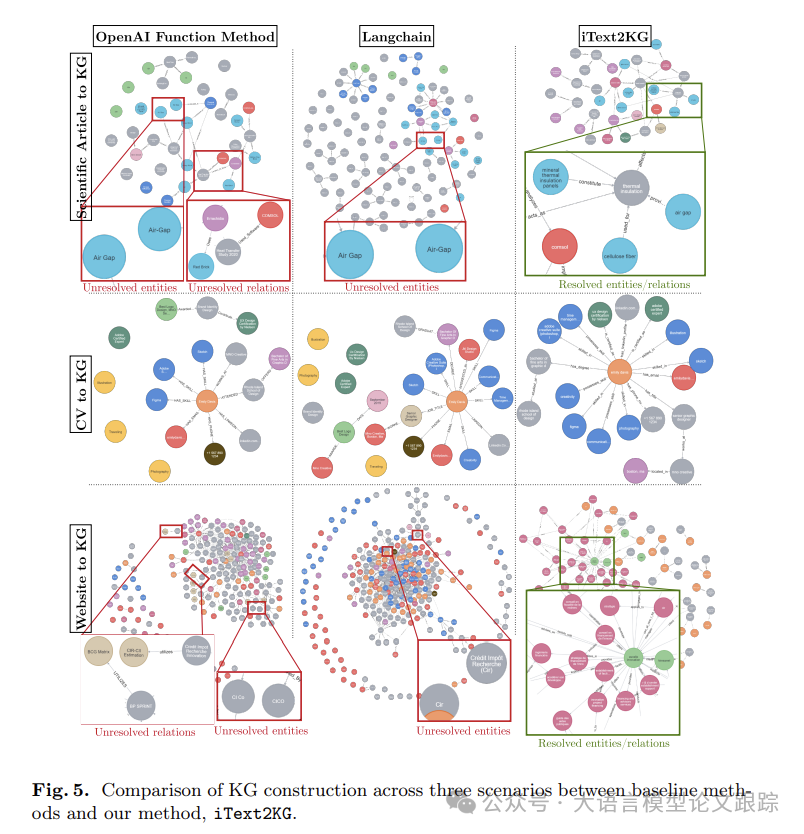
一、分类问题
利用一条直线分类存在很多问题
二、SVM 支持向量机
其核心思想是通过在特征空间中找到一个最优的超平面来进行分类,并且间隔最大。分类面尽可能远离样本点,宽度越大越好。

适用于中小型复杂数据集的分类。
三、硬间隔和软间隔
硬:严格地让所有实例都不在最大间隔之间,并且位于正确的一边。
软:在保持最大间隔宽阔和限制间隔违例(即位于最大间隔之上,甚至在错误的一边的实例)之间找到良好的平衡。
四、使用SVM作为模型时,通常采用如下流程:
1)对样本数据进行归一化
2)应用核函数对样本进行映射(最常采用和核函数是RBF和Linear,在样本线性可分时,Linear效果要比RBF好)
3)用cross-validation和grid-search对超参数进行优选
4)用最优参数调练得到模型
5)测试
五、原理
SVM通过优化一个凸二次规划问题来求解最佳的超平面。可以理解为是用一个平面
对于非线性可分的情况,SVM可以通过核函数(Kernel Function)将输入特征映射到高维空间,使得原本线性不可分的数据在高维空间中变得线性可分。常用的核函数包括线性核、多项式核、高斯核等。
六、SVM的核函数
核函数:是将原始输入空间映射到新的特征空间,从而,使得原本线性不可分的样本可能在核空间可分。核函数并不是SVM特有的,核函数可以和其他算法也进行结合,只是核函数与SVM结合的优势非常大。
 一个很好的理解空间映射和超平面的例子。
一个很好的理解空间映射和超平面的例子。
常见核函数:
线性核和多项式核:
1)这两种核的作用也是首先在属性空间中找到一些点,把这些点当做base,核函数的作用就是找与该点距离和角度满足某种关系的样本点。
2)样本点与该点的夹角近乎垂直时,两个样本的欧式长度必须非常长才能保证满足线性核函数大于0;而当样本点与base点的方向相同时,长度就不必很长;而当方向相反时,核函数值就是负的,被判为反类。即,它在空间上划分出一个梭形,按照梭形来进行正反类划分。
RBF核:
1)高斯核函数就是在属性空间中找到一些点,这些点可以是也可以不是样本点,把这些点当做base,以这些base为圆心向外扩展,扩展半径即为带宽,即可划分数据。
2)换句话说,在属性空间中找到一些超圆,用这些超圆来判定正反类。
Sigmoid核:
1)同样地是定义一些base,
2)核函数就是将线性核函数经过一个tanh函数进行处理,把值域限制在了-1到1上。
总之,都是在定义距离,大于该距离,判为正,小于该距离,判为负。至于选择哪一种核函数,要根据具体的样本分布情况来确定,以下是使用的指导规则:
1)如果Feature的数量很大,甚至和样本数量差不多时,往往线性可分,这时选用LR或者线性核Linear。
2)如果Feature的数量很小,样本数量正常,不算多也不算少,这时选用RBF核。
3)如果Feature的数量很小,而样本的数量很大,这时手动添加一些Feature,使得线性可分,然后选用LR或者线性核Linear。
4)多项式核一般很少使用,效率不高,结果也不优于RBF。
5)Linear核参数少,速度快;RBF核参数多,分类结果非常依赖于参数,需要交叉验证或网格搜索最佳参数,比较耗时。
6)应用最广的应该就是RBF核,无论是小样本还是大样本,高维还是低维等情况,RBF核函数均适用。
七、SVM损失函数
支持向量机(SVM)在分类问题中使用的损失函数是"hinge loss"(铰链损失),它通常被用于最大间隔分类,即寻找能够最大化分类间隔的超平面。而在SVM中,我们主要讨论三种损失函数:




![动手学深度学习(pytorch)学习记录27-深度卷积神经网络(AlexNet)[学习记录]](https://i-blog.csdnimg.cn/direct/15a0a1f62f5841f2b337e29708b72604.png)