1 学习目标
- 重点掌握聚合函数的使用
- 重点掌握字段别名
- 重点掌握分组查询的语法
- 重点掌握having的使用方法
- 了解子查询的语法
- 重点掌握排序查询语法
2 排序查询
2.1 语法
SELECT
要查询的东西
FROM
表
WHERE
条件
ORDER BY 排序的字段|表达式|函数|别名 [ASC|DESC]- ASC 升序(默认)(从小到大) ascend
- DESC 降序(从大到小) descend
2.2 例子
①员工薪水升序排列
SELECT employee_id, first_name, salary
FROM employees
ORDER BY salary;②按部门升序,相同部门按工资降序
SELECT employee_id, first_name, salary, department_id
FROM employees
ORDER BY department_id ASC, salary DESC;2.3 小练习
①50部门的员工,按工资降序排列
SELECT employee_id,first_name,salary,department_id
FROM employees
WHERE department_id = 50
ORDER BY salary DESC;②岗位后缀是'CLERK',按主管id排序,相同主管按工资降序
SELECT employee_id,first_name,salary,job_id,manager_id
FROM employees
WHERE job_id LIKE '%CLERK'
ORDER BY manager_id ASC, salary DESC;3 别名
3.1 表别名
3.1.1 特点
-
使用 MySQL 查询时,当表名很长或者执行一些特殊查询的时候,为了方便操作或者需要多次使用相同的表时,可以为表指定别名,用这个别名代替表原来的名称。
-
在为表取别名时,要保证不能与数据库中的其他表的名称冲突
3.1.2 语法格式
<表名> [AS] <别名>
- <表名>:数据中存储的数据表的名称
- <别名>:查询时指定的表的新名称
- AS:关键字为可选参数
3.1.3 例子
①查询出部门信息
SELECT d.department_id,d.department_name,d.location_id,d.manager_id
FROM departments AS d;
或者
SELECT d.department_id,d.department_name,d.location_id,d.manager_id
FROM departments d;3.2 字段别名
3.2.1 特点
- 在使用 SELECT 语句显示查询结果时,MySQL 会显示每个 SELECT 后面指定输出的列,在有些情况下,显示的列名称会很长或者名称不够直观,MySQL 可以指定列的别名,替换字段或表达式
- 在where 中不能使用字段别名
- order by 可以使用字段别名
3.2.2 语法格式
<列名> [AS] <列别名>- <列名>:为表中字段定义的名称。
- <列别名>:字段新的名称。
- AS:关键字为可选参数
3.2.3 例子
①计算出每个员工的年薪
SELECT employee_id 员工id,first_name 姓,salary 薪资,salary*12 年薪
FROM employees
WHERE salary*12>=120000
ORDER BY 年薪 DESC;4 多行函数(聚合函数)
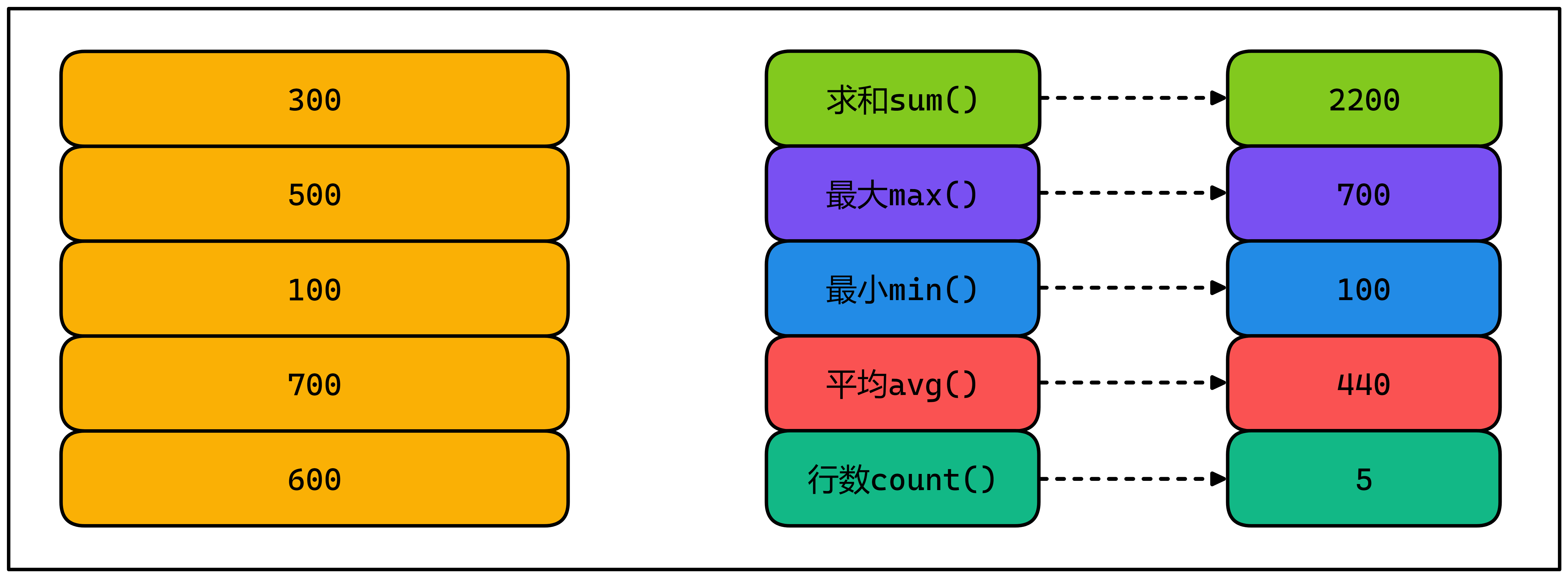
4.1 特点
- 多行数据,运算产生一行结果
-
多行函数,不能和其他普通字段一起查询
- 其他数据库会禁止执行
- mysql可以执行,只是把第一条数据显示出来
-
多行函数可以一起查询
-
多行函数会忽略null值
-
count(a)对指定字段的值计数,重复值会重复计数
-
可以用distinct去除重复
-
count() 计算行数
-
count(*) 数据量大时(千万),效率低
4.2 例子
①查询全体员工的平均薪资
SELECT AVG(salary) 平均薪资 FROM employees; 注意:但是注意,不能和其他字段一起查询
SELECT AVG(salary),employee_id,first_name FROM employees; mysql可以执行,只是把第一条数据显示出来,容易造成误解

②查询全体员工的薪资总和,平均薪资,最大薪资,最低薪资,人员数量(多行函数可以一起查询)
SELECT SUM(salary) 薪资总和,AVG(salary) 平均薪资,MAX(salary) 最大薪资,MIN(salary) 最低薪资,COUNT(salary) 人员数量
FROM employees;③查询commission_pct字段非null值的总数(多行函数会忽略null值)
SELECT COUNT(commission_pct),COUNT(*)
FROM employees;④共有多少个工作岗位(可以用distinct去除重复)
SELECT COUNT(DISTINCT job_id)
FROM employees;⑤50部分的人数
SELECT COUNT(*)
FROM employees
WHERE department_id=50;5 分组查询
5.1 含义
- 按指定字段,相同的值,分组计算
5.2 语法
SELECT 查询的字段,分组函数
FROM 表
GROUP BY 分组的字段5.3 特点
- 可以按单个字段分组
- 和分组函数一同查询的字段最好是分组后的字段
- 可以按多个字段分组,字段之间用逗号隔开
- 可以支持排序
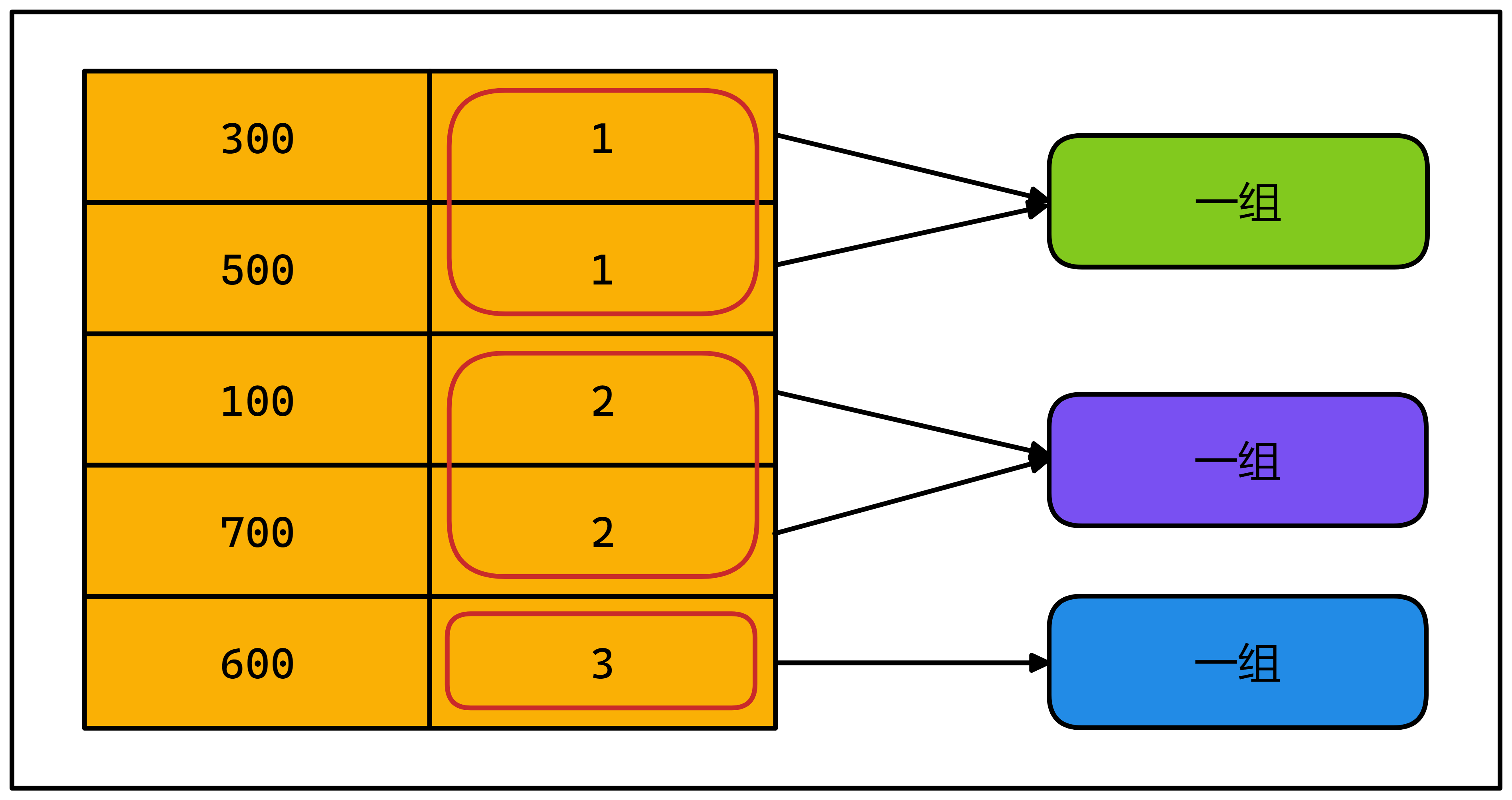
5.4 例子
①每个部门的人数(分组字段,可以和多行函数一起查询)
SELECT department_id, COUNT(*)
FROM employees
WHERE department_id IS NOT NULL
GROUP BY department_id;②每个工作岗位的最高工资
SELECT job_id,MAX(salary)
FROM employees
GROUP BY job_id;③每个部门中,每个岗位的人数,按人数排序
SELECT department_id,job_id,COUNT(*) c
FROM employees
WHERE department_id IS NOT NULL
GROUP BY department_id,job_id
ORDER BY c;6 HAVING
6.1 含义
- having对分组求出的多行函数结果进行过滤
6.2 where和having
- where最先执行,只能过滤普通条件
- having分组计算完多行函数之后,执行过滤
- having也可以过滤普通条件,但不应该这样做
| 针对的表 | 位置 | 关键字 | |
|---|---|---|---|
| 分组前筛选 | 原始表 | group by的前面 | where |
| 分组后筛选 | 分组后的结果集 | group by的后面 | having |
6.3 例子
①只有一个人的部门
SELECT department_id, COUNT(*) c
FROM employees
WHERE department_id IS NOT NULL
GROUP BY department_id
HAVING c=1;②平均工资大于8000的工作岗位
SELECT job_id,AVG(salary) s
FROM employees
GROUP BY job_id
HAVING s>8000
ORDER BY s DESC;7 子查询
7.1 含义
- 一条查询语句中又嵌套了另一条完整的select语句,其中被嵌套的select语句,称为子查询或内查询 在外面的查询语句,称为主查询或外查询,简单理解,就是将一个查询的结果,作为另一个查询的过滤条件
7.2 特点
- 子查询都放在小括号内
- 子查询可以放在from后面、select后面、where后面、having后面,但一般放在条件的右侧
- 子查询优先于主查询执行,主查询使用了子查询的执行结果
- 子查询根据查询结果的行数不同分为单行子查询和多行子查询
7.3 单行子查询
7.3.1 特点
- 结果集只有一行
- 一般搭配单行操作符使用:> < = <> >= <=
- 非法使用子查询的情况:
- 子查询的结果为一组值
- 子查询的结果为空
7.3.2 例子
①拿最低工资的所有员工
SELECT employee_id,first_name,salary
FROM employees
WHERE salary=(
SELECT MIN(salary) FROM employees
);②工资低于平均工资的员工
SELECT employee_id, first_name, salary
FROM employees
WHERE salary<(
SELECT AVG(salary) FROM employees
)
ORDER BY salary DESC;7.4 多行子查询
7.4.1 特点
- 结果集有多行
- in: 属于子查询结果中的任意一个就行
7.4.2 例子
①只有一个人的部门中的员工
SELECT employee_id,first_name,salary,department_id
FROM employees
WHERE department_id IN(
SELECT department_id
FROM employees
WHERE department_id IS NOT NULL
GROUP BY department_id
HAVING COUNT(*)=1
);②每个部门中,拿最低工资的员工
SELECT employee_id,first_name,department_id,salary
FROM employees
WHERE (department_id,salary) IN(
SELECT department_id,MIN(salary)
FROM employees
WHERE department_id IS NOT NULL
GROUP BY department_id
)
ORDER BY department_id;8 总结
-
什么是分组查询?
按指定字段,相同的值,分组计算
-
是什么是子查询?
一条查询语句中又嵌套了另一条完整的select语句,其中被嵌套的select语句,称为子查询或内查询
-
将查询的结果进行排序怎么做?
SELECT 要查询的东西 FROM 表 WHERE 条件 ORDER BY 排序的字段|表达式|函数|别名 [ASC|DESC]上一篇文章:SQL的高级查询练习知识点(day24)-CSDN博客
 https://blog.csdn.net/Z0412_J0103/article/details/141713435下一篇文章:SQL的高级查询练习知识点下(day26)-CSDN博客https://blog.csdn.net/Z0412_J0103/article/details/141806035
https://blog.csdn.net/Z0412_J0103/article/details/141713435下一篇文章:SQL的高级查询练习知识点下(day26)-CSDN博客https://blog.csdn.net/Z0412_J0103/article/details/141806035