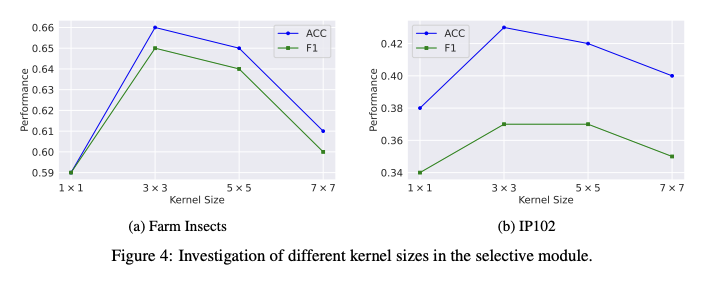
前言
之前笔者分享了text2sql & LLM & KG的有机结合实现KBQA的问答,
《【LLM & RAG & text2sql】大模型在知识图谱问答上的核心算法详细思路及实践》、
《【开源分享】KBQA核心技术及结合大模型SPARQL查询生成问答实践》。
我们再来看看大模型在text2sql上的一篇综述,大模型的发展,出现了一系列新方法,主要集中在提示工程(prompt engineering)和微调(fine-tuning)上。这篇综述提供了LLMs在Text-to-SQL任务中的全面概述,讨论了基准数据集、提示工程、微调方法和未来的研究方向。
Text2SQL
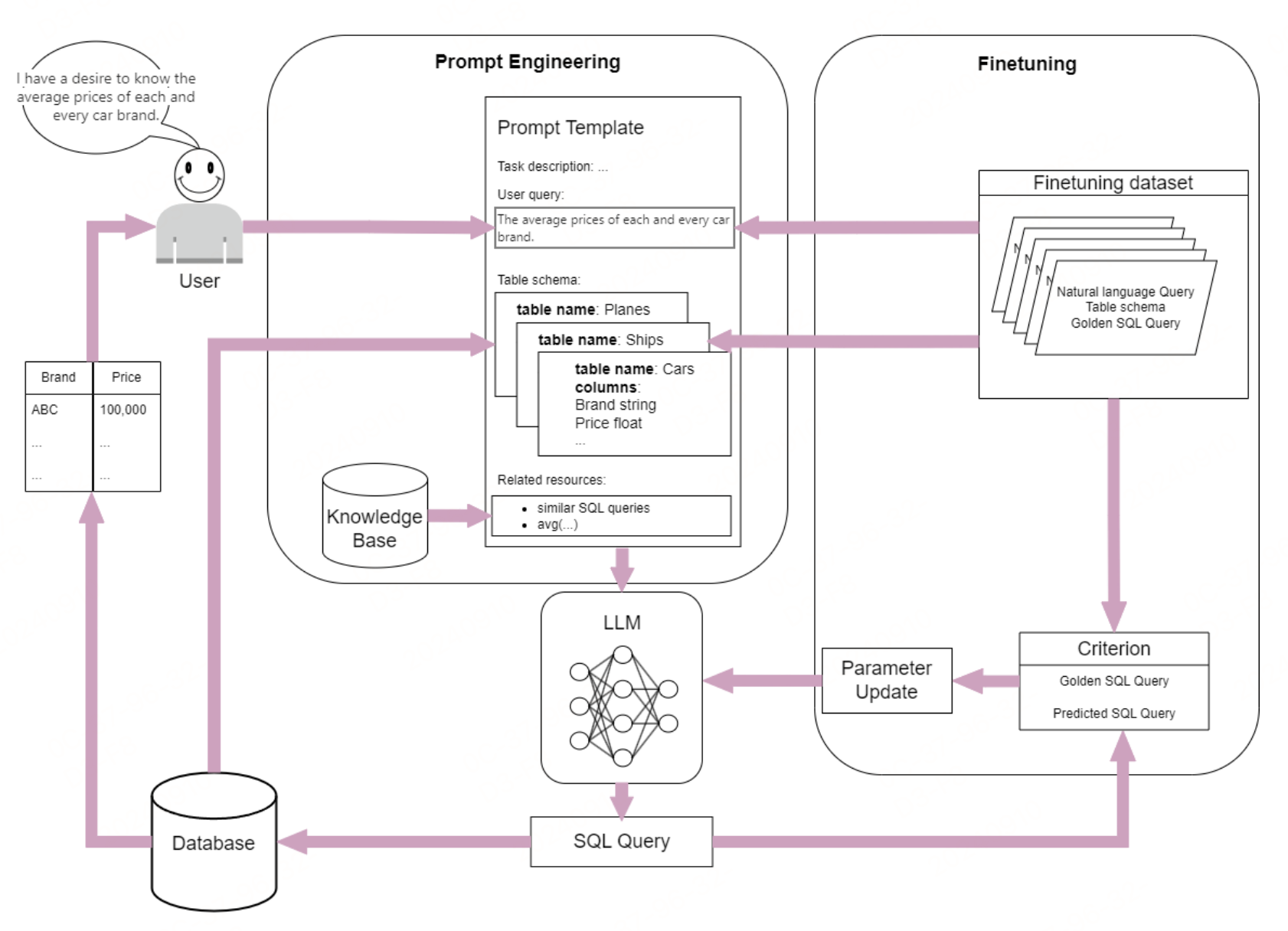
利用大型语言模型(LLMs)解决文本到SQL任务的方法,主要包括提示工程和微调两大类。
-
提示工程

提示工程通过设计结构化的提示,使LLMs能够理解任务需求并生成相应的SQL查询。提示工程分为三个阶段:预处理、推理和后处理。
-
预处理:包括问题描述和数据库模式的格式化和布局,以及引入额外的SQL知识或外部知识。问题描述可以采用Openai模板或"Create Table"布局,样本数据可以帮助LLM更好地理解数据库内容。


-
推理:在接收到用户问题和数据库模式后,生成相应的SQL查询。推理过程可以设计特定的工作流,如Chain-of-Thought和Least-to-Most方法,也可以使用Demonstrations来增强SQL生成能力。
-
后处理:对生成的SQL进行优化,提高其性能和稳定性。常见的后处理方法包括自校正(Self-Correction)和一致性方法(Self-Consistency和Cross-Consistency)。
-
-
微调
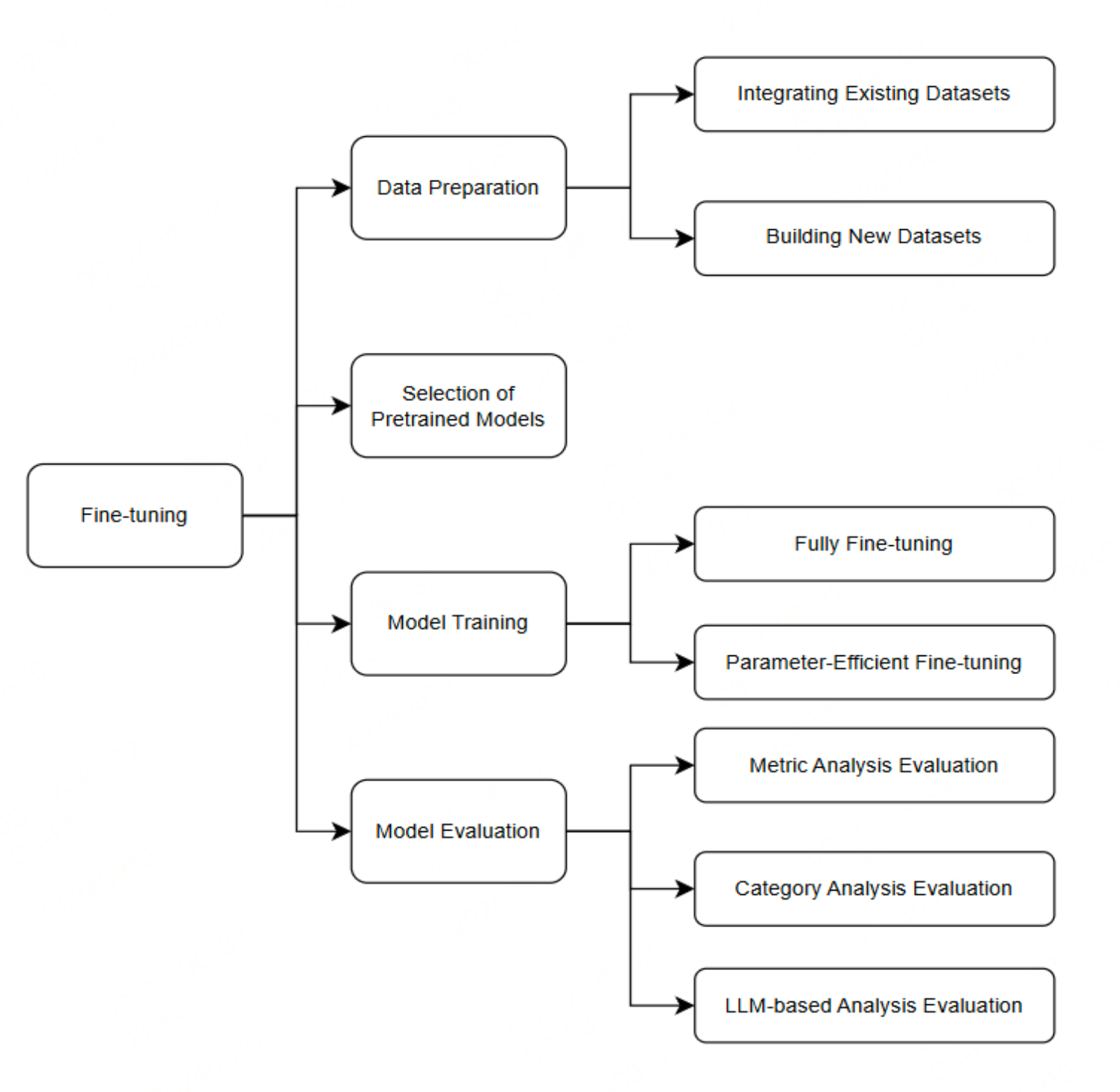
微调通过在特定任务数据上训练LLMs来提升其性能。微调过程包括数据准备、预训练模型选择、模型微调和模型评估。
-
数据:可以通过整合现有数据集或构建新数据集来获取训练数据。新数据集可以通过半自动或全自动的方法生成。
-
预训练模型选择:选择适合的预训练模型进行微调,考虑模型参数规模、预训练语料库和计算能力等因素。
-
模型微调:采用全量微调和参数高效微调等方法。参数高效微调通过仅微调少量模型参数来提高训练效率。
-
模型评估:通过综合指标分析、分类分析和基于LLM的分析评估来衡量模型性能。常用的评估指标包括精确集匹配准确率(EM)、执行准确率(EX)、测试集准确率(TS)和有效效率得分(VES)。
-
参考文献
A Survey on Employing Large Language Models for Text-to-SQL Tasks,https://arxiv.org/pdf/2407.15186v3