一、前言
Kafka提供了高性能的读写,而这些读写操作均是操作在Topic上的,Topic的创建就尤为关键,其中涉及分区分配策略、状态流转等,而Topic的新建语句非常简单
bash kafka-topics.sh \
--bootstrap-server localhost:9092 \ // 需要写入endpoints
--create --topic topicA // 要创建的topic名称
--partitions 10 // 当前要创建的topic分区数
--replication-factor 2 // 副本因子,即每个TP创建多少个副本因此Topic的创建可能并不像表明上操作的那么简单,这节我们就阐述一下Topic新建的细节
以下论述基于Kafka 2.8.2版本
二、整体流程
Topic新建分2部分,分别是
- 用户调用对应的API,然后由Controller指定分区分配策略,并将其持久化至Zookeeper中
- Controller负责监听Zookeeper的回调函数拿到元数据变更后,触发状态机并真正执行副本分配
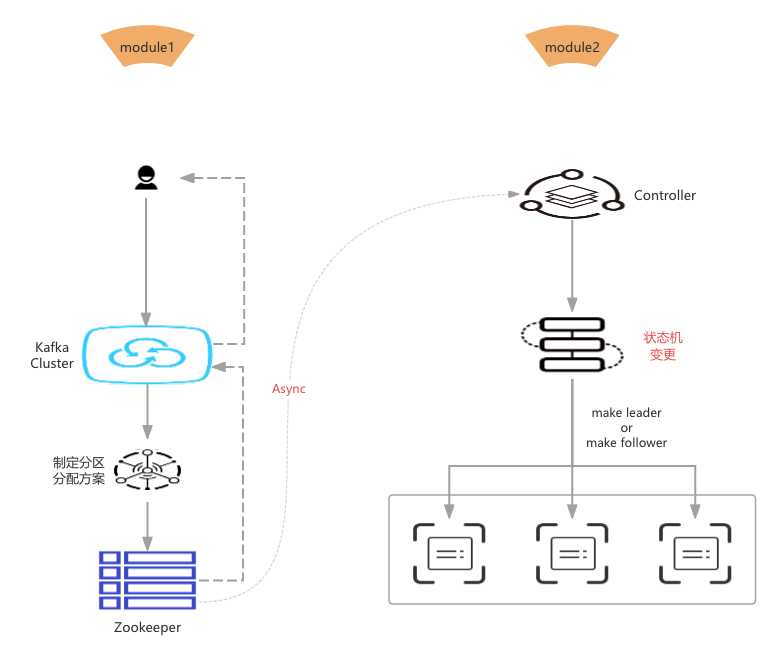
用户发起一个Topic新建的请求,Controller收到请求后,开始制定分区分配方案,继而将分配方案持久化到Zookeeper中,然后就向用户返回结果
而在Controller中专门监听Zookeeper节点变化的线程(当然这个线程与创建Topic的线程是异步的),当发现有变更后,将会异步触发状态机进行状态流转,后续会将对应的Broker设置为Leader或Follower
三、Topic分区分配方案
在模块一中,主要的流程是3部分:
- 用户向Controller发起新增Topic请求
- Controller收到请求后,开始制定该Topic的分区分配策略
- Controller将制定好的策略持久化至Zookeeper中
而上述描述中,流程1、3都是相对好理解的,我们着重要说的是流程2,即分区分配策略。Kafka分区制定方案核心逻辑放在 scala/kafka/admin/AdminUtils.scala 中,分为无机架、有机架两种,我们核心看一下无机架的策略
无机架策略中,又分为Leader Replica及Follow Replica两种
3.1、Leader Partition
而关于Leader及Follower的分配策略统一在方法kafka.admin.AdminUtils#assignReplicasToBrokersRackUnaware中,此方法只有20多行,我们简单来看一下
private def assignReplicasToBrokersRackUnaware(nPartitions: Int, // 目标topic的分区总数
replicationFactor: Int, // topic副本因子
brokerList: Seq[Int], // broker列表
fixedStartIndex: Int, // 默认情况传-1
startPartitionId: Int /* 默认情况传-1 */): Map[Int, Seq[Int]] = {
val ret = mutable.Map[Int, Seq[Int]]()
val brokerArray = brokerList.toArray
// leader针对broker列表的开始index,默认会随机选取
val startIndex = if (fixedStartIndex >= 0) fixedStartIndex else rand.nextInt(brokerArray.length)
// 默认为0,从0开始
var currentPartitionId = math.max(0, startPartitionId)
// 这个值主要是为分配Follower Partition而用
var nextReplicaShift = if (fixedStartIndex >= 0) fixedStartIndex else rand.nextInt(brokerArray.length)
// 这里开始对partition进行循环遍历
for (_ <- 0 until nPartitions) {
// 这个判断逻辑,影响follower partition
if (currentPartitionId > 0 && (currentPartitionId % brokerArray.length == 0))
nextReplicaShift += 1
// 当前partition的第一个replica,也就是leader
// 由于startIndex是随机生成的,因此firstReplicaIndex也是从broker list中随机取一个
val firstReplicaIndex = (currentPartitionId + startIndex) % brokerArray.length
// 存储了当前partition的所有replica的数组
val replicaBuffer = mutable.ArrayBuffer(brokerArray(firstReplicaIndex))
for (j <- 0 until replicationFactor - 1)
replicaBuffer += brokerArray(replicaIndex(firstReplicaIndex, nextReplicaShift, j, brokerArray.length))
ret.put(currentPartitionId, replicaBuffer)
currentPartitionId += 1
}
ret
}由此可见,Topic Leader Replica的分配策略是相对简单的,我们再简单概括一下它的流程
- 从Broker List中随机选取一个Broker,作为 Partition 0 的 Leader
- 之后开始遍历Broker List,依次创建Partition 1、Partition 2、Partition 3....
- 如果遍历到了Broker List末尾,那么重定向到0,继续向后遍历
假定我们有5个Broker,编号从1000开始,分别是1000、1001、1002、1003、1004,假定partition 0随机选举的broker是1000,那么最终的分配策略将会是如下:
| Broker | 1000 | 1001 | 1002 | 1003 | 1004 |
| Leader Partition | 0 | 1 | 2 | 3 | 4 |
| 5 | 6 | 7 | 8 | 9 |
而假定partition 0随机选举的broker是1002,那么最终的分配策略将会是如下:
| Broker | 1000 | 1001 | 1002 | 1003 | 1004 |
| Leader Partition | 3 | 4 | 0 | 1 | 2 |
| 8 | 9 | 5 | 6 | 7 |
这样做的目的是将Partition尽可能地打乱,将Partition Leader分配到不同的Broker上,避免数据热点
然而这个方案也并不是完美的,它只是会将当前创建的Topic Partition Leader打散,并没有考虑其他Topic Partition的分配情况,假定我们现在创建了5个Topic,均是单分区的,而正好它们都落在Broker 1000上,下一次我们创建新Topic的时,它的Partition 0依旧可能落在Broker 1000上,造成数据热点。不过因为是随机创建,因此当Topic足够多的情况时,还是能保证相对离散
3.2、Follower Partition
Leader Replica已经确定下来,接下来就是要制定Follower的分配方案,Follower的分配方案至少要满足以下2点要求
- Follower要随机打散在不同的Broker上,主要是做高可用保证,当Leader Broker不可用时,Follower要能顶上
- Follower的分配还不能太随机,因为如果真的全部随机分配的话,可能出现某个Broker比其他Broker的replica要多,而这个是可以避免的
Follower Replica的分配逻辑除了上述说的kafka.admin.AdminUtils#assignReplicasToBrokersRackUnaware方法外,很重要的一个方法是kafka.admin.AdminUtils#replicaIndex
private def replicaIndex(
firstReplicaIndex: Int, // 第一个replica的index,也就是leader index
secondReplicaShift: Int, // 随机shift,范围是[0, brokerList.length),每隔brokerList.length,将+1
replicaIndex: Int, // 当前follower副本编号,从0开始
nBrokers: Int): Int = { // broker数量
val shift = 1 + (secondReplicaShift + replicaIndex) % (nBrokers - 1)
(firstReplicaIndex + shift) % nBrokers
}其实这个方法只有2行,不过这2行代码相当晦涩,要理解它不太容易,而且在2.8.2版本中没有对其的注释,我特意翻看了当前社区的最新版本3.9.0-SNAPSHOT,依旧没有针对这个方法的注释。不过我们还是需要花点精力去理解它的
第一行
val shift = 1 + (secondReplicaShift + replicaIndex) % (nBrokers - 1)
这行代码的作用是生成一个随机值shift,因此shift的范围是 0 <= shift < nBrokers,而随着replicaIndex的增加,shift也会相应增加,当然这样做的目的是为第二行代码做铺垫
当然shift的值,只会与secondReplicaShift、replicaIndex相关,与partition无关
第二行
(firstReplicaIndex + shift) % nBrokers
这样代码就保证了生成的follower index不会与Leader index重复,并且所有的follower index是向前递增的
总结一下分配的规则:
- 随机从Broker list中选择一个作为第一个follower的起始位置(由变量secondReplicaShift控制)
- 后续的follower均基于步骤1的起始位置,依次向后+1
- follower的位置确保不会与Leader冲突,如果冲突则向后顺延一位(由
(firstReplicaIndex + shift) % nBrokers进行控制) - 并非当前Topic的所有的partition均采用同一步调,一旦(
PartitionNum%BrokerNum == 0),secondReplicaShift将会+1,导致第一个follower的起始位置+1,这样就更加离散
我们看一个具体case:
| Broker | 1000 | 1001 | 1002 | 1003 | 1004 |
| Leader | 0 | 1 | 2 | 3 | 4 |
| 5 | 6 | 7 | 8 | 9 | |
| Follower 1 | 1 | 2 | 3 | 4 | 0 |
| 9 | 5 | 6 | 7 | 8 | |
| Follower 2 | 4 | 0 | 1 | 2 | 3 |
| 8 | 9 | 5 | 6 | 7 |
- Partition 1:Leader在1001上,而2个Follower分别在1000、1002上。很明显,Follower是从1000开始往后遍历寻找的,因此2个Follower的分布本来应该是1000、1001,但1001正好是Leader,因此往后顺移,最终Follower的分布也就是【1000、1002】
-
- 此处注意:为什么“Follower是从1000开始往后遍历”? 这个就与kafka.admin.AdminUtils#replicaIndex方法中的shift变量有关,而shift则是由随机变量secondReplicaShift而定的,因此“1000开始往后遍历”是本次随机运行后的一个结果,如果再跑一次程序,可能结果就不一致了
- Partition 3:再看分区3,Leader在1003上,Follower是从1002开始的,因此Follower的分布也就是【1002、1004】
- Partition 7:因为从partition 5开始,超过了broker的总数,因此变量secondReplicaShift++,导致Follower的起始index也+1,因此Follower的分布是【1003、1004】
为什么要费尽九牛二虎之力,做这么复杂的方案设定呢?直接将Leader Broker后面的N个Broker作为Follower不可以吗?其实自然是可以的,不过可能带来一些问题,比如如果Leader宕机后,这些Leader Partition都会飘到某1个或某几个Broker上,这样可能带来一些热点隐患,导致存活的Broker不能均摊这些流量
3.3、手动制定策略
当然上述是Kafka帮助我们自动制定分区分配方案,另外我们可以手动制定策略:
bash kafka-topics.sh \
--bootstrap-server localhost:9092 \
--create --topic topicA \
--replica-assignment 1000,1000,1000,1000,1000按照上述的命令创建Topic,我们会新建一个名称为“topicA”的主题,它有5个分区,全部都创建在ID为1000的Broker上
另外Kafka还支持机架(rack)优先的分区分配方案,即尽量将某个partition的replica均匀地打散至N个rack中,这样确保某个rack不可用后,不影响这个partition整体对外的服务能力。本文不再对这种case进行展开
四、状态机
在分区分配方案制定完毕后,Controller便将此方案进行编码,转换为二进制的byte[],进而持久化到ZooKeeper的路径为/topics/topicXXX(其中topicXXX就是topic名称)的path内,而后便向用户返回创建成功的提示;然而真正创建Topic的逻辑并没有结束,Controller会异步执行后续创建Topic的操作,源码中逻辑写的相对比较绕,不过不外乎做了以下两件事儿:
- 更新元数据并通知给所有Brokers
- 向各个Broker传播ISR,并对应执行Make Leader、Make Follower操作
而实现上述操作则是通过两个状态机:
PartitionStateMachine.scala分区状态机ReplicaStateMachine.scala副本状态机
Controll收到ZK异步通知的入口为 kafka.controller.KafkaController#processTopicChange
4.1、分区状态机
即一个partition的状态,对应的申明类为kafka.controller.PartitionState,共有4种状态:
- NewPartition 新建状态,其实只会在Controll中停留很短的时间,继而转换为OnlinePartition
- OnlinePartition 在线状态,只有处于在线状态的partition才能对外提供服务
- OfflinePartition 下线状态,比如Topic删除操作
- NonExistentPartition 初始化状态,如果新建Topic,partition默认则为此状态
转换关系如下
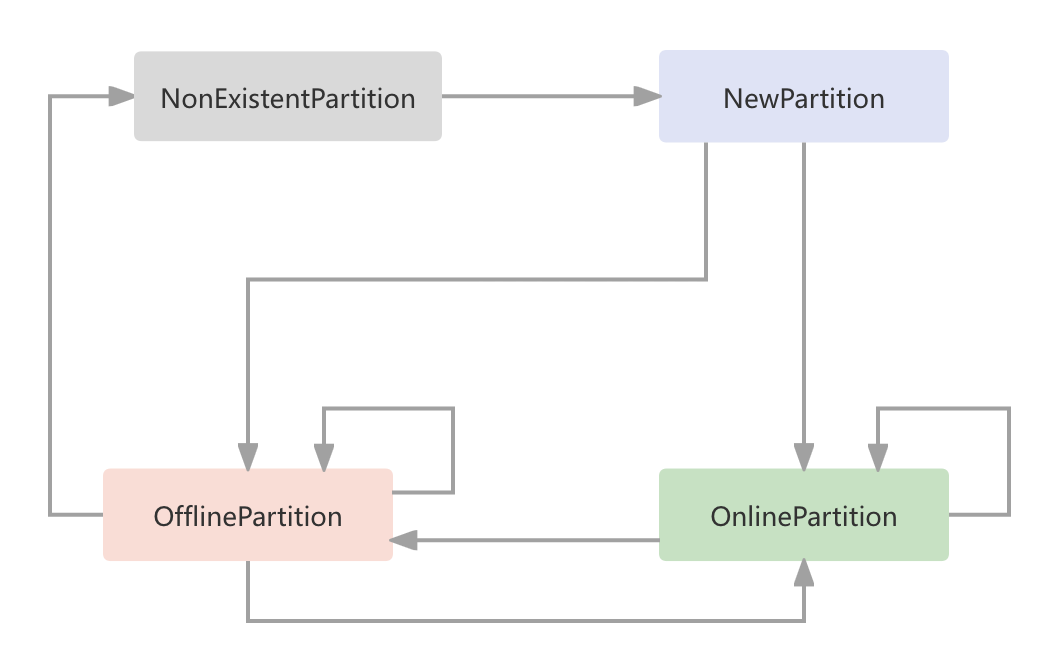
本文只讨论新建Topic时,状态转换的过程,因此只涉及
- NonExistentPartition -> NewPartition
- NewPartition -> OnlinePartition
4.2、副本状态机
所谓副本状态机,对应的申明类为kafka.controller.ReplicaState,共有7种状态:NewReplica、OnlineReplica、OfflineReplica、ReplicaDeletionStarted、ReplicaDeletionSuccessful、ReplicaDeletionIneligible、NonExistentReplica。在Topic新建的流程中,我们只会涉及其中的3种:NewReplica、OnlineReplica、NonExistentReplica,且副本状态机在新建流程中发挥的空间有限,不是本文的重点,读者对其有个大致概念即可
4.3、状态流转
首先要确认一点,Kafka的Controller是单线程的,所有的事件均是串行执行,以下所有的操作也均是串行执行
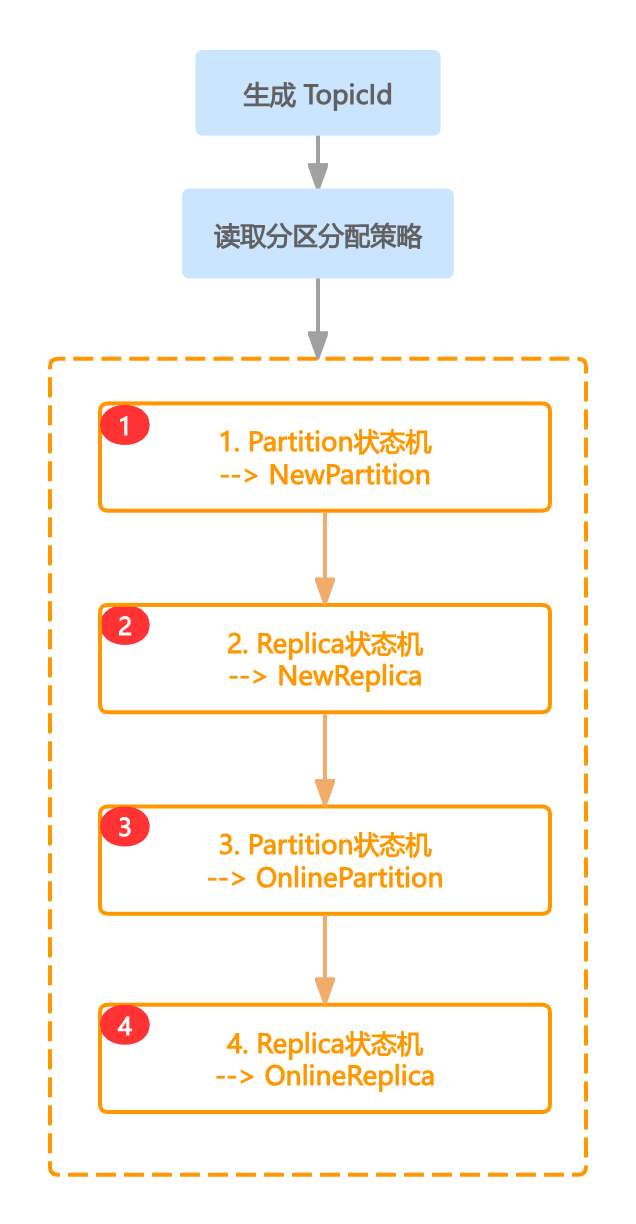
在真正执行状态流转前,需要执行2个前置步骤
- 生产Topic ID。为新建的Topic生产唯一的TopicID,具体实现方法位置在
kafka.zk.KafkaZkClient#setTopicIds内,其实就是简单调用org.apache.kafka.common.Uuid#randomUuid来生成一个随机串 - 读取分区分配策略。接着从zk(存储路径为
/brokers/topics/topicName)中读取这个Topic的分区分配策略,然后将分区分配策略放进缓存中,缓存的位置为kafka.controller.ControllerContext#partitionAssignments
上述两个步骤其实没啥好说的,只是为状态流转做一些前置铺垫。接下来就要进入主方法的逻辑中了,即kafka.controller.KafkaController#onNewPartitionCreation,可简单看一下此方法,主要执行4部分内容
-
- partition状态机将状态设置为NewPartition
- replica状态机降状态置为NewReplica
- partition状态机将状态设置为OnlinePartition
- replica状态机降状态置为OnlineReplica
// kafka.controller.KafkaController#onNewPartitionCreation
private def onNewPartitionCreation(newPartitions: Set[TopicPartition]): Unit = {
info(s"New partition creation callback for ${newPartitions.mkString(",")}")
partitionStateMachine.handleStateChanges(newPartitions.toSeq, NewPartition)
replicaStateMachine.handleStateChanges(controllerContext.replicasForPartition(newPartitions).toSeq, NewReplica)
partitionStateMachine.handleStateChanges(newPartitions.toSeq, OnlinePartition, Some(OfflinePartitionLeaderElectionStrategy(false)))
replicaStateMachine.handleStateChanges(controllerContext.replicasForPartition(newPartitions).toSeq, OnlineReplica)
}4.3.1、Partition状态机NewPartition
partition状态机将状态设置为NewPartition。这一步就是维护kafka.controller.ControllerContext#partitionStates内存变量,将对应partition的状态设置为NewPartition,其他什么都不做
4.3.2、Replica状态机NewReplica
replica状态机降状态置为NewReplica。这一步是维护kafka.controller.ControllerContext#replicaStates内存变量,将replica状态设置为NewReplica
4.3.3、Partition状态机OnlinePartition
这一步也是整个状态机流转中的核心部分,共分为以下5大步:
- 初始化Leader、ISR等信息,并将这些信息暂存至zk中
-
- 创建topic-partition在zk中的路径,path为/brokers/topics/topicName/partitions
- 为每个partition创建路径,path为/brokers/topics/topicName/partitions/xxx,例如
-
-
- /brokers/topics/topicName/partitions/0
- /brokers/topics/topicName/partitions/1
- /brokers/topics/topicName/partitions/2
-
-
- 将Leader及ISR的信息持久化下来,path为/brokers/topics/topicName/partitions/0/state
- 而后将Leader、ISR等已经持久化到zk的信息放入缓存
kafka.controller.ControllerContext#partitionLeadershipInfo中 - 因为Leader、ISR这些元数据发生了变化,因此将这些信息记录下来,放在内存结构
kafka.controller.AbstractControllerBrokerRequestBatch#leaderAndIsrRequestMap中,表明这些信息是需要同步给对应的Broker的 - 维护
kafka.controller.ControllerContext#partitionStates内存变量,将状态设置为OnlinePartition - 调用接口ApiKeys.LEADER_AND_ISR,向对应的Broker发送数据,当Broker接收到这个请求后,便会执行MakeLeader/MakeFollower相关操作
4.3.4、Replica状态机OnlineReplica
replica状态机降状态置为OnlineReplica。维护kafka.controller.ControllerContext#replicaStates内存变量,将状态设置为OnlineReplica
至此,一个 Kafka Topic 才算是真正被创建出来