论文:Late Chunking: Contextual Chunk Embeddings Using Long-Context Embedding Models
地址:https://arxiv.org/abs/2409.04701
研究背景
研究问题:这篇文章要解决的问题是文本块嵌入在处理长文本时丢失上下文信息的问题。具体来说,当文本被分割成多个小块进行嵌入时,每个块的嵌入可能会失去与其他块的上下文联系,导致表示质量下降。 研究难点:该问题的研究难点包括:如何在嵌入过程中保留长文本的上下文信息,以及如何在不增加额外训练的情况下实现这一目标。
研究难点:该问题的研究难点包括:如何在嵌入过程中保留长文本的上下文信息,以及如何在不增加额外训练的情况下实现这一目标。
相关工作:现有的文本嵌入模型大多基于Transformer架构,使用均值池化等方法将token嵌入转换为单个向量表示。为了解决上下文长度有限的问题,常见的做法是在嵌入前对文本进行分块处理。然而,这种方法会导致块与块之间的上下文信息丢失。
研究方法
这篇论文提出了一种名为“Late Chunking”的新方法,用于解决文本块嵌入丢失上下文信息的问题。具体来说:
长文本嵌入:首先,利用最新的开源长上下文嵌入模型(如jina-embeddings-v2)对整篇文本进行编码,生成每个token的向量表示。这些表示包含了整个文本的上下文信息。
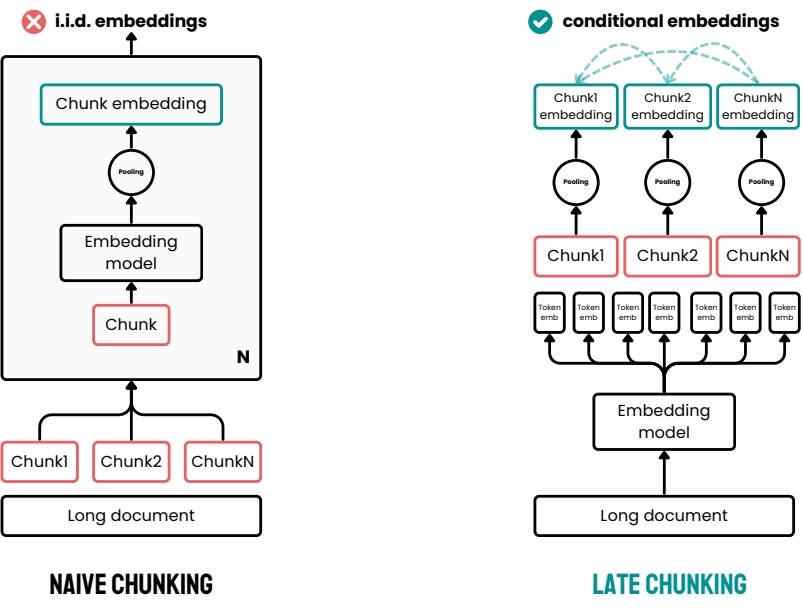
块嵌入生成:然后,在均值池化之前,对生成的token序列进行分块处理。这样,每个块的嵌入就会包含整个文本的上下文信息。
边界线索:需要注意的是,Late Chunking仍然需要边界线索来确定分块的起始和结束位置。这些线索在分词过程中确定,但在获得token级嵌入后使用。
实验设计
数据集:实验使用了BeIR基准测试中的多个数据集,包括SciFact、TRECCOV、FiQA2018、NFCorpus和Quora。
分块方法:为了评估不同方法的效果,实验中将文本分割成256个token的块。
模型:所有实验都使用jina-embeddings-v2-small模型进行嵌入。
评估指标:使用nDCG@10指标来评估检索任务的性能。nDCG@10表示在排名列表中前10个结果的相关性得分。
结果与分析
定性分析:通过计算“Berlin”一词与文章中不同句子的相似度,验证了Late Chunking能够将文本外的上下文信息转移到嵌入表示中。结果表明,使用Late Chunking方法的相似度得分显著高于使用Naive Chunking方法。
定量分析:在BeIR基准测试的多个数据集上,Late Chunking方法在所有实验中均优于Naive Chunking方法。特别是在文档平均长度较长的数据集上,Late Chunking方法的改进效果更为显著。例如,在SciFact数据集上,Late Chunking方法的nDCG@10得分提高了6.59%,从Naive Chunking方法的63.89%提高到66.10%。
总体结论
本文提出了一种名为“Late Chunking”的新方法,用于解决文本块嵌入丢失上下文信息的问题。通过利用长上下文嵌入模型对整篇文本进行编码,并在均值池化之前进行分块处理,Late Chunking方法能够生成包含整个文本上下文的块嵌入。实验结果表明,该方法在各种检索任务中均优于传统的Naive Chunking方法,且无需额外训练,具有广泛的应用前景。未来的工作将包括更全面的评估和模型的微调,以进一步提高检索任务的性能。
本文由AI辅助人工完成。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦














![[基于 Vue CLI 5 + Vue 3 + Ant Design Vue 4 搭建项目] 07 如何修改 npm run serve 的启动端口号](https://i-blog.csdnimg.cn/direct/17aff2bd1b434dbe8f5514b5abc76b8d.png#pic_center)