此头文件是线程支持库的一部分。
类模板 std::barrier 提供一种线程协调机制,阻塞已知大小的线程组直至该组中的所有线程到达该屏障。不同于 std::latch,屏障是可重用的:一旦到达的线程组被解除阻塞,即可重用同一屏障。与 std::latch 不同,会在线程解除阻塞前执行一个可能为空的可调用对象。
屏障对象的生存期由一个或多个屏障阶段组成。每个阶段定义一个阻塞线程的阶段同步点。线程可以抵达屏障,但通过调用 arrive 来推迟它在阶段同步点上的等待。这样的线程可以随后再通过调用 wait 在阶段同步点上阻塞。
屏障 阶段 由以下步骤组成:
- 每次调用 arrive 或 arrive_and_drop 减少期待计数。
- 期待计数抵达零时,运行阶段完成步骤,即调用 completion,并解除所有在阶段同步点上阻塞的线程。完成步骤的结束强先发生于所有从完成步骤所除阻的调用的返回。
在期待计数抵达零后,一个线程会在其调用 arrive、arrive_and_drop 或 wait 的过程中执行完成步骤恰好一次,但如果没有线程调用 wait 则是否执行完成步骤为实现定义。 - 完成步骤结束时,重置期待计数为构造中指定的值,它可能为
arrive_and_drop调用所调整,自此开始下一阶段。
并发调用barrier 除了析构函数外的成员函数不会引起数据竞争。
vs2022 类模板如下:
class barrier {
public:
static_assert(
#ifndef __cpp_noexcept_function_type
is_function_v<remove_pointer_t<_Completion_function>> ||
#endif // !defined(__cpp_noexcept_function_type)
is_nothrow_invocable_v<_Completion_function&>,
"N4950 [thread.barrier.class]/5: is_nothrow_invocable_v<CompletionFunction&> shall be true");
using arrival_token = _Arrival_token<_Completion_function>;
constexpr explicit barrier(
const ptrdiff_t _Expected, _Completion_function _Fn = _Completion_function()) noexcept /* strengthened */
: _Val(_One_then_variadic_args_t{}, _STD move(_Fn), _Expected << _Barrier_value_shift) {
_STL_VERIFY(_Expected >= 0 && _Expected <= (max) (),
"Precondition: expected >= 0 and expected <= max() (N4950 [thread.barrier.class]/9)");
}
barrier(const barrier&) = delete;
barrier& operator=(const barrier&) = delete;
_NODISCARD static constexpr ptrdiff_t(max)() noexcept {
return _Barrier_max;
}
_NODISCARD_BARRIER_TOKEN arrival_token arrive(ptrdiff_t _Update = 1) noexcept /* strengthened */ {
_STL_VERIFY(_Update > 0 && _Update <= (max) (), "Precondition: update > 0 (N4950 [thread.barrier.class]/12)");
_Update <<= _Barrier_value_shift;
// TRANSITION, GH-1133: should be memory_order_release
ptrdiff_t _Current = _Val._Myval2._Current.fetch_sub(_Update) - _Update;
_STL_VERIFY(_Current >= 0, "Precondition: update is less than or equal to the expected count "
"for the current barrier phase (N4950 [thread.barrier.class]/12)");
if ((_Current & _Barrier_value_mask) == 0) {
// TRANSITION, GH-1133: should have this fence:
// atomic_thread_fence(memory_order_acquire);
_Completion(_Current);
}
// Embedding this into the token to provide an additional correctness check that the token is from the same
// barrier and wasn't used. All bits of this fit, as barrier should be aligned to at least the size of an
// atomic counter.
return arrival_token{(_Current & _Barrier_arrival_token_mask) | reinterpret_cast<intptr_t>(this)};
}
void wait(arrival_token&& _Arrival) const noexcept /* strengthened */ {
_STL_VERIFY((_Arrival._Value & _Barrier_value_mask) == reinterpret_cast<intptr_t>(this),
"Preconditions: arrival is associated with the phase synchronization point for the current phase "
"or the immediately preceding phase of the same barrier object (N4950 [thread.barrier.class]/19)");
const ptrdiff_t _Arrival_value = _Arrival._Value & _Barrier_arrival_token_mask;
_Arrival._Value = _Barrier_invalid_token;
for (;;) {
// TRANSITION, GH-1133: should be memory_order_acquire
const ptrdiff_t _Current = _Val._Myval2._Current.load();
_STL_VERIFY(_Current >= 0, "Invariant counter >= 0, possibly caused by preconditions violation "
"(N4950 [thread.barrier.class]/12)");
if ((_Current & _Barrier_arrival_token_mask) != _Arrival_value) {
break;
}
_Val._Myval2._Current.wait(_Current, memory_order_relaxed);
}
}
void arrive_and_wait() noexcept /* strengthened */ {
// TRANSITION, GH-1133: should be memory_order_acq_rel
ptrdiff_t _Current = _Val._Myval2._Current.fetch_sub(_Barrier_value_step) - _Barrier_value_step;
const ptrdiff_t _Arrival = _Current & _Barrier_arrival_token_mask;
_STL_VERIFY(_Current >= 0, "Precondition: update is less than or equal to the expected count "
"for the current barrier phase (N4950 [thread.barrier.class]/12)");
if ((_Current & _Barrier_value_mask) == 0) {
_Completion(_Current);
return;
}
for (;;) {
_Val._Myval2._Current.wait(_Current, memory_order_relaxed);
// TRANSITION, GH-1133: should be memory_order_acquire
_Current = _Val._Myval2._Current.load();
_STL_VERIFY(_Current >= 0, "Invariant counter >= 0, possibly caused by preconditions violation "
"(N4950 [thread.barrier.class]/12)");
if ((_Current & _Barrier_arrival_token_mask) != _Arrival) {
break;
}
}
}
void arrive_and_drop() noexcept /* strengthened */ {
const ptrdiff_t _Rem_count =
_Val._Myval2._Total.fetch_sub(_Barrier_value_step, memory_order_relaxed) - _Barrier_value_step;
_STL_VERIFY(_Rem_count >= 0, "Precondition: The expected count for the current barrier phase "
"is greater than zero (N4950 [thread.barrier.class]/24) "
"(checked initial expected count, which is not less than the current)");
(void) arrive(1);
}
private:
void _Completion(const ptrdiff_t _Current) noexcept {
const ptrdiff_t _Rem_count = _Val._Myval2._Total.load(memory_order_relaxed);
_STL_VERIFY(_Rem_count >= 0, "Invariant: initial expected count less than zero, "
"possibly caused by preconditions violation "
"(N4950 [thread.barrier.class]/24)");
_Val._Get_first()();
const ptrdiff_t _New_phase_count = _Rem_count | ((_Current + 1) & _Barrier_arrival_token_mask);
// TRANSITION, GH-1133: should be memory_order_release
_Val._Myval2._Current.store(_New_phase_count);
_Val._Myval2._Current.notify_all();
}
struct _Counter_t {
constexpr explicit _Counter_t(ptrdiff_t _Initial) : _Current(_Initial), _Total(_Initial) {}
// wait(arrival_token&&) accepts a token from the current phase or the immediately preceding phase; this means
// we can track which phase is the current phase using 1 bit which alternates between each phase. For this
// purpose we use the low order bit of _Current.
atomic<ptrdiff_t> _Current;
atomic<ptrdiff_t> _Total;
};
_Compressed_pair<_Completion_function, _Counter_t> _Val;
};成员对象
| 名称 | 定义 |
completion (私有) | CompletionFunction 类型的完成函数对象,在每个阶段完成步骤调用。(仅用于阐述的成员对象*) |
成员类型
| 名称 | 定义 |
arrival_token | 未指定的对象类型,满足可移动构造 (MoveConstructible) 、可移动赋值 (MoveAssignable) 及可析构 (Destructible) |
成员函数
| (构造函数) | 构造 barrier(公开成员函数) |
| (析构函数) | 销毁 barrier(公开成员函数) |
| operator= [弃置] | barrier 不可赋值(公开成员函数) |
| arrive | 到达屏障并减少期待计数 (公开成员函数) |
| wait | 在阶段同步点阻塞,直至运行其阶段完成步骤 (公开成员函数) |
| arrive_and_wait | 到达屏障并把期待计数减少一,然后阻塞直至当前阶段完成 (公开成员函数) |
| arrive_and_drop | 将后继阶段的初始期待计数和当前阶段的期待计数均减少一 (公开成员函数) |
常量 | |
| max [静态] | 实现所支持的期待计数的最大值 (公开静态成员函数) |
示例代码:
#include <barrier>
#include <iostream>
#include <string>
#include <syncstream>
#include <thread>
#include <vector>
int main()
{
const auto workers = { "Anil", "Busara", "Carl" };
auto on_completion = []() noexcept
{
// 此处无需锁定
static auto phase =
"... 完成\n"
"清理...\n";
std::cout << phase;
phase = "... 完成\n";
};
std::barrier sync_point(std::ssize(workers), on_completion);
auto work = [&](std::string name)
{
std::string product = " " + name + " 已工作\n";
std::osyncstream(std::cout) << product; // OK, op<< 的调用是原子的
sync_point.arrive_and_wait();
product = " " + name + " 已清理\n";
std::osyncstream(std::cout) << product;
sync_point.arrive_and_wait();
};
std::cout << "启动...\n";
std::vector<std::jthread> threads;
threads.reserve(std::size(workers));
for (auto const& worker : workers)
threads.emplace_back(work, worker);
return 0;
}运行结果:

另一个示例:
#include <barrier>
#include <iostream>
#include <string>
#include <syncstream>
#include <thread>
#include <vector>
std::barrier bar(4); //创建一个barrier,需要4个线程到达同步点
void thread_func(int id) {
// 线程执行一些任务
//std::cout << "Thread ID: " << std::this_thread::get_id() << " is doing some work." << std::endl;
std::cout << "Thread ID=======start===== is doing some work.\n";
// 等待所有线程到达栅栏
bar.arrive_and_wait();
// 所有线程到达栅栏后,继续执行后续任务
//std::cout << "Thread ID: " << std::this_thread::get_id() << " continues working after barrier." << std::endl;
std::cout << "Thread ID=======end: ===== continues working after barrier.\n";
}
int main() {
constexpr int num_threads = 4;
std::vector<std::thread> threads;
// 创建线程并执行线程函数
for (int i = 0; i < num_threads; ++i) {
threads.emplace_back(thread_func, i);
}
// 等待所有线程执行完毕
for (auto& t : threads) {
t.join();
}
return 0;
}
示例代码:
#include <barrier>
#include <iostream>
#include <string>
#include <syncstream>
#include <thread>
#include <vector>
std::barrier bar(4); //创建一个barrier,需要4个线程到达同步点
void thread_func(int id) {
// 线程执行一些任务
//std::cout << "Thread ID: " << std::this_thread::get_id() << " is doing some work." << std::endl;
std::cout << "Thread ID=======start===== is doing some work.\n";
// 等待所有线程到达栅栏
bar.arrive_and_wait();
// 所有线程到达栅栏后,继续执行后续任务
//std::cout << "Thread ID: " << std::this_thread::get_id() << " continues working after barrier." << std::endl;
std::cout << "Thread ID=======end: ===== continues working after barrier.\n";
}
int main() {
constexpr int num_threads = 4;
std::vector<std::thread> threads;
// 创建线程并执行线程函数
for (int i = 0; i < num_threads; ++i) {
threads.emplace_back(thread_func, i);
}
// 等待所有线程执行完毕
for (auto& t : threads) {
t.join();
}
return 0;
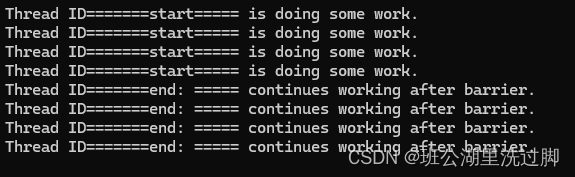
}运行结果:
参考:
std::barrier - cppreference.com
【C++ 20 并发工具 std::barrier】掌握并发编程:深入理解C++的std::barrier_c++ barrier-CSDN博客