文章链接:https://arxiv.org/pdf/2408.15914
亮点直击
CoRe只用于输出embedding和注意力图,不需要生成图像,可以用于任意提示。
在身份保护和文本对齐方面表现出优越的性能,特别是对于需要高度视觉可变性的提示。
除了个性化一般对象外,方法还可以很好地实现人脸个性化,与最近的三种人脸个性化方法相比,生成了更多保留身份的人脸图像。
近年来,文本到图像的个性化生成技术取得了显著进展,能够针对用户提供的概念实现高质量且可控的图像合成。然而,现有的方法在平衡身份保留和文本对齐方面仍然面临挑战。本方法基于这样一个事实,即生成与提示语对齐的图像需要对提示语有精确的语义理解,这涉及到在CLIP文本编码器中准确处理新概念与其周围上下文token之间的交互。为了解决这个问题,目标是将新概念正确地嵌入文本编码器的输入embedding空间,从而实现与现有token的无缝整合。
本文引入了上下文正则化(Context Regularization, CoRe),通过对提示语中的上下文token进行正则化,来增强新概念文本embedding的学习。这基于这样一种洞察:只有当新概念的文本embedding被正确学习时,文本编码器对上下文token的输出向量才是合适的。CoRe可以应用于任意提示语,而不需要生成相应的图像,从而提高了学习到的文本embedding的泛化能力。此外,CoRe还可以作为一种测试时优化技术,进一步增强特定提示语的生成效果。
全面的实验结果表明,本文方法在身份保留和文本对齐方面均优于若干baseline方法。

方法
使用CoRe进行文本embedding学习
为了实现文本对齐的生成,目标是为新概念学习一种合适的文本embedding,使其能够与现有token兼容并无缝集成。这是因为文本对齐的生成依赖于对提示语的精确语义理解,而这又取决于新概念与其他token之间的正确交互。本方法不是直接改进新概念的嵌入,而是集中于约束新概念周围的上下文token。
本方法来自于两个关键见解。首先,只有当新概念的输入embedding被正确学习时,才能获得合适的上下文token输出embedding;否则,它会对文本编码器中的上下文token输出embedding产生不利影响。其次,当在提示语中将对象token替换为另一个时,上下文token的输出embedding和注意力图应大致保持一致。我们通过实验验证了这些见解,如下图2所示。例如,在提示语“沙漠中的狗”中,用文本反演方法(Textual Inversion)过拟合的embedding替换“狗”会显著改变其他token的输出embedding和注意力图。相比之下,用“猫”替换“狗”则保持了输出embedding和注意力图的一致性。
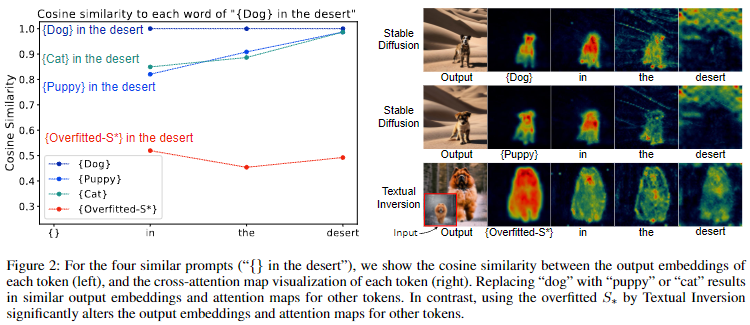
基于这些见解,提出了上下文正则化(Context Regularization, CoRe),通过正则化上下文token来增强新概念的文本embedding学习。对于包含新概念的训练提示语,通过用超类token替换新概念token来构造参考提示语。然后,对这两个提示语的上下文token输出embedding和注意力图施加相似性约束。需要注意的是,本文上下文正则化可以与任意提示语一起使用,因为它仅应用于输出embedding和注意力图,而不需要生成图像。因此构建了一个正则化提示语集,以覆盖广泛的提示语。
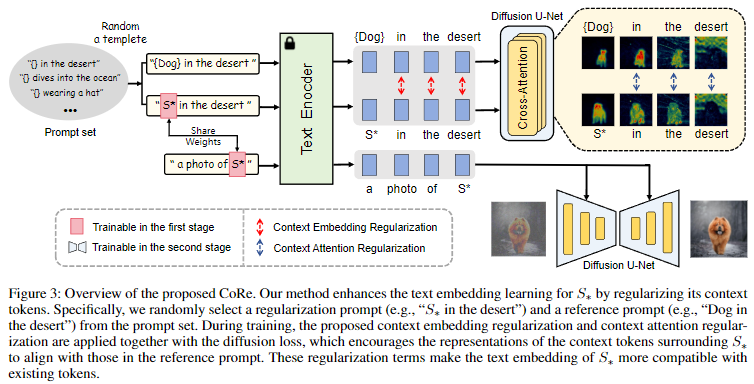
上下文嵌入正则化
形式上,从正则化提示语集中随机选择一个提示模板(例如,“在丛林中的{}”),分别填入新概念token和其超类token,生成一对提示语 和 (例如,“在丛林中的” 和 “在丛林中的[超类]”)。这两个提示语的输入embedding, 和 ,然后被输入到文本编码器 中,生成相应的输出embedding为 和 。通过最小化这两组输出embedding之间的平均余弦距离来实现:
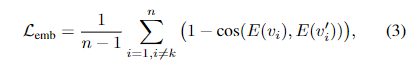
其中, 是与 和 [超类] 对应的索引, 是输出embedding的长度, 表示余弦相似度。需要注意的是,避免在 和 [超类] 之间施加约束,这是因为新概念与其超类通常存在显著差异,强制施加约束会导致身份保留能力的显著下降。
上下文注意力正则化 如前面图2所示,新概念的过拟合embedding会导致上下文token的注意力图错误。因此,利用注意力图进一步正则化新概念的文本embedding学习。本文引入了一个额外的正则化项,对提示语 和 的注意力图施加相似性约束。形式上,将 和 的输出embedding 和 输入到U-Net的16个不同的交叉注意力层中,分别生成16个注意力图 和 {} 。通过最小化这些注意力图均值的平均平方差来实现:
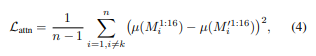
其中, 表示16个注意力图中所有值的均值, 是与 对应的索引, 是提示语的长度。
总体而言,完整优化目标定义为:
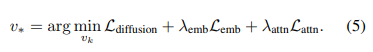
Embedding重缩放
正如 (Alaluf et al., 2023; Pang et al., 2024a) 所指出的那样,在优化过程中,新概念的文本embedding的尺度往往会变得过大,导致文本对齐能力的显著下降。受到 (Alaluf et al., 2023) 的启发,本文提出在优化过程中对文本embedding的范数进行重缩放,以缓解这一问题。具体来说,在一次优化步骤后,将更新后的embedding的范数重置为与前一步相匹配。重缩放后的embedding表示为:
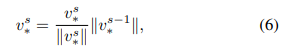
其中, 表示第 次优化步骤。在实际操作中,仅在优化的中间阶段应用这种重缩放策略,因为经验表明,在优化的开始或结束阶段进行重缩放可能会导致身份保留能力的下降,这可能是由于重缩放引入的信息丢失造成的。
Embedding到身份的训练策略
仅仅优化文本embedding不足以捕捉概念身份。受到 (Roich et al., 2022; Pang et al., 2024b) 的启发,本文提出了一个两阶段的训练策略。首先,使用 CoRe 来学习与现有token兼容的新概念的文本embedding。这产生了一个可编辑的嵌入,但仅对概念身份提供了粗略的描述。在第二阶段,冻结文本embedding,并微调 U-Net 的所有层,以精确捕捉概念身份。
测试时优化
在测试时,CoRe 可以作为一种测试时优化技术,来增强特定提示语的生成。具体来说,给定一个用于生成的提示语,通过使用 CoRe 执行一些额外的优化步骤,来细化与该提示语相关的输出embedding和注意力图。这种细化是在不使用扩散损失的情况下完成的。需要注意的是,在本文实验中,为了确保公平比较,在与baselines方法进行比较时并未应用此测试时优化策略。
实验
数据集
为了全面评估,研究者们收集了24个来自先前研究的概念 。按照 (Tewel et al., 2023) 的方法,将这些概念分为两组:有生命的物体(例如“猫”和“娃娃”)和无生命的物体(例如“钟”和“浆果碗”)。相应地,为这两组分别使用了两套提示语。一些提示语适用于所有概念,包括背景变化、概念颜色变化和艺术风格变化,而其他提示语则特定于有生命的物体,例如动作和服装变化。
评估设置
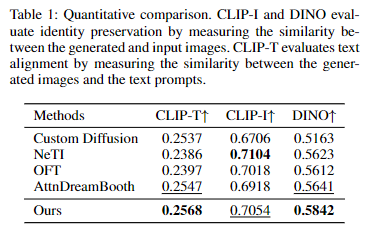
将本文方法与四种近期的baseline方法进行了比较:Custom Diffusion、NeTI、OFT和 AttnDreamBooth。对于定量评估,使用了一组20个提示语,并使用以下指标进行评估:
(1) 身份保留,通过CLIP-I和 DINO特征空间中生成图像与输入图像之间的视觉相似性来衡量;:
(2) 文本对齐,通过生成图像与提示语之间的 CLIP-T 相似性来衡量。按照 (Zeng et al., 2024) 的方法,CLIP-I 和 DINO 分数仅在前景遮罩的图像上计算,以消除背景变化,更好地反映概念身份的相似性。此外,涉及风格化或服装变化的提示语被排除在 CLIP-I 和 DINO 分数计算之外,因为这些修改会显著改变概念的外观。本文方法和基线的实现细节在附录中提供。
结果
定性评估
下图4展示了针对各种概念的个性化生成的视觉比较。我们使用了一组复杂的提示语进行评估,例如描绘宠物以类人姿势和着装(例如“穿着蜘蛛侠服装的在高楼之间摆动”),复杂的空间关系(例如“在一个漂浮在水上的盒子里”),以及多个变化的组合(例如“带有齿轮和管道的蒸汽朋克,在一个复古工厂中探索”)。如图所示,Custom Diffusion 无法生成文本对齐的图像,有时在生成过程中会丢弃新概念。NeTI 和 OFT 在新场景中准确适应给定概念方面存在困难。AttnDreamBooth 实现了改进的个性化生成,但仍未能生成身份保留且文本对齐的图像,尤其是对于需要高视觉可变性的提示语(例如“穿着蜘蛛侠服装的猫*”)。相比之下,本文方法生成的图像准确地保留了概念身份,并与复杂的提示语对齐。

虽然本文方法主要设计用于个性化一般物体,但在个性化人脸方面也表现良好。下图5展示了我们在人脸个性化方面的结果,与三种专门的人脸个性化方法进行比较,包括 Cross Initialization、PhotoMaker 和 Face2Diffusion。本文结果在身份保留方面优于这些基线方法。

定量评估
研究者们使用24个概念和20个文本提示语对每种方法进行了定量评估,每个概念的每个提示语生成32个样本。结果如下表1所示。需要注意的是,由于定量指标在准确评估这些提示语的生成图像质量方面的局限性,需要高视觉可变性的提示语被排除在定量评估之外,主要有两个原因。首先,这类提示语会显著改变概念的外观,使其不适合用于测量与输入图像的身份相似性。其次,那些在生成过程中忽略新概念的方法往往会获得较高的文本对齐分数,因为这些分数的计算不考虑新概念。因此,使用相对简单的提示语,本文方法在CLIP-T分数上略高于AttnDreamBooth。在CLIP-I和DINO分数方面,本文方法优于AttnDreamBooth,这可能是由于AttnDreamBooth在文本embedding学习方面的不足。NeTI获得了最高的CLIP-I分数,但在文本对齐方面得分最低,这表明其有过拟合新概念的倾向。总体而言,结果表明本文方法在身份保留和文本对齐之间实现了比基线方法更好的平衡。
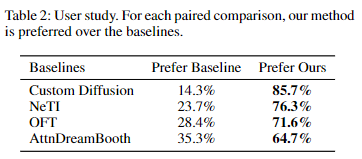
用户研究
研究者们进行了一项成对的人工偏好研究,以比较CoRe与基线方法。在每个问题中,展示两张生成的图像,一张来自本文方法,一张来自基线方法,使用相同的提示语。参与者被要求根据身份保留和文本对齐来评估生成的图像。我们从60名参与者那里收集了1200个反馈。正如下表2所示,参与者明显更偏好本文方法,这表明本文方法在身份保留和文本对齐方面具有优势。
消融研究
研究者们对方法的每个子模块进行了消融实验,以展示其贡献。图6展示了消融研究的结果。如图所示,缺少上下文嵌入正则化会导致身份保留和文本对齐的退化。缺少上下文注意力正则化的模型倾向于生成与输入相似的图像,表明可能对概念过拟合。此外,在没有应用嵌入重缩放策略的情况下,模型在文本对齐和身份保留方面也表现出轻微的退化。更多的消融研究结果可以在附录中找到。
测试时优化
研究者们评估了CoRe在测试时优化中的有效性。对于给定的特定生成提示语,我们使用CoRe执行额外的10次优化步骤,以细化该提示语的输出embedding和注意力图。如图7所示,这种策略有助于使生成结果更好地与提示语对齐,使之前被忽略的词汇能够在新图像中得到体现。例如,在第二行中,测试时优化有效地将意外出现的“狗”替换为正确的“孩子”,并恢复了丢失的“狐狸”。
结论与局限性
本文提出了一种名为CoRe的个性化方法,通过正则化上下文token来增强新概念的文本embedding学习。该方法基于这样的见解:只有当新概念的文本embedding正确学习时,才可能实现上下文token的适当输出embedding。本文实验结果表明,CoRe优于基线方法。如下图7所示,本文方法在涉及学习概念和其他物体的复杂组合时仍面临挑战,这部分是从预训练模型中继承的。CoRe可以作为一种测试时优化技术,来增强此类复杂组合的生成。

参考文献
[1]CoRe: Context-Regularized Text Embedding Learning for Text-to-Image Personalization
更多精彩内容,请关注公众号:AI生成未来