本文展示了在PyTorch模型中添加Dropout正则化如何影响模型在损失和准确率方面的性能。

Dropout正则化在机器学习中的意义是什么?
Dropout正则化是机器学习中的一种方法,通过在神经网络中随机丢弃一些单元(神经元)来模拟同时训练多个网络架构的效果,这对于减少训练过程中的过拟合风险至关重要。
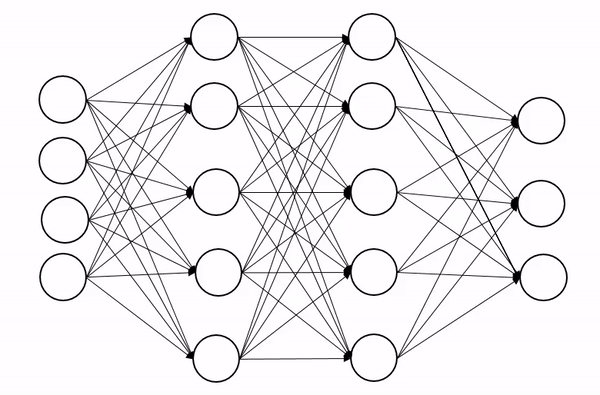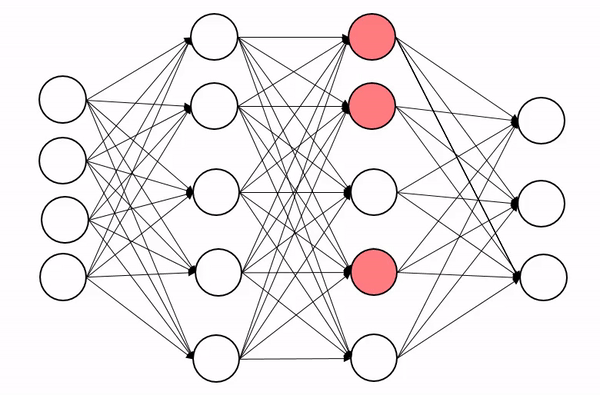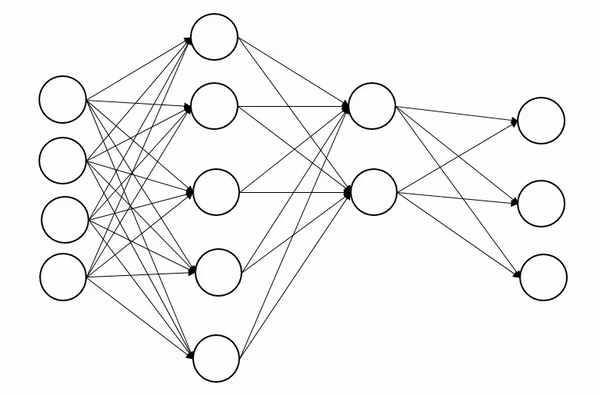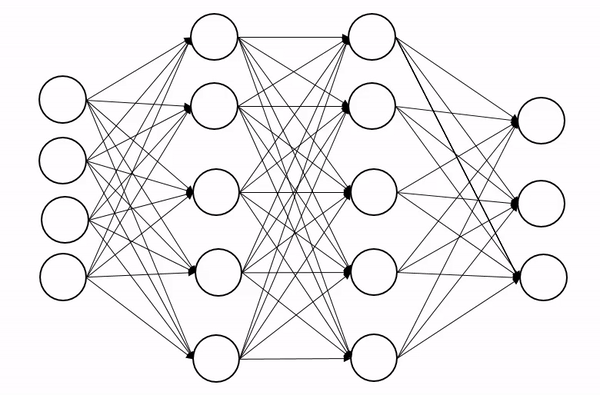
在PyTorch模型中集成Dropout
要在PyTorch模型中集成Dropout正则化,可以方便地使用torch.nn.Dropout类。
这个类需要一个输入参数,即dropout率,它表示神经元被关闭(即不参与训练)的概率。
Dropout可以应用于任何非输出层之后。
self.dropout = nn.Dropout(0.25)
观察Dropout对模型性能的影响
为了研究Dropout的效果,我们将训练一个用于图像分类的模型。
首先,我们将训练一个包含Dropout正则化的网络,然后训练一个不包含Dropout正则化的网络。
两个模型都将在Cifar-10数据集上进行8个周期的训练。
步骤 1: 导入必要的依赖和库
import torch
from torch import nn
from torch import optim
from torch.nn import functional as F
import torchvision
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
步骤 2: 加载数据集并准备DataLoader
BATCH_SIZE = 32
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root="./data", train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=BATCH_SIZE,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root="./data", train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=BATCH_SIZE,
shuffle=False, num_workers=2)
CLASS_NAMES = ("plane", "car", "bird", "cat",
"deer", "dog", "frog", "horse", "ship", "truck")
步骤 3: 加载并可视化部分数据
def show_batch(image_batch, label_batch):
plt.figure(figsize=(10,10))
for n in range(25):
ax = plt.subplot(5,5,n+1)
img = image_batch[n] / 2 + 0.5 # unnormalize
img = img.numpy()
plt.imshow(np.transpose(img, (1, 2, 0)))
plt.title(CLASS_NAMES[label_batch[n]])
plt.axis("off")
sample_images, sample_labels = next(iter(trainloader))
show_batch(sample_images, sample_labels)
输出:

步骤 4: 实现包含Dropout正则化的网络
class Net(nn.Module):
def __init__(self, input_shape=(3,32,32)):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 3)
self.conv2 = nn.Conv2d(32, 64, 3)
self.conv3 = nn.Conv2d(64, 128, 3)
self.pool = nn.MaxPool2d(2,2)
n_size = self._get_conv_output(input_shape)
self.fc1 = nn.Linear(n_size, 512)
self.fc2 = nn.Linear(512, 10)
self.dropout = nn.Dropout(0.25)
def _get_conv_output(self, shape):
batch_size = 1
input = torch.autograd.Variable(torch.rand(batch_size, *shape))
output_feat = self._forward_features(input)
n_size = output_feat.data.view(batch_size, -1).size(1)
return n_size
def _forward_features(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = self.pool(F.relu(self.conv3(x)))
return x
def forward(self, x):
x = self._forward_features(x)
x = x.view(x.size(0), -1)
x = self.dropout(x)
x = F.relu(self.fc1(x))
x = self.dropout(x)
x = self.fc2(x)
return x
步骤 5: 实现训练过程
def train(model, device, train_loader, optimizer, criterion, epoch, steps_per_epoch=20):
# Switch model to training mode. This is necessary for layers like dropout, batchnorm etc which behave differently in training and evaluation mode
model.train()
train_loss = 0
train_total = 0
train_correct = 0
# We loop over the data iterator, and feed the inputs to the network and adjust the weights.
for batch_idx, (data, target) in enumerate(train_loader, start=0):
# Load the input features and labels from the training dataset
data, target = data.to(device), target.to(device)
# Reset the gradients to 0 for all learnable weight parameters
optimizer.zero_grad()
# Forward pass: Pass image data from training dataset, make predictions about class image belongs to (0-9 in this case)
output = model(data)
# Define our loss function, and compute the loss
loss = criterion(output, target)
train_loss += loss.item()
scores, predictions = torch.max(output.data, 1)
train_total += target.size(0)
train_correct += int(sum(predictions == target))
# Reset the gradients to 0 for all learnable weight parameters
optimizer.zero_grad()
# Backward pass: compute the gradients of the loss w.r.t. the model"s parameters
loss.backward()
# Update the neural network weights
optimizer.step()
acc = round((train_correct / train_total) * 100, 2)
print("Epoch [{}], Loss: {}, Accuracy: {}".format(epoch, train_loss/train_total, acc), end="")
步骤 6: 实现测试函数
def test(model, device, test_loader, criterion, classes):
# Switch model to evaluation mode. This is necessary for layers like dropout, batchnorm etc which behave differently in training and evaluation mode
model.eval()
test_loss = 0
test_total = 0
test_correct = 0
example_images = []
with torch.no_grad():
for data, target in test_loader:
# Load the input features and labels from the test dataset
data, target = data.to(device), target.to(device)
# Make predictions: Pass image data from test dataset, make predictions about class image belongs to (0-9 in this case)
output = model(data)
# Compute the loss sum up batch loss
test_loss += criterion(output, target).item()
scores, predictions = torch.max(output.data, 1)
test_total += target.size(0)
test_correct += int(sum(predictions == target))
acc = round((test_correct / test_total) * 100, 2)
print(" Test_loss: {}, Test_accuracy: {}".format(test_loss/test_total, acc))
步骤 7: 初始化网络的损失函数和优化器
net = Net().to(device)
print(net)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters())
输出:
Net(
(conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1))
(conv2): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1))
(conv3): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1))
(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(fc1): Linear(in_features=512, out_features=512, bias=True)
(fc2): Linear(in_features=512, out_features=10, bias=True)
(dropout): Dropout(p=0.25, inplace=False)
)
步骤 8: 开始训练
ffor epoch in range(8):
train(net, device, trainloader, optimizer, criterion, epoch)
test(net, device, testloader, criterion, CLASS_NAMES)
print("Finished Training")
输出:
Epoch [0], Loss: 0.0461193907892704, Accuracy: 45.45 Test_loss: 0.036131812924146654, Test_accuracy: 58.58
Epoch [1], Loss: 0.03446852257728577, Accuracy: 60.85 Test_loss: 0.03089196290373802, Test_accuracy: 65.27
Epoch [2], Loss: 0.029333480607271194, Accuracy: 66.83 Test_loss: 0.027052838513255118, Test_accuracy: 70.41
Epoch [3], Loss: 0.02650276515007019, Accuracy: 70.21 Test_loss: 0.02630699208676815, Test_accuracy: 70.99
Epoch [4], Loss: 0.024451716771125794, Accuracy: 72.41 Test_loss: 0.024404651895165445, Test_accuracy: 73.03
Epoch [5], Loss: 0.022718262011408807, Accuracy: 74.35 Test_loss: 0.023125074282288553, Test_accuracy: 74.86
Epoch [6], Loss: 0.021408387248516084, Accuracy: 75.76 Test_loss: 0.023151200053095816, Test_accuracy: 74.43
Epoch [7], Loss: 0.02033562403023243, Accuracy: 76.91 Test_loss: 0.023537022879719736, Test_accuracy: 73.93
Finished Training
不含Dropout正则化的网络
接下来,我们将构建相同的网络,但不包含Dropout层。
我们将在相同的数据集和训练周期上训练这个网络,并评估Dropout对网络性能的影响,这里将使用相同的训练和测试函数。
步骤 1: 实现网络
class Net(nn.Module):
def __init__(self, input_shape=(3,32,32)):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 3)
self.conv2 = nn.Conv2d(32, 64, 3)
self.conv3 = nn.Conv2d(64, 128, 3)
self.pool = nn.MaxPool2d(2,2)
n_size = self._get_conv_output(input_shape)
self.fc1 = nn.Linear(n_size, 512)
self.fc2 = nn.Linear(512, 10)
def _get_conv_output(self, shape):
batch_size = 1
input = torch.autograd.Variable(torch.rand(batch_size, *shape))
output_feat = self._forward_features(input)
n_size = output_feat.data.view(batch_size, -1).size(1)
return n_size
def _forward_features(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = self.pool(F.relu(self.conv3(x)))
return x
def forward(self, x):
x = self._forward_features(x)
x = x.view(x.size(0), -1)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
步骤 2: 初始化损失函数和优化器
net = Net().to(device)
print(net)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters())
输出:
Net(
(conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1))
(conv2): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1))
(conv3): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1))
(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(fc1): Linear(in_features=512, out_features=512, bias=True)
(fc2): Linear(in_features=512, out_features=10, bias=True)
步骤 3: 开始训练
for epoch in range(8):
train(net, device, trainloader, optimizer, criterion, epoch)
test(net, device, testloader, criterion, CLASS_NAMES)
print("Finished Training")
输出:
Epoch [0], Loss: 0.04425342482566833, Accuracy: 48.29 Test_loss: 0.03506121407747269, Test_accuracy: 59.93
Epoch [1], Loss: 0.0317487561249733, Accuracy: 63.97 Test_loss: 0.029791217082738877, Test_accuracy: 66.4
Epoch [2], Loss: 0.026000032302737237, Accuracy: 70.83 Test_loss: 0.027046055325865747, Test_accuracy: 69.97
Epoch [3], Loss: 0.022179243130385877, Accuracy: 75.11 Test_loss: 0.02481114484965801, Test_accuracy: 72.95
Epoch [4], Loss: 0.01933788091301918, Accuracy: 78.26 Test_loss: 0.024382170912623406, Test_accuracy: 73.55
Epoch [5], Loss: 0.016771901984512807, Accuracy: 81.04 Test_loss: 0.024696413831412793, Test_accuracy: 73.53
Epoch [6], Loss: 0.014588635778725148, Accuracy: 83.41 Test_loss: 0.025593858751654625, Test_accuracy: 73.94
Epoch [7], Loss: 0.01255791916936636, Accuracy: 85.94 Test_loss: 0.026889967443048952, Test_accuracy: 73.69
Finished Training
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓