high frequency SQL 50 (basic version) 高頻sql題目(Leetcode)
查詢
1757. 可回收且低脂的产品
Question
表:Products
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| product_id | int |
| low_fats | enum |
| recyclable | enum |
+-------------+---------+
product_id 是该表的主键(具有唯一值的列)。
low_fats 是枚举类型,取值为以下两种 ('Y', 'N'),其中 'Y' 表示该产品是低脂产品,'N' 表示不是低脂产品。
recyclable 是枚举类型,取值为以下两种 ('Y', 'N'),其中 'Y' 表示该产品可回收,而 'N' 表示不可回收。
编写解决方案找出既是低脂又是可回收的产品编号。
返回结果 无顺序要求 。
返回结果格式如下例所示:
示例 1:
输入: Products 表: +-------------+----------+------------+ | product_id | low_fats | recyclable | +-------------+----------+------------+ | 0 | Y | N | | 1 | Y | Y | | 2 | N | Y | | 3 | Y | Y | | 4 | N | N | +-------------+----------+------------+ 输出: +-------------+ | product_id | +-------------+ | 1 | | 3 | +-------------+ 解释: 只有产品 id 为 1 和 3 的产品,既是低脂又是可回收的产品。
Answer
SELECT
product_id
FROM
Products
WHERE
low_fats = 'Y'
AND recyclable = 'Y'
584. 寻找用户推荐人
Question
表: Customer
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| id | int |
| name | varchar |
| referee_id | int |
+-------------+---------+
在 SQL 中,id 是该表的主键列。
该表的每一行表示一个客户的 id、姓名以及推荐他们的客户的 id。
找出那些 没有被 id = 2 的客户 推荐 的客户的姓名。
以 任意顺序 返回结果表。
结果格式如下所示。
示例 1:
输入: Customer 表: +----+------+------------+ | id | name | referee_id | +----+------+------------+ | 1 | Will | null | | 2 | Jane | null | | 3 | Alex | 2 | | 4 | Bill | null | | 5 | Zack | 1 | | 6 | Mark | 2 | +----+------+------------+ 输出: +------+ | name | +------+ | Will | | Jane | | Bill | | Zack | +------+
Answer
SELECT
name
FROM
Customer
WHERE
referee_id <> 2
OR referee_id is null
595 大的国家
Question
World 表:
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| name | varchar |
| continent | varchar |
| area | int |
| population | int |
| gdp | bigint |
+-------------+---------+
name 是该表的主键(具有唯一值的列)。
这张表的每一行提供:国家名称、所属大陆、面积、人口和 GDP 值。
如果一个国家满足下述两个条件之一,则认为该国是 大国 :
- 面积至少为 300 万平方公里(即,
3000000 km<sup>2</sup>),或者 - 人口至少为 2500 万(即
25000000)
编写解决方案找出 大国 的国家名称、人口和面积。
按 任意顺序 返回结果表。
返回结果格式如下例所示。
示例:
输入: World 表: +-------------+-----------+---------+------------+--------------+ | name | continent | area | population | gdp | +-------------+-----------+---------+------------+--------------+ | Afghanistan | Asia | 652230 | 25500100 | 20343000000 | | Albania | Europe | 28748 | 2831741 | 12960000000 | | Algeria | Africa | 2381741 | 37100000 | 188681000000 | | Andorra | Europe | 468 | 78115 | 3712000000 | | Angola | Africa | 1246700 | 20609294 | 100990000000 | +-------------+-----------+---------+------------+--------------+ 输出: +-------------+------------+---------+ | name | population | area | +-------------+------------+---------+ | Afghanistan | 25500100 | 652230 | | Algeria | 37100000 | 2381741 | +-------------+------------+---------+
Answer
SELECT
`name`,
`population`,
`area`
FROM
World
WHERE
`area` >= 3000000
OR `population` >= 25000000
1148 文章浏览 I
Question
Views 表:
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| article_id | int |
| author_id | int |
| viewer_id | int |
| view_date | date |
+---------------+---------+
此表可能会存在重复行。(换句话说,在 SQL 中这个表没有主键)
此表的每一行都表示某人在某天浏览了某位作者的某篇文章。
请注意,同一人的 author_id 和 viewer_id 是相同的。
请查询出所有浏览过自己文章的作者
结果按照 id 升序排列。
查询结果的格式如下所示:
示例 1:
输入: Views 表: +------------+-----------+-----------+------------+ | article_id | author_id | viewer_id | view_date | +------------+-----------+-----------+------------+ | 1 | 3 | 5 | 2019-08-01 | | 1 | 3 | 6 | 2019-08-02 | | 2 | 7 | 7 | 2019-08-01 | | 2 | 7 | 6 | 2019-08-02 | | 4 | 7 | 1 | 2019-07-22 | | 3 | 4 | 4 | 2019-07-21 | | 3 | 4 | 4 | 2019-07-21 | +------------+-----------+-----------+------------+ 输出: +------+ | id | +------+ | 4 | | 7 | +------+
Answer
SELECT
DISTINCT author_id as 'id'
FROM
Views
WHERE
author_id = viewer_id
ORDER BY
author_id
1683. 无效的推文
Question
表:Tweets
+----------------+---------+
| Column Name | Type |
+----------------+---------+
| tweet_id | int |
| content | varchar |
+----------------+---------+
在 SQL 中,tweet_id 是这个表的主键。
这个表包含某社交媒体 App 中所有的推文。
查询所有无效推文的编号(ID)。当推文内容中的字符数严格大于 15 时,该推文是无效的。
以任意顺序返回结果表。
查询结果格式如下所示:
示例 1:
输入: Tweets 表: +----------+----------------------------------+ | tweet_id | content | +----------+----------------------------------+ | 1 | Vote for Biden | | 2 | Let us make America great again! | +----------+----------------------------------+ 输出: +----------+ | tweet_id | +----------+ | 2 | +----------+ 解释: 推文 1 的长度 length = 14。该推文是有效的。 推文 2 的长度 length = 32。该推文是无效的。
Answer
SELECT
tweet_id
FROM
Tweets
WHERE
length(content)>15
連接
1378. 使用唯一标识码替换员工ID
Question
Employees 表:
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| id | int |
| name | varchar |
+---------------+---------+
在 SQL 中,id 是这张表的主键。
这张表的每一行分别代表了某公司其中一位员工的名字和 ID 。
EmployeeUNI 表:
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| id | int |
| unique_id | int |
+---------------+---------+
在 SQL 中,(id, unique_id) 是这张表的主键。
这张表的每一行包含了该公司某位员工的 ID 和他的唯一标识码(unique ID)。
展示每位用户的 ** 唯一标识码(unique ID )** ;如果某位员工没有唯一标识码,使用 null 填充即可。
你可以以** 任意** 顺序返回结果表。
返回结果的格式如下例所示。
示例 1:
输入:
Employees 表:
+----+----------+
| id | name |
+----+----------+
| 1 | Alice |
| 7 | Bob |
| 11 | Meir |
| 90 | Winston |
| 3 | Jonathan |
+----+----------+
EmployeeUNI 表:
+----+-----------+
| id | unique_id |
+----+-----------+
| 3 | 1 |
| 11 | 2 |
| 90 | 3 |
+----+-----------+
输出:
+-----------+----------+
| unique_id | name |
+-----------+----------+
| null | Alice |
| null | Bob |
| 2 | Meir |
| 3 | Winston |
| 1 | Jonathan |
+-----------+----------+
解释:
Alice and Bob 没有唯一标识码, 因此我们使用 null 替代。
Meir 的唯一标识码是 2 。
Winston 的唯一标识码是 3 。
Jonathan 唯一标识码是 1 。
Answer
SELECT
unique_id,
name
FROM
Employees
LEFT JOIN EmployeeUNI ON Employees.id = EmployeeUNI.id
1068. 产品销售分析 I
Question
销售表 Sales:
+-------------+-------+
| Column Name | Type |
+-------------+-------+
| sale_id | int |
| product_id | int |
| year | int |
| quantity | int |
| price | int |
+-------------+-------+
(sale_id, year) 是销售表 Sales 的主键(具有唯一值的列的组合)。
product_id 是关联到产品表 Product 的外键(reference 列)。
该表的每一行显示 product_id 在某一年的销售情况。
注意: price 表示每单位价格。
产品表 Product:
+--------------+---------+
| Column Name | Type |
+--------------+---------+
| product_id | int |
| product_name | varchar |
+--------------+---------+
product_id 是表的主键(具有唯一值的列)。
该表的每一行表示每种产品的产品名称。
编写解决方案,以获取 Sales 表中所有 sale_id 对应的 product_name 以及该产品的所有 year 和 price 。
返回结果表 无顺序要求 。
结果格式示例如下。
示例 1:
输入:
Sales 表:
+---------+------------+------+----------+-------+
| sale_id | product_id | year | quantity | price |
+---------+------------+------+----------+-------+
| 1 | 100 | 2008 | 10 | 5000 |
| 2 | 100 | 2009 | 12 | 5000 |
| 7 | 200 | 2011 | 15 | 9000 |
+---------+------------+------+----------+-------+
Product 表:
+------------+--------------+
| product_id | product_name |
+------------+--------------+
| 100 | Nokia |
| 200 | Apple |
| 300 | Samsung |
+------------+--------------+
输出:
+--------------+-------+-------+
| product_name | year | price |
+--------------+-------+-------+
| Nokia | 2008 | 5000 |
| Nokia | 2009 | 5000 |
| Apple | 2011 | 9000 |
+--------------+-------+-------+
Answer
SELECT
`product_name`,
`year`,
`price`
FROM
Sales
LEFT JOIN Product ON Product.product_id = Sales.product_id
1581. 进店却未进行过交易的顾客
Question
表:Visits
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| visit_id | int |
| customer_id | int |
+-------------+---------+
visit_id 是该表中具有唯一值的列。
该表包含有关光临过购物中心的顾客的信息。
表:Transactions
+----------------+---------+
| Column Name | Type |
+----------------+---------+
| transaction_id | int |
| visit_id | int |
| amount | int |
+----------------+---------+
transaction_id 是该表中具有唯一值的列。
此表包含 visit_id 期间进行的交易的信息。
有一些顾客可能光顾了购物中心但没有进行交易。请你编写一个解决方案,来查找这些顾客的 ID ,以及他们只光顾不交易的次数。
返回以 任何顺序 排序的结果表。
返回结果格式如下例所示。
示例 1:
输入:
Visits
+----------+-------------+
| visit_id | customer_id |
+----------+-------------+
| 1 | 23 |
| 2 | 9 |
| 4 | 30 |
| 5 | 54 |
| 6 | 96 |
| 7 | 54 |
| 8 | 54 |
+----------+-------------+
Transactions
+----------------+----------+--------+
| transaction_id | visit_id | amount |
+----------------+----------+--------+
| 2 | 5 | 310 |
| 3 | 5 | 300 |
| 9 | 5 | 200 |
| 12 | 1 | 910 |
| 13 | 2 | 970 |
+----------------+----------+--------+
输出:
+-------------+----------------+
| customer_id | count_no_trans |
+-------------+----------------+
| 54 | 2 |
| 30 | 1 |
| 96 | 1 |
+-------------+----------------+
解释:
ID = 23 的顾客曾经逛过一次购物中心,并在 ID = 12 的访问期间进行了一笔交易。
ID = 9 的顾客曾经逛过一次购物中心,并在 ID = 13 的访问期间进行了一笔交易。
ID = 30 的顾客曾经去过购物中心,并且没有进行任何交易。
ID = 54 的顾客三度造访了购物中心。在 2 次访问中,他们没有进行任何交易,在 1 次访问中,他们进行了 3 次交易。
ID = 96 的顾客曾经去过购物中心,并且没有进行任何交易。
如我们所见,ID 为 30 和 96 的顾客一次没有进行任何交易就去了购物中心。顾客 54 也两次访问了购物中心并且没有进行任何交易。
Answer
method one
SELECT
`customer_id`,
COUNT(`visit_id`) as 'count_no_trans'
FROM
Visits
WHERE
visit_id not in (SELECT visit_id FROM Transactions)
GROUP BY
`customer_id`
method two
select customer_id, count(customer_id) as count_no_trans
from visits
left join transactions using(visit_id)
where transaction_id is null
group by customer_id;
197. 上升的温度
Question
表: Weather
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| id | int |
| recordDate | date |
| temperature | int |
+---------------+---------+
id 是该表具有唯一值的列。
没有具有相同 recordDate 的不同行。
该表包含特定日期的温度信息
编写解决方案,找出与之前(昨天的)日期相比温度更高的所有日期的 id 。
返回结果 无顺序要求 。
结果格式如下例子所示。
示例 1:
输入: Weather 表: +----+------------+-------------+ | id | recordDate | Temperature | +----+------------+-------------+ | 1 | 2015-01-01 | 10 | | 2 | 2015-01-02 | 25 | | 3 | 2015-01-03 | 20 | | 4 | 2015-01-04 | 30 | +----+------------+-------------+ 输出: +----+ | id | +----+ | 2 | | 4 | +----+ 解释: 2015-01-02 的温度比前一天高(10 -> 25) 2015-01-04 的温度比前一天高(20 -> 30)
Answer
SELECT
w1.id
FROM
Weather w1
JOIN
Weather w2 ON datediff(w1.recorddate,w2.recorddate) = 1
WHERE
w1.temperature > w2.temperature
Explain:
最開始是準備直接用LAG向下移動一個格子就是之前的溫度,但是未考慮到如果不存在前一天的日期將會直接是前好幾天的溫度,所以只能表自連,然後日期做減法連接上
注意: 日期不能直接 -1 必須使用
datediff()來進行計算
1661 每台机器的进程平均运行时间
Question
表: Activity
+----------------+---------+
| Column Name | Type |
+----------------+---------+
| machine_id | int |
| process_id | int |
| activity_type | enum |
| timestamp | float |
+----------------+---------+
该表展示了一家工厂网站的用户活动。
(machine_id, process_id, activity_type) 是当前表的主键(具有唯一值的列的组合)。
machine_id 是一台机器的ID号。
process_id 是运行在各机器上的进程ID号。
activity_type 是枚举类型 ('start', 'end')。
timestamp 是浮点类型,代表当前时间(以秒为单位)。
'start' 代表该进程在这台机器上的开始运行时间戳 , 'end' 代表该进程在这台机器上的终止运行时间戳。
同一台机器,同一个进程都有一对开始时间戳和结束时间戳,而且开始时间戳永远在结束时间戳前面。
现在有一个工厂网站由几台机器运行,每台机器上运行着 相同数量的进程 。编写解决方案,计算每台机器各自完成一个进程任务的平均耗时。
完成一个进程任务的时间指进程的 'end' 时间戳 减去 'start' 时间戳。平均耗时通过计算每台机器上所有进程任务的总耗费时间除以机器上的总进程数量获得。
结果表必须包含 machine_id(机器ID) 和对应的 average time(平均耗时) 别名 processing_time,且四舍五入保留3位小数。
以 任意顺序 返回表。
具体参考例子如下。
示例 1:
输入: Activity table: +------------+------------+---------------+-----------+ | machine_id | process_id | activity_type | timestamp | +------------+------------+---------------+-----------+ | 0 | 0 | start | 0.712 | | 0 | 0 | end | 1.520 | | 0 | 1 | start | 3.140 | | 0 | 1 | end | 4.120 | | 1 | 0 | start | 0.550 | | 1 | 0 | end | 1.550 | | 1 | 1 | start | 0.430 | | 1 | 1 | end | 1.420 | | 2 | 0 | start | 4.100 | | 2 | 0 | end | 4.512 | | 2 | 1 | start | 2.500 | | 2 | 1 | end | 5.000 | +------------+------------+---------------+-----------+ 输出: +------------+-----------------+ | machine_id | processing_time | +------------+-----------------+ | 0 | 0.894 | | 1 | 0.995 | | 2 | 1.456 | +------------+-----------------+ 解释: 一共有3台机器,每台机器运行着两个进程. 机器 0 的平均耗时: ((1.520 - 0.712) + (4.120 - 3.140)) / 2 = 0.894 机器 1 的平均耗时: ((1.550 - 0.550) + (1.420 - 0.430)) / 2 = 0.995 机器 2 的平均耗时: ((4.512 - 4.100) + (5.000 - 2.500)) / 2 = 1.456
Answer
Method one
SELECT
a1.machine_id,
ROUND((`end` - `start`)/a1.count,3) as 'processing_time'
FROM
(SELECT
machine_id,
COUNT(machine_id) as 'count',
SUM(timestamp) as 'start'
FROM
Activity
WHERE
activity_type = 'start'
GROUP BY machine_id) a1
LEFT JOIN
(
SELECT
machine_id,
COUNT(machine_id) as 'count',
SUM(timestamp) as 'end'
FROM
Activity
WHERE
activity_type = 'end'
GROUP BY machine_id
) a2
ON a1.machine_id = a2.machine_id
GROUP BY a1.machine_id
process_time = (end1 - start1) + (end2 - start2)
機器的開始時間和次數
SELECT
machine_id,
COUNT(machine_id) as 'count',
SUM(timestamp) as 'start'
FROM
Activity
WHERE
activity_type = 'start'
GROUP BY machine_id
機器的結束時間和次數
SELECT
machine_id,
COUNT(machine_id) as 'count',
SUM(timestamp) as 'end'
FROM
Activity
WHERE
activity_type = 'end'
GROUP BY machine_id
Method two:
select
machine_id,
round(
sum(case when activity_type="end" then timestamp else -timestamp end)/count(distinct process_id),3) as processing_time
from Activity
group by machine_id
在SUM 中判斷 end為正數 start為負數 此時結合為: end - start
577. 员工奖金
Question
表:Employee
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| empId | int |
| name | varchar |
| supervisor | int |
| salary | int |
+-------------+---------+
empId 是该表中具有唯一值的列。
该表的每一行都表示员工的姓名和 id,以及他们的工资和经理的 id。
表:Bonus
+-------------+------+
| Column Name | Type |
+-------------+------+
| empId | int |
| bonus | int |
+-------------+------+
empId 是该表具有唯一值的列。
empId 是 Employee 表中 empId 的外键(reference 列)。
该表的每一行都包含一个员工的 id 和他们各自的奖金。
编写解决方案,报告每个奖金 少于 1000 的员工的姓名和奖金数额。
以 任意顺序 返回结果表。
结果格式如下所示。
示例 1:
输入: Employee table: +-------+--------+------------+--------+ | empId | name | supervisor | salary | +-------+--------+------------+--------+ | 3 | Brad | null | 4000 | | 1 | John | 3 | 1000 | | 2 | Dan | 3 | 2000 | | 4 | Thomas | 3 | 4000 | +-------+--------+------------+--------+ Bonus table: +-------+-------+ | empId | bonus | +-------+-------+ | 2 | 500 | | 4 | 2000 | +-------+-------+ 输出: +------+-------+ | name | bonus | +------+-------+ | Brad | null | | John | null | | Dan | 500 | +------+-------+
Answer
SELECT
name,
bonus
FROM
Employee
LEFT JOIN
Bonus ON Employee.empId = Bonus.empId
WHERE
bonus < 1000
OR bonus is null
1280. 学生们参加各科测试的次数
Question
学生表: Students
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| student_id | int |
| student_name | varchar |
+---------------+---------+
在 SQL 中,主键为 student_id(学生ID)。
该表内的每一行都记录有学校一名学生的信息。
科目表: Subjects
+--------------+---------+
| Column Name | Type |
+--------------+---------+
| subject_name | varchar |
+--------------+---------+
在 SQL 中,主键为 subject_name(科目名称)。
每一行记录学校的一门科目名称。
考试表: Examinations
+--------------+---------+
| Column Name | Type |
+--------------+---------+
| student_id | int |
| subject_name | varchar |
+--------------+---------+
这个表可能包含重复数据(换句话说,在 SQL 中,这个表没有主键)。
学生表里的一个学生修读科目表里的每一门科目。
这张考试表的每一行记录就表示学生表里的某个学生参加了一次科目表里某门科目的测试。
查询出每个学生参加每一门科目测试的次数,结果按 student_id 和 subject_name 排序。
查询结构格式如下所示。
示例 1:
输入: Students table: +------------+--------------+ | student_id | student_name | +------------+--------------+ | 1 | Alice | | 2 | Bob | | 13 | John | | 6 | Alex | +------------+--------------+ Subjects table: +--------------+ | subject_name | +--------------+ | Math | | Physics | | Programming | +--------------+ Examinations table: +------------+--------------+ | student_id | subject_name | +------------+--------------+ | 1 | Math | | 1 | Physics | | 1 | Programming | | 2 | Programming | | 1 | Physics | | 1 | Math | | 13 | Math | | 13 | Programming | | 13 | Physics | | 2 | Math | | 1 | Math | +------------+--------------+ 输出: +------------+--------------+--------------+----------------+ | student_id | student_name | subject_name | attended_exams | +------------+--------------+--------------+----------------+ | 1 | Alice | Math | 3 | | 1 | Alice | Physics | 2 | | 1 | Alice | Programming | 1 | | 2 | Bob | Math | 1 | | 2 | Bob | Physics | 0 | | 2 | Bob | Programming | 1 | | 6 | Alex | Math | 0 | | 6 | Alex | Physics | 0 | | 6 | Alex | Programming | 0 | | 13 | John | Math | 1 | | 13 | John | Physics | 1 | | 13 | John | Programming | 1 | +------------+--------------+--------------+----------------+ 解释: 结果表需包含所有学生和所有科目(即便测试次数为0): Alice 参加了 3 次数学测试, 2 次物理测试,以及 1 次编程测试; Bob 参加了 1 次数学测试, 1 次编程测试,没有参加物理测试; Alex 啥测试都没参加; John 参加了数学、物理、编程测试各 1 次。
Answer
SELECT
st.student_id,
student_name,
su.subject_name,
COUNT(ex.subject_name) as 'attended_exams'
FROM
Students st
JOIN
Subjects su
LEFT JOIN
Examinations ex ON ex.student_id = st.student_id and su.subject_name = ex.subject_name
GROUP BY su.subject_name,st.student_id
ORDER BY st.student_id, su.subject_name, attended_exams desc
other method
with t1 as (select *
from students,
subjects),
t2 as (select student_id, subject_name, count(1) as attended_exams
from examinations
group by student_id, subject_name)
select t1.*, ifnull(attended_exams, 0) as attended_exams
from t1
left join t2 on t1.student_id = t2.student_id
and t1.subject_name = t2.subject_name
order by student_id, subject_name
570. 至少有5名直接下属的经理
Question
表: Employee
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| id | int |
| name | varchar |
| department | varchar |
| managerId | int |
+-------------+---------+
id 是此表的主键(具有唯一值的列)。
该表的每一行表示雇员的名字、他们的部门和他们的经理的id。
如果managerId为空,则该员工没有经理。
没有员工会成为自己的管理者。
编写一个解决方案,找出至少有五个直接下属的经理。
以 **任意顺序 **返回结果表。
查询结果格式如下所示。
示例 1:
输入: Employee 表: +-----+-------+------------+-----------+ | id | name | department | managerId | +-----+-------+------------+-----------+ | 101 | John | A | Null | | 102 | Dan | A | 101 | | 103 | James | A | 101 | | 104 | Amy | A | 101 | | 105 | Anne | A | 101 | | 106 | Ron | B | 101 | +-----+-------+------------+-----------+ 输出: +------+ | name | +------+ | John | +------+
Answer
SELECT
name
FROM
Employee
WHERE
id in (SELECT
managerId
FROM
Employee
GROUP BY managerId
HAVING COUNT(managerId) >= 5)
1934. 确认率
Question
表: Signups
+----------------+----------+
| Column Name | Type |
+----------------+----------+
| user_id | int |
| time_stamp | datetime |
+----------------+----------+
User_id是该表的主键。
每一行都包含ID为user_id的用户的注册时间信息。
表: Confirmations
+----------------+----------+
| Column Name | Type |
+----------------+----------+
| user_id | int |
| time_stamp | datetime |
| action | ENUM |
+----------------+----------+
(user_id, time_stamp)是该表的主键。
user_id是一个引用到注册表的外键。
action是类型为('confirmed', 'timeout')的ENUM
该表的每一行都表示ID为user_id的用户在time_stamp请求了一条确认消息,该确认消息要么被确认('confirmed'),要么被过期('timeout')。
用户的 确认率 是 'confirmed' 消息的数量除以请求的确认消息的总数。没有请求任何确认消息的用户的确认率为 0 。确认率四舍五入到 小数点后两位 。
编写一个SQL查询来查找每个用户的 确认率 。
以 任意顺序 返回结果表。
查询结果格式如下所示。
示例1:
输入: Signups 表: +---------+---------------------+ | user_id | time_stamp | +---------+---------------------+ | 3 | 2020-03-21 10:16:13 | | 7 | 2020-01-04 13:57:59 | | 2 | 2020-07-29 23:09:44 | | 6 | 2020-12-09 10:39:37 | +---------+---------------------+ Confirmations 表: +---------+---------------------+-----------+ | user_id | time_stamp | action | +---------+---------------------+-----------+ | 3 | 2021-01-06 03:30:46 | timeout | | 3 | 2021-07-14 14:00:00 | timeout | | 7 | 2021-06-12 11:57:29 | confirmed | | 7 | 2021-06-13 12:58:28 | confirmed | | 7 | 2021-06-14 13:59:27 | confirmed | | 2 | 2021-01-22 00:00:00 | confirmed | | 2 | 2021-02-28 23:59:59 | timeout | +---------+---------------------+-----------+ 输出: +---------+-------------------+ | user_id | confirmation_rate | +---------+-------------------+ | 6 | 0.00 | | 3 | 0.00 | | 7 | 1.00 | | 2 | 0.50 | +---------+-------------------+ 解释: 用户 6 没有请求任何确认消息。确认率为 0。 用户 3 进行了 2 次请求,都超时了。确认率为 0。 用户 7 提出了 3 个请求,所有请求都得到了确认。确认率为 1。 用户 2 做了 2 个请求,其中一个被确认,另一个超时。确认率为 1 / 2 = 0.5。
Answer
SELECT
s.user_id,
ROUND(SUM(case when action='confirmed' then 1 else 0 end)/SUM(1),2) as 'confirmation_rate'
FROM
Confirmations c
RIGHT JOIN Signups s ON s.user_id = c.user_id
GROUP BY user_id
SUM()中通過 case when condition else 執行語句 else 執行語句 end 只計算 action = 'confirmed' 情況下的 總數
SUM(1) 每一條都加一 => 計算不論confirm還是timeout 的總數
兩個相除就是確認率
聚合函數
620. 有趣的电影
Question
表:cinema
+----------------+----------+
| Column Name | Type |
+----------------+----------+
| id | int |
| movie | varchar |
| description | varchar |
| rating | float |
+----------------+----------+
id 是该表的主键(具有唯一值的列)。
每行包含有关电影名称、类型和评级的信息。
评级为 [0,10] 范围内的小数点后 2 位浮点数。
编写解决方案,找出所有影片描述为 非 boring (不无聊) 的并且** id 为奇数 **的影片。编写解决方案,找出所有影片描述为 非 boring (不无聊) 的并且 id 为奇数 的影片。
返回结果按 rating 降序排列 。
结果格式如下示例。
示例 1:
输入: +---------+-----------+--------------+-----------+ | id | movie | description | rating | +---------+-----------+--------------+-----------+ | 1 | War | great 3D | 8.9 | | 2 | Science | fiction | 8.5 | | 3 | irish | boring | 6.2 | | 4 | Ice song | Fantacy | 8.6 | | 5 | House card| Interesting| 9.1 | +---------+-----------+--------------+-----------+ 输出: +---------+-----------+--------------+-----------+ | id | movie | description | rating | +---------+-----------+--------------+-----------+ | 5 | House card| Interesting| 9.1 | | 1 | War | great 3D | 8.9 | +---------+-----------+--------------+-----------+ 解释: 我们有三部电影,它们的 id 是奇数:1、3 和 5。id = 3 的电影是 boring 的,所以我们不把它包括在答案中。
Answer
SELECT
id,
movie,
description,
rating
FROM
cinema
WHERE
description != "boring"
AND id%2 = 1
ORDER BY rating desc
1251. 平均售价
Question
表:Prices
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| product_id | int |
| start_date | date |
| end_date | date |
| price | int |
+---------------+---------+
(product_id,start_date,end_date) 是 prices 表的主键(具有唯一值的列的组合)。
prices 表的每一行表示的是某个产品在一段时期内的价格。
每个产品的对应时间段是不会重叠的,这也意味着同一个产品的价格时段不会出现交叉。
表:UnitsSold
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| product_id | int |
| purchase_date | date |
| units | int |
+---------------+---------+
该表可能包含重复数据。
该表的每一行表示的是每种产品的出售日期,单位和产品 id。
编写解决方案以查找每种产品的平均售价。average_price 应该 四舍五入到小数点后两位 。
返回结果表 无顺序要求 。
结果格式如下例所示。
示例 1:
输入: Prices table: +------------+------------+------------+--------+ | product_id | start_date | end_date | price | +------------+------------+------------+--------+ | 1 | 2019-02-17 | 2019-02-28 | 5 | | 1 | 2019-03-01 | 2019-03-22 | 20 | | 2 | 2019-02-01 | 2019-02-20 | 15 | | 2 | 2019-02-21 | 2019-03-31 | 30 | +------------+------------+------------+--------+ UnitsSold table: +------------+---------------+-------+ | product_id | purchase_date | units | +------------+---------------+-------+ | 1 | 2019-02-25 | 100 | | 1 | 2019-03-01 | 15 | | 2 | 2019-02-10 | 200 | | 2 | 2019-03-22 | 30 | +------------+---------------+-------+ 输出: +------------+---------------+ | product_id | average_price | +------------+---------------+ | 1 | 6.96 | | 2 | 16.96 | +------------+---------------+ 解释: 平均售价 = 产品总价 / 销售的产品数量。 产品 1 的平均售价 = ((100 * 5)+(15 * 20) )/ 115 = 6.96 产品 2 的平均售价 = ((200 * 15)+(30 * 30) )/ 230 = 16.96
Answer
SELECT
p.product_id,
IFNULL(ROUND(SUM(units * price)/SUM(units),2),0) as 'average_price'
FROM
UnitsSold u
RIGHT JOIN
Prices p ON p.product_id = u.product_id AND (u.purchase_date BETWEEN p.start_date AND p.end_date)
GROUP BY product_id
1075. 项目员工 I
Question
项目表 Project:
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| project_id | int |
| employee_id | int |
+-------------+---------+
主键为 (project_id, employee_id)。
employee_id 是员工表 Employee 表的外键。
这张表的每一行表示 employee_id 的员工正在 project_id 的项目上工作。
员工表 Employee:
+------------------+---------+
| Column Name | Type |
+------------------+---------+
| employee_id | int |
| name | varchar |
| experience_years | int |
+------------------+---------+
主键是 employee_id。数据保证 experience_years 非空。
这张表的每一行包含一个员工的信息。
请写一个 SQL 语句,查询每一个项目中员工的 **平均 **工作年限, 精确到小数点后两位 。
以 任意 顺序返回结果表。
查询结果的格式如下。
示例 1:
输入: Project 表: +-------------+-------------+ | project_id | employee_id | +-------------+-------------+ | 1 | 1 | | 1 | 2 | | 1 | 3 | | 2 | 1 | | 2 | 4 | +-------------+-------------+ Employee 表: +-------------+--------+------------------+ | employee_id | name | experience_years | +-------------+--------+------------------+ | 1 | Khaled | 3 | | 2 | Ali | 2 | | 3 | John | 1 | | 4 | Doe | 2 | +-------------+--------+------------------+ 输出: +-------------+---------------+ | project_id | average_years | +-------------+---------------+ | 1 | 2.00 | | 2 | 2.50 | +-------------+---------------+ 解释:第一个项目中,员工的平均工作年限是 (3 + 2 + 1) / 3 = 2.00;第二个项目中,员工的平均工作年限是 (3 + 2) / 2 = 2.50
Answer
SELECT
project_id,
ROUND(SUM(experience_years)/SUM(1),2) as 'average_years'
FROM
Project p
LEFT JOIN
Employee e ON p.employee_id = e.employee_id
GROUP BY project_id
1633. 各赛事的用户注册率
Question
用户表: Users
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| user_id | int |
| user_name | varchar |
+-------------+---------+
user_id 是该表的主键(具有唯一值的列)。
该表中的每行包括用户 ID 和用户名。
注册表: Register
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| contest_id | int |
| user_id | int |
+-------------+---------+
(contest_id, user_id) 是该表的主键(具有唯一值的列的组合)。
该表中的每行包含用户的 ID 和他们注册的赛事。
编写解决方案统计出各赛事的用户注册百分率,保留两位小数。
返回的结果表按 percentage 的 **降序 **排序,若相同则按 contest_id 的 **升序 **排序。
返回结果如下示例所示。
示例 1:
输入:
Users 表:
+---------+-----------+
| user_id | user_name |
+---------+-----------+
| 6 | Alice |
| 2 | Bob |
| 7 | Alex |
+---------+-----------+
Register 表:
+------------+---------+
| contest_id | user_id |
+------------+---------+
| 215 | 6 |
| 209 | 2 |
| 208 | 2 |
| 210 | 6 |
| 208 | 6 |
| 209 | 7 |
| 209 | 6 |
| 215 | 7 |
| 208 | 7 |
| 210 | 2 |
| 207 | 2 |
| 210 | 7 |
+------------+---------+
输出:
+------------+------------+
| contest_id | percentage |
+------------+------------+
| 208 | 100.0 |
| 209 | 100.0 |
| 210 | 100.0 |
| 215 | 66.67 |
| 207 | 33.33 |
+------------+------------+
解释:
所有用户都注册了 208、209 和 210 赛事,因此这些赛事的注册率为 100% ,我们按 contest_id 的降序排序加入结果表中。
Alice 和 Alex 注册了 215 赛事,注册率为 ((2/3) * 100) = 66.67%
Bob 注册了 207 赛事,注册率为 ((1/3) * 100) = 33.33%
Answer
with temporaryTable (Total) AS (
SELECT COUNT(user_id)
FROM Users
)
SELECT
contest_id,
ROUND((COUNT(user_id)/temporaryTable.Total)*100,2) as 'percentage'
FROM
Register, temporaryTable
GROUP BY contest_id
ORDER BY percentage DESC, contest_id
method two
select contest_id, round(ifnull(total / tu *100,0),2) as percentage
from(
select contest_id,count(*) as total
from register group by contest_id
)t1 join(
select count(*) as tu from users
)t2
order by percentage desc ,contest_id asc
1211. 查询结果的质量和占比
Question
Queries 表:
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| query_name | varchar |
| result | varchar |
| position | int |
| rating | int |
+-------------+---------+
此表可能有重复的行。
此表包含了一些从数据库中收集的查询信息。
“位置”(position)列的值为 1 到 500 。
“评分”(rating)列的值为 1 到 5 。评分小于 3 的查询被定义为质量很差的查询。
将查询结果的质量 quality 定义为:
各查询结果的评分与其位置之间比率的平均值。
将劣质查询百分比 poor_query_percentage 为:
评分小于 3 的查询结果占全部查询结果的百分比。
编写解决方案,找出每次的 query_name 、 quality 和 poor_query_percentage。
quality 和 poor_query_percentage 都应 四舍五入到小数点后两位 。
以 任意顺序 返回结果表。
结果格式如下所示:
示例 1:
输入: Queries table: +------------+-------------------+----------+--------+ | query_name | result | position | rating | +------------+-------------------+----------+--------+ | Dog | Golden Retriever | 1 | 5 | | Dog | German Shepherd | 2 | 5 | | Dog | Mule | 200 | 1 | | Cat | Shirazi | 5 | 2 | | Cat | Siamese | 3 | 3 | | Cat | Sphynx | 7 | 4 | +------------+-------------------+----------+--------+ 输出: +------------+---------+-----------------------+ | query_name | quality | poor_query_percentage | +------------+---------+-----------------------+ | Dog | 2.50 | 33.33 | | Cat | 0.66 | 33.33 | +------------+---------+-----------------------+ 解释: Dog 查询结果的质量为 ((5 / 1) + (5 / 2) + (1 / 200)) / 3 = 2.50 Dog 查询结果的劣质查询百分比为 (1 / 3) * 100 = 33.33 Cat 查询结果的质量为 ((2 / 5) + (3 / 3) + (4 / 7)) / 3 = 0.66 Cat 查询结果的劣质查询百分比为 (1 / 3) * 100 = 33.33
Answer
#quantity = SUM(rating/position)/total
SELECT
`query_name`,
ROUND((SUM(`rating`/`position`)/SUM(1)),2) as `quality`,
ROUND(SUM(case when `rating`<3 then 1 else 0 end)*100/SUM(1),2) as `poor_query_percentage`
FROM
Queries
WHERE
`query_name` is not null
GROUP BY `query_name`
SELECT
`query_name`,
ROUND((SUM(`rating`/`position`)/SUM(1)),2) as `quality`,
ROUND(SUM(if(`rating`<3, 1,0))*100/SUM(1),2) as `poor_query_percentage`
FROM
Queries
WHERE
`query_name` is not null
GROUP BY `query_name`
1193. 每月交易 I
Question
表:Transactions
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| id | int |
| country | varchar |
| state | enum |
| amount | int |
| trans_date | date |
+---------------+---------+
id 是这个表的主键。
该表包含有关传入事务的信息。
state 列类型为 ["approved", "declined"] 之一。
编写一个 sql 查询来查找每个月和每个国家/地区的事务数及其总金额、已批准的事务数及其总金额。
以 任意顺序 返回结果表。
查询结果格式如下所示。
示例 1:
输入:
Transactions table:
+------+---------+----------+--------+------------+
| id | country | state | amount | trans_date |
+------+---------+----------+--------+------------+
| 121 | US | approved | 1000 | 2018-12-18 |
| 122 | US | declined | 2000 | 2018-12-19 |
| 123 | US | approved | 2000 | 2019-01-01 |
| 124 | DE | approved | 2000 | 2019-01-07 |
+------+---------+----------+--------+------------+
输出:
+----------+---------+-------------+----------------+--------------------+-----------------------+
| month | country | trans_count | approved_count | trans_total_amount | approved_total_amount |
+----------+---------+-------------+----------------+--------------------+-----------------------+
| 2018-12 | US | 2 | 1 | 3000 | 1000 |
| 2019-01 | US | 1 | 1 | 2000 | 2000 |
| 2019-01 | DE | 1 | 1 | 2000 | 2000 |
+----------+---------+-------------+----------------+--------------------+-----------------------+
Answer
SELECT
DISTINCT Date_FORMAT(`trans_date`, '%Y-%m') as 'month',
`country`,
COUNT(`id`) as 'trans_count',
SUM(if(`state`='approved',1,0)) as 'approved_count',
SUM(`amount`) as 'trans_total_amount',
SUM(if(`state`='approved',`amount`,0)) as 'approved_total_amount'
FROM
Transactions
GROUP BY `month`,`country`
Explain
使用 Date_FORMAT 進行 DATE的格式轉換
DATE_FORMAT( , '%Y-%m') 將空格處的內容更改格式成YYY-mm
日期格式匯總:
| DATE_FORMAT字串 | 格式化日期 |
|---|---|
%Y-%m-%d | 2017/4/30 |
%e/%c/%Y | 4/7/2013 |
%c/%e/%Y | 7/4/2013 |
%d/%m/%Y | 4/7/2013 |
%m/%d/%Y | 7/4/2013 |
%e/%c/%Y %H:%i | 4/7/2013 11:20 |
%c/%e/%Y %H:%i | 7/4/2013 11:20 |
%d/%m/%Y %H:%i | 4/7/2013 11:20 |
%m/%d/%Y %H:%i | 7/4/2013 11:20 |
%e/%c/%Y %T | 4/7/2013 11:20 |
%c/%e/%Y %T | 7/4/2013 11:20 |
%d/%m/%Y %T | 4/7/2013 11:20 |
%m/%d/%Y %T | 7/4/2013 11:20 |
%a %D %b %Y | Thu 4th Jul 2013 |
%a %D %b %Y %H:%i | Thu 4th Jul 2013 11:20 |
%a %D %b %Y %T | Thu 4th Jul 2013 11:20:05 |
%a %b %e %Y | Thu Jul 4 2013 |
%a %b %e %Y %H:%i | Thu Jul 4 2013 11:20 |
%a %b %e %Y %T | Thu Jul 4 2013 11:20:05 |
%W %D %M %Y | Thursday 4th July 2013 |
%W %D %M %Y %H:%i | Thursday 4th July 2013 11:20 |
%W %D %M %Y %T | Thursday 4th July 2013 11:20:05 |
%l:%i %p %b %e, %Y | 7/4/2013 11:20 |
%M %e, %Y | 4-Jul-13 |
%a, %d %b %Y %T | Thu, 04 Jul 2013 11:20:05 |
符號匯總:
| 限定符 | 含義 |
|---|---|
%a | 三個字元縮寫的工作日名稱,例如:Mon , Tue , Wed ,等 |
%b | 三個字元縮寫的月份名稱,例如:Jan,Feb,Mar等 |
%c | 以數位表示的月份值,例如:1, 2, 3… 12 |
%D | 英文後綴如:0th , 1st , 2nd等的一個月之中的第幾天 |
%d | 如果是個數位(小於),那麼一個月之中的第幾天表示為加前導加, 如:00, 01,02, … 31 1``10``0 |
%e | 沒有前導零的月份的日子,例如:1,2,… 31 |
%f | 微秒,範圍在 000000..999999 |
%H | 24小時格式的小時,前導加,例如:00,01…23 0 |
%h | 小時,12小時格式,帶前導零,例如:01,02 … 12 |
%I | 與相同 %h |
%i | 分數為零,例如:00,01,… 59 |
%j | 一年中的的第幾天,前導為,例如,001,002,… 366 0 |
%k | 24小時格式的小時,無前導零,例如:0,1,2 … 23 |
%l | 12小時格式的小時,無前導零,例如:0,1,2 … 12 |
%M | 月份全名稱,例如:January, February,… December |
%m | 具有前導零的月份名稱,例如:00,01,02,… 12 |
%p | AM或,取決於其他時間說明符 PM |
%r | 表示時間,小時格式或 12``hh:mm:ss AM``PM |
%S | 表示秒,前導零,如:00,01,… 59 |
%s | 與相同 %S |
%T | 表示時間,24小時格式 hh:mm:ss |
%U | 周的第一天是星期日,例如:00,01,02 … 53時,前導零的周數 |
%u | 周的第一天是星期一,例如:00,01,02 … 53時,前導零的周數 |
%V | 與相同,它與一起使用 %U``%X |
%v | 與相同,它與一起使用 %u``%x |
%W | 工作日的全稱,例如:Sunday, Monday,…, Saturday |
%w | 工作日,以數位來表示(0 = 星期日,1 = 星期一等) |
%X | 周的四位數表示年份,第一天是星期日; 經常與一起使用 %V |
%x | 周的四位數表示年份,第一天是星期日; 經常與一起使用 %v |
%Y | 表示年份,四位數,例如2000,2001,… 等。 |
%y | 表示年份,兩位數,例如00,01,… 等。 |
%% | 將百分比()字元添加到輸出 % |
1174. 即时食物配送 II
Question
配送表: Delivery
+-----------------------------+---------+
| Column Name | Type |
+-----------------------------+---------+
| delivery_id | int |
| customer_id | int |
| order_date | date |
| customer_pref_delivery_date | date |
+-----------------------------+---------+
delivery_id 是该表中具有唯一值的列。
该表保存着顾客的食物配送信息,顾客在某个日期下了订单,并指定了一个期望的配送日期(和下单日期相同或者在那之后)。
如果顾客期望的配送日期和下单日期相同,则该订单称为 「 即时订单 」,否则称为「 计划订单 」。
「 首次订单 」是顾客最早创建的订单。我们保证一个顾客只会有一个「首次订单」。
编写解决方案以获取即时订单在所有用户的首次订单中的比例。保留两位小数。
结果示例如下所示:
示例 1:
输入: Delivery 表: +-------------+-------------+------------+-----------------------------+ | delivery_id | customer_id | order_date | customer_pref_delivery_date | +-------------+-------------+------------+-----------------------------+ | 1 | 1 | 2019-08-01 | 2019-08-02 | | 2 | 2 | 2019-08-02 | 2019-08-02 | | 3 | 1 | 2019-08-11 | 2019-08-12 | | 4 | 3 | 2019-08-24 | 2019-08-24 | | 5 | 3 | 2019-08-21 | 2019-08-22 | | 6 | 2 | 2019-08-11 | 2019-08-13 | | 7 | 4 | 2019-08-09 | 2019-08-09 | +-------------+-------------+------------+-----------------------------+ 输出: +----------------------+ | immediate_percentage | +----------------------+ | 50.00 | +----------------------+ 解释: 1 号顾客的 1 号订单是首次订单,并且是计划订单。 2 号顾客的 2 号订单是首次订单,并且是即时订单。 3 号顾客的 5 号订单是首次订单,并且是计划订单。 4 号顾客的 7 号订单是首次订单,并且是即时订单。 因此,一半顾客的首次订单是即时的。
Answer
#首次訂單:
/*
SELECT
MIN(`order_date`) as 'first_order',
`customer_id`
FROM
Delivery
GROUP BY `customer_id`
*/
#即時訂單:
/*
SELECT
delivery_id,
customer_id
FROM
Delivery
WHERE
order_date = customer_pref_delivery_date
*/
SELECT
ROUND(SUM(if(`order_date` = `customer_pref_delivery_date`, 1,0))*100/SUM(1),2) as 'immediate_percentage'
FROM
Delivery D
LEFT JOIN
(
SELECT
MIN(`order_date`) as 'first_order',
`customer_id`
FROM
Delivery
GROUP BY `customer_id`
) F ON D.customer_id = F.customer_id
WHERE
`order_date` = `first_order`
Optimised
用in代替LEFT JOIN
SELECT
ROUND(SUM(if(`order_date` = `customer_pref_delivery_date`, 1,0))*100/SUM(1),2) as 'immediate_percentage'
FROM
Delivery
WHERE (order_date, customer_id) in
(
SELECT
MIN(`order_date`),
`customer_id`
FROM
Delivery
GROUP BY `customer_id`
)
運用窗口函數 排序來獲得首單的item
select
round(sum(t1.flag)/count(distinct t1.customer_id)*100,2) as immediate_percentage
from
(
select
customer_id, order_date,
customer_pref_delivery_date,
row_number() over(partition by customer_id order by order_date,delivery_id) as r1,
if(order_date=customer_pref_delivery_date,1,0) as flag
from Delivery) t1
where r1=1
550. 游戏玩法分析 IV
Question
Table: Activity
+--------------+---------+
| Column Name | Type |
+--------------+---------+
| player_id | int |
| device_id | int |
| event_date | date |
| games_played | int |
+--------------+---------+
(player_id,event_date)是此表的主键(具有唯一值的列的组合)。
这张表显示了某些游戏的玩家的活动情况。
每一行是一个玩家的记录,他在某一天使用某个设备注销之前登录并玩了很多游戏(可能是 0)。
编写解决方案,报告在首次登录的第二天再次登录的玩家的 比率 , 四舍五入到小数点后两位 。换句话说,你需要计算从首次登录日期开始至少连续两天登录的玩家的数量,然后除以玩家总数。
结果格式如下所示:
示例 1:
输入: Activity table: +-----------+-----------+------------+--------------+ | player_id | device_id | event_date | games_played | +-----------+-----------+------------+--------------+ | 1 | 2 | 2016-03-01 | 5 | | 1 | 2 | 2016-03-02 | 6 | | 2 | 3 | 2017-06-25 | 1 | | 3 | 1 | 2016-03-02 | 0 | | 3 | 4 | 2018-07-03 | 5 | +-----------+-----------+------------+--------------+ 输出: +-----------+ | fraction | +-----------+ | 0.33 | +-----------+ 解释: 只有 ID 为 1 的玩家在第一天登录后才重新登录,所以答案是 1/3 = 0.33
Answer
這個是直接找到所有的連續登陸的日期的然後限定登陸日期為用戶的註冊日期來查詢的
/* 向上移動一位為下一次的登陸時間 下一次登陸時間-前一次登錄時間 = 1為連續登陸 */ SELECT ROUND(SUM(if(d. `differ `=1,1,0))/SUM(1),2) as 'fraction' FROM( SELECT player_id, IFNULL(datediff(t.next_date,t.event_date),0) as 'differ'# 這個等於1的時候說明是連續登陸 FROM ( SELECT player_id, event_date, IFNULL(LEAD(event_date,1) OVER(Partition BY player_id ORDER BY event_date),0) as 'next_date' FROM Activity ) t WHERE (event_date, player_id) IN (SELECT MIN(event_date), player_id FROM Activity GROUP BY player_id)) d /* 向上移動一位為下一次的登陸時間 下一次登陸時間-前一次登錄時間 = 1為連續登陸
*/ SELECT ROUND(SUM(if(d.`differ`=1,1,0))/SUM(1),2) as 'fraction'
FROM(
SELECT
player_id,
IFNULL(datediff(t.next_date,t.event_date),0) as 'differ'# 這個等於1的時候說明是連續登陸
FROM
(
SELECT
player_id,
event_date,
IFNULL(LEAD(event_date,1) OVER(Partition BY player_id ORDER BY event_date),0) as 'next_date'
FROM
Activity
) t
WHERE
(event_date, player_id) IN (SELECT
MIN(event_date),
player_id
FROM
Activity
GROUP BY
player_id)) d
將前後兩次的登陸時間放在同一條記錄中
SELECT
player_id,
event_date,
IFNULL(LEAD(event_date,1) OVER(Partition BY player_id ORDER BY event_date),0) as 'next_date'
FROM
Activity
output:
| player_id | event_date | next_date |
|---|---|---|
| 1 | 2016-03-01 | 2016-03-02 |
| 1 | 2016-03-02 | “0” |
| 2 | 2017-06-25 | “0” |
| 3 | 2016-03-02 | 2018-07-03 |
| 3 | 2018-07-03 | “0” |
計算兩個日期之間的差
SELECT
player_id,
t.event_date,
next_date,
IFNULL(datediff(t.next_date,t.event_date),0) as 'differ'# 這個等於1的時候說明是連續登陸
FROM
(
SELECT
player_id,
event_date,
IFNULL(LEAD(event_date,1) OVER(Partition BY player_id ORDER BY event_date),0) as 'next_date'
FROM
Activity
) t
output:
| player_id | event_date | next_date | differ |
|---|---|---|---|
| 1 | 2016-03-01 | 2016-03-02 | 1 |
| 1 | 2016-03-02 | “0” | 0 |
| 2 | 2017-06-25 | “0” | 0 |
| 3 | 2016-03-02 | 2018-07-03 | 853 |
| 3 | 2018-07-03 | “0” | 0 |
這個時候差距為1的為連續登陸一天的, 而1到0結束是連續登陸結束的日期
更快速的方法
表格自連,並且是註冊日期的基礎上,找到表格中用戶在註冊日期第二天的登錄記錄添加的表格中, 計算存在第二天日期的則為重複兩天登錄的用戶
select
round(count(distinct a.player_id)/count(distinct t.player_id),2) as fraction
from(
select
player_id,
min(event_date) as first_date
from Activity
group by player_id
) as t left join Activity a
on t.player_id=a.player_id
and datediff(a.event_date,first_date)=1
排序和分組
2356. 每位教师所教授的科目种类的数量
Question
表: Teacher
±------------±-----+
| Column Name | Type |
±------------±-----+
| teacher_id | int |
| subject_id | int |
| dept_id | int |
±------------±-----+
在 SQL 中,(subject_id, dept_id) 是该表的主键。
该表中的每一行都表示带有 teacher_id 的教师在系 dept_id 中教授科目 subject_id。
查询每位老师在大学里教授的科目种类的数量。
以 **任意顺序** 返回结果表。
查询结果格式示例如下。
**示例 1:**
<pre><strong>输入:</strong>
Teacher 表:
+------------+------------+---------+
| teacher_id | subject_id | dept_id |
+------------+------------+---------+
| 1 | 2 | 3 |
| 1 | 2 | 4 |
| 1 | 3 | 3 |
| 2 | 1 | 1 |
| 2 | 2 | 1 |
| 2 | 3 | 1 |
| 2 | 4 | 1 |
+------------+------------+---------+
<strong>输出:</strong>
+------------+-----+
| teacher_id | cnt |
+------------+-----+
| 1 | 2 |
| 2 | 4 |
+------------+-----+
<strong>解释:</strong>
教师 1:
- 他在 3、4 系教科目 2。
- 他在 3 系教科目 3。
教师 2:
- 他在 1 系教科目 1。
- 他在 1 系教科目 2。
- 他在 1 系教科目 3。
- 他在 1 系教科目 4。</pre>
Answer
SELECT
teacher_id,
COUNT(DISTINCT subject_id) as 'cnt'
FROM
Teacher
GROUP BY teacher_id
1141. 查询近30天活跃用户数
Question
表:Activity
±--------------±--------+
| Column Name | Type |
±--------------±--------+
| user_id | int |
| session_id | int |
| activity_date | date |
| activity_type | enum |
±--------------±--------+
该表没有包含重复数据。
activity_type 列是 ENUM(category) 类型, 从 (‘open_session’, ‘end_session’, ‘scroll_down’, ‘send_message’) 取值。
该表记录社交媒体网站的用户活动。
注意,每个会话只属于一个用户。
编写解决方案,统计截至 2019-07-27(包含2019-07-27),近 30 天的每日活跃用户数(当天只要有一条活动记录,即为活跃用户)。
以 任意顺序 返回结果表。
结果示例如下。
示例 1:
输入:
Activity table:
±--------±-----------±--------------±--------------+
| user_id | session_id | activity_date | activity_type |
±--------±-----------±--------------±--------------+
| 1 | 1 | 2019-07-20 | open_session |
| 1 | 1 | 2019-07-20 | scroll_down |
| 1 | 1 | 2019-07-20 | end_session |
| 2 | 4 | 2019-07-20 | open_session |
| 2 | 4 | 2019-07-21 | send_message |
| 2 | 4 | 2019-07-21 | end_session |
| 3 | 2 | 2019-07-21 | open_session |
| 3 | 2 | 2019-07-21 | send_message |
| 3 | 2 | 2019-07-21 | end_session |
| 4 | 3 | 2019-06-25 | open_session |
| 4 | 3 | 2019-06-25 | end_session |
±--------±-----------±--------------±--------------+
输出:
±-----------±-------------+
| day | active_users |
±-----------±-------------+
| 2019-07-20 | 2 |
| 2019-07-21 | 2 |
±-----------±-------------+
解释:注意非活跃用户的记录不需要展示。
Answer
SELECT
`activity_date` as 'day',
COUNT(DISTINCT `user_id`) as 'active_users'
FROM
Activity
WHERE
`activity_date` BETWEEN date_sub('2019-07-27', INTERVAL 29 day) AND '2019-07-27'
GROUP BY `activity_date`
ORDER BY `day`
1084. 销售分析III
Question
表: Product
±-------------±--------+
| Column Name | Type |
±-------------±--------+
| product_id | int |
| product_name | varchar |
| unit_price | int |
±-------------±--------+
product_id 是该表的主键(具有唯一值的列)。
该表的每一行显示每个产品的名称和价格。
表:`Sales`
±------------±--------+
| Column Name | Type |
±------------±--------+
| seller_id | int |
| product_id | int |
| buyer_id | int |
| sale_date | date |
| quantity | int |
| price | int |
±----- ------±--------+
这个表可能有重复的行。
product_id 是 Product 表的外键(reference 列)。
该表的每一行包含关于一个销售的一些信息。
编写解决方案,报告 `2019年春季` 才售出的产品。即 **仅 **在 `<strong>2019-01-01</strong>` (含)至 `<strong>2019-03-31</strong>` (含)之间出售的商品。
以 **任意顺序** 返回结果表。
结果格式如下所示。
**示例 1:**
<pre><strong>输入:</strong>
Product table:
+------------+--------------+------------+
| product_id | product_name | unit_price |
+------------+--------------+------------+
| 1 | S8 | 1000 |
| 2 | G4 | 800 |
| 3 | iPhone | 1400 |
+------------+--------------+------------+
<code>Sales </code>table:
+-----------+------------+----------+------------+----------+-------+
| seller_id | product_id | buyer_id | sale_date | quantity | price |
+-----------+------------+----------+------------+----------+-------+
| 1 | 1 | 1 | 2019-01-21 | 2 | 2000 |
| 1 | 2 | 2 | 2019-02-17 | 1 | 800 |
| 2 | 2 | 3 | 2019-06-02 | 1 | 800 |
| 3 | 3 | 4 | 2019-05-13 | 2 | 2800 |
+-----------+------------+----------+------------+----------+-------+
<strong>输出:</strong>
+-------------+--------------+
| product_id | product_name |
+-------------+--------------+
| 1 | S8 |
+-------------+--------------+
<strong>解释:</strong>
id 为 1 的产品仅在 2019 年春季销售。
id 为 2 的产品在 2019 年春季销售,但也在 2019 年春季之后销售。
id 为 3 的产品在 2019 年春季之后销售。
我们只返回 id 为 1 的产品,因为它是 2019 年春季才销售的产品。</pre>
Answer
SELECT
DISTINCT s.product_id,
product_name
FROM
Sales s
LEFT JOIN
Product p ON p.product_id = s.product_id
WHERE
sale_date BETWEEN '2019-01-01' AND '2019-03-31'
AND s.product_id not in (
SELECT
product_id
FROM
Sales
WHERE
sale_date < '2019-01-01' OR sale_date > '2019-03-31'
)
Another Method
select
product_id,
product_name
from
Product
where
product_id in (
select
product_id
from
Sales
group by product_id
having min(sale_date)>=‘2019-01-01’ and max(sale_date)<=‘2019-03-31’);
156. Classes More Than 5 Students
Question
表: Courses
±------------±--------+
| Column Name | Type |
±------------±--------+
| student | varchar |
| class | varchar |
±------------±--------+
(student, class)是该表的主键(不同值的列的组合)。
该表的每一行表示学生的名字和他们注册的班级。
查询 **至少有 5 个学生** 的所有班级。
以 **任意顺序 **返回结果表。
结果格式如下所示。
**示例 1:**
<pre><strong>输入:</strong>
Courses table:
+---------+----------+
| student | class |
+---------+----------+
| A | Math |
| B | English |
| C | Math |
| D | Biology |
| E | Math |
| F | Computer |
| G | Math |
| H | Math |
| I | Math |
+---------+----------+
<strong>输出:</strong>
+---------+
| class |
+---------+
| Math |
+---------+
<strong>解释: </strong>
-数学课有 6 个学生,所以我们包括它。
-英语课有 1 名学生,所以我们不包括它。
-生物课有 1 名学生,所以我们不包括它。
-计算机课有 1 个学生,所以我们不包括它。</pre>
Answer
SELECT
class
FROM
Courses
GROUP BY class
HAVING COUNT(class) >=5
1729. 求关注者的数量
Question
表: Followers
±------------±-----+
| Column Name | Type |
±------------±-----+
| user_id | int |
| follower_id | int |
±------------±-----+
(user_id, follower_id) 是这个表的主键(具有唯一值的列的组合)。
该表包含一个关注关系中关注者和用户的编号,其中关注者关注用户。
编写解决方案,对于每一个用户,返回该用户的关注者数量。
按 `user_id` 的顺序返回结果表。
查询结果的格式如下示例所示。
**示例 1:**
<pre><strong>输入:</strong>
Followers 表:
+---------+-------------+
| user_id | follower_id |
+---------+-------------+
| 0 | 1 |
| 1 | 0 |
| 2 | 0 |
| 2 | 1 |
+---------+-------------+
<strong>输出:</strong>
+---------+----------------+
| user_id | followers_count|
+---------+----------------+
| 0 | 1 |
| 1 | 1 |
| 2 | 2 |
+---------+----------------+
<strong>解释:</strong>
0 的关注者有 {1}
1 的关注者有 {0}
2 的关注者有 {0,1}</pre>
Answer
SELECT
user_id,
COUNT(follower_id) as 'followers_count'
FROM
Followers
GROUP BY user_id
ORDER BY
user_id
619. 只出现一次的最大数字
Question
MyNumbers 表:
±------------±-----+
| Column Name | Type |
±------------±-----+
| num | int |
±------------±-----+
该表可能包含重复项(换句话说,在SQL中,该表没有主键)。
这张表的每一行都含有一个整数。
**单一数字** 是在 `MyNumbers` 表中只出现一次的数字。
找出最大的 **单一数字** 。如果不存在 **单一数字** ,则返回 `null` 。
查询结果如下例所示。
**示例 1:**
<pre><strong>输入:</strong>
MyNumbers 表:
+-----+
| num |
+-----+
| 8 |
| 8 |
| 3 |
| 3 |
| 1 |
| 4 |
| 5 |
| 6 |
+-----+
<strong>输出:</strong>
+-----+
| num |
+-----+
| 6 |
+-----+
<strong>解释:</strong>单一数字有 1、4、5 和 6 。
6 是最大的单一数字,返回 6 。
</pre>
**示例 2:**
<pre><strong>输入:</strong>
MyNumbers table:
+-----+
| num |
+-----+
| 8 |
| 8 |
| 7 |
| 7 |
| 3 |
| 3 |
| 3 |
+-----+
<strong>输出:</strong>
+------+
| num |
+------+
| null |
+------+
<strong>解释:</strong>输入的表中不存在单一数字,所以返回 null 。</pre>
Answer
SELECT
MAX(num) as 'num'
FROM
(SELECT
num
FROM
MyNumbers
GROUP BY num
HAVING COUNT(num) = 1
ORDER BY num desc
LIMIT 0,1) t
NULL 輸出情況
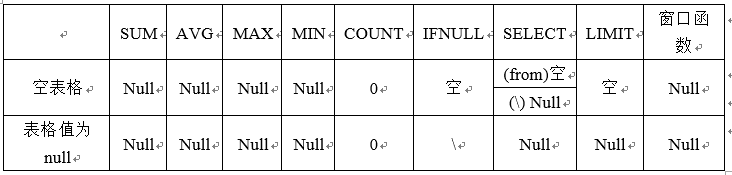
- select 空 param1 -> param1:null
- select param1 from 空 —> param1:空
-> 可以使用聚合函数进行空值null值的转换,具体的聚合函数包括SUM/AVG/MAX/MIN
-> 應當SELECT一個空值 而不是 FROM 一個空值
-> LIMIT , WHERE,HAVING 語句不會產生新的NULL
1045. 买下所有产品的客户
Question
Customer 表:
±------------±--------+
| Column Name | Type |
±------------±--------+
| customer_id | int |
| product_key | int |
±------------±--------+
该表可能包含重复的行。
customer_id 不为 NULL。
product_key 是 Product 表的外键(reference 列)。
`Product` 表:
±------------±--------+
| Column Name | Type |
±------------±--------+
| product_key | int |
±------------±--------+
product_key 是这张表的主键(具有唯一值的列)。
编写解决方案,报告 `Customer` 表中购买了 `Product` 表中所有产品的客户的 id。
返回结果表 **无顺序要求** 。
返回结果格式如下所示。
**示例 1:**
<pre><strong>输入:</strong>
Customer 表:
+-------------+-------------+
| customer_id | product_key |
+-------------+-------------+
| 1 | 5 |
| 2 | 6 |
| 3 | 5 |
| 3 | 6 |
| 1 | 6 |
+-------------+-------------+
Product 表:
+-------------+
| product_key |
+-------------+
| 5 |
| 6 |
+-------------+
<strong>输出:</strong>
+-------------+
| customer_id |
+-------------+
| 1 |
| 3 |
+-------------+
<strong>解释:</strong>
购买了所有产品(5 和 6)的客户的 id 是 1 和 3 。</pre>
Answer
SELECT
customer_id
FROM
Customer
GROUP BY customer_id
HAVING COUNT(DISTINCT product_key)=(SELECT COUNT(product_key) FROM Product)
1731. 每位经理的下属员工数量
Question
表:Employees
±------------±---------+
| Column Name | Type |
±------------±---------+
| employee_id | int |
| name | varchar |
| reports_to | int |
| age | int |
±------------±---------+
employee_id 是这个表中具有不同值的列。
该表包含员工以及需要听取他们汇报的上级经理的 ID 的信息。 有些员工不需要向任何人汇报(reports_to 为空)。
对于此问题,我们将至少有一个其他员工需要向他汇报的员工,视为一个经理。
编写一个解决方案来返回需要听取汇报的所有经理的 ID、名称、直接向该经理汇报的员工人数,以及这些员工的平均年龄,其中该平均年龄需要四舍五入到最接近的整数。
返回的结果集需要按照 `employee_id` 进行排序。
结果的格式如下:
**示例 1:**
<pre><strong>输入:</strong>
Employees 表:
+-------------+---------+------------+-----+
| employee_id | name | reports_to | age |
+-------------+---------+------------+-----+
| 9 | Hercy | null | 43 |
| 6 | Alice | 9 | 41 |
| 4 | Bob | 9 | 36 |
| 2 | Winston | null | 37 |
+-------------+---------+------------+-----+
<strong>输出:</strong>
+-------------+-------+---------------+-------------+
| employee_id | name | reports_count | average_age |
+-------------+-------+---------------+-------------+
| 9 | Hercy | 2 | 39 |
+-------------+-------+---------------+-------------+
<strong>解释:
</strong>Hercy 有两个需要向他汇报的员工, 他们是 Alice and Bob. 他们的平均年龄是 (41+36)/2 = 38.5, 四舍五入的结果是 39.
</pre>
**示例 2:**
<pre><strong>输入:</strong>
Employees 表:
+-------------+---------+------------+-----+
| employee_id | name | reports_to | age |
|-------------|---------|------------|-----|
| 1 | Michael | null | 45 |
| 2 | Alice | 1 | 38 |
| 3 | Bob | 1 | 42 |
| 4 | Charlie | 2 | 34 |
| 5 | David | 2 | 40 |
| 6 | Eve | 3 | 37 |
| 7 | Frank | null | 50 |
| 8 | Grace | null | 48 |
+-------------+---------+------------+-----+
<strong>输出:</strong>
+-------------+---------+---------------+-------------+
| employee_id | name | reports_count | average_age |
| ----------- | ------- | ------------- | ----------- |
| 1 | Michael | 2 | 40 |
| 2 | Alice | 2 | 37 |
| 3 | Bob | 1 | 37 |
+-------------+---------+---------------+-------------+</pre>
Answer
SELECT
e1.reports_to as 'employee_id',
e2.name as 'name',
COUNT(e1.reports_to) as 'reports_count',
ROUND(AVG(e1.age),0) as 'average_age'
FROM
Employees e1
LEFT JOIN Employees e2 ON e1.reports_to = e2.employee_id
WHERE
e1.reports_to is not null
GROUP BY e1.reports_to
ORDER BY employee_id
1789. 员工的直属部门
Question
表:Employee
±--------------±--------+
| Column Name | Type |
±--------------±--------+
| employee_id | int |
| department_id | int |
| primary_flag | varchar |
±--------------±--------+
这张表的主键为 employee_id, department_id (具有唯一值的列的组合)
employee_id 是员工的ID
department_id 是部门的ID,表示员工与该部门有关系
primary_flag 是一个枚举类型,值分别为(‘Y’, ‘N’). 如果值为’Y’,表示该部门是员工的直属部门。 如果值是’N’,则否
一个员工可以属于多个部门。当一个员工加入**超过一个部门**的时候,他需要决定哪个部门是他的直属部门。请注意,当员工只加入一个部门的时候,那这个部门将默认为他的直属部门,虽然表记录的值为 `'N'`.
请编写解决方案,查出员工所属的直属部门。
返回结果 **没有顺序要求** 。
返回结果格式如下例子所示:
**示例 1:**
<pre><strong>输入:</strong>
Employee table:
+-------------+---------------+--------------+
| employee_id | department_id | primary_flag |
+-------------+---------------+--------------+
| 1 | 1 | N |
| 2 | 1 | Y |
| 2 | 2 | N |
| 3 | 3 | N |
| 4 | 2 | N |
| 4 | 3 | Y |
| 4 | 4 | N |
+-------------+---------------+--------------+
<strong>输出:</strong>
+-------------+---------------+
| employee_id | department_id |
+-------------+---------------+
| 1 | 1 |
| 2 | 1 |
| 3 | 3 |
| 4 | 3 |
+-------------+---------------+
<strong>解释:</strong>
- 员工 1 的直属部门是 1
- 员工 2 的直属部门是 1
- 员工 3 的直属部门是 3
- 员工 4 的直属部门是 3</pre>
Answer
SELECT
e.employee_id,
department_id
FROM
Employee e
LEFT JOIN (
SELECT
employee_id,
COUNT(employee_id) as 'department'
FROM
Employee
GROUP BY employee_id
) n ON e.employee_id = n.employee_id
WHERE
(department = 1 AND primary_flag = 'N')
OR (department > 1 AND primary_flag = 'Y')
610. 判断三角形
Question
表: Triangle
±------------±-----+
| Column Name | Type |
±------------±-----+
| x | int |
| y | int |
| z | int |
±------------±-----+
在 SQL 中,(x, y, z)是该表的主键列。
该表的每一行包含三个线段的长度。
对每三个线段报告它们是否可以形成一个三角形。
以 **任意顺序 **返回结果表。
查询结果格式如下所示。
**示例 1:**
<pre><strong>输入:</strong>
Triangle 表:
+----+----+----+
| x | y | z |
+----+----+----+
| 13 | 15 | 30 |
| 10 | 20 | 15 |
+----+----+----+
<strong>输出:</strong>
+----+----+----+----------+
| x | y | z | triangle |
+----+----+----+----------+
| 13 | 15 | 30 | No |
| 10 | 20 | 15 | Yes |
+----+----+----+----------+</pre>
Answer
SELECT
x,
y,
z,
IF((ABS(z)>=ABS(x) AND ABS(z)>=ABS(y) AND ABS(x+y)>ABS(z))OR (ABS(x)>= ABS(z) AND ABS(x)>=ABS(y) AND ABS(z+y)>ABS(x)) OR (ABS(y)>=ABS(x) AND ABS(y)>=ABS(z) AND ABS(x+z)>ABS(y)),'Yes','No')as 'Triangle'
FROM
Triangle
select *,if(x+y>z and x+z>y and y+z>x, 'Yes', 'No') as triangle from Triangle;
180. 连续出现的数字
Question
表:Logs
±------------±--------+
| Column Name | Type |
±------------±--------+
| id | int |
| num | varchar |
±------------±--------+
在 SQL 中,id 是该表的主键。
id 是一个自增列。
找出所有至少连续出现三次的数字。
返回的结果表中的数据可以按 **任意顺序** 排列。
结果格式如下面的例子所示:
**示例 1:**
<pre><strong>输入:</strong>
Logs 表:
+----+-----+
| id | num |
+----+-----+
| 1 | 1 |
| 2 | 1 |
| 3 | 1 |
| 4 | 2 |
| 5 | 1 |
| 6 | 2 |
| 7 | 2 |
+----+-----+
<strong>输出:</strong>
Result 表:
+-----------------+
| ConsecutiveNums |
+-----------------+
| 1 |
+-----------------+
<strong>解释:</strong>1 是唯一连续出现至少三次的数字。</pre>
Answer
SELECT
DISTINCT num as 'ConsecutiveNums'
FROM
(
SELECT
id,
num,
Lead(num,1) OVER(ORDER BY id) as 'next',
Lead(num,2) OVER(ORDER BY id) as 'next2'
FROM
Logs
)n
WHERE
num = next and next = next2
1164. 指定日期的产品价格
Question
产品数据表: Products
±--------------±--------+
| Column Name | Type |
±--------------±--------+
| product_id | int |
| new_price | int |
| change_date | date |
±--------------±--------+
(product_id, change_date) 是此表的主键(具有唯一值的列组合)。
这张表的每一行分别记录了 某产品 在某个日期 更改后 的新价格。
编写一个解决方案,找出在 `2019-08-16` 时全部产品的价格,假设所有产品在修改前的价格都是 `10`** 。**
以 **任意顺序 **返回结果表。
结果格式如下例所示。
**示例 1:**
<pre><strong>输入:</strong>
Products 表:
+------------+-----------+-------------+
| product_id | new_price | change_date |
+------------+-----------+-------------+
| 1 | 20 | 2019-08-14 |
| 2 | 50 | 2019-08-14 |
| 1 | 30 | 2019-08-15 |
| 1 | 35 | 2019-08-16 |
| 2 | 65 | 2019-08-17 |
| 3 | 20 | 2019-08-18 |
+------------+-----------+-------------+
<strong>输出:</strong>
+------------+-------+
| product_id | price |
+------------+-------+
| 2 | 50 |
| 1 | 35 |
| 3 | 10 |
+------------+-------+</pre>
Answer
SELECT
DISTINCT p.product_id,
if(np.new_price,np.new_price,10) as 'price'
FROM Products p
LEFT JOIN
(SELECT
product_id,
new_price
FROM
(
SELECT
product_id,
new_price,
DENSE_RANK() OVER(PARTITION BY product_id ORDER BY change_date desc) cr
FROM
Products
WHERE
change_date <= '2019-08-16'
) r
WHERE
r.cr = 1) np ON np.product_id = p.product_id
給更改價格的日期排序 倒序排序獲得的第一位就是最後更改的記錄
SELECT
product_id,
new_price
FROM
(
SELECT
product_id,
new_price,
DENSE_RANK() OVER(PARTITION BY product_id ORDER BY change_date desc) cr
FROM
Products
WHERE
change_date <= '2019-08-16'
) r
WHERE
r.cr = 1
由于需要直到所有產品id,所以先查詢id 再用JOIN的方式添加更改後的價格,若無更改後價格則為原來的10 這裡需要使用IF() 進行條件判斷
SELECT
DISTINCT p.product_id,
if(np.new_price,np.new_price,10) as 'price'
FROM Products p
LEFT JOIN b
DISTINCT 可以用GROUP BY 替換
SELECT
p.product_id,
if(np.new_price,np.new_price,10) as 'price'
FROM Products p
LEFT JOIN np ON
GROUP BY p.product_id
1204. 最后一个能进入巴士的人
Question
表: Queue
±------------±--------+
| Column Name | Type |
±------------±--------+
| person_id | int |
| person_name | varchar |
| weight | int |
| turn | int |
±------------±--------+
person_id 是这个表具有唯一值的列。
该表展示了所有候车乘客的信息。
表中 person_id 和 turn 列将包含从 1 到 n 的所有数字,其中 n 是表中的行数。
turn 决定了候车乘客上巴士的顺序,其中 turn=1 表示第一个上巴士,turn=n 表示最后一个上巴士。
weight 表示候车乘客的体重,以千克为单位。
有一队乘客在等着上巴士。然而,巴士有 `1000` **千克** 的重量限制,所以其中一部分乘客可能无法上巴士。
编写解决方案找出 **最后一个** 上巴士且不超过重量限制的乘客,并报告 `person_name` 。题目测试用例确保顺位第一的人可以上巴士且不会超重。
返回结果格式如下所示。
**示例 1:**
<pre><strong>输入:</strong>
Queue 表
+-----------+-------------+--------+------+
| person_id | person_name | weight | turn |
+-----------+-------------+--------+------+
| 5 | Alice | 250 | 1 |
| 4 | Bob | 175 | 5 |
| 3 | Alex | 350 | 2 |
| 6 | John Cena | 400 | 3 |
| 1 | Winston | 500 | 6 |
| 2 | Marie | 200 | 4 |
+-----------+-------------+--------+------+
<strong>输出:</strong>
+-------------+
| person_name |
+-------------+
| John Cena |
+-------------+
<strong>解释:</strong>
为了简化,Queue 表按 turn 列由小到大排序。
+------+----+-----------+--------+--------------+
| Turn | ID | Name | Weight | Total Weight |
+------+----+-----------+--------+--------------+
| 1 | 5 | Alice | 250 | 250 |
| 2 | 3 | Alex | 350 | 600 |
| 3 | 6 | John Cena | 400 | 1000 | (最后一个上巴士)
| 4 | 2 | Marie | 200 | 1200 | (无法上巴士)
| 5 | 4 | Bob | 175 | ___ |
| 6 | 1 | Winston | 500 | ___ |
+------+----+-----------+--------+--------------+</pre>
Answer
SELECT
person_name
FROM(
SELECT
person_name,
turn,
SUM(weight) OVER (ORDER BY Turn) r
FROM
Queue) q
WHERE q.r <=1000
ORDER BY turn DESC
LIMIT 1
SUM() OVER() 窗口函数的方法进行排序,每一个乘客上去之后的总重量都会显示出来 然后筛选出添加后不超载的 所有人后 由上车顺序倒序排序,排第一的就是最后一个上车的人
output:
| person_name | turn | r |
|---|---|---|
| Alice | 1 | 250 |
| Alex | 2 | 600 |
| John Cena | 3 | 1000 |
| Marie | 4 | 1200 |
| Bob | 5 | 1375 |
| Winston | 6 | 1875 |
1907. 按分类统计薪水
Question
表: Accounts
±------------±-----+
| 列名 | 类型 |
±------------±-----+
| account_id | int |
| income | int |
±------------±-----+
在 SQL 中,account_id 是这个表的主键。
每一行都包含一个银行帐户的月收入的信息。
查询每个工资类别的银行账户数量。 工资类别如下:
* `"Low Salary"`:所有工资 **严格低于** `20000` 美元。
* `"Average Salary"`: **包含** 范围内的所有工资 `[$20000, $50000]` 。
* `"High Salary"`:所有工资 **严格大于** `50000` 美元。
结果表 **必须** 包含所有三个类别。 如果某个类别中没有帐户,则报告 `0` 。
按 **任意顺序** 返回结果表。
查询结果格式如下示例。
**示例 1:**
<pre><b>输入:</b>
Accounts 表:
+------------+--------+
| account_id | income |
+------------+--------+
| 3 | 108939 |
| 2 | 12747 |
| 8 | 87709 |
| 6 | 91796 |
+------------+--------+
<strong>输出:</strong>
+----------------+----------------+
| category | accounts_count |
+----------------+----------------+
| Low Salary | 1 |
| Average Salary | 0 |
| High Salary | 3 |
+----------------+----------------+
<strong>解释:</strong>
低薪: 有一个账户 2.
中等薪水: 没有.
高薪: 有三个账户,他们是 3, 6和 8.</pre>
Answer
SELECT
"Low Salary" as category,
SUM(IF(income<20000,1,0)) as 'accounts_count'
FROM
Accounts
UNION ALL
SELECT
"Average Salary" as category,
SUM(IF(income>=20000 AND income<=50000,1,0)) as 'accounts_count'
FROM
Accounts
UNION ALL
SELECT
"High Salary" as category,
SUM(IF(income>50000,1,0)) as 'accounts_count'
FROM
Accounts
子查詢
1978. 上级经理已离职的公司员工
Question
表: Employees
±------------±---------+
| Column Name | Type |
±------------±---------+
| employee_id | int |
| name | varchar |
| manager_id | int |
| salary | int |
±------------±---------+
在 SQL 中,employee_id 是这个表的主键。
这个表包含了员工,他们的薪水和上级经理的id。
有一些员工没有上级经理(其 manager_id 是空值)。
查找这些员工的id,他们的薪水严格少于 `$30000` 并且他们的上级经理已离职。当一个经理离开公司时,他们的信息需要从员工表中删除掉,但是表中的员工的 `manager_id` 这一列还是设置的离职经理的id 。
返回的结果按照 `employee_id `从小到大排序。
查询结果如下所示:
**示例:**
<pre><strong>输入:</strong>
Employees table:
+-------------+-----------+------------+--------+
| employee_id | name | manager_id | salary |
+-------------+-----------+------------+--------+
| 3 | Mila | 9 | 60301 |
| 12 | Antonella | null | 31000 |
| 13 | Emery | null | 67084 |
| 1 | Kalel | 11 | 21241 |
| 9 | Mikaela | null | 50937 |
| 11 | Joziah | 6 | 28485 |
+-------------+-----------+------------+--------+
<strong>输出:</strong>
+-------------+
| employee_id |
+-------------+
| 11 |
+-------------+
<strong>解释:</strong>
薪水少于 30000 美元的员工有 1 号(Kalel) 和 11号 (Joziah)。
Kalel 的上级经理是 11 号员工,他还在公司上班(他是 Joziah )。
Joziah 的上级经理是 6 号员工,他已经离职,因为员工表里面已经没有 6 号员工的信息了,它被删除了。</pre>
Answer
SELECT
employee_id
FROM
Employees
WHERE
salary < 30000
AND manager_id not in (SELECT employee_id FROM Employees)
ORDER BY employee_id
626. 换座位
Question
表: Seat
±------------±--------+
| Column Name | Type |
±------------±--------+
| id | int |
| student | varchar |
±------------±--------+
id 是该表的主键(唯一值)列。
该表的每一行都表示学生的姓名和 ID。
ID 序列始终从 1 开始并连续增加。
编写解决方案来交换每两个连续的学生的座位号。如果学生的数量是奇数,则最后一个学生的id不交换。
按 `id` **升序** 返回结果表。
查询结果格式如下所示。
**示例 1:**
<pre><strong>输入:</strong>
Seat 表:
+----+---------+
| id | student |
+----+---------+
| 1 | Abbot |
| 2 | Doris |
| 3 | Emerson |
| 4 | Green |
| 5 | Jeames |
+----+---------+
<strong>输出:</strong>
+----+---------+
| id | student |
+----+---------+
| 1 | Doris |
| 2 | Abbot |
| 3 | Green |
| 4 | Emerson |
| 5 | Jeames |
+----+---------+
<strong>解释:
</strong>请注意,如果学生人数为奇数,则不需要更换最后一名学生的座位。</pre>
Answer
WITH temporaryTable(total) AS (
SELECT COUNT(id)
FROM Seat
)
SELECT
(case
when mod(id,2)!=0 AND id=total then id
when mod(id,2)!=0 AND id!= total then id+1
else id-1
end) as 'id',
student
FROM
Seat, temporaryTable
ORDER BY id
1341. 电影评分
Question
表:Movies
±--------------±--------+
| Column Name | Type |
±--------------±--------+
| movie_id | int |
| title | varchar |
±--------------±--------+
movie_id 是这个表的主键(具有唯一值的列)。
title 是电影的名字。
表:`Users`
±--------------±--------+
| Column Name | Type |
±--------------±--------+
| user_id | int |
| name | varchar |
±--------------±--------+
user_id 是表的主键(具有唯一值的列)。
‘name’ 列具有唯一值。
表:`MovieRating`
±--------------±--------+
| Column Name | Type |
±--------------±--------+
| movie_id | int |
| user_id | int |
| rating | int |
| created_at | date |
±--------------±--------+
(movie_id, user_id) 是这个表的主键(具有唯一值的列的组合)。
这个表包含用户在其评论中对电影的评分 rating 。
created_at 是用户的点评日期。
Answer
SELECT
results
FROM (SELECT
COUNT(m.user_id) as 'num',
name as 'results'
FROM
MovieRating m
LEFT JOIN Users u ON m.user_id=u.user_id
GROUP BY name
ORDER BY num desc, name
LIMIT 1) r1
UNION ALL
SELECT
results
FROM
(SELECT
AVG(rating) as 'num',
title as 'results'
FROM
MovieRating
LEFT JOIN Movies mo ON mo.movie_id = MovieRating.movie_id
WHERE created_at BETWEEN '2020-02-01' AND '2020-02-29'
GROUP BY results
ORDER BY num desc, results
LIMIT 1) r2
1321. 餐馆营业额变化增长
Question
表: Customer
±--------------±--------+
| Column Name | Type |
±--------------±--------+
| customer_id | int |
| name | varchar |
| visited_on | date |
| amount | int |
±--------------±--------+
在 SQL 中,(customer_id, visited_on) 是该表的主键。
该表包含一家餐馆的顾客交易数据。
visited_on 表示 (customer_id) 的顾客在 visited_on 那天访问了餐馆。
amount 是一个顾客某一天的消费总额。
你是餐馆的老板,现在你想分析一下可能的营业额变化增长(每天至少有一位顾客)。
计算以 7 天(某日期 + 该日期前的 6 天)为一个时间段的顾客消费平均值。`average_amount` 要 **保留两位小数。**
结果按 `visited_on` **升序排序** 。
返回结果格式的例子如下。
**示例 1:**
<pre><strong>输入:</strong>
Customer 表:
+-------------+--------------+--------------+-------------+
| customer_id | name | visited_on | amount |
+-------------+--------------+--------------+-------------+
| 1 | Jhon | 2019-01-01 | 100 |
| 2 | Daniel | 2019-01-02 | 110 |
| 3 | Jade | 2019-01-03 | 120 |
| 4 | Khaled | 2019-01-04 | 130 |
| 5 | Winston | 2019-01-05 | 110 |
| 6 | Elvis | 2019-01-06 | 140 |
| 7 | Anna | 2019-01-07 | 150 |
| 8 | Maria | 2019-01-08 | 80 |
| 9 | Jaze | 2019-01-09 | 110 |
| 1 | Jhon | 2019-01-10 | 130 |
| 3 | Jade | 2019-01-10 | 150 |
+-------------+--------------+--------------+-------------+
<strong>输出:</strong>
+--------------+--------------+----------------+
| visited_on | amount | average_amount |
+--------------+--------------+----------------+
| 2019-01-07 | 860 | 122.86 |
| 2019-01-08 | 840 | 120 |
| 2019-01-09 | 840 | 120 |
| 2019-01-10 | 1000 | 142.86 |
+--------------+--------------+----------------+
<strong>解释:</strong>
第一个七天消费平均值从 2019-01-01 到 2019-01-07 是restaurant-growth/restaurant-growth/ (100 + 110 + 120 + 130 + 110 + 140 + 150)/7 = 122.86
第二个七天消费平均值从 2019-01-02 到 2019-01-08 是 (110 + 120 + 130 + 110 + 140 + 150 + 80)/7 = 120
第三个七天消费平均值从 2019-01-03 到 2019-01-09 是 (120 + 130 + 110 + 140 + 150 + 80 + 110)/7 = 120
第四个七天消费平均值从 2019-01-04 到 2019-01-10 是 (130 + 110 + 140 + 150 + 80 + 110 + 130 + 150)/7 = 142.86</pre>
Answer
with temp as(
SELECT
visited_on,
SUM(amount) as 'amount'
FROM
Customer
GROUP BY
visited_on
)
SELECT
b.visited_on,
SUM(b.amount) as 'amount',
ROUND(SUM(b.amount)/7,2) as 'average_amount'
FROM
temp b, temp a
WHERE
DATEDIFF(b.visited_on,a.visited_on) BETWEEN 0 AND 6
GROUP BY a.visited_on
HAVING COUNT(*)=7
更优方法
使用滑動窗口函數來計算當天到前七天的總的amount的值
with temp(min_visited) as ( #找到最早日期後續需要使用來找到第一個七天
SELECT
MIN(visited_on)
FROM
Customer
)
SELECT
visited_on,
amount,
ROUND(amount/7,2) as 'average_amount'
FROM
(SELECT #滑動窗口獲取 前七天的總數
DISTINCT visited_on,
SUM(amount) OVER(ORDER BY visited_on range interval 6 day preceding) 'amount'
FROM
Customer) t, temp
WHERE DATEDIFF(t.visited_on,temp.min_visited) >=6
SELECT #滑動窗口獲取 前七天的總數
DISTINCT visited_on,
SUM(amount) OVER(ORDER BY visited_on range interval 6 day preceding) 'amount'
FROM
Customer
output:
| visited_on | amount |
|---|---|
| 2019-01-01 | 100 |
| 2019-01-02 | 210 |
| 2019-01-03 | 330 |
| 2019-01-04 | 460 |
| 2019-01-05 | 570 |
| 2019-01-06 | 710 |
| 2019-01-07 | 860 |
| 2019-01-08 | 840 |
| 2019-01-09 | 840 |
| 2019-01-10 | 1000 |
根據最早的日期計算第一個七天的日期
可以通過WHERE 子查詢的方式
WHERE datediff(visited_on, (select min(visited_on) from Customer))>=6
或者 通過WITH 的方式事先查好
with temp(min_visited) as ( #找到最早日期後續需要使用來找到第一個七天
SELECT
MIN(visited_on)
FROM
Customer
)
WHERE DATEDIFF(t.visited_on,temp.min_visited) >=6
#### 602. [好友申请 II :谁有最多的好友](https://leetcode.cn/problems/friend-requests-ii-who-has-the-most-friends/)
##### Question
`RequestAccepted` 表:
±---------------±--------+
| Column Name | Type |
±---------------±--------+
| requester_id | int |
| accepter_id | int |
| accept_date | date |
±---------------±--------+
(requester_id, accepter_id) 是这张表的主键(具有唯一值的列的组合)。
这张表包含发送好友请求的人的 ID ,接收好友请求的人的 ID ,以及好友请求通过的日期。
编写解决方案,找出拥有最多的好友的人和他拥有的好友数目。
生成的测试用例保证拥有最多好友数目的只有 1 个人。
查询结果格式如下例所示。
**示例 1:**
<pre><strong>输入:</strong>
RequestAccepted 表:
+--------------+-------------+-------------+
| requester_id | accepter_id | accept_date |
+--------------+-------------+-------------+
| 1 | 2 | 2016/06/03 |
| 1 | 3 | 2016/06/08 |
| 2 | 3 | 2016/06/08 |
| 3 | 4 | 2016/06/09 |
+--------------+-------------+-------------+
<strong>输出:</strong>
+----+-----+
| id | num |
+----+-----+
| 3 | 3 |
+----+-----+
<strong>解释:</strong>
编号为 3 的人是编号为 1 ,2 和 4 的人的好友,所以他总共有 3 个好友,比其他人都多。</pre>
Answer
WITH temp1 (id) AS (
SELECT
requester_id as 'id'
FROM
RequestAccepted
UNION ALL
SELECT
accepter_id as 'id'
FROM
RequestAccepted
)
SELECT
id,
COUNT(*) as 'num'
FROM
temp1
GROUP BY id
ORDER BY num desc
LIMIT 1
585.2016年的投资
Question
Insurance 表:
±------------±------+
| Column Name | Type |
±------------±------+
| pid | int |
| tiv_2015 | float |
| tiv_2016 | float |
| lat | float |
| lon | float |
±------------±------+
pid 是这张表的主键(具有唯一值的列)。
表中的每一行都包含一条保险信息,其中:
pid 是投保人的投保编号。
tiv_2015 是该投保人在 2015 年的总投保金额,tiv_2016 是该投保人在 2016 年的总投保金额。
lat 是投保人所在城市的纬度。题目数据确保 lat 不为空。
lon 是投保人所在城市的经度。题目数据确保 lon 不为空。
编写解决方案报告 2016 年 (`tiv_2016`) 所有满足下述条件的投保人的投保金额之和:
* 他在 2015 年的投保额 (`tiv_2015`) 至少跟一个其他投保人在 2015 年的投保额相同。
* 他所在的城市必须与其他投保人都不同(也就是说 (`lat, lon`) 不能跟其他任何一个投保人完全相同)。
`tiv_2016` 四舍五入的 **两位小数** 。
查询结果格式如下例所示。
**示例 1:**
<pre><strong>输入:</strong>
Insurance 表:
+-----+----------+----------+-----+-----+
| pid | tiv_2015 | tiv_2016 | lat | lon |
+-----+----------+----------+-----+-----+
| 1 | 10 | 5 | 10 | 10 |
| 2 | 20 | 20 | 20 | 20 |
| 3 | 10 | 30 | 20 | 20 |
| 4 | 10 | 40 | 40 | 40 |
+-----+----------+----------+-----+-----+
<strong>输出:</strong>
+----------+
| tiv_2016 |
+----------+
| 45.00 |
+----------+
<strong>解释:
</strong>表中的第一条记录和最后一条记录都满足两个条件。
tiv_2015 值为 10 与第三条和第四条记录相同,且其位置是唯一的。
第二条记录不符合任何一个条件。其 tiv_2015 与其他投保人不同,并且位置与第三条记录相同,这也导致了第三条记录不符合题目要求。
因此,结果是第一条记录和最后一条记录的 tiv_2016 之和,即 45 。</pre>
Answer
SELECT
ROUND(sum(tiv_2016),2) as 'tiv_2016'
FROM
Insurance
WHERE
tiv_2015 IN (
SELECT
tiv_2015
FROM
Insurance
GROUP BY tiv_2015
HAVING COUNT(tiv_2015) > 1
)
AND CONCAT(LAT, LON) IN
(
SELECT
CONCAT(LAT, LON)
FROM
insurance
GROUP BY LAT , LON
HAVING COUNT(*) = 1
)
USING CONTACT() function:
CONCAT ( input_string1, input_string2 [, input_stringN ] ); 將結果拼接成一個字符串輸出為結果
Note that to add a separator during the concatenation, you use the
CONCAT_WS()function.
185. 部門工資前三高的所有員工
Question
表: Employee
±-------------±--------+
| Column Name | Type |
±-------------±--------+
| id | int |
| name | varchar |
| salary | int |
| departmentId | int |
±-------------±--------+
id 是该表的主键列(具有唯一值的列)。
departmentId 是 Department 表中 ID 的外键(reference 列)。
该表的每一行都表示员工的ID、姓名和工资。它还包含了他们部门的ID。
表: `Department`
±------------±--------+
| Column Name | Type |
±------------±--------+
| id | int |
| name | varchar |
±------------±--------+
id 是该表的主键列(具有唯一值的列)。
该表的每一行表示部门ID和部门名。
公司的主管们感兴趣的是公司每个部门中谁赚的钱最多。一个部门的 **高收入者** 是指一个员工的工资在该部门的 **不同** 工资中 **排名前三** 。
编写解决方案,找出每个部门中 **收入高的员工** 。
以 **任意顺序** 返回结果表。
返回结果格式如下所示。
**示例 1:**
<pre><strong>输入:</strong>
Employee 表:
+----+-------+--------+--------------+
| id | name | salary | departmentId |
+----+-------+--------+--------------+
| 1 | Joe | 85000 | 1 |
| 2 | Henry | 80000 | 2 |
| 3 | Sam | 60000 | 2 |
| 4 | Max | 90000 | 1 |
| 5 | Janet | 69000 | 1 |
| 6 | Randy | 85000 | 1 |
| 7 | Will | 70000 | 1 |
+----+-------+--------+--------------+
Department 表:
+----+-------+
| id | name |
+----+-------+
| 1 | IT |
| 2 | Sales |
+----+-------+
<strong>输出:</strong>
+------------+----------+--------+
| Department | Employee | Salary |
+------------+----------+--------+
| IT | Max | 90000 |
| IT | Joe | 85000 |
| IT | Randy | 85000 |
| IT | Will | 70000 |
| Sales | Henry | 80000 |
| Sales | Sam | 60000 |
+------------+----------+--------+
<strong>解释:
</strong>在IT部门:
- Max的工资最高
- 兰迪和乔都赚取第二高的独特的薪水
- 威尔的薪水是第三高的
在销售部:
- 亨利的工资最高
- 山姆的薪水第二高
- 没有第三高的工资,因为只有两名员工</pre>
Answer
SELECT
Department,
Employee,
salary
FROM(
SELECT
Department.name as 'Department',
Employee.name as 'Employee',
salary as 'Salary',
DENSE_RANK() OVER(PARTITION BY employee.departmentId ORDER BY salary DESC) as 'rank'
FROM
Employee
LEFT JOIN Department ON Department.id = Employee.departmentId) as a
WHERE
a.rank <=3
1667. 修复表中的名字
Question
表: Users
±---------------±--------+
| Column Name | Type |
±---------------±--------+
| user_id | int |
| name | varchar |
±---------------±--------+
user_id 是该表的主键(具有唯一值的列)。
该表包含用户的 ID 和名字。名字仅由小写和大写字符组成。
编写解决方案,修复名字,使得只有第一个字符是大写的,其余都是小写的。
返回按 `user_id` 排序的结果表。
返回结果格式示例如下。
**示例 1:**
<pre><strong>输入:</strong>
Users table:
+---------+-------+
| user_id | name |
+---------+-------+
| 1 | aLice |
| 2 | bOB |
+---------+-------+
<strong>输出:</strong>
+---------+-------+
| user_id | name |
+---------+-------+
| 1 | Alice |
| 2 | Bob |
+---------+-------+</pre>
Answer
select
user_id,
CONCAT(UPPER(SUBSTRING(name,1,1)),LOWER(SUBSTRING(name,2,length(name)))) as 'name'
FROM
Users
ORDER BY user_id
1527. 患某种疾病的患者
Question
患者信息表: Patients
±-------------±--------+
| Column Name | Type |
±-------------±--------+
| patient_id | int |
| patient_name | varchar |
| conditions | varchar |
±-------------±--------+
在 SQL 中,patient_id (患者 ID)是该表的主键。
‘conditions’ (疾病)包含 0 个或以上的疾病代码,以空格分隔。
这个表包含医院中患者的信息。
查询患有 I 类糖尿病的患者 ID (patient_id)、患者姓名(patient_name)以及其患有的所有疾病代码(conditions)。I 类糖尿病的代码总是包含前缀 `DIAB1` 。
按 **任意顺序** 返回结果表。
查询结果格式如下示例所示。
**示例 1:**
输入:
Patients表:
±-----------±-------------±-------------+
| patient_id | patient_name | conditions |
±-----------±-------------±-------------+
| 1 | Daniel | YFEV COUGH |
| 2 | Alice | |
| 3 | Bob | DIAB100 MYOP |
| 4 | George | ACNE DIAB100 |
| 5 | Alain | DIAB201 |
±-----------±-------------±-------------+
输出:
±-----------±-------------±-------------+
| patient_id | patient_name | conditions |
±-----------±-------------±-------------+
| 3 | Bob | DIAB100 MYOP |
| 4 | George | ACNE DIAB100 |
±-----------±-------------±-------------+
解释:Bob 和 George 都患有代码以 DIAB1 开头的疾病。
Answer
SELECT
*
FROM
Patients
WHERE
conditions LIKE 'DIAB1%'
OR conditions LIKE '% DIAB1%'
其他方法
select * from Patients where conditions regexp '\\bDIAB1.*'
正則表達式 來進行匹配
196. 删除重复的电子邮箱
Question
表: Person
±------------±--------+
| Column Name | Type |
±------------±--------+
| id | int |
| email | varchar |
±------------±--------+
id 是该表的主键列(具有唯一值的列)。
该表的每一行包含一封电子邮件。电子邮件将不包含大写字母。
编写解决方案** 删除** 所有重复的电子邮件,只保留一个具有最小 `id` 的唯一电子邮件。
(对于 SQL 用户,请注意你应该编写一个 `DELETE` 语句而不是 `SELECT` 语句。)
(对于 Pandas 用户,请注意你应该直接修改 `Person` 表。)
运行脚本后,显示的答案是 `Person` 表。驱动程序将首先编译并运行您的代码片段,然后再显示 `Person` 表。`Person` 表的最终顺序 **无关紧要** 。
返回结果格式如下示例所示。
**示例 1:**
<pre><strong>输入:</strong>
Person 表:
+----+------------------+
| id | email |
+----+------------------+
| 1 | john@example.com |
| 2 | bob@example.com |
| 3 | john@example.com |
+----+------------------+
<strong>输出:</strong>
+----+------------------+
| id | email |
+----+------------------+
| 1 | john@example.com |
| 2 | bob@example.com |
+----+------------------+
<strong>解释:</strong> john@example.com重复两次。我们保留最小的Id = 1。</pre>
Answer
DELETE FROM Person
WHERE id NOT IN (
SELECT id FROM (
SELECT MIN(id) AS id FROM Person GROUP BY email
) AS u
);
delete p1 from Person p1, Person p2 where p1.email=p2.email and p1.id>p2.id
176. 第二高的薪水
Question
Employee 表:
±------------±-----+
| Column Name | Type |
±------------±-----+
| id | int |
| salary | int |
±------------±-----+
id 是这个表的主键。
表的每一行包含员工的工资信息。
查询并返回 `Employee` 表中第二高的 **不同** 薪水 。如果不存在第二高的薪水,查询应该返回 `null(Pandas 则返回 None)` 。
查询结果如下例所示。
**示例 1:**
<pre><strong>输入:</strong>
Employee 表:
+----+--------+
| id | salary |
+----+--------+
| 1 | 100 |
| 2 | 200 |
| 3 | 300 |
+----+--------+
<strong>输出:</strong>
+---------------------+
| SecondHighestSalary |
+---------------------+
| 200 |
+---------------------+
</pre>
**示例 2:**
<pre><strong>输入:</strong>
Employee 表:
+----+--------+
| id | salary |
+----+--------+
| 1 | 100 |
+----+--------+
<strong>输出:</strong>
+---------------------+
| SecondHighestSalary |
+---------------------+
| null |
+---------------------+</pre>
Answer
SELECT
IFNULL(
(SELECT
salary
FROM
(SELECT
salary,
DENSE_RANK() OVER(ORDER BY salary DESC) r
FROM
Employee) e
WHERE e.r=2
LIMIT 1)
,null) as 'SecondHighestSalary'
由於輸出 null的原則是選擇了空而不是選擇的表為空 所以在最外面套一層 SELECT IFNULL((),NULL) 直接將結果為null的輸出成null
1484. 按日期分组销售产品
Question
表 Activities:
±------------±--------+
| 列名 | 类型 |
±------------±--------+
| sell_date | date |
| product | varchar |
±------------±--------+
该表没有主键(具有唯一值的列)。它可能包含重复项。
此表的每一行都包含产品名称和在市场上销售的日期。
编写解决方案找出每个日期、销售的不同产品的数量及其名称。
每个日期的销售产品名称应按词典序排列。
返回按 `sell_date` 排序的结果表。
结果表结果格式如下例所示。
**示例 1:**
输入:
Activities 表:
±-----------±------------+
| sell_date | product |
±-----------±------------+
| 2020-05-30 | Headphone |
| 2020-06-01 | Pencil |
| 2020-06-02 | Mask |
| 2020-05-30 | Basketball |
| 2020-06-01 | Bible |
| 2020-06-02 | Mask |
| 2020-05-30 | T-Shirt |
±-----------±------------+
输出:
±-----------±---------±-----------------------------+
| sell_date | num_sold | products |
±-----------±---------±-----------------------------+
| 2020-05-30 | 3 | Basketball,Headphone,T-shirt |
| 2020-06-01 | 2 | Bible,Pencil |
| 2020-06-02 | 1 | Mask |
±-----------±---------±-----------------------------+
解释:
对于2020-05-30,出售的物品是 (Headphone, Basketball, T-shirt),按词典序排列,并用逗号 ‘,’ 分隔。
对于2020-06-01,出售的物品是 (Pencil, Bible),按词典序排列,并用逗号分隔。
对于2020-06-02,出售的物品是 (Mask),只需返回该物品名。
Answer
SELECT
sell_date,
count(DISTINCT product) as 'num_sold',
group_concat(distinct product order by product SEPARATOR ',') as 'products'
FROM
Activities
GROUP BY sell_date
1327. 列出指定时间段内所有的下单产品
Question
表: Products
±-----------------±--------+
| Column Name | Type |
±-----------------±--------+
| product_id | int |
| product_name | varchar |
| product_category | varchar |
±-----------------±--------+
product_id 是该表主键(具有唯一值的列)。
该表包含该公司产品的数据。
表: `Orders`
±--------------±--------+
| Column Name | Type |
±--------------±--------+
| product_id | int |
| order_date | date |
| unit | int |
±--------------±--------+
该表可能包含重复行。
product_id 是表单 Products 的外键(reference 列)。
unit 是在日期 order_date 内下单产品的数目。
写一个解决方案,要求获取在 2020 年 2 月份下单的数量不少于 100 的产品的名字和数目。
返回结果表单的 **顺序无要求 ** 。
查询结果的格式如下。
**示例 1:**
<pre><strong>输入:</strong>
Products 表:
+-------------+-----------------------+------------------+
| product_id | product_name | product_category |
+-------------+-----------------------+------------------+
| 1 | Leetcode Solutions | Book |
| 2 | Jewels of Stringology | Book |
| 3 | HP | Laptop |
| 4 | Lenovo | Laptop |
| 5 | Leetcode Kit | T-shirt |
+-------------+-----------------------+------------------+
Orders 表:
+--------------+--------------+----------+
| product_id | order_date | unit |
+--------------+--------------+----------+
| 1 | 2020-02-05 | 60 |
| 1 | 2020-02-10 | 70 |
| 2 | 2020-01-18 | 30 |
| 2 | 2020-02-11 | 80 |
| 3 | 2020-02-17 | 2 |
| 3 | 2020-02-24 | 3 |
| 4 | 2020-03-01 | 20 |
| 4 | 2020-03-04 | 30 |
| 4 | 2020-03-04 | 60 |
| 5 | 2020-02-25 | 50 |
| 5 | 2020-02-27 | 50 |
| 5 | 2020-03-01 | 50 |
+--------------+--------------+----------+
<strong>输出:</strong>
+--------------------+---------+
| product_name | unit |
+--------------------+---------+
| Leetcode Solutions | 130 |
| Leetcode Kit | 100 |
+--------------------+---------+
<strong>解释:</strong>
2020 年 2 月份下单 product_id = 1 的产品的数目总和为 (60 + 70) = 130 。
2020 年 2 月份下单 product_id = 2 的产品的数目总和为 80 。
2020 年 2 月份下单 product_id = 3 的产品的数目总和为 (2 + 3) = 5 。
2020 年 2 月份 product_id = 4 的产品并没有下单。
2020 年 2 月份下单 product_id = 5 的产品的数目总和为 (50 + 50) = 100 。</pre>
Answer
SELECT
p.product_name,
SUM(o.unit) as 'unit'
FROM
Orders o
LEFT JOIN Products p ON p.product_id = o.product_id
WHERE
order_date BETWEEN '2020-02-01' AND '2020-02-29'
GROUP BY product_name
HAVING SUM(o.unit) >= 100
1517. 查找拥有有效邮箱的用户
Question
表: Users
±--------------±--------+
| Column Name | Type |
±--------------±--------+
| user_id | int |
| name | varchar |
| mail | varchar |
±--------------±--------+
user_id 是该表的主键(具有唯一值的列)。
该表包含了网站已注册用户的信息。有一些电子邮件是无效的。
编写一个解决方案,以查找具有有效电子邮件的用户。
一个有效的电子邮件具有前缀名称和域,其中:
1. **前缀** 名称是一个字符串,可以包含字母(大写或小写),数字,下划线 `'_'` ,点 `'.'` 和/或破折号 `'-'` 。前缀名称 **必须** 以字母开头。
2. **域** 为 `'@leetcode.com'` 。
以任何顺序返回结果表。
结果的格式如以下示例所示:
**示例 1:**
<pre><b>输入:</b>
Users 表:
+---------+-----------+-------------------------+
| user_id | name | mail |
+---------+-----------+-------------------------+
| 1 | Winston | winston@leetcode.com |
| 2 | Jonathan | jonathanisgreat |
| 3 | Annabelle | bella-@leetcode.com |
| 4 | Sally | sally.come@leetcode.com |
| 5 | Marwan | quarz#2020@leetcode.com |
| 6 | David | david69@gmail.com |
| 7 | Shapiro | .shapo@leetcode.com |
+---------+-----------+-------------------------+
<b>输出:</b>
+---------+-----------+-------------------------+
| user_id | name | mail |
+---------+-----------+-------------------------+
| 1 | Winston | winston@leetcode.com |
| 3 | Annabelle | bella-@leetcode.com |
| 4 | Sally | sally.come@leetcode.com |
+---------+-----------+-------------------------+
<b>解释:</b>
用户 2 的电子邮件没有域。
用户 5 的电子邮件带有不允许的 '#' 符号。
用户 6 的电子邮件没有 leetcode 域。
用户 7 的电子邮件以点开头。</pre>
Answer
SELECT
*
FROM
Users
WHERE
mail REGEXP '^[a-zA-Z][a-zA-Z0-9_.-]*\\@leetcode\\.com$'




![[Linux]:文件(下)](https://img-blog.csdnimg.cn/img_convert/15b9838da8def121b3a555d0a1206039.jpeg)