《博主简介》
小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。
👍感谢小伙伴们点赞、关注!
《------往期经典推荐------》
一、AI应用软件开发实战专栏【链接】
| 项目名称 | 项目名称 |
|---|---|
| 1.【人脸识别与管理系统开发】 | 2.【车牌识别与自动收费管理系统开发】 |
| 3.【手势识别系统开发】 | 4.【人脸面部活体检测系统开发】 |
| 5.【图片风格快速迁移软件开发】 | 6.【人脸表表情识别系统】 |
| 7.【YOLOv8多目标识别与自动标注软件开发】 | 8.【基于YOLOv8深度学习的行人跌倒检测系统】 |
| 9.【基于YOLOv8深度学习的PCB板缺陷检测系统】 | 10.【基于YOLOv8深度学习的生活垃圾分类目标检测系统】 |
| 11.【基于YOLOv8深度学习的安全帽目标检测系统】 | 12.【基于YOLOv8深度学习的120种犬类检测与识别系统】 |
| 13.【基于YOLOv8深度学习的路面坑洞检测系统】 | 14.【基于YOLOv8深度学习的火焰烟雾检测系统】 |
| 15.【基于YOLOv8深度学习的钢材表面缺陷检测系统】 | 16.【基于YOLOv8深度学习的舰船目标分类检测系统】 |
| 17.【基于YOLOv8深度学习的西红柿成熟度检测系统】 | 18.【基于YOLOv8深度学习的血细胞检测与计数系统】 |
| 19.【基于YOLOv8深度学习的吸烟/抽烟行为检测系统】 | 20.【基于YOLOv8深度学习的水稻害虫检测与识别系统】 |
| 21.【基于YOLOv8深度学习的高精度车辆行人检测与计数系统】 | 22.【基于YOLOv8深度学习的路面标志线检测与识别系统】 |
| 23.【基于YOLOv8深度学习的智能小麦害虫检测识别系统】 | 24.【基于YOLOv8深度学习的智能玉米害虫检测识别系统】 |
| 25.【基于YOLOv8深度学习的200种鸟类智能检测与识别系统】 | 26.【基于YOLOv8深度学习的45种交通标志智能检测与识别系统】 |
| 27.【基于YOLOv8深度学习的人脸面部表情识别系统】 | 28.【基于YOLOv8深度学习的苹果叶片病害智能诊断系统】 |
| 29.【基于YOLOv8深度学习的智能肺炎诊断系统】 | 30.【基于YOLOv8深度学习的葡萄簇目标检测系统】 |
| 31.【基于YOLOv8深度学习的100种中草药智能识别系统】 | 32.【基于YOLOv8深度学习的102种花卉智能识别系统】 |
| 33.【基于YOLOv8深度学习的100种蝴蝶智能识别系统】 | 34.【基于YOLOv8深度学习的水稻叶片病害智能诊断系统】 |
| 35.【基于YOLOv8与ByteTrack的车辆行人多目标检测与追踪系统】 | 36.【基于YOLOv8深度学习的智能草莓病害检测与分割系统】 |
| 37.【基于YOLOv8深度学习的复杂场景下船舶目标检测系统】 | 38.【基于YOLOv8深度学习的农作物幼苗与杂草检测系统】 |
| 39.【基于YOLOv8深度学习的智能道路裂缝检测与分析系统】 | 40.【基于YOLOv8深度学习的葡萄病害智能诊断与防治系统】 |
| 41.【基于YOLOv8深度学习的遥感地理空间物体检测系统】 | 42.【基于YOLOv8深度学习的无人机视角地面物体检测系统】 |
| 43.【基于YOLOv8深度学习的木薯病害智能诊断与防治系统】 | 44.【基于YOLOv8深度学习的野外火焰烟雾检测系统】 |
| 45.【基于YOLOv8深度学习的脑肿瘤智能检测系统】 | 46.【基于YOLOv8深度学习的玉米叶片病害智能诊断与防治系统】 |
| 47.【基于YOLOv8深度学习的橙子病害智能诊断与防治系统】 | 48.【车辆检测追踪与流量计数系统】 |
| 49.【行人检测追踪与双向流量计数系统】 | 50.【基于YOLOv8深度学习的反光衣检测与预警系统】 |
| 51.【危险区域人员闯入检测与报警系统】 | 52.【高密度人脸智能检测与统计系统】 |
| 53.【CT扫描图像肾结石智能检测系统】 | 54.【水果智能检测系统】 |
| 55.【水果质量好坏智能检测系统】 | 56.【蔬菜目标检测与识别系统】 |
| 57.【非机动车驾驶员头盔检测系统】 | 58.【太阳能电池板检测与分析系统】 |
| 59.【工业螺栓螺母检测】 | 60.【金属焊缝缺陷检测系统】 |
| 61.【链条缺陷检测与识别系统】 | 62.【交通信号灯检测识别】 |
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
目录
- 引言
- 1. 机器学习与一般编程有何不同?
- 2. 聚类算法在实际生活中有哪些应用?
- 3. 如何选择最佳的聚类数?
- 4.什么是特征工程?它如何影响模型的性能?
- 5.机器学习中的假设是什么?
- 6. 如何衡量集群的有效性?
- 7.为什么我们要取较小的学习率值?
- 8.机器学习中的过度拟合是什么以及如何避免它?
- 9. 为什么我们不能使用线性回归进行分类任务?
- 10.为什么要进行归一化?
- 11. 准确率和召回率有什么区别?
- 12. 上采样和下采样有什么区别?
- 13. 什么是数据泄露?如何识别?
- 14. 解释分类报告及其所包含的指标。
- 15. 随机森林回归器的哪些超参数有助于避免过度拟合?
- 16. 偏差-方差权衡是什么?
- 17. 训练测试划分是否总是需要使用 8:2 的比例?
- 18.什么是主成分分析?
- 19.什么是单次学习(one-shot)?
- 20.曼哈顿距离和欧几里得距离有什么区别?
- 21. 协方差和相关性有什么区别?
- 22. 独热编码和序数编码有什么区别?
- 23.如何判断模型是否过度拟合训练数据?
- 24. 如何使用混淆矩阵得出有关模型性能的结论?
- 25. 箱线图代表哪五个统计指标?
- 26.随机梯度下降(SGD)和梯度下降(GD)有什么区别?
引言
在求职的道路上,面试无疑是应届毕业生必须面对的重要关卡。尤其在机器学习这一热门领域,掌握面试中的关键问题,对于成功踏入职场至关重要。
本文精心整理了一系列针对应届毕业生的机器学习面试问题,涵盖了机器学习的基本概念、算法应用、模型评估等多个方面,旨在帮助广大毕业生巩固知识体系,提升面试成功率。下面,让我们一起探索这些面试问题的答案,为未来的职业生涯打下坚实基础。
1. 机器学习与一般编程有何不同?
在一般编程中,我们有数据和逻辑,利用这两者我们就能得出答案。但在机器学习中,我们有数据和答案,我们让机器从中学习逻辑,这样同样的逻辑就可以用来回答未来将面临的问题。
此外,有时无法在代码中写入逻辑,因此,机器学习就成为救星并学习逻辑本身。
2. 聚类算法在实际生活中有哪些应用?
聚类技术可用于数据科学的多个领域,如图像分类、客户细分和推荐引擎。
最常见的用途之一是市场研究和客户细分,然后利用这些细分来瞄准特定的市场群体,以扩大业务和盈利成果。
3. 如何选择最佳的聚类数?
通过使用 Elbow 方法,我们可以确定聚类算法必须尝试形成的最佳聚类数。此方法背后的主要原理是,如果我们增加聚类数,错误值就会减少。
但是在达到最佳特征数量之后,误差值的减少就变得微不足道了,因此,在这种情况开始发生之后,我们选择该点作为算法将尝试形成的最佳聚类数量。
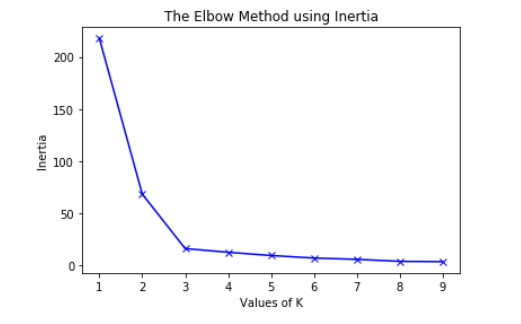
肘部方法
从上图可知,最佳聚类数为 3。
4.什么是特征工程?它如何影响模型的性能?
特征工程是指利用现有特征开发一些新特征。有时某些特征之间存在非常微妙的数学关系,如果正确探索,则可以使用这些数学运算开发新特征。
此外,有时我们会将多条信息汇总起来,作为单个数据列提供。在那些时候,开发新特征并使用它们有助于我们更深入地了解数据,并且如果得出的特征足够重要,则有助于大大提高模型的性能。
5.机器学习中的假设是什么?
假设是监督机器学习领域中常用的术语。由于我们有独立的特征和目标变量,我们试图找到从特征空间到目标变量的近似函数映射,这种映射的近似称为假设。
6. 如何衡量集群的有效性?
有惯性或平方误差和 (SSE)、Silhouette 分数、l1 和 l2 分数等指标。在所有这些指标中,惯性或平方误差和 (SSE) 和 Silhouette 分数是衡量集群有效性的常用指标。
虽然这种方法在计算成本方面相当昂贵,但如果形成的簇密集且分离良好,则得分较高。
7.为什么我们要取较小的学习率值?
学习率越小,训练过程越缓慢、逐渐地收敛到全局最优值,而不是在全局最优值附近波动。这是因为学习率越小,每次迭代对模型权重的更新就越小,这有助于确保更新更精确、更稳定。
如果学习率太大,模型权重可能会更新得太快,这可能会导致训练过程超出全局最优值并完全偏离目标。
因此,为了避免误差值的振荡并实现模型的最佳权重,有必要使用较小的学习率值。
8.机器学习中的过度拟合是什么以及如何避免它?
当模型学习模式以及数据中存在的噪声时,就会发生过度拟合,这会导致训练数据的性能很高,但对于模型之前从未见过的数据,性能却很低。为了避免过度拟合,我们可以使用多种方法:
- 如果验证训练停止增加但训练仍在继续,则提前停止模型的训练。
- 使用正则化方法(例如 L1 或 L2 正则化)来惩罚模型的权重,以避免过度拟合。
9. 为什么我们不能使用线性回归进行分类任务?
我们不能将线性回归用于分类任务的主要原因是线性回归的输出是连续且无界的,而分类需要离散且有界的输出值。
如果我们使用线性回归进行分类任务,误差函数图将不会是凸的。凸图只有一个最小值,也称为全局最小值,但在非凸图的情况下,我们的模型有可能卡在某些局部最小值上,而这些局部最小值可能不是全局最小值。为了避免这种卡在局部最小值的情况,我们不使用线性回归算法进行分类任务。
10.为什么要进行归一化?
为了实现模型的稳定和快速训练,我们使用规范化技术将所有特征归一化到一定的比例或值范围内。如果我们不进行规范化,那么梯度就有可能不会收敛到全局或局部最小值,最终会来回震荡。
11. 准确率和召回率有什么区别?
准确率就是模型预测的正例 (TP) 与所有正例 (TP+FP) 的比例。换句话说,准确率衡量预测的正例中有多少是真正的正例。它衡量了模型避免假阳性和做出准确阳性预测的能力。

但在召回率的情况下,我们计算的是真实正例 (TP) 与实际属于正类的样本总数 (TP+FN) 的比例。召回率衡量模型正确识别的实际正例中有多少。它是衡量模型避免假阴性并正确识别所有正例的能力的指标。

12. 上采样和下采样有什么区别?
在上采样方法中,我们通过从少数类中随机选择一些点并将其添加到数据集中来增加少数类中的样本数量,重复此过程直到每个类的数据集达到平衡。但这里有一个缺点,训练准确率会变得很高,因为在每个时期模型中训练不止一次,但在验证准确率中却没有观察到同样高的准确率。
在下采样的情况下,我们通过选择与少数类中数据点数量相等的随机点数来减少多数类中的样本数量,以使分布变得平衡。在这种情况下,我们不得不遭受数据丢失,这也可能导致一些关键信息的丢失。
13. 什么是数据泄露?如何识别?
如果目标变量和输入特征之间存在高度相关性,则这种情况称为数据泄漏。这是因为当我们使用该高度相关的特征训练模型时,模型仅在训练过程中就获得了大部分目标变量的信息,并且只需做很少的工作即可实现高精度。在这种情况下,模型在训练和验证数据上都表现得相当不错,但是当我们使用该模型进行实际预测时,模型的性能就达不到标准。这就是我们识别数据泄漏的方法。
14. 解释分类报告及其所包含的指标。
分类报告使用具有每个类别的精确度、召回率和 f1 分数的分类指标进行评估。
- 准确率可以定义为分类器不将实际上为负的实例标记为正的能力。
- 召回率是分类器找到所有正值的能力。对于每个类别,召回率定义为真阳性与真阳性和假阴性之和的比率。
- F1 分数是精确度和召回率的调和平均值。
- 支持度是每个类别使用的样本数量。
- 模型的总体准确度得分也可以作为对性能的高级评估。它是正确预测总数与数据集总数之间的比率。
- 宏平均值不过是每个类别的度量(精确度、召回率、f1 分数)值的平均值。
- 加权平均值是通过为数据集中数量较多的类别提供更高的优先级来计算的。
15. 随机森林回归器的哪些超参数有助于避免过度拟合?
随机森林最重要的超参数是:
- *max_depth* – 有时树的深度越大,越容易造成过度拟合。为了克服这个问题,应该限制深度。
- ****n-estimator——****这是我们想要在森林中出现的决策树的数量。
- *min_sample_split* – 这是内部节点为了分裂成更多节点必须持有的最小样本数。
- *max_leaf_nodes* – 它帮助模型控制节点的分裂,反过来,模型的深度也受到限制。
16. 偏差-方差权衡是什么?
首先,让我们了解什么是偏差和方差:
- ****偏差****是指实际值与模型预测值之间的差异。低偏差意味着模型已经学习了数据中的模式,而高偏差意味着模型无法学习数据中存在的模式,即欠拟合。
- ****方差****是指模型在未经训练的情况下预测准确度的变化。方差低是良好情况,方差高意味着训练数据和验证数据的性能差异很大。
如果偏差太低但方差太高,这种情况就称为过度拟合。因此,在这两种情况之间找到平衡点就称为偏差-方差权衡。
17. 训练测试划分是否总是需要使用 8:2 的比例?
不,没有这样的必要条件,即数据必须按 8:2 的比例分割。分割的主要目的是获得一些模型以前没有见过的数据,以便我们评估模型的性能。
如果数据集包含 50,000 行数据,那么仅 1000 行或 2000 行数据就足以评估模型的性能。
18.什么是主成分分析?
PCA(主成分分析)是一种无监督机器学习降维技术,我们以大幅减少数据大小为代价来牺牲一些数据信息或模式。在此算法中,我们尝试将原始数据集的方差保留到最高水平,比如说 95%。对于非常高维的数据,有时即使方差损失 1%,我们也可以显著减少数据大小。
通过使用该算法,我们可以进行图像压缩,可视化高维数据以及使数据可视化变得简单。
19.什么是单次学习(one-shot)?
单次学习是机器学习中的一个概念,其中模型被训练为从单个示例中识别数据集中的模式,而不是在大型数据集上进行训练。当我们没有大型数据集时,这很有用。它用于查找两幅图像之间的相似性和差异性。
20.曼哈顿距离和欧几里得距离有什么区别?
曼哈顿距离和欧几里得距离都是两种距离测量技术。
曼哈顿距离 (MD) 计算为每个维度上两个点的坐标之间的绝对差的总和。

欧几里得距离 (ED) 计算为每个维度上两个点的坐标之间的平方差和的平方根。

一般用这两个指标来评价一个聚类算法所形成的聚类的有效性。
21. 协方差和相关性有什么区别?
顾名思义,协方差为我们提供了两个变量之间差异程度的度量。但另一方面,相关性为我们提供了两个变量之间相关程度的度量。协方差可以取任意值,而相关性始终介于 -1 和 1 之间。这些度量在探索性数据分析过程中用于从数据中获取见解。
22. 独热编码和序数编码有什么区别?
独热编码和序数编码都是将分类特征转换为数字特征的不同方法,区别在于实现方式。
在独热编码中,我们为每个类别创建一个单独的列,并根据该行对应的值添加 0 或 1。与独热编码相反,在序数编码中,我们根据顺序或等级用 0 到 n-1 的数字替换类别,其中 n 是数据集中存在的唯一类别的数量。
独热编码和序数编码之间的主要区别在于,独热编码以 0 和 1 的形式产生数据的二进制矩阵表示,它用于数据集之间没有顺序或等级的情况,而序数编码将类别表示为序数值。
23.如何判断模型是否过度拟合训练数据?
如果模型在训练数据上的表现与在验证数据上的表现相比非常高,那么我们可以说该模型通过学习数据集中存在的模式和噪声而过度拟合了训练数据。
24. 如何使用混淆矩阵得出有关模型性能的结论?
混淆矩阵总结了分类模型的性能。在混淆矩阵中,我们得到四种类型的输出(在二元分类问题的情况下),即 TP、TN、FP 和 FN。我们知道正方形中可能存在两条对角线,其中一条对角线代表我们的模型预测和真实标签相同的数字。我们的目标也是最大化这些对角线上的值。从混淆矩阵中,我们可以计算出各种评估指标,如准确率、精确率、召回率、F1 分数等。
25. 箱线图代表哪五个统计指标?

箱线图及其统计量表
- min——该统计测量值是通过从 Q1 中减去 1.5 倍 IQR(四分位距)计算得出的。
- IQR = Q3-Q1
- min = Q1-1.5*IQR
- Q1 — 这也称为 25 百分位数。
- Q2——这是数据的中位数或 50 百分位数。
- Q3 – 也称为 75 百分位数
- max——该统计指标是通过在 Q3 中添加 1.5 倍 IQR(四分位距)计算得出的。
- max = Q3 + 1.5*IQR
26.随机梯度下降(SGD)和梯度下降(GD)有什么区别?
在梯度下降算法中,一次性在整个数据集上训练我们的模型。但在随机梯度下降中,模型是一次性使用一小批训练数据进行训练的。如果我们使用 SGD,那么就不能指望训练误差平稳下降。训练误差会震荡,但经过一些训练步骤后,我们可以说训练误差已经下降了。此外,使用GD实现的最小值可能与使用 SGD 实现的最小值不同。据观察,使用 SGD 实现的最小值接近 GD,但并不相同。
关注文末名片G-Z-H:【阿旭算法与机器学习】,发送【开源】可获取更多学习资源

好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!