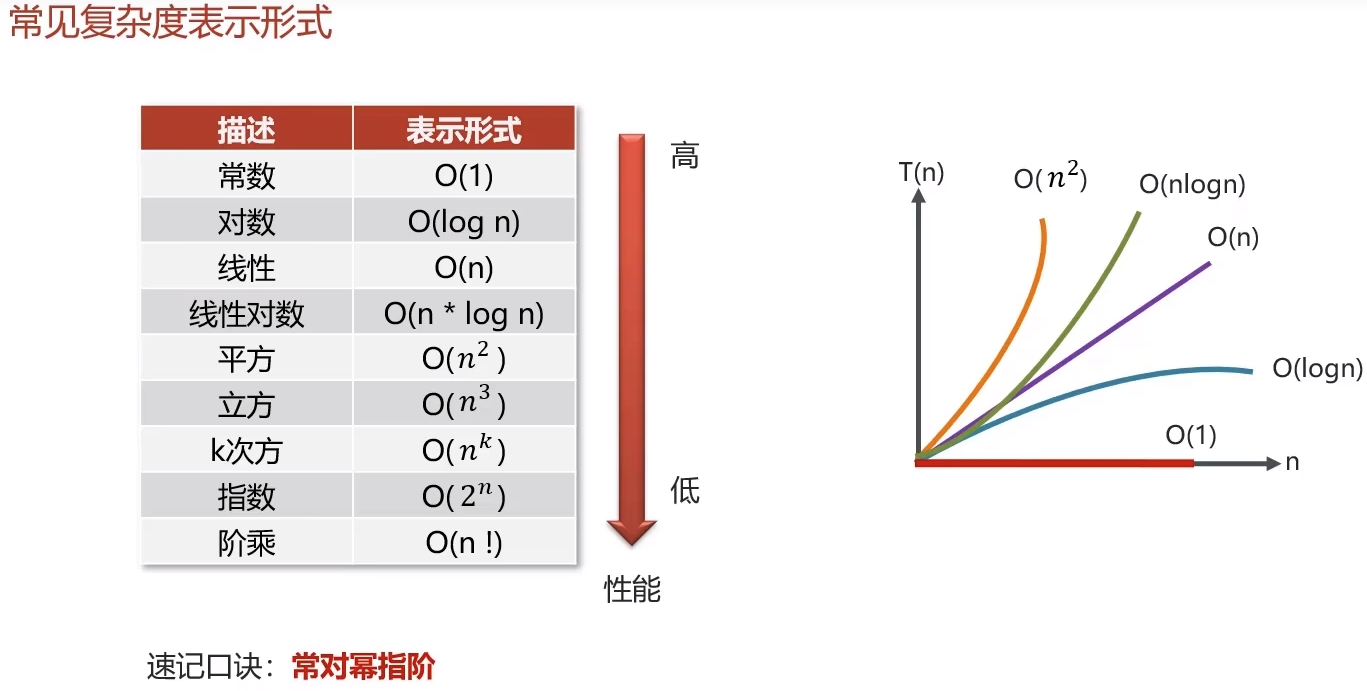

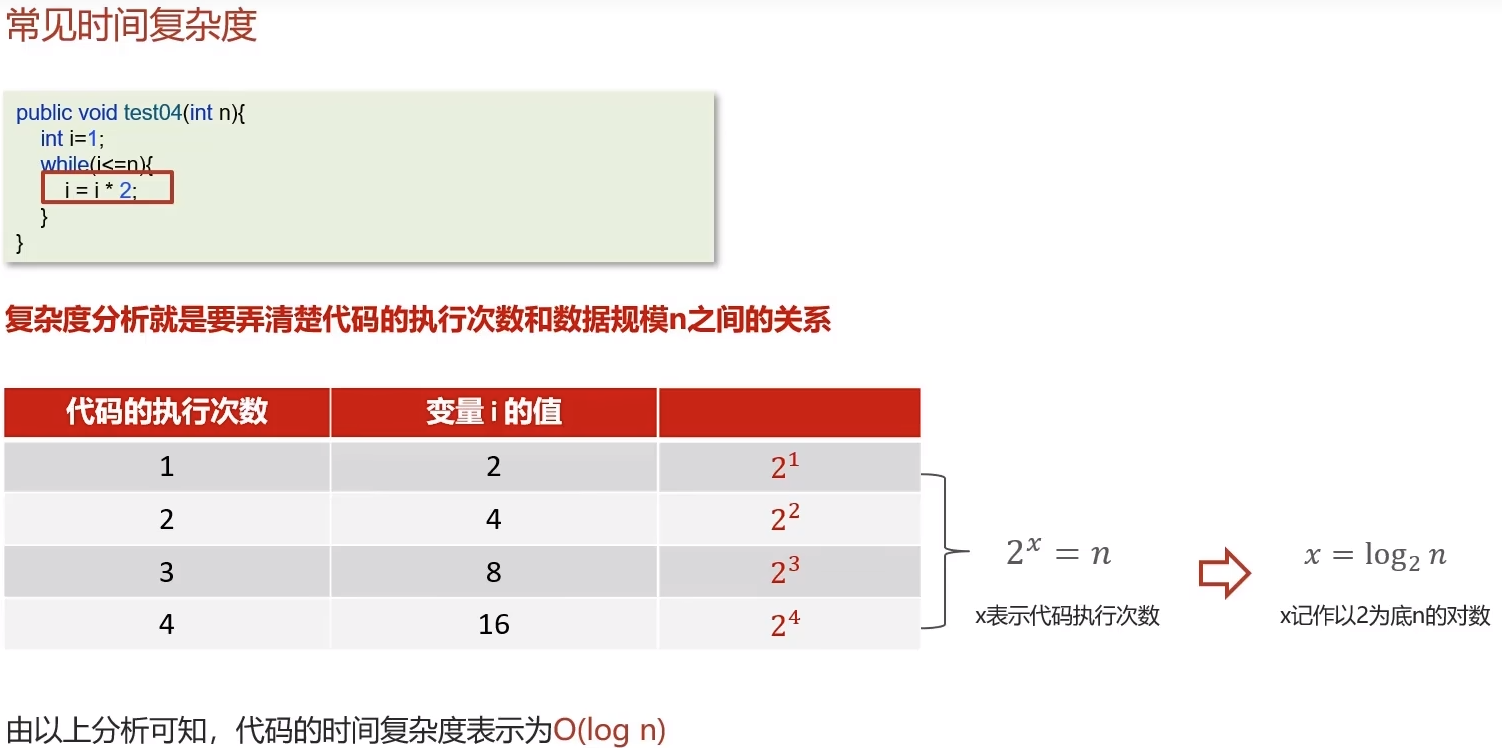
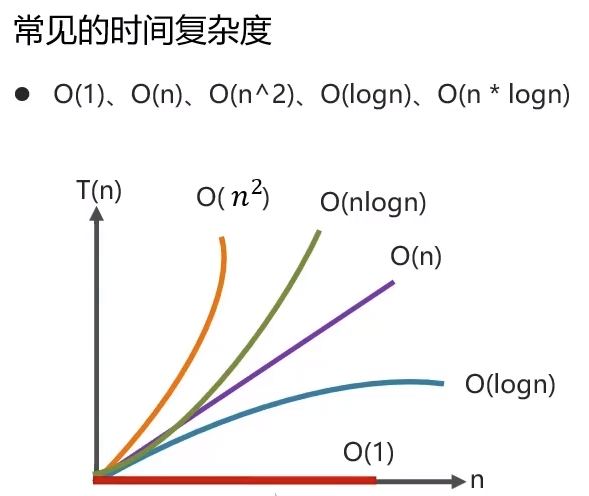

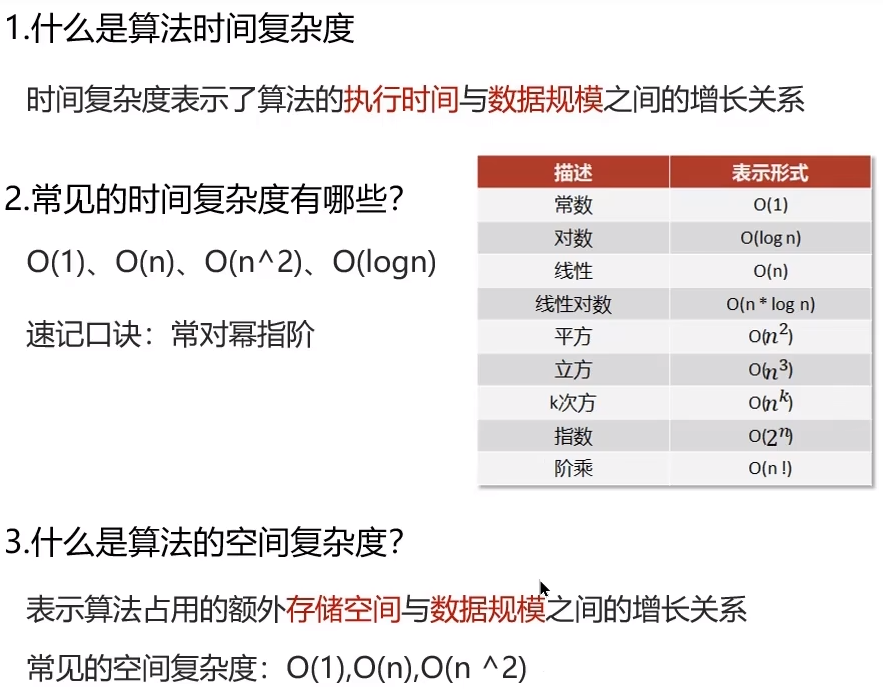
7.2 数组
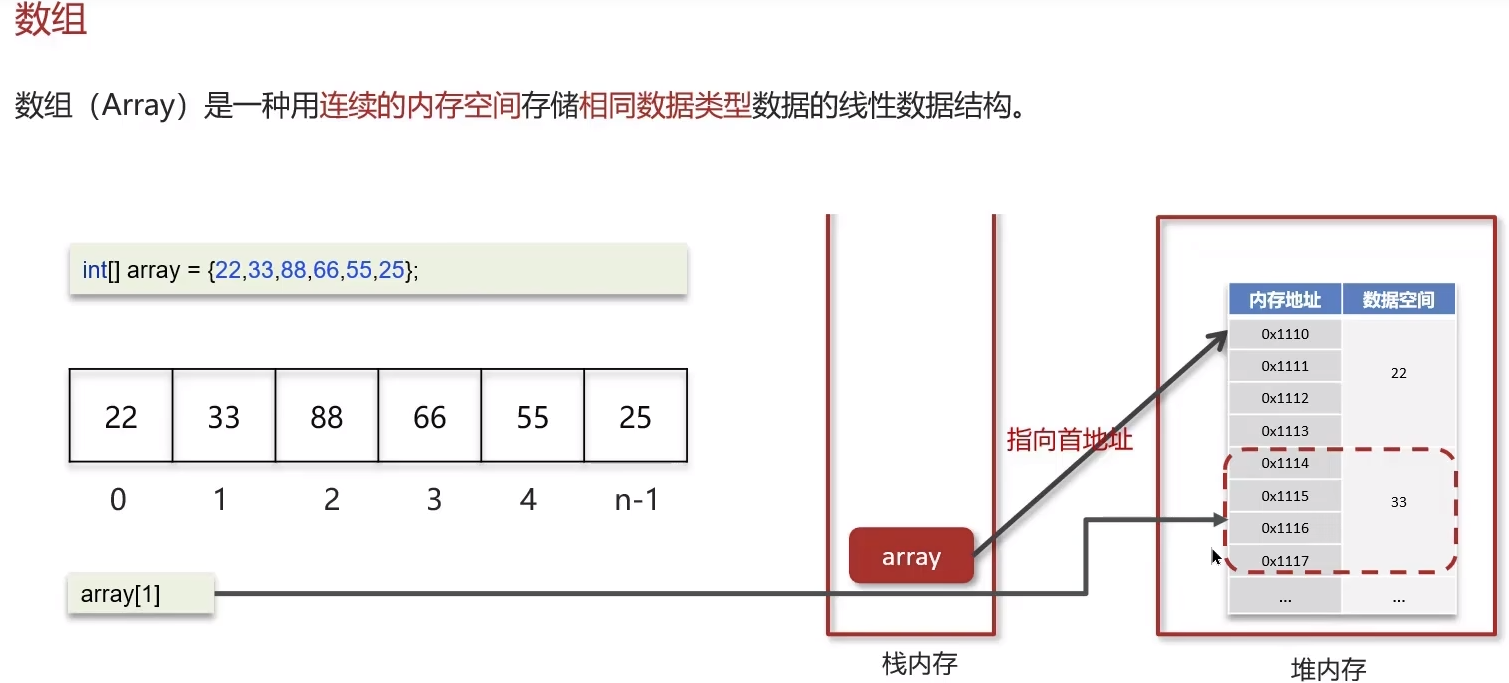


1.数组(Array)是一种用连续的内存空间存储相同数据类型
数据的线性数据结构。
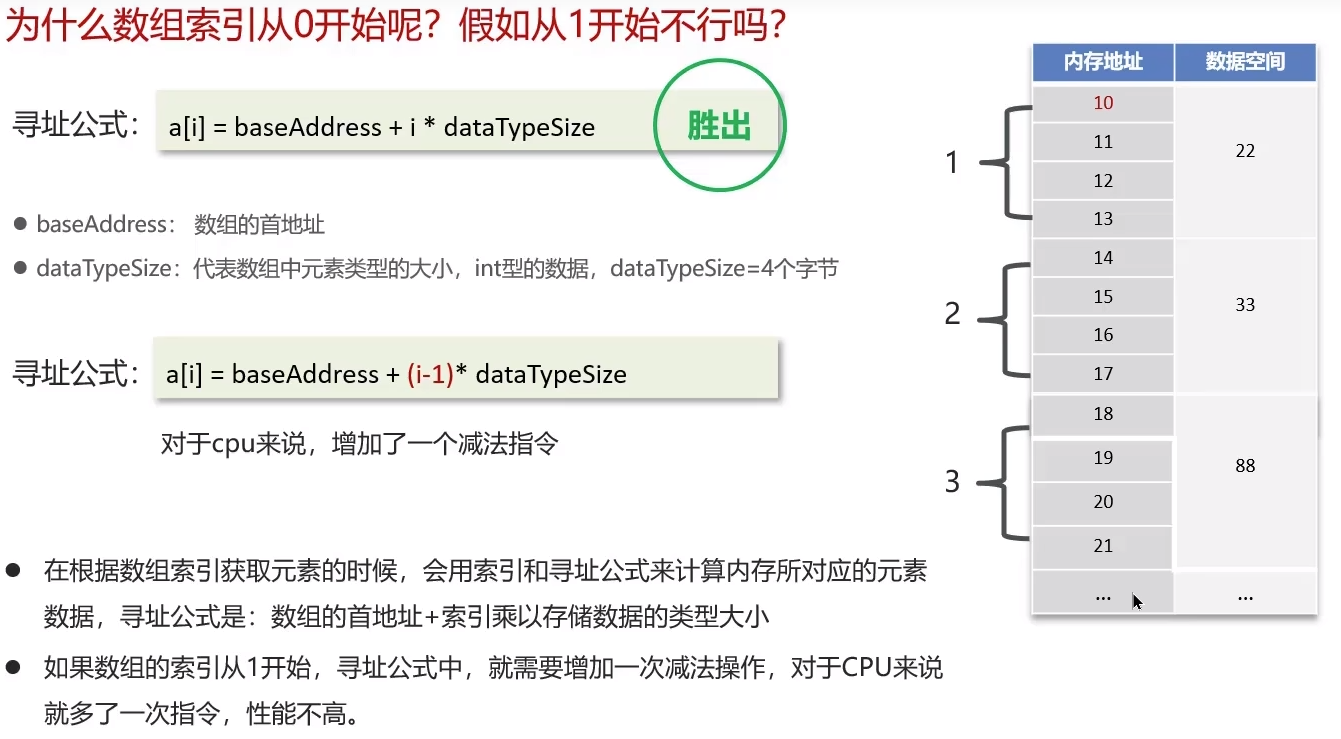
2.数组下标为什么从0开始
寻址公式是:baseAddress+i*dataTypeSize,计算下标的内存地址效率较高
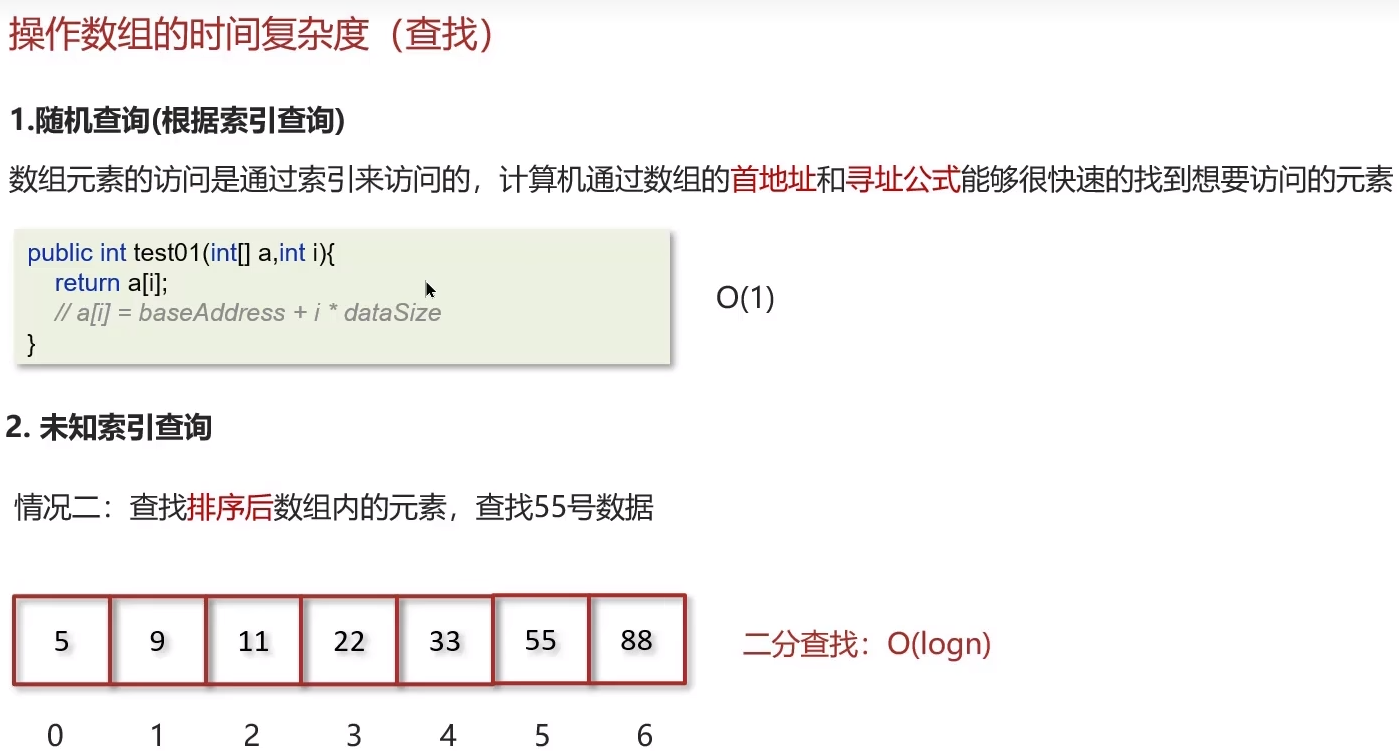
3.查找的时间复杂度
- 随机(通过下标)查询的时间复杂度是O(1)
- 查找元素(未知下标)的时间复杂度是O(n)
- 查找元素(未知下标但排序)通过二分查找的时间复杂度是O(logn)
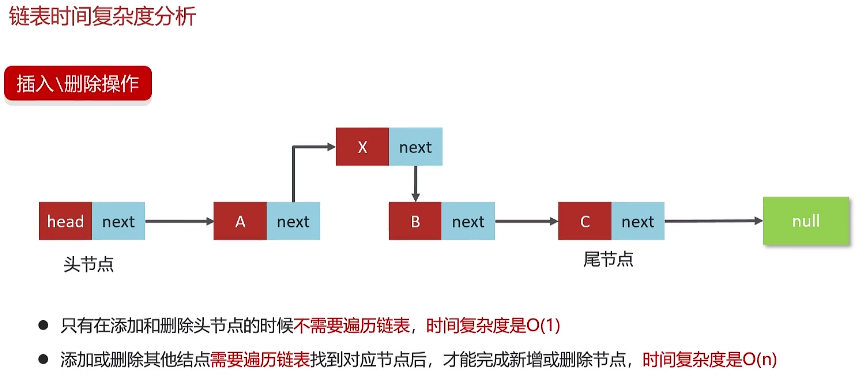
4.插入和删除时间复杂度
插入和删除的时候,为了保证数组的内存连续性,需要挪动数组元素,平均时间复杂度为O(n)
7.3 ArrayList 底层实现



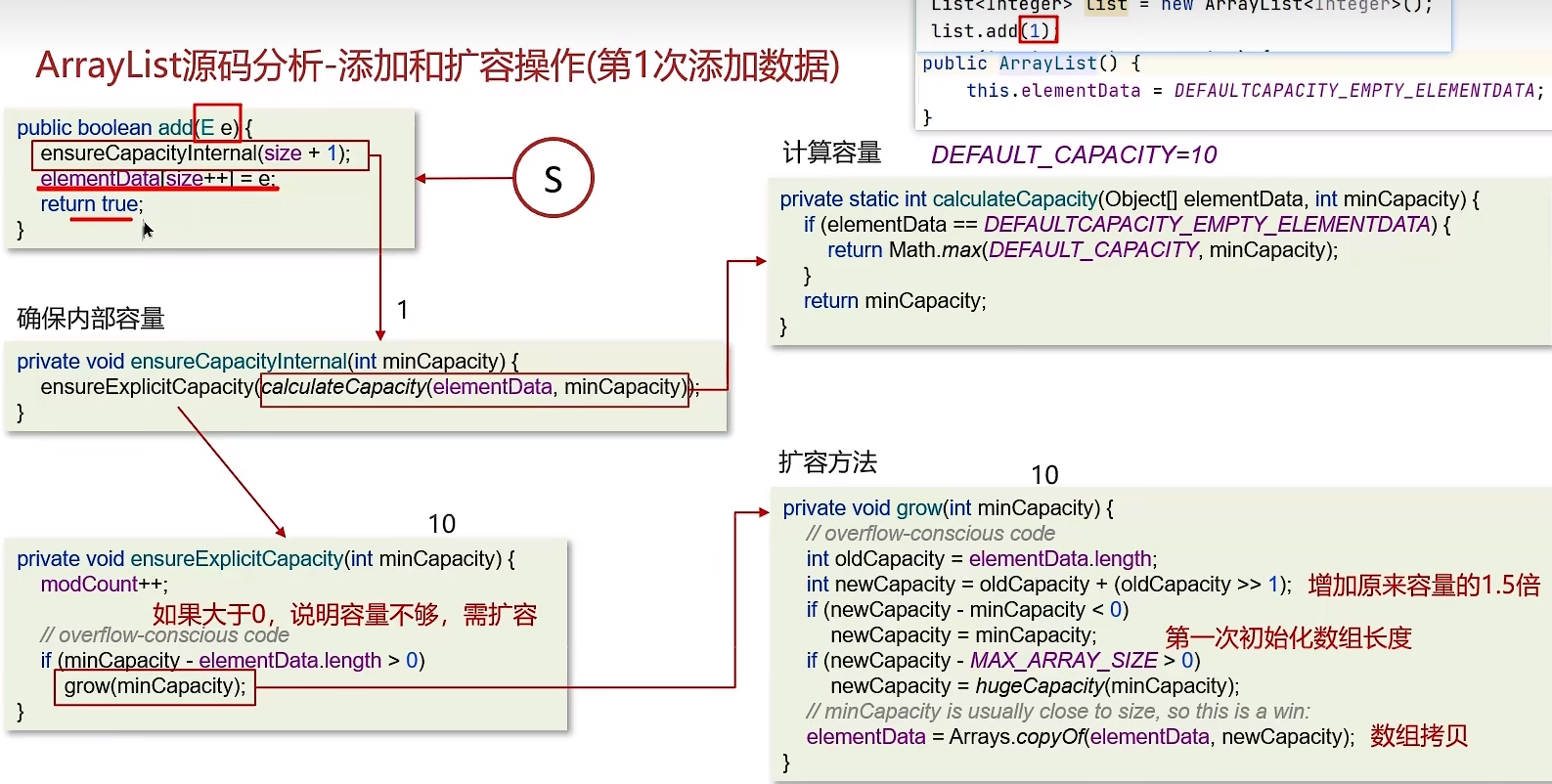
7.4 ArrayList底层的实现原理是什么
- ArrayList底层是用动态的数组实现的
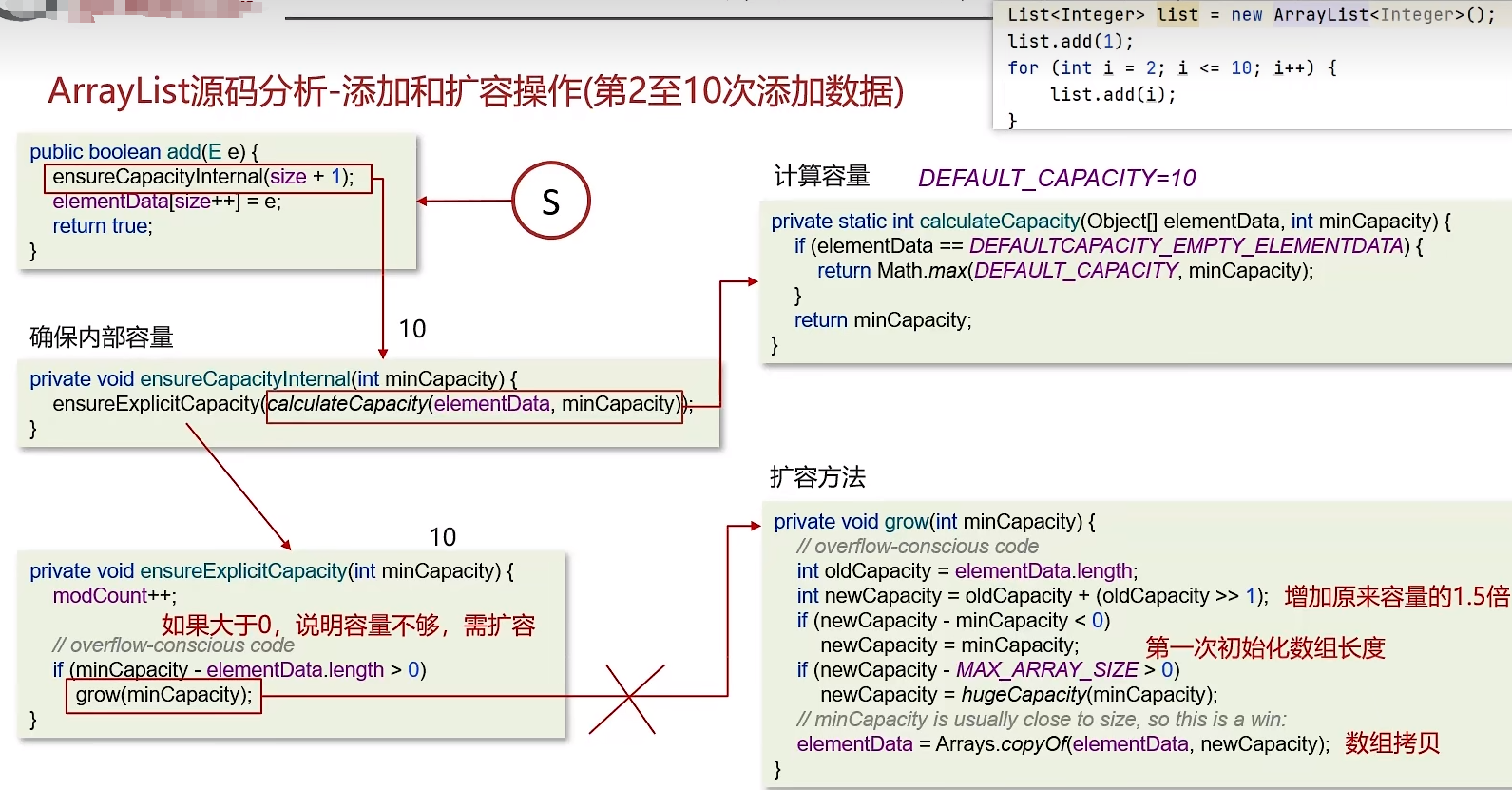
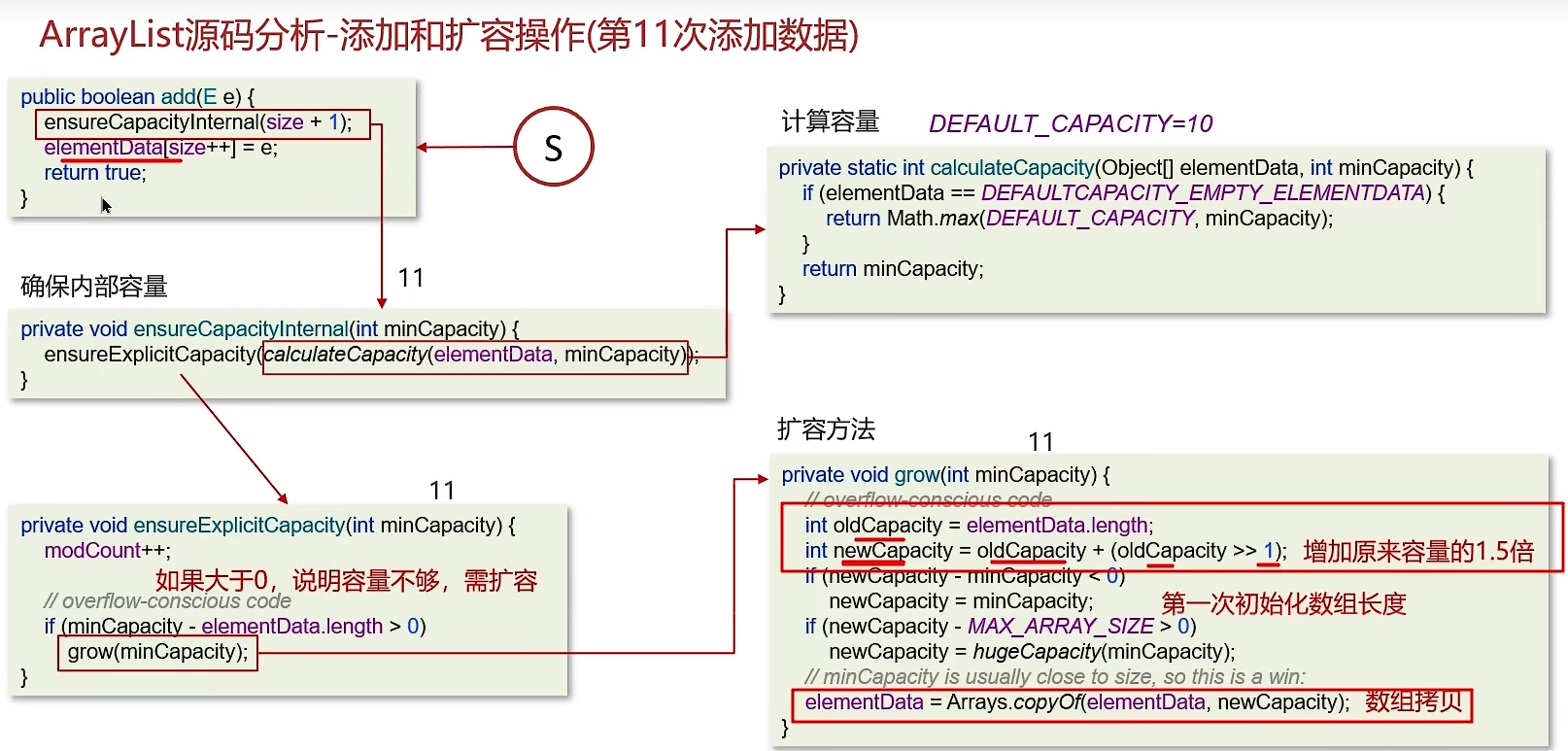
- ArrayList初始容量为0,当第一次添加数据的时候才会初始化容量为10
- ArrayList在进行扩容的时候是原来容量的1.5倍,每次扩容都需要拷贝数组
- ArrayList在添加数据的时候
- 确保数组已使用长度(size)加1之后足够存下下一个数据
- 计算数组的容量,如果当前数组已使用长度+1后的大于当前的数组长度,则调用grow方法扩容(原来的1.5倍)
- 确保新增的数据有地方存储之后,则将新元素添加到位于size的位置上。
- 返回添加成功布尔值。
7.5 ArrayList list=new ArrayList(10)中的list扩容几次

7.6 如何实现数组和list之间的转换
- 数组转List ,使用JDK中java.util.Arrays工具类的asList方法
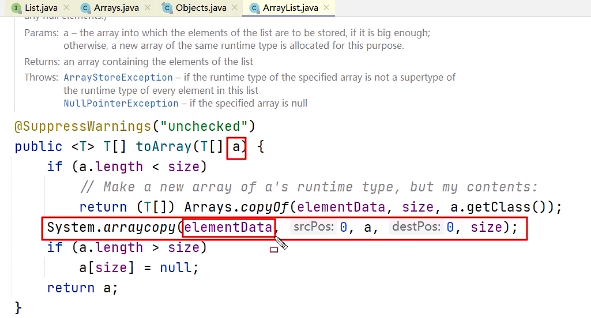
- List转数组,使用List的toArray方法。无参toArray方法返回Object数组,传入初始化长度的数组对象,返回该对象数组



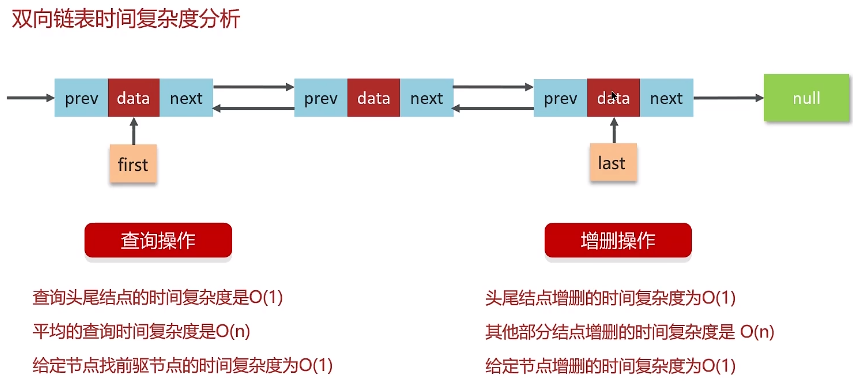
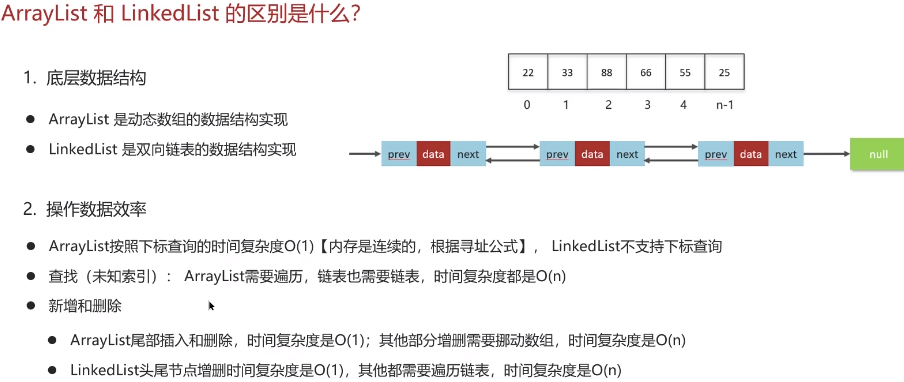
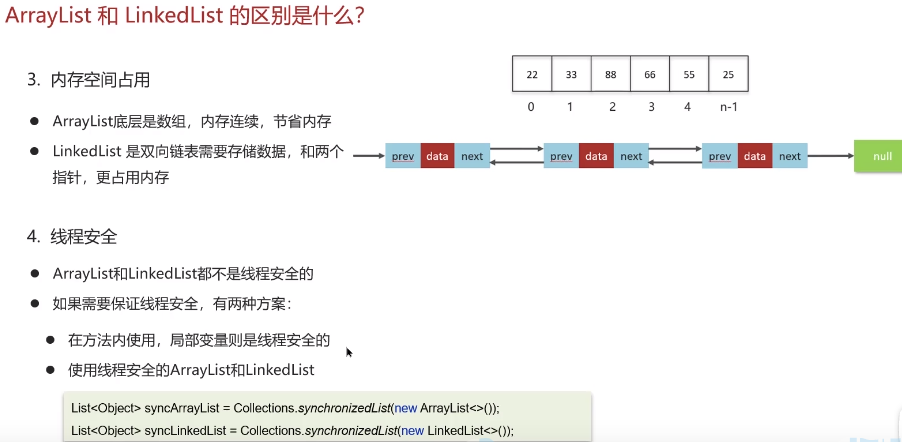
7.7 ArrayList 和 LinkedList 的区别是什么?
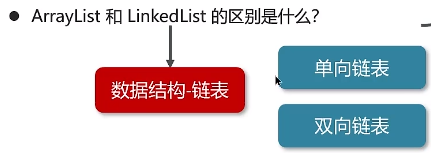
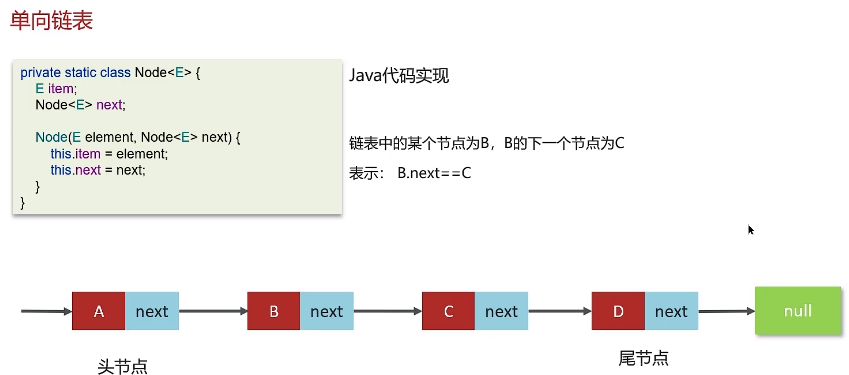
7.7.1单向链表
- 链表中的每一个元素称之为结点(Node)
- 物理存储单元上,非连续、非顺序的存储结构
- 单向链表:每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。记录下个结点地址的指针叫作后继指针 next
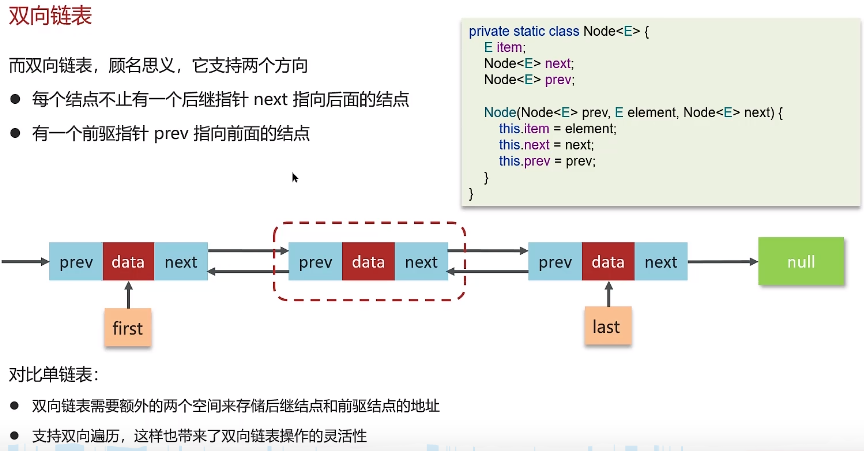
7.7.2 双向连表