FIDAVL:基于视觉语言模型的假图像检测与归因 !
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


作者提出了FIDAVL:使用视觉语言模型进行虚假图像检测。FIDAVL是一种新颖而高效的多任务方法,灵感来源于视觉和语言处理的协同作用。利用零样本学习的益处,FIDAVL利用视觉和语言之间的互补性以及软提示调优策略来检测虚假图像并准确地将其归因于其原始来源模型。 作者在一个涵盖由各种最先进模型生成的合成图像的综合数据集上进行了广泛实验。 作者的结果表明,FIDAVL实现了令人鼓舞的平均检测准确率为95.42%和F1分数为95.47%,同时也取得了显著的性能指标,平均F1分数为92.64%和ROUGE-L分数为96.50%将合成图像归因于各自的原生生成模型。 本工作的源代码将在https://github.com/Mamadou-Keita/FIDAVL上公开发布。
1 Introduction
在过去的二十年里,生成和编辑照片的技术发生了迅速的变化。这一变化带来了视觉内容可以轻松创建和编辑的时代,留下了极少的感知痕迹。因此,人们逐渐意识到作者正站在一个真实图像与计算机生成图像难以区分的世界的边缘。最近生成模型的发展进一步推动了合成图像的质量和高保真度,使它们可以在条件情况下进行上下文操作和扩展媒体合成的范围。然而,在这些进步的同时,一个问题仍然存在,即这些技术的恶意使用可能带来的潜在影响。这种担忧受到公众的关注,因为其对视觉安全、法律框架、政治格局和社会规范产生了破坏性的影响。因此,开发能减轻这些生成模式威胁的有效的视觉法医技术至关重要。
为了解决生成模型带来的挑战,文献中已经出现了几种解决方案。现有的方法主要围绕二进制检测策略(真实与AI生成图像)展开,旨在区分合成图像和真实图像。然而,将生成图像归为其原始来源的任务仍然相对没有探索,并且具有固有的复杂性。现代生成模型达到的真实主义水平,使得依赖人工检查进行归属的方法变得不现实。虽然确定一张图像是否由特定模型生成看起来很简单,但存在细微的挑战。一种简单的做法是训练一个分类器来对由所选模型生成的真实和生成图像的数据集进行分类。然而,这种方法容易受到数据集偏见的影响【31】,并可能在应用于新数据时难以有效地泛化。此外,针对特定生成模型的检测器可能会随着生成技术的发展和训练的模型过时而变得过时。
最近,预训练的大型视觉语言模型已成为许多自然语言处理和计算机视觉任务的有前途的解决方案。这些模型在来自互联网的图像文本数据集上进行训练,并在诸如图像分类、检测和分割等 downstream 任务上表现出零样本和少样本学习的能力。此外,最近利用这些模型检测合成图像的趋势也在增长。
当前最前沿,合成图像的检测和归因往往面临巨大挑战。主要困难之一在于,这些任务通常分开处理,可能导致效果不佳且不够健壮的解决方案。多级或级联架构通常被提出来解决这些任务,但它们增加了复杂性,并且在跨不同类型的合成图像时难以泛化。检测和归因任务的分离开来忽视了由将它们视为相关任务而可能利用到的潜在协同效应。此外,现有模型的泛化能力通常有限,这阻碍了它们在处理种类繁多且不断发展的最前沿图像生成技术方面的有效性。
为解决这些问题,作者提出了一种新的单步多任务方法FIDAVL,该方法将合成图像检测和归因置于统一的框架内。采用视觉语言方法,FIDAVL利用视觉和语言模型之间的协同效应以及软适应策略。这种集成实现了对生成图像的准确检测和归因到其原始来源模型的精细处理,利用了两个任务之间的共享特征。作者的方法得益于视觉语言模型的通用能力,这是对传统方法的重要改进。通过将合成图像检测和归因视为单个过程中相关任务,FIDAVL克服了多级或级联架构的局限性。在包括由各种最先进的模型生成的合成图像的大型数据集上进行的广泛实验证明了FIDAVL的高准确性和稳健性。这种方法不仅简化了检测和归因的过程,而且提高了其可靠性和可扩展性。据作者所知,本研究首次将视觉语言模型应用于合成图像的归因和检测,并在统一的框架内进行。
作者这篇论文的贡献总结如下:
- 作者提出了一种新的单步多任务方法FIDAVL,用于合成图像的检测和归因。利用视觉和语言之间的互补性,FIDAVL有效地将合成图像归因到其各自的原生生成模型。
- 作者采用软提示调优技术来优化FIDAVL的 Query 以实现最佳效果。
通过对大型数据集上的广泛评估,作者提出的这种方法表现出竞争性能,证明了其在合成图像检测和归因方面的有效性。FIDAVL在合成图像检测任务上的平均准确率(ACC)超过95%,平均ROUGE-L分数为96.50%,平均F1分数为92.64%的合成图像归因任务。
本文其余部分将按照以下结构进行组织。第2节提供了相关背景和工作的简要回顾。第3节描述了用于合成图像的归因和检测的 proposed FIDAVL 方法。然后,在第4节中评估和分析了所提出方法的性能。最后,在第5节中得出结论。
2 Background and Related Work
在本节中,作者将探讨生成模型,检查Advanced Deepfake检测和归因技术,并提供对视觉语言模型的见解和提示调优。
Generative Models
生成模型已成为合成各种模态(包括图像、文本、视频和复杂结构)的实时数据强大工具。这些模型通常通过神经网络实现,它们巧妙地学习捕获和复制训练数据中固有的底层模式和分布。在深度生成模型的领域,一个突出的类别是生成对抗网络(GAN)[11]。最近,扩散模型[30]作为图像生成的默认方法取得了实质性进展。将这类模型扩展到文本到图像合成[26,23]领域,带来了许多以卓越质量和多样性为特点的模型,例如Imagen [27]和DALL-E-2 [24]。然而,图像合成的深度生成模型也带来了与合成图像检测和归因相关的挑战。
Synthetic Image Detection and Attribution
近年生成模型取得了重大进展,特别是基于扩散的架构和尖端GAN模型,给现有的检测方法带来了挑战。在[7][25]的研究中,研究方法突出了当前检测器在适应这些创新模型方面的困难,强调了需要开发更有效的检测技术。由此,一种新的方法论已经出现。Coccomini等人尝试使用多层感知器(MLP)和传统的卷积神经网络(CNNs),并检测其在该领域的有效性。相反,Wang等人引入了DIRE,一种适用于扩散生成图像的方法,它优先分析重构误差。通过利用扩散模式,SeDID[21]实现了准确的检测,重点关注逆向和去噪计算错误。Amoroso等人探讨了语义风格解耦以增强风格检测,而Xi等人提出了一个双流网络,强调纹理用于人工智能(AI)生成图像检测。Wu等人倡导语言引导合成检测(LASTED),将检测视为识别问题,并利用语言引导对比学习。Ju等人提出了特征融合机制,将ResNet50和基于注意力的模块结合在一起,实现全球和局部特征融合用于AI合成图像检测。Sinitsa等人提出了一种基于规则的方法,利用CNN提取独特特征,即使在有限的生成图像数据下也能实现高精度。
与传统方法不同,Chang等人从视觉语言模型(VLMs)中获得灵感,将深伪造检测作为视觉问答任务。最后,Cozzolino等人提出了一种轻量级策略,基于对比语言图像预训练(CLIP)特征和线性支持向量机(SVM)提出了一种有效的检测方法。总体而言,准确地将深伪造内容归因于其来源是检测和预防领域的一个关键方面。与其他二进制检测相比,归因引入了多类别维度,有助于识别负责内容的特定生成模型。近期的研究重点关注增强归因技术的重要性。He等人将检测器扩展到探索文本归因,揭示该领域可以改进的领域。在生成视觉数据方面,针对GAN的归因方法已经出现。Bui等人引入了一种GAN指纹技术,显著提高了封闭集环境下的源归因。近期,扩散模型(diffusion models (DMs))也受到了关注。Sha等人使用ResNet检测和归因合成图像到各自生成器,而Guarnera等人提出了一种多 Level 方法进行合成图像检测和归因。Lorenz等人引入了multiLID,一种专门针对扩散生成图像检测和归因的方法,利用内在维度提高准确性。此外,Wang等人解决了生成数据到其训练数据对等物的归因问题,需要识别训练集中显著的贡献者。
Vision Language Models
最近在视觉语言模型的(VLMs)领域取得了重要进展,特别是在任务特异性和数据集约束方面克服了早期模型的局限性。值得注意的是,像CLIP这样的模型,通过在一个包含4亿张图像-标题对的大量数据集上进行训练,同时拥有图像和文本编码器,从而促进了图像分类任务的多样化。在这一领域处于领先地位的先锋模型,如LaViVA [18],BLIP2 [17],InstructBLIP [9]和Flamingo [1],代表了VLMs创新的前沿。
LaViVA是一个开源项目,将视觉和语言理解无缝集成在一个广阔的多模态框架中。然而,BLIP2通过结合预训练的图像编码器和国家语言模型,实现了最先进的性能。在此基础上,InstructBLIP进一步改进了其架构,使其特别适合于视觉指示器的调优。值得注意的是,Flamingo是一个家族的VLMs,它在处理交错式的视觉和文本数据方面具有非常杰出的能力,从而在适应下游任务和扩展零样本能力方面取得了重要的进步。这些进展标志着VLMs领域的巨大进步,展示了其在依赖多模态理解和处理的各种领域的革命性潜力。
Prompt Tuning for Vision Language Models
视觉语言模型(VLMs)在处理多模态数据方面表现出色,然而在适应特定的下游视觉相关目标时,它们会遇到一些挑战。 [37] 推出的开创性研究发现了一种名为上下文优化(CoOp)的方法,可以增强CLIP在图像分类任务中的效率。与传统的提示模板不同,CoOp方法学习的是几乎不依赖下游数据集样品的提示嵌入。提示调优有两种主要形式:硬调优和软调优。 [39] 中提出的硬提示调优涉及调整不可微分的标记来符合用户定义的标准,虽然实现离散改进存在困难。而 [16] 中展示的软提示调优通过反向传播优化可训练张量,从而提升建模性能。在一个显著的应用中,[5] 采用了微妙的提示调优技术来增强黑盒机器学习(ML)模型的指令生成。这些努力强调了在各种下游任务中提高视觉语言模型的适应性和性能的细微提示调优方法的重要性。
3 Proposed Synthetic Image Detection and Localization
Problem Formulation
为了利用视觉语言模型的能力,如InstructBLIP,作者采用了称之为视觉问答(VQA)的框架,作者称之为FIDAVL。FIDAVL的制作非常注重对给定图像的回答。输入包含两个关键组件:一个 Query 图像,标为,作为作者关注的焦点,和一个综合问题,标为,指导FIDAVL对 Query 图像进行分析。随后,图像被分类为真实或虚假;如果是虚假的,它会被归因于其来源。问题可以有不同的形式,从预定义的问题如"这张照片是虚假的,它的来源生成器是什么?"到包含伪词的自定义问题。这种适应性使作者能够根据研究的具体需求调整作者的提问策略。
FIDAVL的输出包括一组响应文本,标为。虽然理论上包含任何文本,作者强加特定的约束以保持作者在响应中的一致性和清晰度。如果 Query 图像被确定为真实,响应被表达为"不,这是一个真实样本。"。反之,如果它被认为是虚假的,响应遵循模板"是的,这是一个由模型名称生成,模型类别模型的虚假样本。在这里,模型名称 表示生成模型的名称,可以属于set progan,diff-projectedgan,stylegan,ldm,glide,Stable diffusion,而模型类别表示生成模型的类别,可以是以扩散还是gan。这种响应结构与作者检测和归因合成图像的实际情况相吻合。最后,为了评估FIDAVL的有效性,作者衡量检测和归因任务的精确性。这种定量评估提供了有关模型在准确识别和归因合成图像方面的能力。
在数学上,单步骤合成图像检测和归因任务的表示如下:
图1:提出的合成图像检测和定位架构。
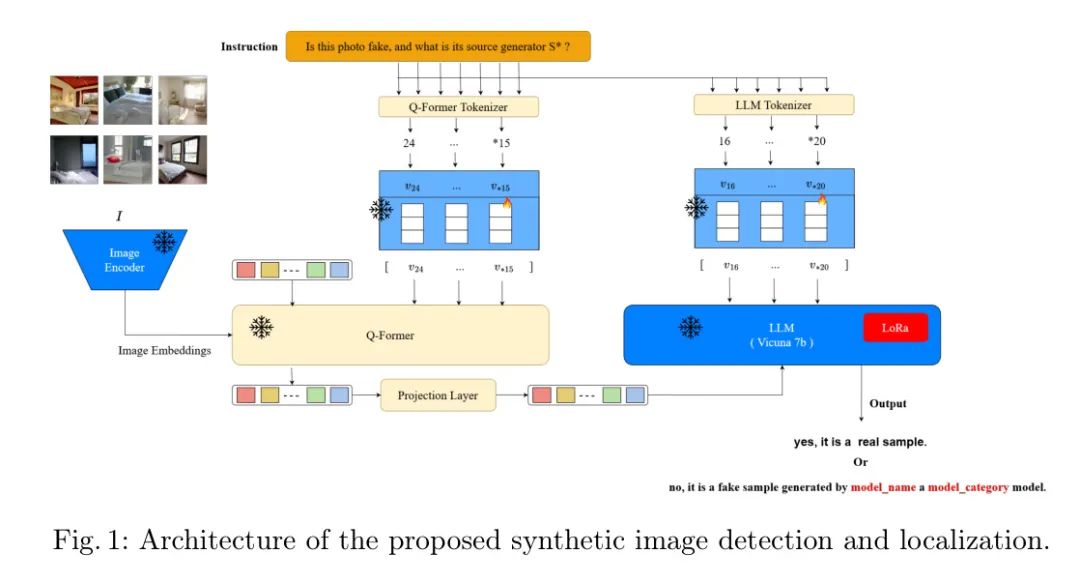
其中是一个具有参数的视觉语言模型,输入图像和问题并生成答案。
作者的研究在InstructBLIP中使用软提示调优,遵循所述的程序。在InstructBLIP中,提示作为输入到两个关键组件:Q-Former和大型语言模型(LLM)。首先,提示经历分词和嵌入后,并行地输入到Q-Former和LLM,如图1所示。为了促进提示调优,作者在提示中引入了一个伪词,作为调优的目标。具体地说,作者采用问题模式"这张照片是虚假的,它的来源生成器是什么?",在提示末尾添加了伪词。因此,调整后的提示为:“这张照片是虚假的,它的来源生成器是什么?”。对于真实图像,作者将输出标签设置为“不,它是一个真实样本。”对于虚假图像,作者将标签设置为“是的,它是一个由模型名称生成的,模型类别模型的虚假样本。”这种标记方案有助于软提示调优。
然后,作者冻结除了与伪词对应的词嵌入之外的所有模型模块,该伪词以随机初始化。接下来,作者使用语言模型损失对伪词在三元训练集上进行优化。作者的目标是使VLM的输出与标签一致。因此,优化目标可以定义为:
其中是语言模型损失函数(交叉熵损失)。
4 Experimental Results
数据集 本文中所使用的数据集是一个经过仔细挑选的图像集合,分为两个主要部分:来自大规模场景理解(LSUN)卧室数据集的真实图像,以及通过三种不同的GAN引擎(ProGAN,StyleGAN,Diff-ProjectedGAN)生成的合成数据,还有三种文本到图像的DM模型(LDM,Glide,Stable diffusion v1.4)。对于每个考虑的GAN,产生了20,000张用于训练的图像和10,000张用于测试的图像,总共产生了90,000张合成图像。同样,每个DM架构也生成了相当于数量相同的图像用于训练和测试,使用“一个卧室的照片”作为提示,从而产生了另外90,000张图像。因此,累积的合成数据集共有180,000张图像。除了合成数据,数据集还包含了130,000张真实图像。值得注意的是,用于测试的真实图像在所有测试子集中都是一致的。
实现细节 作者使用[4]库基于LAVIS图书馆进行实现、训练和评估,该库在GitHub上提供。为了防止小GPU上的内存问题,作者使用了Vicuna-7B作为LLM。对于提示调优,作者从LAVIS中初始化了模型的指令调优预训练权重,仅对虚假词语的嵌入进行微调,而冻结其余模型部分。模型以5个epoch进行提示调优,使用AdamW优化器,β1=0.9,β2=0.999,批量大小16,权重衰减0.05。初始学习率设置为10^-8,使用余弦衰减,最小学习率设置为0。代码在配备16 GB NVIDIA RTX A4500显卡和Intel® i9-12950HX CPU的台式机上运行。在图像处理方面,所有图像均被缩小至较短边224像素,保持原始 aspect ratio。在训练中,随机裁剪形成最终大小224 x 224像素,而在测试中进行居中裁剪到相同大小。
Evaluation Metrics.
在作者的合成图像检测和归因任务中,作者对FIDAVL模型在多个指标上进行评估,包括准确率和F1分数。由于作者无法像二分类一样直接比较文本数据的结果,作者所做的就是计算预测和参照之间的重叠单词。在这方面,作者使用ROUGE分数,它衡量了生成句子内容与参照句子内容之间的对应程度。这些指标的值越高,模型的性能就越好。
Synthetic Image Detection
在这一节中,作者深入分析了这些结果,仔细检查模型在测试集上的性能,并阐明了作者的检测策略的优势。通过全面检查准确性(ACC)和F1分数等指标,作者旨在更深入地了解FIDAVL在合成图像检测任务上的有效性。
表1展示了作者提出的方法FIDAVL的检测能力评估结果。在对所有测试子集的检查中,FIDAVL展现出了强大的性能,始终获得了高准确度和F1分数。值得注意的是,FIDAVL的平均准确性达到了95.42%,令人印象深刻的F1分数达到了95.47%,这进一步强调了它准确区分手合成图像和真实图像的能力。FIDAVL的有效性可以归因于其创新的 Approach,利用了视觉和语言模态中固有的互补优势。通过无缝集成视觉和语言模型,FIDAVL利用了每个模态内的语义理解,使它能够区分出合成图像生成的细微线索和模式。这强调了跨学科方法在解决合成图像检测等复杂挑战中的重要性。
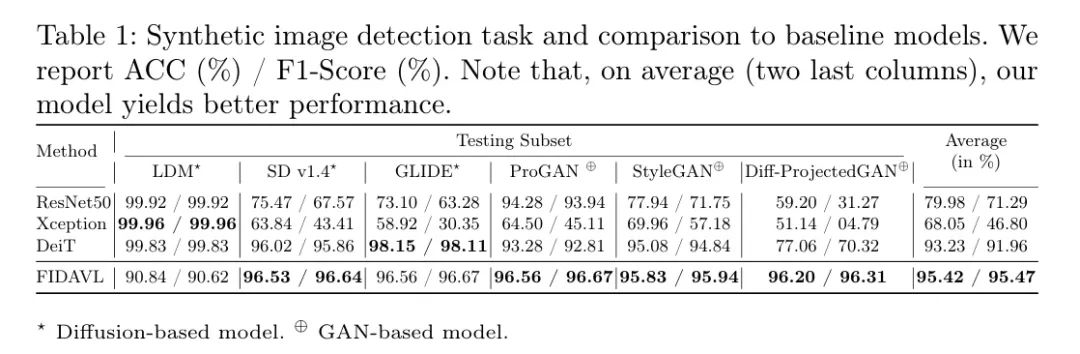
图2提供了FIDAVL在区分合成图像样本与真实图像样本方面的性能概述。每个子图分别对应于特定测试子集的混淆矩阵,并相应地进行了标记。对所有子集,观察到一致的假阴性率为688,这强调了准确检测合成图像的共同挑战。值得注意的是,在滑翔和progan子集中,所有合成图像都被正确检测。然而,FIDAVL在准确检测LDM生成的图像方面遇到挑战,如大量真实阳性,总计达到1144。这一困难可以归因于作者特定的卧室图像数据集的均匀性,这可能对检测算法构成挑战。
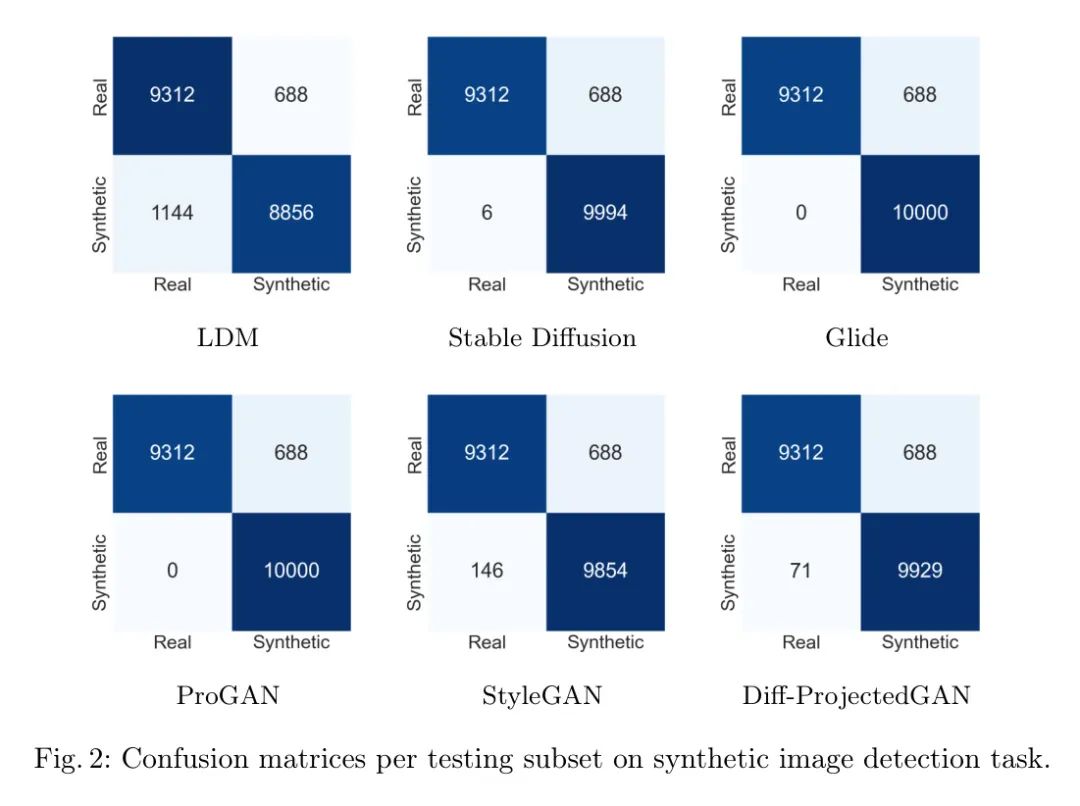
图3提供了关于识别准确为合成图像的合成图像在GAN基础模型或以上扩散基础模型中所属类别分布的分析。在图2中,作者从LDM混淆矩阵观察到8856张合成图像被准确识别。此外,在图3中,LDM混淆矩阵说明了这些图像按其分配到的相应生成器源模型类型分布,8266张归类为扩散,590张归类为GAN。图3表明,尽管图像已被准确识别为合成,但FIDAVL在准确将这些图像归类到其具体的原生模型类型方面遇到了困难,尤其值得注意的是与GAN基础模型和LDM。此外,在稳定扩散和glide上表现最好。
在本小节中,作者对FIDAVL与三个基准模型:ResNet50、Xception和DeiT进行了比较分析。为了建立作者的基准模型,作者通过替换这些架构中的最终全连接层,使用一个新的包含一个用于区分真实图像和虚假图像的全连接层来微调这些架构。这些模型最初使用来自ImageNet数据集的预训练权重进行初始化,从而利用其学习中编码的知识。
作者对这些模型的性能在每个测试子集(包括LDM、SD v1.4、GLIDE、ProGAN、StyleGAN和Diff-ProjectedGAN)上进行了评估。
作者将这些子集的平均性能汇总,以提供对模型效果的全面视角。表1总结了实验的结果。在LDM子集上,ResNet50表现出色,具有99.92%的准确度和99.92%的F1分数,并在其他子集上保持良好的性能,平均准确度为79.98%,F1分数为71.29%。Xception在LDM子集上表现相当,但在其他子集上显著下降,平均准确度为68.05%,F1分数为46.80%。DeiT在SD v1.4子集和GLIDE子集中表现强大,平均准确度为93.23%,F1分数为91.96%。与其他基准模型相比,FIDAVL在所有子集上都表现出出众的性能,平均准确度为95.42%,F1分数为95.47%。在SD v1.4、ProGAN、StyleGAN和Diff-ProjectedGAN子集中,FIDAVL尤为出色,展现了其与基准模型的抗压能力和竞争力。
总之,作者的方法在测试子集上表现出竞争力的分数,特别是在LDM和GLIDE子集中。值得注意的是,FIDAVL在LDM上的分数约为90.84%,并在其他子集上保持分数在95%以上。FIDAVL采用了一种多任务学习方法,这种方法不仅涉及图像检测(区分真实与虚假),还包括一个旨在识别生成特定图像的模型的任务。这种双重关注训练使得模型的训练任务更加复杂,并可能影响其表现动力学,因为模型必须在多个目标之间平衡学习。
在本小节中,作者对FIDAVL在多个未见的合成图像检测子集(包括ADM、DDPM、IDDPM、PNDM、Diff-StyleGAN2和ProjectedGAN)上的泛化能力进行了评估。每个子集都代表检测任务中不同的特性和挑战,因此可以对FIDAVL的泛化能力进行全面评估。
表2的结果突显了FIDAVL在不同子集上的泛化性能。总体来说,FIDAVL在训练期间对所有未见测试集的泛化表现非常好,平均准确度为86.04%,F1-分数为83.48%。ResNet50在子集上的表现相当温和,在ADM和IDDPM中的表现尤为显著。Xception在子集上的表现有所变化,特别是在ADM、DDPM和IDDPM子集中表现不佳。DeiT的表现类似于Xception,在ADM、DDPM和IDDPM子集中面临挑战。FIDAVL在大多数子集上表现出优越的性能,尤其在DDPM、IDDPM、PNDM和基于GAN的子集(如Diff-StyleGAN2和ProjectedGAN)上表现出优异的表现。
此外,结果揭示了需要进一步研究的模式和考虑因素:
- ADM子集:FIDAVL在准确率为67.35%,F1-score为56.01%,显示出中等性能。
- DDPM子集:使用Vision-Language模型进行虚假图像检测和归因(FIDAVL)实现了令人称赞的准确率86.56%,F1-score为85.61%,表明在检测基于扩散的模型方面有强大的性能。然而,需要更深入的研究来了解处理这种合成图像时可能存在的偏见或限制。
- IDDPM子集:FIDAVL的性能(准确率:81.38%,F1-score:78.91%)表明相对于其他子集,其效果略低,暗示可能存在识别与该子集相关特定特性的挑战,并需要进一步研究模型的适应性。
- PNDM子集:FIDAVL的性能(准确率:94.93%,F1-score:95.02%)显示出在检测某些基于扩散的模型方面具有强大的性能。此外,这突显了其优势,但提高了其对所有扩散变体的通用性的疑问。
- Diff-StyleGAN2子集:FIDAVL在检测GAN模型方面取得了高准确率(96.25%)和高F1-score(96.36%)。虽然这一成就强调了FIDAVL确定该特定GAN架构的能力,但有必要在更广泛的GAN变体范围内评估其性能。
- ProjectedGAN子集:FIDAVL在准确率(96.38%)和F1-score(96.49%)方面表现出色,显示了FIDAVL准确检测由ProjectedGAN模型生成的图像的能力。
尽管FIDAVL表现出令人鼓舞的性能,但一个相当关键的方面需要进行更深入的研究。FIDAVL在某些子集上的卓越性能引发了关于其专注于特定模型特性还是更广泛的合成图像检测的疑问。然而,模型特异性和普适性的平衡对于其真实世界的应用至关重要。这些结果强调了FIDAVL在处理由未见模型生成的多样化合成图像数据集的有效性。其卓越性能表示其在广义合成图像变体上的强适应性,这对实际应用至关重要,其中模型必须适应不断变化的合成数据源。
Synthetic Image Attribution
在本节中,作者使用ROUGE分数作为指标来评估FIDAVL在合成图像归因任务中的性能,并结合了标准分类指标,如准确性和F1分数。如3.1小节所述,FIDAVL生成文本作为输出。ROUGE分数被认为是文本生成任务中广泛使用的指标。这些分数主要通过与参考文本进行比较来评估机器生成文本的质量,测量文本相似性的各种方面,如n-gram(连续词组)。此外,准确性和F1分数的包含为FIDAVL在合成图像归因任务中的性能提供了全面的了解。在作者的实验中,作者使用了两个ROUGE分数:ROUGE-2和ROUGE-L。
表3呈现了FIDAVL在不同测试集(根据其基础体系结构分类:扩散模型(LDM、Stable Diffusion v1.4、GLIDE)和GAN模型(ProGAN、StyleGAN、Diff-ProjectedGAN))中对合成图像归因任务的全面评估。使用的评估指标是ROUGE-2、ROUGE-L、准确性和F1分数,测量不同测试子集。
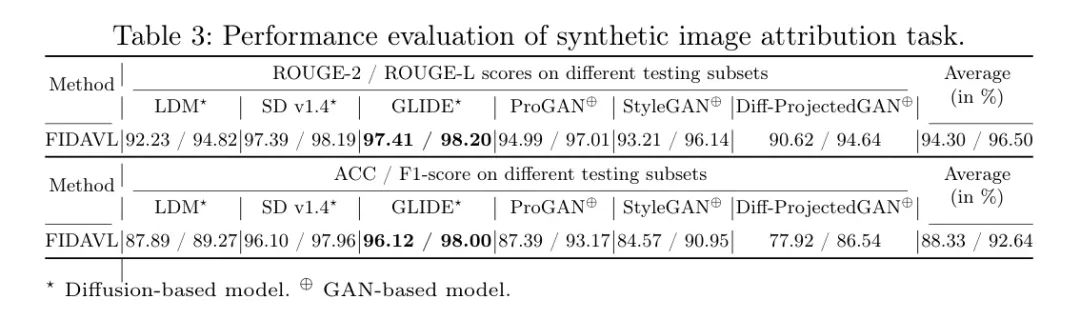
首先,结果表明在对基于扩散的模型(与GAN基模型相比),在ROUGE分数、准确性和F1分数方面,FIDAVL表现出竞争性能。特别是,Stable Diffusion v1.4和GLIDE比ProGAN、StyleGAN和Diff-ProjectedGAN实现了更高的ROUGE分数、准确性和F1分数。这种变化突显了FIDAVL对不同体系结构模型固有特性的敏感性,可能暗示了该模型在特定图像生成范式上的熟练程度。
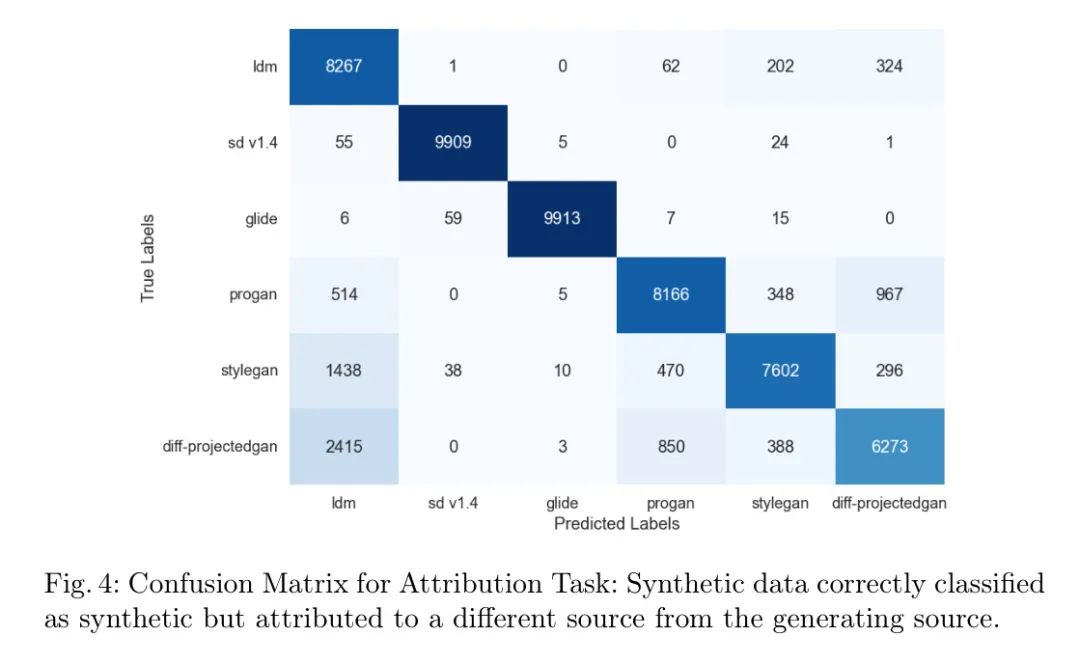
图4说明了各种生成模型准确分类的合成图像的分布。对角线元素(True Positive)表示每个类别正确预测的数量。值得注意的是,FIDAVL在稳定扩散和GLIDE上表现尤为出色,分别有9909和9913个实例被正确分类。然而,矩阵也揭示了令人担忧的方面。FIDAVL在准确归因GAN生成图像到其特定源模型方面遇到困难。许多GAN生成图像错误地归因到LDM和其他GAN生成模型。这可能归因于无条件扩散模型(如LDM)与基于GAN的生成模型的相似性,这给准确归因带来了挑战。
5 Conclusion and Future Work
在本文中提出了FIDAVL,这是一个新颖的多任务框架,用于检测和归因AI生成的图像,利用视觉-语言模型。通过整合视觉和语言模态,FIDAVL在准确识别和将AI生成的图像归因于其相应的源模型方面表现出了卓越的性能。
广泛的实验验证了FIDAVL在同时解决合成图像检测和归因挑战方面的有效性。作者的研究强调了在当今快速发展的技术领域中,采用跨学科方法解决复杂问题的重要性。
凭借其出色的性能,FIDAVL为增强在虚假图像泛滥背景下的可问责性和信任提供了有价值的解决方案。在未来的努力中,计划进行额外的实验,以评估FIDAVL在现实世界场景中的鲁棒性和泛化能力。
这包括探索涉及JPEG压缩、缩放、来自新生成模型的未见图像以及添加噪声的场景。