Benchmarking Benchmark Leakage in Large Language Models
https://arxiv.org/abs/2404.18824
在大型语言模型中基准测试泄露的基准测试
文章目录
- 在大型语言模型中基准测试泄露的基准测试
- 摘要
- 1 引言

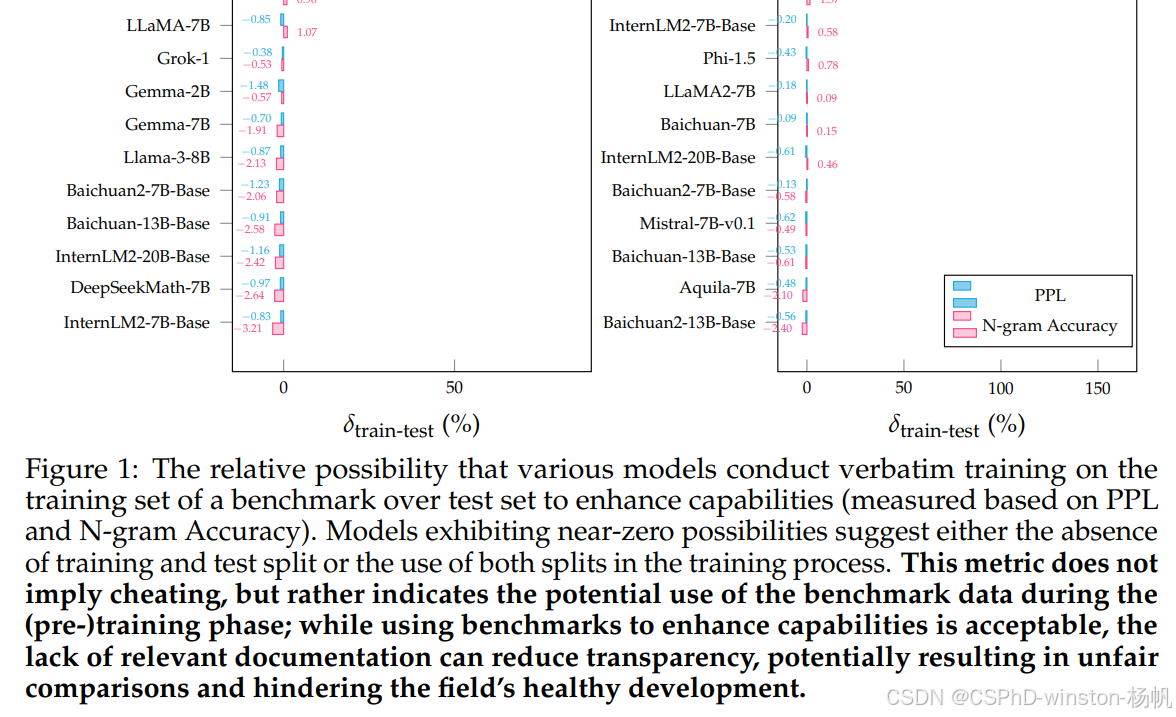
图1:不同模型在基准测试的训练集上进行逐字训练相对于测试集以增强能力(基于PPL和N-gram准确性测量)的相对可能性。表现出接近零可能性的模型表明要么没有训练和测试分割,要么在训练过程中使用了这两个分割。这个指标并不意味着作弊,而是表明在(预)训练阶段可能使用了基准测试数据;虽然使用基准测试来增强能力是可以接受的,但缺乏相关文档可能会降低透明度,可能导致不公平的比较,并阻碍该领域的健康发展。
摘要
随着预训练数据使用的不断扩大,基准数据集泄露现象变得越来越突出,这种情况因大型语言模型(LLMs)训练过程的不透明性以及监督数据的经常未披露的包含而加剧。这个问题扭曲了基准测试的有效性,并促进了可能不公平的比较,阻碍了该领域的健康发展。为了解决这个问题,我们引入了一个利用困惑度和N-gram准确性这两个简单且可扩展的指标来衡量模型在基准测试上的预测精度的检测流程,以识别潜在的数据泄露。通过在数学推理的背景下分析31个LLMs,我们揭示了大量的训练甚至测试集误用的情况,导致可能不公平的比较。这些发现促使我们提出了关于模型文档、基准设置和未来评估的一些建议。值得注意的是,我们提出了“基准透明度卡片”(表19),以鼓励清晰地记录基准测试的使用情况,促进LLMs的透明度和健康发展。我们已经公开了我们的排行榜、流程实现和模型预测,以促进未来的研究。
代码:https://github.com/GAIR-NLP/benbench
主页:https://gair-nlp.github.io/benbench
案例研究演示:https://huggingface.co/spaces/GAIR/benbench
1 引言
大型语言模型(LLMs)的快速发展导致了评估方法/协议(Chang等人,2024年)的显著滞后。加上LLMs训练的不透明性,这可能导致个人很难对评估结果形成客观的评估(Bommasani等人,2023年)。这高估了基准测试的有效性,忽视了潜在的不公平比较因素,并最终导致错过了科学上有意义的方向,浪费了社会资源。特别是,许多模型在预训练阶段明确涉及了监督数据,如GLM-130B(Zeng等人,2023年)、Qwen(Bai等人,2023年)、Nemotron-415B(Parmar等人,2024年)、InternLM-2(Cai等人,2024年)、MiniCPM(Hu等人,2024年)等。这一背景为讨论基准数据泄露的关键问题设定了舞台。随着对这些基准测试的依赖性增加,它们可能无意中被纳入LLMs的训练数据中,从而破坏了评估的完整性并复杂化了真正的能力评估。
在探索这个问题时,选择一个合适的测试平台至关重要。理想的测试平台应该表现出特定的特征:(1)它应该包括训练集和测试集,允许受控比较;(2)在这个基准测试上提高性能应该是固有的挑战,且有效的数据集有限。这种稀缺性增加了开发者使用基准数据来提高性能的诱惑;(3)它也应该引起广泛的兴趣,确保它是评估流行模型(如GPT-4(OpenAI,2023年)、Claude-3(Anthropic,2024年)等)的标准度量。鉴于这些标准,数学推理基准数据集GSM8K(Cobbe等人,2021年)和MATH(Hendrycks等人,2021b)成为我们测试平台的合适选择,它们允许我们深入研究数据泄露,但也提供了一个相关且具有挑战性的环境。我们使用这些数据集的主要目的是挖掘潜在的基准泄露,提高语言模型开发的透明度。
鉴于训练数据和模型细节通常是不透明的,且泄露检测受到诸如模型大小和训练策略等各种因素的影响,检测基准泄露并不是一项简单的任务。在这项工作中,我们不是在追求系统开发中的技术贡献;相反,我们试图鼓励这个领域的健康发展,特别是通过数学推理任务的视角,在以下方面:(1)总结各种预训练行为和检测基准泄露的挑战(见第2节):数据泄露可能在各种场景中发生,其检测受到不可靠假设、模型大小、训练策略、未知训练数据甚至无法访问的模型权重等多种因素的影响。(2)提出用于估计预训练行为的检测流程(见第3节):我们引入了一个简单、计算效率高且可扩展的流程,利用两个基本但有洞察力的原子指标:困惑度和N-gram准确性。这些指标有效地概括了语言建模的本质,分别从连续和离散的角度捕捉其细微差别。通过改写基准测试以创建不同的参考版本,我们可以检测模型的原子指标的差异,从而识别潜在的数据泄露。这个流程的有效性得到了彻底的元实验的支持(见第4节)。(3)现有模型的泄露分析(第5节):我们将调查扩展到分析现有模型(即,31个开源LLMs),揭示除了先前确定的泄露外,许多(即,大约一半)包括知名语言模型,可能无意中利用训练数据来提高它们在数学推理任务上的性能,导致不公平的优势。此外,我们的指标甚至可以进行实例级检测,揭示了许多模型中测试集泄露的可能性(见第5.3节)。例如,我们发现Qwen1.8B可以准确预测GSM8K训练集中的223个示例中的所有5-gram,以及MATH训练集中的67个,甚至在MATH测试集中还有额外的25个正确预测。(4)关于模型文档、基准设置和未来评估的建议(见第6节):基于这些发现,我们提出了包括模型文档、基准构建、公共基准访问和多角度评估在内的建议。我们特别强调模型文档的方面;我们建议模型在发布时应附带一个文档,记录是否使用了基准数据进行特定的性能提升以及是否进行了任何数据增强。为此,我们引入了基准透明度卡片(见第A.4节和表19),以促进这一过程,希望它能够被广泛采用,以促进LLMs的透明度和健康发展。
这些发现强调了我们在开发和评估语言模型的方法上进行范式转变的紧迫性。通过精确定位潜在的数据泄露,我们的工作倡导在模型开发中实现更大的透明度和公平性,引导社区朝着更道德和有效的研究方法发展。