1 .Thread如何划分为Warp? https://jielahou.com/code/cuda/thread-to-warp.html
Thread Index和Thread ID之间有什么关系呢?(线程架构参考这里:CUDA C++ Programming Guide (nvidia.com)open in new window)
-
1维的Thread Index,其Thread ID就是Thread Index
-
2维的Thread Index,其Thread ID为
tx + ty * DX -
3维的Thread Index,其Thread ID为
tx + ty * DX + tz * DX * DY
由此再回到本文的问题:Thread如何划分为Warp?
- 对于1维的Thread Index,直接32个为一组划分(e.g.
0~31、32~63、64~95...) - 对于2维的Thread Index,先按照x分,然后再按照y分(e.g. 假设Thread Block大小为[dx]16*[dy]32,那么
(0,0),(1,0)...(14,0),(15,0),(0,1),(1,1)...(14,1),(15,1)是一个warp内的) - 对于3维的Thread Index,先按照x分,然后再按照y分,最后按照z分(例子略)
2. CUDA ---- 线程配置
前言
线程的组织形式对程序的性能影响是至关重要的,本篇博文主要以下面一种情况来介绍线程组织形式:
- 2D grid 2D block
线程索引
矩阵在memory中是row-major线性存储的:

在kernel里,线程的唯一索引非常有用,为了确定一个线程的索引,我们以2D为例:
- 线程和block索引
- 矩阵中元素坐标
- 线性global memory 的偏移
首先可以将thread和block索引映射到矩阵坐标:
ix = threadIdx.x + blockIdx.x * blockDim.x
iy = threadIdx.y + blockIdx.y * blockDim.y
之后可以利用上述变量计算线性地址:
idx = iy * nx + ix
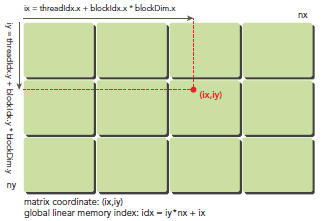
上图展示了block和thread索引,矩阵坐标以及线性地址之间的关系,谨记,相邻的thread拥有连续的threadIdx.x,也就是索引为(0,0)(1,0)(2,0)(3,0)...的thread连续,而不是(0,0)(0,1)(0,2)(0,3)...连续,跟我们线代里玩矩阵的时候不一样。
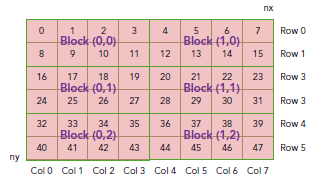
现在可以验证出下面的关系:
thread_id(2,1)block_id(1,0) coordinate(6,1) global index 14 ival 14
下图显示了三者之间的关系:
3、CUDA编程:深入理解GPU中的并行机制(八) - 知乎 (zhihu.com)
4、CUDA ---- Warp解析 - 苹果妖 - 博客园 (cnblogs.com)
Warp Divergence
控制流语句普遍存在于各种编程语言中,GPU支持传统的,C-style,显式控制流结构,例如if…else,for,while等等。
CPU有复杂的硬件设计可以很好的做分支预测,即预测应用程序会走哪个path。如果预测正确,那么CPU只会有很小的消耗。和CPU对比来说,GPU就没那么复杂的分支预测了(CPU和GPU这方面的差异的原因不是我们关心的,了解就好,我们关心的是由这差异引起的问题)。
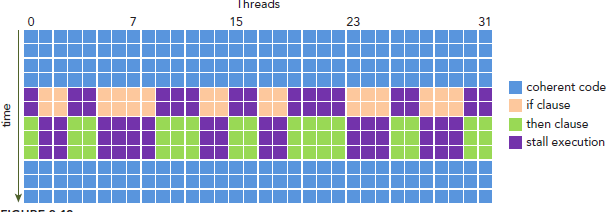
这样我们的问题就来了,因为所有同一个warp中的thread必须执行相同的指令,那么如果这些线程在遇到控制流语句时,如果进入不同的分支,那么同一时刻除了正在执行的分之外,其余分支都被阻塞了,十分影响性能。这类问题就是warp divergence。
请注意,warp divergence问题只会发生在同一个warp中。
下图展示了warp divergence问题:
Latency Hiding
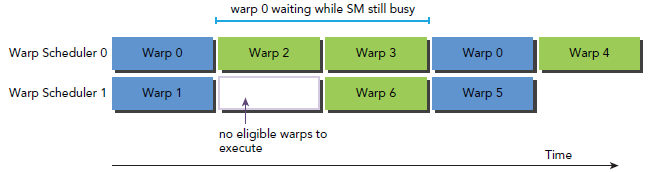
指令从开始到结束消耗的clock cycle称为指令的latency。当每个cycle都有eligible warp被调度时,计算资源就会得到充分利用,基于此,我们就可以将每个指令的latency隐藏于issue其它warp的指令的过程中。
和CPU编程相比,latency hiding对GPU非常重要。CPU cores被设计成可以最小化一到两个thread的latency,但是GPU的thread数目可不是一个两个那么简单。
当涉及到指令latency时,指令可以被区分为下面两种:
- Arithmetic instruction
- Memory instruction
顾名思义,Arithmetic instruction latency是一个算数操作的始末间隔。另一个则是指load或store的始末间隔。二者的latency大约为:
- 10-20 cycle for arithmetic operations
- 400-800 cycles for global memory accesses
下图是一个简单的执行流程,当warp0阻塞时,执行其他的warp,当warp变为eligible时从新执行。
你可能想要知道怎样评估active warps 的数量来hide latency。Little’s Law可以提供一个合理的估计:
![]()
对于Arithmetic operations来说,并行性可以表达为用来hide Arithmetic latency的操作的数目。下表显示了Fermi和Kepler相关数据,这里是以(a + b * c)作为操作的例子。不同的算数指令,throughput(吞吐)也是不同的。
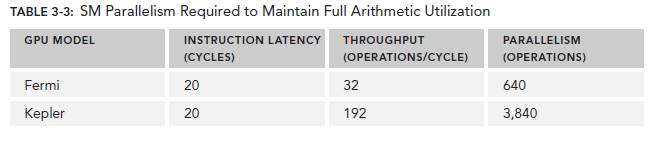
这里的throughput定义为每个SM每个cycle的操作数目。由于每个warp执行同一种指令,因此每个warp对应32个操作。所以,对于Fermi来说,每个SM需要640/32=20个warp来保持计算资源的充分利用。这也就意味着,arithmetic operations的并行性可以表达为操作的数目或者warp的数目。二者的关系也对应了两种方式来增加并行性:
- Instruction-level Parallelism(ILP):同一个thread中更多的独立指令
- Thread-level Parallelism (TLP):更多并发的eligible threads
对于Memory operations,并行性可以表达为每个cycle的byte数目。
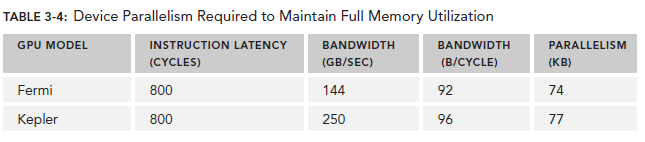
因为memory throughput总是以GB/Sec为单位,我们需要先作相应的转化。可以通过下面的指令来查看device的memory frequency:
$ nvidia-smi -a -q -d CLOCK | fgrep -A 3 "Max Clocks" | fgrep "Memory"
以Fermi为例,其memory frequency可能是1.566GHz,Kepler的是1.6GHz。那么转化过程为:
![]()
乘上这个92可以得到上图中的74,这里的数字是针对整个device的,而不是每个SM。
有了这些数据,我们可以做一些计算了,以Fermi为例,假设每个thread的任务是将一个float(4 bytes)类型的数据从global memory移至SM用来计算,你应该需要大约18500个thread,也就是579个warp来隐藏所有的memory latency。

Fermi有16个SM,所以每个SM需要579/16=36个warp来隐藏memory latency。
Occupancy
当一个warp阻塞了,SM会执行另一个eligible warp。理想情况是,每时每刻到保证cores被占用。Occupancy就是每个SM的active warp占最大warp数目的比例:
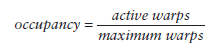
我们可以使用的device篇提到的方法来获取warp最大数目:
cudaError_t cudaGetDeviceProperties(struct cudaDeviceProp *prop, int device);
然后用maxThreadsPerMultiProcessor来获取具体数值。
grid和block的配置准则:
- 保证block中thrad数目是32的倍数。
- 避免block太小:每个blcok最少128或256个thread。
- 根据kernel需要的资源调整block。
- 保证block的数目远大于SM的数目。
- 多做实验来挖掘出最好的配置。
Occupancy专注于每个SM中可以并行的thread或者warp的数目。不管怎样,Occupancy不是唯一的性能指标,Occupancy达到当某个值是,再做优化就可能不在有效果了,还有许多其它的指标需要调节,我们会在之后的博文继续探讨。
Synchronize
同步是并行编程的一个普遍的问题。在CUDA的世界里,有两种方式实现同步:
- System-level:等待所有host和device的工作完成
- Block-level:等待device中block的所有thread执行到某个点
因为CUDA API和host代码是异步的,cudaDeviceSynchronize可以用来停住CUP等待CUDA中的操作完成:
cudaError_t cudaDeviceSynchronize(void);
因为block中的thread执行顺序不定,CUDA提供了一个function来同步block中的thread。
__device__ void __syncthreads(void);
当该函数被调用,block中的每个thread都会等待所有其他thread执行到某个点来实现同步。











![数据结构(2):LinkedList和链表[1]](https://i-blog.csdnimg.cn/direct/71bbe4f8f67c4e4f9074042b06980948.png)







