数学建模笔记—— 模糊综合评价
- 模糊综合评价
- 1. 模糊数学概述
- 2. 经典集合和模糊集合的基本概念
- 2.1 经典集合
- 2.2 模糊集合和隶属函数
- 1. 基本概念
- 2.模糊集合的表示方法
- 3. 模糊集合的分类
- 4. 隶属函数的确定方法
- 3. 评价问题概述
- 4. 一级模糊综合评价模型
- 典型例题
- 5. 多层次模糊综合评价模型
- 典型例题
- 6. python实现
模糊综合评价
1. 模糊数学概述
1965年,美国著名计算机与控制专家查德(L.A.Zadeh)教授提出了模糊的概念,并在国际期刊《Information and Control》并发表了第一篇用数学方法研究模糊现象的论文“Fuzzy Sets”(模糊集合),开创了模糊数学的新领域。
模糊是指客观事物差异的中间过渡中的“不分明性”或“亦此亦彼性”。如高个子与矮个子、年轻人与老年人、热水与凉水、环境污染严重与不严重等。在决策中,也有这种模糊的现象,如选举一个好干部,但怎样才算一个好干部?好干部与不好干部之间没有绝对分明和固定不变的界限。这些现象很难用经典的数学来描述。
模糊数学就是用数学方法研究与处理模糊现象的数学。它作为一门崭新的学科,它是继经典数学、统计数学之后发展起来的一个新的数学学科。经过短暂的沉默和争议之后,迅猛的发展起来了,而且应用越来越广泛。如今的模糊数学的应用已经遍及理、工、农、医及社会科学的各个领域,充分的表现了它强大的生命力和渗透力。统计数学是将数学的应用范围从确定性的领域扩大到了不确定性的领域,即从必然现象到偶然现象,而模糊数学则是把数学的应用范围从确定领域扩大到了模糊领域,即从精确现象到模糊现象。
实际中,我们处理现实的数学模型可以分成三大类:第一类是确定性数学模型,即模型的背景具有确定性,对象之间具有必然的关系。第二类是随机性的数学模型,即模型的背景具有随机性和偶然性。第三类是模糊性模型,即模型的背景及关系具有模糊性。
2. 经典集合和模糊集合的基本概念
2.1 经典集合
我们先来看经典集合的基本概念
- 集合:具有相同属性的事物的集体,例如:自然数集、实数集、颜色等
- 集合的基本属性:
- 互斥性:若 a ∈ A , b ∈ A a\in A,b\in A a∈A,b∈A,则 a ≠ b a\neq b a=b
- 确定性: a ∈ A , a ∉ A a\in A,a\notin A a∈A,a∈/A有且仅有之一发生(非此即彼)
- 数学上对于经典集合的刻画特征函数:
f
A
:
U
→
{
0
,
1
}
f_A{: }U\to \{ 0, 1\}
fA:U→{0,1}
U
:
U{: }
U:论域
f
A
f_A
fA表示
A
A
A集合的特征函数
比如 A A A为成绩及格的集合, U U U为全班成绩的集合则对 ∀ x ∈ U , f A ( x ) = { 1 , x ∈ A 0 , x ∉ A \forall x\in U,f_A(x)=\begin{cases}1,x\in A\\0,x\notin A\end{cases} ∀x∈U,fA(x)={1,x∈A0,x∈/A
2.2 模糊集合和隶属函数
1. 基本概念
而对于模糊集合和隶属函数来说:
- 模糊集合:用来描述模糊性概念的集合(美、丑、高、矮、年轻、年长)
- 与经典集合相比,模糊集合承认亦此亦彼
- 数学上对于模糊集合的刻画:
隶属函数 μ A : X → [ 0 , 1 ] \mu _{_{A}}{: }X\to [ 0, 1] μA:X→[0,1] (注意这里是一个区间 ) x → μ A ( x ) )x\to\mu_{_{A}}(x) )x→μA(x)
确定 X X X上的一个模糊集合 A , μ A A,\mu_A A,μA叫做 A A A的隶属函数, μ A ( x ) \mu_A(x) μA(x)叫做 x x x对模糊集A的隶属度
记为: A = { ( x , μ A ( x ) ) ∣ x ∈ X } A=\left\{\left(x,\mu_{A}(x)\right)|x\in X\right\} A={(x,μA(x))∣x∈X}显然,模糊集合A完全由隶属函数来刻画 μ A ( x ) = 0.5 \mu_{_A}(x)=0.5 μA(x)=0.5最具模糊性
举一个简单的例子,我们要衡量“年轻”的概念 A = A= A=“年轻”, X = ( 0 , 150 ) X=(0,150) X=(0,150)表示年龄的集合
在这里我们不好直接在0-150之间画个线把年轻和不年轻区分开,我们应该给一个隶属函数来进行描述
μ A ( x ) = { 1 , 0 < x < 20 40 − x 20 , 20 ≤ x ≤ 40 0 , 40 < x < 150 \mu_A\left(x\right)=\begin{cases}1,0<x<20\\\frac{40-x}{20},20\le x \le 40\\0,40<x<150\end{cases} μA(x)=⎩ ⎨ ⎧1,0<x<202040−x,20≤x≤400,40<x<150
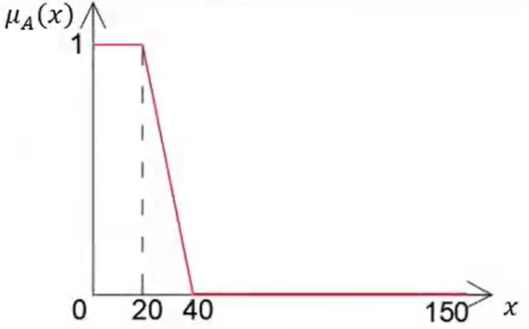
简单来说,隶属度就是某个元素属于某个模糊集合的程度,而隶属函数就是用来刻画隶属度的函数。
2.模糊集合的表示方法
当论域 X X X为有限集时,记 X = { x 1 , x 2 , ⋅ ⋅ ⋅ , x n } X=\{x_1,x_2,\cdotp\cdotp\cdotp,x_n\} X={x1,x2,⋅⋅⋅,xn},则 X X X 上的模糊集 A A A有下列三种常见的表示形式。
-
zadeh 表示法
当论域 X X X 为有限集时,记 X = { x 1 , x 2 , ⋯ , x n } X=\{x_1,x_2,\cdots,x_n\} X={x1,x2,⋯,xn},则 X X X 上的模糊集 A A A可以写成
A = ∑ i = 1 n μ A ( i ) x i = μ A ( x 1 ) x 1 + μ A ( x 2 ) x 2 + ⋯ + μ A ( x n ) x n A=\sum_{i=1}^n\frac{\mu_A(i)}{x_i}=\frac{\mu_A(x_1)}{x_1}+\frac{\mu_A(x_2)}{x_2}+\cdots+\frac{\mu_A(x_n)}{x_n} A=i=1∑nxiμA(i)=x1μA(x1)+x2μA(x2)+⋯+xnμA(xn)
注:“ ∑ ”和“ + \sum\text{”和“}+ ∑”和“+”不是求和的意思,只是概括集合的记号;“ μ A ( x i ) x i \frac{\mu_A(x_i)}{x_i} xiμA(xi)”不是分数,它表示点 x i x_i xi对模糊集 A A A的隶属度是 μ A ( x i ) \mu_A(x_i) μA(xi) 。 -
序偶表示法
A = { ( x 1 , μ A ( x 1 ) ) , ( x 2 , μ A ( x 2 ) ) , ⋯ , ( x n , μ A ( x n ) ) } A=\{(x_1,\mu_A(x_1)),(x_2,\mu_A(x_2)),\cdots,(x_n,\mu_A(x_n))\} A={(x1,μA(x1)),(x2,μA(x2)),⋯,(xn,μA(xn))}
- 向量表示法
A = ( μ A ( x 1 ) , μ A ( x 2 ) , ⋯ , μ A ( x n ) ) A=(\mu_A(x_1),\mu_A(x_2),\cdots,\mu_A(x_n)) A=(μA(x1),μA(x2),⋯,μA(xn))
当论域
X
X
X为无限集时,
X
X
X上的模糊集
A
A
A可以写成
A
=
∫
x
∈
X
μ
A
(
x
)
x
A=\int\limits_{x\in X}\frac{\mu_A(x)}{x}
A=x∈X∫xμA(x)
注:“ ∫ \int ∫"也不是表示积分的意思," μ A ( x i ) x i \frac{\mu_A(x_i)}{x_i} xiμA(xi)”也不是分数
示例:设论域 X = { x 1 ( 140 ) , x 2 ( 150 ) , x 3 ( 160 ) , x 4 ( 170 ) , x 5 ( 180 ) , x 6 ( 190 ) } X=\{x_1(140),x_2(150),x_3(160),x_4(170),x_5(180),x_6(190)\} X={x1(140),x2(150),x3(160),x4(170),x5(180),x6(190)}(单位:cm)表示人的身高, X X X上的一个模糊集“高个子”( A A A)的隶属函数定义为 μ A ( x ) = x − 140 190 − 140 \mu_A(x)=\frac{x-140}{190-140} μA(x)=190−140x−140
zadeh表示法
A = 0 x 1 + 0.2 x 2 + 0.4 x 3 + 0.6 x 4 + 0.8 x 5 + 1 x 6 A=\frac0{x_1}+\frac{0.2}{x_2}+\frac{0.4}{x_3}+\frac{0.6}{x_4}+\frac{0.8}{x_5}+\frac1{x_6} A=x10+x20.2+x30.4+x40.6+x50.8+x61序偶表示法
A = { ( 140 , 0 ) , ( 150 , 0.2 ) , ( 160 , 0.4 ) , ( 170 , 0.6 ) , ( 180 , 0.8 ) , ( 190 , 1 ) } A=\{(140,0),(150,0.2),(160,0.4),(170,0.6),(180,0.8),(190,1)\} A={(140,0),(150,0.2),(160,0.4),(170,0.6),(180,0.8),(190,1)}
- 向量表示法
A = ( 0 , 0.2 , 0.4 , 0.6 , 0.8 , 1 ) A=(0,0.2,0.4,0.6,0.8,1) A=(0,0.2,0.4,0.6,0.8,1)
3. 模糊集合的分类
模糊集合主要有三类,分别为偏小型,中间型和偏大型。其实也就类似于TOPSIS方法中的极大型、极小型、中间型、区间型指标。
举个例子,“年轻”就是一个偏小型的模糊集合,因为岁数越小,隶属度越大,就越“年轻”;“年老”则是一个偏大型的模糊集合,岁数越大,隶属度越大,越“年老”;而“中年”则是一个中间型集合,岁数只有处在某个中间的范围,隶属度才越大。总结来说,就是考虑“元素”与“隶属度”的关系,再类比一下,就是考虑隶属函数的单调性。
4. 隶属函数的确定方法
-
模糊统计法
模糊统计法的原理是,找多个人对同一个模糊概念进行描述,用隶属频率去定义隶属度。例如我们想知道30岁相对于“年轻”的隶属度,那就找来n个人问一问,如果其中有m个人认为30岁属于“年轻”的范畴,那m/n就可以用来作为30岁相对于“年轻”的隶属度。n越大时,走
符合实际情况,也就越准确。这个方法比较符合实际情况,但是往往通过发放问卷或者其他手段进行调查,数学建模比赛日时间有限,所以仅做介绍,基本不予采用。 -
借助已有的客观尺度
对于某些模糊集合,我们可以用已经有的指标去作为元素的隶属度。例如“小康家庭”这个模糊集合,就可以用“恩格尔系数(食品支出总额/家庭总支出)”衡量相应的隶属度。显而易见,家庭越接近小康水平,其恩格尔系数应该越低,那“1-恩格尔系数”就越大,我们便可以把“1-恩格尔系数”看作家庭相对于“小康家庭”的隶属度。对于“质量稳定”这一模糊集合,我们可以使用正品率衡量隶属度。注意:隶属度是在[0,1]之间的。如果找的指标不在,可以进行归一化处理。
-
指派法
指派方法是一种主观的方法,它主要依据人们的实践经验来确定某些模糊集隶属函数的一种方法。
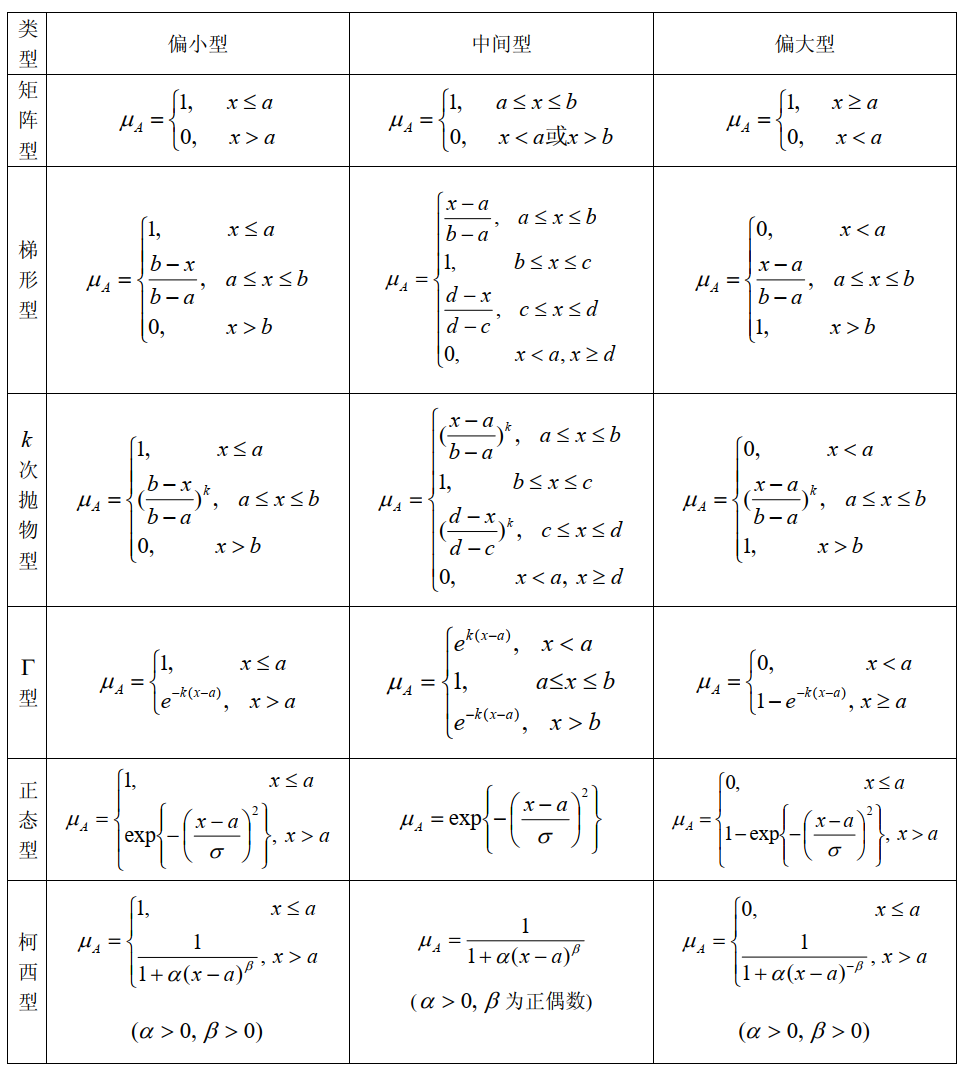
如果模糊集定义在实数域R上,则模糊集的隶属函数称为模糊分布。所谓指派方法就是根据问题的性质主观地选用某些形式地模糊分布,再根据实际测量数据确定其中所包含地参数,常用的模糊分布如表1所示。
实际中,根据问题对研究对象的描述来选择适当的模糊分布:
-
偏小型模糊分布一般适合于描述像**“小,少,浅,淡,冷,疏,青年”**等偏小的程度的模糊现象。
-
偏大型模糊分布一般适合于描述像**“大,多,深,浓,热,密,老年”**等偏大的程度的模糊现象。
-
中间型模糊分布一般适合于描述像**“中,适中,不太多,不太少,不太深,不太浓,暖和,中年”**等处于中间状态的模糊现象。
但是,表1给出的隶属函数都是近似的,应用时需要对实际问题进行分析,逐步修改进行完善,最后得到近似程度更好的隶属函数。
-
3. 评价问题概述
模糊评价问题是要把论域中的对象对应评语集中一个指定的评语或者将方案作为评语集并选择一个最优的方案。
在模糊综合评价中,引入三个集合:
-
因素集(评价指标集) U = { u 1 , u 2 , ⋯ , u n } U=\{u_1,u_2,\cdots,u_n\} U={u1,u2,⋯,un}
-
评语集(评价的结果) V = { v 1 , v 2 , ⋯ , v n } V= \{ v_1, v_2, \cdots , v_n\} V={v1,v2,⋯,vn}
-
权重集(指标的权重) A = { a 1 , a 2 , ⋅ ⋅ ⋅ , a n } A=\begin{Bmatrix}a_1,a_2,\cdotp\cdotp\cdotp,a_n\end{Bmatrix} A={a1,a2,⋅⋅⋅,an}
例:评价一名学生的表现
U = { U=\{ U={专业排名、课外实践、志愿服务、竞赛成绩 } \} }
V = { V=\{ V={优、良、差 } \} }
A = { 0.4 、 0.2 、 0.1 、 0.3 } A=\{0.4、0.2、0.1、0.3\} A={0.4、0.2、0.1、0.3}
模糊综合评价模型就是给定对象,用因素集的指标进行评价,从评语集中找到一个最适合它的评语。如果评语集中是方案的话,就是选出一个最恰当的方案。这种“合适”就是隶属度,隶属于某个模糊集合的程度。
4. 一级模糊综合评价模型
在对企业员工进行考核时,在指标个数较少的考核中,可以运用一级模糊综合评判。
-
确定因素集:评判的因素构成的评价指标体系集合称为因素集
对员工的表现,需要从多个方面进行综合评判,如员工的工作业绩、工作态度、沟通能力、政治表现等。记为 U = { u 1 , u 2 , ⋯ , u n } U=\{u_1,u_2,\cdots,u_n\} U={u1,u2,⋯,un},这里取因素集 U = { 政治表现 u 1 , 工作能力 u 2 , 工作态度 u 3 , 工作成绩 u 4 } U=\{政治表现u_1,工作能力u_2,工作态度u_3,工作成绩u_4\} U={政治表现u1,工作能力u2,工作态度u3,工作成绩u4}
-
确定评语集:由各种不同决断构成的集合称为评语集
评价往往有不同的等级,对员工评价可能有好、较好、中等、较差、很差等记为 V = { v 1 , v 2 , . . . , v n } V= \{ v_1, v_2, . . . , v_n\} V={v1,v2,...,vn}这里取评语集 V = { 优秀 v 1 , 良好 v 2 , 一般 v 3 , 较差 v 4 , 差 v 5 } V=\{优秀v_1,良好v_2,一般v_3,较差v_4,差v_5\} V={优秀v1,良好v2,一般v3,较差v4,差v5}
-
确定各因素的权重:因素集中各因素的评价中作用不同,需要确定权重,它是 U U U上的模糊向量
判断权重的方法很多,如Delphi法等,也可以用我们学习过的层次分析法和熵权法来确定权重
记为 A = [ a 1 , a 2 , . . . , a n ] A=[a_1,a_2,...,a_n] A=[a1,a2,...,an]这里取 A = [ 0.25 , 0.2 , 0.25 , 0.3 ] A=[0.25,0.2,0.25,0.3] A=[0.25,0.2,0.25,0.3]
-
确定模糊综合判断矩阵
对指标 u i u_i ui来说,对各个评语的隶属度为V上的模糊子集,对指标 u i u_i ui的评判记为记为 R i = [ r i 1 , r i 2 , . . . , r i n ] R_i=[r_{i1},r_{i2},...,r_{in}] Ri=[ri1,ri2,...,rin] 各指标的模糊综合判断矩阵为
R = [ r 11 r 12 ⋯ r 1 m r 21 r 22 ⋯ r 2 m ⋮ ⋮ ⋱ ⋮ r n 1 r n 2 ⋯ r n m ] R=\begin{bmatrix}r_{11}&r_{12}&\cdots&r_{1m}\\r_{21}&r_{22}&\cdots&r_{2m}\\\vdots&\vdots&\ddots&\vdots\\r_{n1}&r_{n2}&\cdots&r_{nm}\end{bmatrix} R= r11r21⋮rn1r12r22⋮rn2⋯⋯⋱⋯r1mr2m⋮rnm
这是一个从 U U U到 V V V的模糊关系矩阵。对员工的评定如果由模糊统计法来确定:-
u 1 u_1 u1比如由群众打分确定
r 1 = [ 0.1 , 0.5 , 0.4 , 0 , 0 ] r_1=[0.1,0.5,0.4,0,0] r1=[0.1,0.5,0.4,0,0]
上式表示,参与打分的群众中,10%的人认为该员工政治表现优秀,50%的人认为其政治表现良好等 -
u 2 , u 3 u_2,u_3 u2,u3由部门领导打分来确定
r 3 = [ 0.2 , 0.5 , 0.3 , 0 , 0 ] r 2 = [ 0.2 , 0.5 , 0.2 , 0.1 , 0 ] r_3=[\begin{matrix}0.2\:,0.5\:,0.3\:,0\:,0\end{matrix}]\\ r_2=[0.2,0.5,0.2,0.1,0] r3=[0.2,0.5,0.3,0,0]r2=[0.2,0.5,0.2,0.1,0] -
u 4 u_4 u4由单位考核组成员打分来确定
r 4 = [ 0.2 , 0.6 , 0.2 , 0 , 0 ] r_4=[0.2,0.6,0.2,0,0] r4=[0.2,0.6,0.2,0,0]
形成以 R i R_i Ri为第 i i i行构成评价矩阵(模糊综合判断矩阵)
R = [ 0.1 0.5 0.4 0 0 0.2 0.5 0.2 0.1 0 0.2 0.5 0.3 0 0 0.2 0.6 0.2 0 0 ] R=\begin{bmatrix}0.1&0.5&0.4&0&0\\0.2&0.5&0.2&0.1&0\\0.2&0.5&0.3&0&0\\0.2&0.6&0.2&0&0\end{bmatrix} R= 0.10.20.20.20.50.50.50.60.40.20.30.200.1000000
-
-
模糊综合评判,进行矩阵合成运算
选择评价的合成算子,将 A A A与 R R R 合成得到 B = ( b 1 , b 2 , ⋯ , b m ) B=(b_1,b_2,\cdots,b_m) B=(b1,b2,⋯,bm)
B = A O R = ( a 1 , a 2 , ⋯ , a n ) O ( r 11 r 12 ⋯ r 1 m r 21 r 22 ⋯ r 2 m ⋯ ⋯ ⋯ ⋯ r n 1 r n 2 ⋯ r n m ) b j = ( a 1 ∙ r 1 j ) + ( a 2 ∙ r 2 j ) + ⋯ + ( a n ∙ r n j ) , j = 1 , 2 , ⋯ , m B=A\mathrm{O}R=(a_{1},a_{2},\cdots,a_{n})\:\mathrm{O}\begin{pmatrix}r_{11}&r_{12}&\cdots&r_{1m}\\r_{21}&r_{22}&\cdots&r_{2m}\\\cdots&\cdots&\cdots&\cdots\\\\r_{n1}&r_{n2}&\cdots&r_{nm}\end{pmatrix}\\b_{j}=(a_{1}\bullet r_{1j})+(a_{2}\bullet r_{2j})+\cdots+(a_{n}\bullet r_{nj})\:,\quad j=1,2,\cdots,m B=AOR=(a1,a2,⋯,an)O r11r21⋯rn1r12r22⋯rn2⋯⋯⋯⋯r1mr2m⋯rnm bj=(a1∙r1j)+(a2∙r2j)+⋯+(an∙rnj),j=1,2,⋯,m常用的模糊算子有:
-
M
(
∧
,
∨
)
M(\land,\lor)
M(∧,∨), 即用
∧
\land
∧代替
∙
\bullet
∙,用
∨
\lor
∨代替+,式中
∧
\land
∧为取小运算,
∨
\lor
∨代表取大运算
2. M ( ∙ , ∨ ) M( \bullet , \vee ) M(∙,∨) , 即用实数乘法 ∙ \bullet ∙代替 ∙ \bullet ∙,用 ∨ \vee ∨代替 + + +
3. M ( ∧ , ⊕ ) M(\wedge,\oplus) M(∧,⊕),即用 ∧ \wedge ∧代替 ∙ \bullet ∙,用 ⊕ \oplus ⊕代替+,其中 a ⊕ b = min ( 1 , a + b ) a\oplus b=\min(1,a+b) a⊕b=min(1,a+b) ;
4. M ( ∙ , ⊕ ) M( \bullet , \oplus ) M(∙,⊕) , 即用实数乘法 ∙ \bullet ∙代替 ∙ \bullet ∙,用 ⊕ \oplus ⊕代替+。
经过比较研究, M ( ∙ , ⊕ ) M(\bullet,\oplus) M(∙,⊕)对各因素按权数大小,统筹兼顾,综合考虑,比较合理。
B = A ⋅ R = [ 0.25 , 0.2 , 0.25 , 0.3 ] ⋅ [ 0.1 0.5 0.4 0 0 0.2 0.5 0.2 0.1 0 0.2 0.5 0.3 0 0 0.2 0.6 0.2 0 0 ] = [ 0.175 , 0.53 , 0.275 , 0.02 , 0 ] B=A\cdot R=[0.25 ,0.2 ,0.25 ,0.3]\cdot\begin{bmatrix}0.1&0.5&0.4&0&0\\0.2&0.5&0.2&0.1&0\\0.2&0.5&0.3&0&0\\0.2&0.6&0.2&0&0\end{bmatrix}=[0.175,0.53,0.275,0.02,0] B=A⋅R=[0.25,0.2,0.25,0.3]⋅ 0.10.20.20.20.50.50.50.60.40.20.30.200.1000000 =[0.175,0.53,0.275,0.02,0]
取数值最大的评语作为综合评判结果,即评判结果为“良好”。
-
M
(
∧
,
∨
)
M(\land,\lor)
M(∧,∨), 即用
∧
\land
∧代替
∙
\bullet
∙,用
∨
\lor
∨代替+,式中
∧
\land
∧为取小运算,
∨
\lor
∨代表取大运算
典型例题
例:某露天煤矿有五个边坡设计方案,其各项参数根据分析计算结果得到边坡设计方案如下表
项目 方案1 方案2 方案3 方案4 方案5 可采矿量/万吨 4700 6700 5900 8800 7600 基建投资/万元 5000 5500 5300 6800 6000 采矿成本/(元/吨) 4.0 6.1 5.5 7.0 6.8 不稳定费用/万元 30 50 40 200 160 净现值/万元 1500 700 1000 50 100 据勘探,该矿探明储量8800吨,开采总投资不超过8000万元,试做出各方案的优劣排序,选出最佳方案
-
首先确定可采矿量的隶属函数
因为勘探的储量为8800吨,故可用资源的利用函数作为隶属函数
μ A ( x ) = x 8800 \mu_A(x)=\frac{x}{8800} μA(x)=8800x -
基建投资的隶属函数
投资约束是8000万元,所以
μ B ( x ) = 1 − x 8000 \mu_B\left(x\right)=1-\frac{x}{8000} μB(x)=1−8000x -
采矿成本的隶属函数
根据专家意见,采矿成本
a
1
≤
5.5
a_1\leq5.5
a1≤5.5元/吨为低成本,
a
2
=
8.0
a_2=8.0
a2=8.0元/吨为高成本,故
μ
c
(
x
)
=
{
1
,
0
≤
x
≤
a
1
a
2
−
x
a
2
−
a
1
,
a
1
≤
x
≤
a
2
0
,
a
2
<
x
\mu_c\left(x\right)=\begin{cases}1,&0\leq x\leq a_1\\\dfrac{a_2-x}{a_2-a_1},&a_1\leq x\leq a_2\\0,&a_2<x\end{cases}
μc(x)=⎩
⎨
⎧1,a2−a1a2−x,0,0≤x≤a1a1≤x≤a2a2<x
-
不稳定费用的隶属函数
μ D ( x ) = 1 − x 200 \mu_D\left(x\right)=1-\frac{x}{200} μD(x)=1−200x -
净现值的隶属函数
取上限15(百万元),下限0.5(百万元),采用线性隶属函数
μ E ( x ) = x − 50 1500 − 50 = x − 50 1450 \mu _{E}\left ( x\right ) = \frac {x- 50}{1500- 50}= \frac {x- 50}{1450} μE(x)=1500−50x−50=1450x−50
-
根据各个隶属函数计算出5个方案所对应的不同隶属度
项目 方案1 方案2 方案3 方案4 方案5 可采矿量/万吨 0.5341 0.7614 0.6705 1 0.8636 基建投资/万元 0.3750 0.3125 0.3375 0.15 0.25 采矿成本/(元/吨) 1 0.76 1 0.4 0.48 不稳定费用/万元 0.85 0.75 0.8 0 0.2 净现值/万元 1 0.4480 0.6552 0 0.0345 确定单因素评判矩阵
R = [ 0.5341 0.7614 0.6705 1.0000 0.8636 0.3750 0.3125 0.3375 0.1500 0.2500 0.8500 0.7500 0.8000 0.0000 0.2000 1.0000 0.7600 1.0000 0.4000 0.4800 1.0000 0.4480 0.6552 0.0000 0.0345 ] \begin{aligned}R=\begin{bmatrix}0.5341&0.7614&0.6705&1.0000&0.8636\\0.3750&0.3125&0.3375&0.1500&0.2500\\0.8500&0.7500&0.8000&0.0000&0.2000\\1.0000&0.7600&1.0000&0.4000&0.4800\\1.0000&0.4480&0.6552&0.0000&0.0345\end{bmatrix}\end{aligned} R= 0.53410.37500.85001.00001.00000.76140.31250.75000.76000.44800.67050.33750.80001.00000.65521.00000.15000.00000.40000.00000.86360.25000.20000.48000.0345
根据专家评价,诸因素在决策中占的权重为
A
=
(
0.25
,
0.20
,
0.20
,
0.10
,
0.25
)
A=(0.25,0.20,0.20,0.10,0.25)
A=(0.25,0.20,0.20,0.10,0.25)
注:没有专家可以用熵权法、层次分析法等
- 综合评价
B
=
A
⋅
R
=
(
0.7435
,
0.5919
,
0.6789
,
0.3600
,
0.3905
)
B=A\cdot R=(0.7435,0.5919,0.6789,0.3600,0.3905)
B=A⋅R=(0.7435,0.5919,0.6789,0.3600,0.3905)
由此可知:方案1最佳,方案3次之,方案4最差
5. 多层次模糊综合评价模型
多层次综合评价模型的解题步骤如下
-
给出被评价的对象集合 X = { x 1 , x 2 , . . . , x k } X=\{x_1,x_2,...,x_k\} X={x1,x2,...,xk}
-
确定因素集(亦称指标体系) U = { u 1 , u 2 , . . . , u n } U=\{u_1,u_2,...,u_n\} U={u1,u2,...,un}
若因素众多,往往将 U = { u 1 , u 2 , . . . , u n } U=\{u_1,u_2,...,u_n\} U={u1,u2,...,un}按某些属性分成s个子集
U i = { u 1 ( i ) , u 2 ( i ) , . . . , u n i ( i ) } U_i= \left \{ u_1^{( i) }, u_2^{( i) }, . . . , u_{n_i}^{( i) }\right \} Ui={u1(i),u2(i),...,uni(i)}, i = 1 , 2 , . . . , s i= 1, 2, . . . , s i=1,2,...,s且满足条件:
① ∑ i = 1 s n i = n ; \sum_{i=1}^sn_i=n; ∑i=1sni=n; ② ⋃ i = 1 s U i = U ; \bigcup_{i=1}^sU_i=U; ⋃i=1sUi=U; ③ U i ⋂ U j = ϕ , i ≠ j U_i\bigcap U_j=\phi,i\neq j Ui⋂Uj=ϕ,i=j
-
确定评语集 V = { v 1 , v 2 , . . . , v m } V=\{v_1,v_2,...,v_m\} V={v1,v2,...,vm}
-
由因素集 U i U_i Ui与评语集 V V V,可获得一个评价矩阵
R i = [ r 11 ( i ) r 12 ( i ) . . . r 1 m ( i ) ⋮ ⋮ ⋮ ⋮ r n i 1 ( i ) r n i 2 ( i ) . . . r n i m ( i ) ] R_i=\begin{bmatrix}r_{11}^{(i)}&r_{12}^{(i)}&...&r_{1m}^{(i)}\\\vdots&\vdots&\vdots&\vdots\\r_{n_i1}^{(i)}&r_{n_i2}^{(i)}&...&r_{n_im}^{(i)}\end{bmatrix} Ri= r11(i)⋮rni1(i)r12(i)⋮rni2(i)...⋮...r1m(i)⋮rnim(i) -
对每一个 U i U_{i} Ui,分别作出综合决策。
设 U i U_i Ui中的各因素权重的分配(模糊权向量)为 A i = ( a 1 ( i ) , a 2 ( i ) … , a n i ( i ) ) A_i=\left(a_1^{(i)},a_2^{(i)}\ldots,a_{n_i}^{(i)}\right) Ai=(a1(i),a2(i)…,ani(i)), 其中 ∑ t = 1 n i a t ( i ) = 1 \sum_{t=1}^{n_{i}}a_{t}^{(i)}=1 ∑t=1niat(i)=1。
若 R i R_i Ri为单因素模糊判断矩阵,则得到一级评价向量为:
B i = A i ⋅ R i = ( b i 1 , b i 2 , . . . , b i m ) B_{i}= A_{i}\cdot R_{i}= ( b_{i1}, b_{i2}, . . . , b_{im}) Bi=Ai⋅Ri=(bi1,bi2,...,bim), i = 1 , 2 , . . . , s i= 1, 2, . . . , s i=1,2,...,s
- 将每个
U
i
U_i
Ui视为一个元素,记
U
=
{
U
1
,
U
2
,
.
.
.
,
U
s
}
U=\{U_1,U_2,...,U_s\}
U={U1,U2,...,Us}, 于是
U
U
U又是单因素集,
U
U
U的单因素判断矩阵为
R = [ B 1 B 2 ⋮ B s ] = [ b 11 b 12 ⋯ b 1 m ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ b s 1 b s 2 ⋯ b s m ] R=\begin{bmatrix}B_1\\B_2\\\vdots\\B_s\end{bmatrix}=\begin{bmatrix}b_{11}&b_{12}&\cdots&b_{1m}\\\vdots&\vdots&\vdots&\vdots\\\vdots&\vdots&\vdots&\vdots\\b_{s1}&b_{s2}&\cdots&b_{sm}\end{bmatrix} R= B1B2⋮Bs = b11⋮⋮bs1b12⋮⋮bs2⋯⋮⋮⋯b1m⋮⋮bsm
每个 U i U_i Ui作为 U U U的一部分,反映了 U U U的某种属性,可以按他们的重要性给出权重分配
A = ( a 1 , a 2 , . . . , a s ) A=(a_1,a_2,...,a_s) A=(a1,a2,...,as)
于是得到二级模糊综合评价模型为:
B = A ⋅ R = ( b 1 , b 2 , . . . , b m ) B=A\cdot R=(b_1,b_2,...,b_m) B=A⋅R=(b1,b2,...,bm)
若每个子因素 U i ( i = 1 , 2 , . . . , s ) U_i(i=1,2,...,s) Ui(i=1,2,...,s)仍有较多因素,则可将 U i U_i Ui再划分,于是有三级或更高级模型
典型例题
对某陶瓷厂生产的6种产品的销售前景进行评判
- 影响评判对象因素集的选取
从产品情况、销售能力、市场需求三个方面考虑,根据专家评判法,得到评判对象因素集及子因素组成下图,因素后面数据表示权重
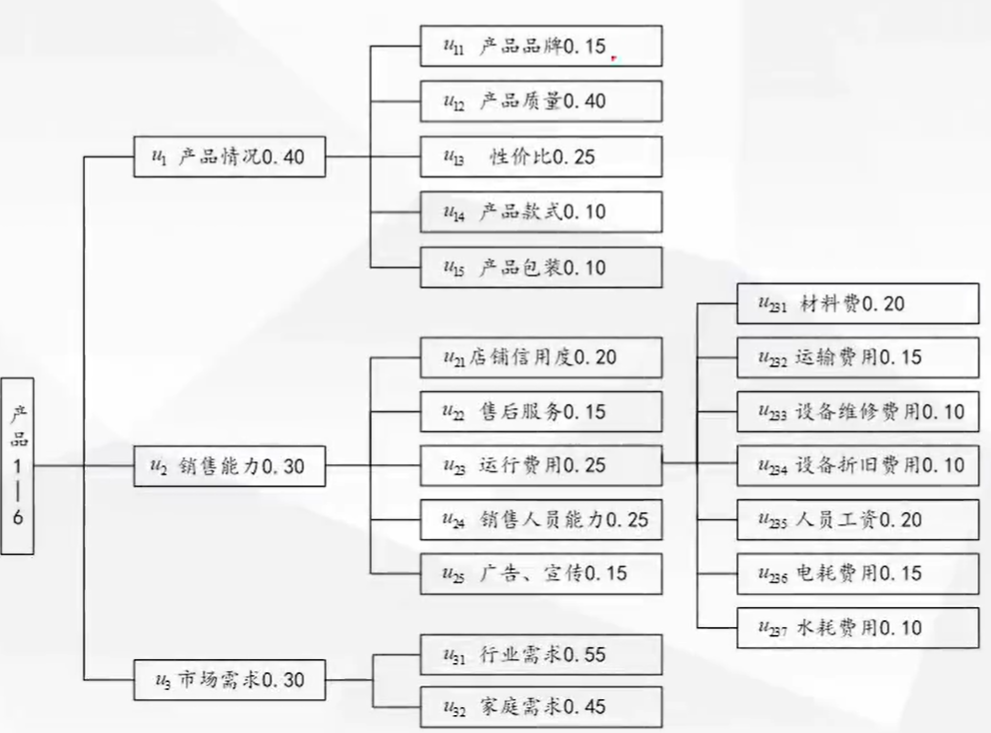
-
备择集 V = { 1 , 2 , 3 , 4 , 5 , 6 } V=\{1,2,3,4,5,6\} V={1,2,3,4,5,6}代表6种不同的陶瓷产品
-
一级模糊综合评价
“运行费用”下属的三级指标是定量指标,有具体数据,对这些数据归一化即求出各种产品的该指标与总指标的比重,得到单因素隶属度;由于其他因素均为定性指标,通过市场调查,把消费者的满意度作为单因素的隶属度,6种产品的单因素隶属度如下表:
因素 产品1 产品2 产品3 产品4 产品5 产品6 u 11 u_{11} u11产品品牌 0.12 0.18 0.17 0.23 0.13 0.17 u 12 u_{12} u12产品质量 0.15 0.13 0.18 0.25 0.12 0.17 u 13 u_{13} u13性价比 0.14 0.13 0.16 0.18 0.20 0.19 u 14 u_{14} u14产品款式 0.12 0.14 0.15 0.17 0.19 0.23 u 15 u_{15} u15 产品包装 0.16 0.12 0.13 0.25 0.18 0.16 u 21 u_{21} u21 店铺信用度 0.13 0.15 0.14 0.18 0.16 0.24 u 22 u_{22} u22售后服务 0.12 0.16 0.13 0.17 0.19 0.23 u 231 u_{231} u231材料费 0.18 0.14 0.18 0.14 0.13 0.23 u 232 u_{232} u232运输费用 0.15 0.2 0.15 0.25 0.1 0.15 u 233 u_{233} u233设备维修费用 0.25 0.12 0.13 0.12 0.18 0.2 u 234 u_{234} u234设备折旧费用 0.16 0.15 0.21 0.11 0.2 0.17 u 235 u_{235} u235人员工资 0.23 0.18 0.17 0.16 0.15 0.11 u 236 u_{236} u236电耗费用 0.19 0.13 0.12 0.12 0.11 0.33 u 237 u_{237} u237水耗费用 0.17 0.16 0.15 0.08 0.25 0.19 u 24 u_{24} u24销售人员能力 0.14 0.13 0.15 0.16 0.18 0.24 u 25 u_{25} u25广告宣传 0.16 0.15 0.15 0.17 0.18 0.19 u 31 u_{31} u31行业需求 0.15 0.14 0.13 0.18 0.14 0.26 u 32 u_{32} u32家庭需求 0.16 0.15 0.18 0.14 0.16 0.21 影响运行费用的各因素的单因素评价矩阵为:
R 23 = [ 0.18 0.14 0.18 0.14 0.13 0.23 0.15 0.20 0.15 0.25 0.10 0.15 0.25 0.12 0.13 0.12 0.18 0.20 0.16 0.15 0.21 0.11 0.20 0.17 0.23 0.18 0.17 0.16 0.15 0.11 0.19 0.13 0.12 0.12 0.11 0.33 0.17 0.16 0.15 0.08 0.25 0.19 ] \begin{gathered}R_{23}=\begin{bmatrix}0.18&0.14&0.18&0.14&0.13&0.23\\0.15&0.20&0.15&0.25&0.10&0.15\\0.25&0.12&0.13&0.12&0.18&0.20\\0.16&0.15&0.21&0.11&0.20&0.17\\0.23&0.18&0.17&0.16&0.15&0.11\\0.19&0.13&0.12&0.12&0.11&0.33\\0.17&0.16&0.15&0.08&0.25&0.19\end{bmatrix}\end{gathered} R23= 0.180.150.250.160.230.190.170.140.200.120.150.180.130.160.180.150.130.210.170.120.150.140.250.120.110.160.120.080.130.100.180.200.150.110.250.230.150.200.170.110.330.19
权重分配为: A 23 = [ 0.20 0.15 0.10 0.10 0.20 0.15 0.10 ] A_{23}=\begin{bmatrix}0.20&0.15&0.10&0.10&0.20&0.15&0.10\end{bmatrix} A23=[0.200.150.100.100.200.150.10],则运行费用的一级评判为:B 23 = A 23 ∙ R 23 = [ 0.1910 0.1565 0.1595 0.1465 0.1505 0.1960 ] B_{23}=A_{23}\bullet R_{23}=\begin{bmatrix}0.1910&0.1565&0.1595&0.1465&0.1505&0.1960\end{bmatrix} B23=A23∙R23=[0.19100.15650.15950.14650.15050.1960]
-
二级模糊综合评判
对产品情况、销售能力、市场需求下属的单因素指标进行二级评判
产品情况的二级评判如下:
R 1 = [ 0.12 0.18 0.17 0.23 0.13 0.17 0.15 0.13 0.18 0.25 0.12 0.17 0.14 0.13 0.16 0.18 0.20 0.19 0.12 0.14 0.15 0.17 0.19 0.23 0.16 0.12 0.13 0.25 0.18 0.16 ] A 1 = [ 0.15 0.40 0.25 0.10 0.10 ] B 1 = A 1 ∙ R 1 = [ 0.1410 0.1375 0.1655 0.2215 0.1545 0.1800 ] R_{1}=\begin{bmatrix}0.12&0.18&0.17&0.23&0.13&0.17\\0.15&0.13&0.18&0.25&0.12&0.17\\0.14&0.13&0.16&0.18&0.20&0.19\\0.12&0.14&0.15&0.17&0.19&0.23\\0.16&0.12&0.13&0.25&0.18&0.16\end{bmatrix}\\ \begin{aligned}&A_{1}=\begin{bmatrix}0.15&0.40&0.25&0.10&0.10\end{bmatrix}\\&B_{1}=A_{1}\bullet R_{1}=\begin{bmatrix}0.1410&0.1375&0.1655&0.2215&0.1545&0.1800\end{bmatrix}\end{aligned} R1= 0.120.150.140.120.160.180.130.130.140.120.170.180.160.150.130.230.250.180.170.250.130.120.200.190.180.170.170.190.230.16 A1=[0.150.400.250.100.10]B1=A1∙R1=[0.14100.13750.16550.22150.15450.1800]
将运行费用的一级评判结果作为二级评判的单因素评价值,即评判矩阵的第三行,则销售能力的评判如下
R 2 = [ 0.13 0.15 0.14 0.18 0.16 0.24 0.12 0.16 0.13 0.17 0.19 0.23 0.1910 0.1565 0.1595 0.1465 0.1505 0.1960 0.14 0.13 0.15 0.16 0.18 0.24 0.16 0.15 0.15 0.17 0.18 0.19 ] A 2 = [ 0.20 0.15 0.25 0.25 0.15 ] B 2 = A 2 • R 2 = [ 0.1508 0.1481 0.1474 0.1636 0.1701 0.2200 ] R_{2}=\begin{bmatrix}0.13&0.15&0.14&0.18&0.16&0.24\\0.12&0.16&0.13&0.17&0.19&0.23\\0.1910&0.1565&0.1595&0.1465&0.1505&0.1960\\0.14&0.13&0.15&0.16&0.18&0.24\\0.16&0.15&0.15&0.17&0.18&0.19\end{bmatrix}\\ \begin{aligned}&A_{2}=\begin{bmatrix}0.20&0.15&0.25&0.25&0.15\end{bmatrix}\\&B_{2}=A_{2}•R_{2}=\begin{bmatrix}0.1508&0.1481&0.1474&0.1636&0.1701&0.2200\end{bmatrix}\end{aligned} R2= 0.130.120.19100.140.160.150.160.15650.130.150.140.130.15950.150.150.180.170.14650.160.170.160.190.15050.180.180.240.230.19600.240.19 A2=[0.200.150.250.250.15]B2=A2•R2=[0.15080.14810.14740.16360.17010.2200]
市场需求的评判如下:
R 3 = [ 0.15 0.14 0.13 0.18 0.14 0.26 0.16 0.15 0.18 0.14 0.16 0.21 ] A 3 = [ 0.55 0.45 ] B 3 = A 3 • R 3 = [ 0.1545 0.1445 0.1525 0.1620 0.1490 0.2375 ] \begin{aligned}&R_{3}=\begin{bmatrix}0.15&0.14&0.13&0.18&0.14&0.26\\0.16&0.15&0.18&0.14&0.16&0.21\end{bmatrix}\\&A_{3}=\begin{bmatrix}0.55&0.45\end{bmatrix}\\&B_{3}=A_{3}•R_{3}=\begin{bmatrix}0.1545&0.1445&0.1525&0.1620&0.1490&0.2375\end{bmatrix}\end{aligned} R3=[0.150.160.140.150.130.180.180.140.140.160.260.21]A3=[0.550.45]B3=A3•R3=[0.15450.14450.15250.16200.14900.2375] -
三级模糊综合评价
将二级评判结果 B 1 , B 2 , B 3 B_1,B_2,B_3 B1,B2,B3作为行,组成三级评判的单因素评判矩阵
R = [ B 1 B 2 B 3 ] R=\begin{bmatrix}B_1\\B_2\\B_3\end{bmatrix} R= B1B2B3
权重及 A = [ 0.40 A= [ 0. 40 A=[0.40 0.30 0.30]
B = A ⋅ R = [ 0.1480 B= A\cdot R= [ 0. 1480 B=A⋅R=[0.1480 0.1428 0.1562 0.1863 0.1575 0.2093]
由结果可知,产品6得分最高,可加大投资,产品1、2得分较低,应减少投资
6. python实现
import numpy as np
# 1. 一级模糊综合评判
# 定义单因素评价矩阵
R23 = np.array(
[[0.18, 0.14, 0.18, 0.14, 0.13, 0.23],
[0.15, 0.20, 0.15, 0.25, 0.10, 0.15],
[0.25, 0.12, 0.13, 0.12, 0.18, 0.20],
[0.16, 0.15, 0.21, 0.11, 0.20, 0.17],
[0.23, 0.18, 0.17, 0.16, 0.15, 0.11],
[0.19, 0.13, 0.12, 0.12, 0.11, 0.33],
[0.17, 0.16, 0.15, 0.08, 0.25, 0.19],]
)
# 权重分配向量
A23 = np.array([0.20, 0.15, 0.10, 0.10, 0.20, 0.15, 0.10])
# 评价结果
# np.dot是numpy中的矩阵乘法函数,计算两个矩阵的内积
B23 = np.dot(A23, R23)
# 2. 二级模糊综合评判
# 产品情况的二级评判如下
R1 = np.array(
[[0.12, 0.18, 0.17, 0.23, 0.13, 0.17],
[0.15, 0.13, 0.18, 0.25, 0.12, 0.17],
[0.14, 0.13, 0.16, 0.18, 0.20, 0.19],
[0.12, 0.14, 0.15, 0.17, 0.19, 0.23],
[0.16, 0.12, 0.13, 0.25, 0.18, 0.16]]
)
# 权重分配向量
A1 = np.array([0.15, 0.40, 0.25, 0.10, 0.10])
# 评价结果
B1 = np.dot(A1, R1)
# 销售能力的二级评判如下
R2 = np.array(
[[0.13, 0.15, 0.14, 0.18, 0.16, 0.25],
[0.12, 0.16, 0.13, 0.17, 0.19, 0.23],
B23,
[0.14, 0.13, 0.15, 0.16, 0.18, 0.24],
[0.16, 0.15, 0.15, 0.17, 0.18, 0.19]]
)
A2 = np.array([0.2, 0.15, 0.25, 0.25, 0.15])
B2 = np.dot(A2, R2)
# 市场需求的二级评判如下
R3 = np.array(
[[0.15, 0.14, 0.13, 0.18, 0.14, 0.26],
[0.16, 0.15, 0.18, 0.14, 0.16, 0.21]]
)
A3 = np.array([0.55, 0.45])
R3 = np.dot(A3, R3)
# 3. 三级模糊综合评判
R = np.array([B1, B2, R3])
A = np.array([0.4, 0.3, 0.3])
B = np.dot(A, R)
print("产品的综合评价值为:", B)
输出:
产品的综合评价值为: [0.147975 0.1427875 0.1561625 0.1862875 0.1575375 0.20985 ]