1、变量间关系的度量
函数关系
(1)是一一对应的确定关系;
(2)设有两个变量x和y,变量y随x一起变化,并完全依赖于x,当x取某个数值时,y根据确定的关系取相应的值,称y是x的函数,记为,其中x称为自变量,y称为因变量;
(3)各观测点落在一条线上。

(4)函数关系的例子
- 某种商品的销售额y和销售量x之间的关系可以表示为
(p为单价);
- 圆的面积S与半径之间的关系可以表示为
;
- 企业的原材料消耗额y与产量
、单位产量消耗
、原材料价格
之间的关系可表示为:
相关关系
(1)变量的关系不能用函数关系精确表达;
(2)一个变量的取值不能由另一个变量唯一确定;
(3)当变量x取某个值时,变量y的取值可能有几个;
(4)各观察点分布在直线周围。

(5)线性相关的例子:
- 子女身高y与父母身高x之间的关系;
- 收入水平y与受教育程度x之间的关系;
- 粮食亩产量y与施肥量
- 商品消费量y与居民收入x之间的关系;
- 商品的销售额y与广告费支出x之间的关系。

例1:一家大型商业银行在多个地区有分行,其业务主要是进行基础设施建设、国家重点项目建设、固定投资等项目的贷款。近年来,该银行的贷款额平稳增长,但不良贷款额也有较大比例提高,这给银行业务的发展带来较大的压力。为弄清不良贷款形成的原因,管理者希望利用银行业务的相关数据做些定量分析,以便找出控制不良贷款的方法。如下就是该银行所属的25家分行的相关业务数据。


从各散点图可以看出,不良贷款与贷款余额、累计应收贷款、贷款项目个数、固定资产投资额之间都具有一定的相关关系。
从各散点的分布情况看,不良贷款与贷款余额的相关关系比较密切,与固定资产投资额之间的关 系最不密切。
相关系数
(1)对变量之间关系密切程度的度量;
(2)对两个变量之间线性关系相关程度的度量称为简单相关系数;
(3)若相关系数是根据总体全部数据计算的,称为总体相关系数,记作;
(4)若是根据样本数据计算的,则称为样本相关系数,记为r

(5)取值以及其意义
r的取值范围[-1,1] ,为负相关
|r| = 1,为完全相关 ,为正相关

在上述案例中,不良贷款、贷款余额、累计应收贷款,贷款项目个数,固定资产投资额的相关系数为:
解:用excel【数据分析】中的【相关系数】工具计算的相关矩阵如下:

可以看出不良贷款与其他几个变量的关系中,与贷款余额的相关系数最大,而与固定资产投资额的相关系数最小。
相关系数的显著性水平检验
能否根据样本相关系数说明总体的相关程度呢?需要考察样本的可靠性,需要进行显著性检验。
r的抽样分布
1、r的抽样分布随总体相关系数和样本容量的大小而变化
当样本数据来自正态总体时,随着n的增大,r的抽样分布趋于正态分布,尤其是在总体相关系数ρ很小或接近0时,区域正态分布的趋势非常明显。当ρ远离0时,除非n非常大,否则r的抽样分布呈现一定的偏态。
2、当为较大的正值时,r呈现左偏分布;当为较小的负值,r呈现右偏分布。只有当接近于0,而样本容量很大时,才能认为r是接近于正态分布的随机变量。
检验的步骤
1、检验两个变量之间是否存在线性相关关系;
2、采用费尔希提出的t检验,可以用于大样本,也可以用于小样本;
3、检验的步骤为
第一步:提出假设
第二步:计算p值
第三步:确定显著性水平α,并做出决策
若,表明总体的两个变量之间存在显著的线性关系
若,不能拒绝原假设H0
对之前案例中的不良贷款与贷款余额之间的相关系数进行显著性检验()
解:第一步:提出假设
第二步:计算检验的统计量
第三步:做出决策
根据显著性水平,查t分布表得
由于,拒绝H0,不良贷款与贷款余额之间存在显著性的正线性相关关系。
2、一元线性回归
回归分析,对于因变量Y,根据自变量X结合统计学模型(数学公式),预测出因变量Y。
(1)回归分析和相关性分析的区别
1、回归分析中,变量x和变量y处于平等的地位;回归分析中,y称为因变量,处于被解释的位置,x是自变量,用于预测因变量的变化。
2、相关分析中所涉及的变量x和y都是随机变量;回归分析中,因变量y是随机变量,自变量x可以是随机变量,也可以是非随机变量的确定变量。
3、相关性分析主要是描述两个变量之间线性关系的密切程度;回归分析不仅可以揭示自变量x对因变量y的影响大小,还可以由回归方程进行预测。
(2)一元线性回归模型
1、描述因变量y依赖自变量x和误差项的方程称为回归模型。
2、一元线性回归模型可以表示为:
其中y是x的线性部分加上误差项,线性部分反映x的变化而引起y的变化,误差项反映的是除了线性关系之外的因素对y的影响,不能由x和y之间的线性关系揭示的变异性,称为模型参数。
(3)基本假定
误差项是一个期望值为0的随机变量,对于一个给定的x,y的期望值为
;
对于所有的x值,的方差
都相同;
误差项是一个服从正态分布的随机变量,且相互独立。即
;
独立性意味着对一个特定的x值,它所对应的与其他x对应的
不相关;
对于一个特定的X值,它所对应的Y值与其他X所对应的Y值也不相关。

从上图可以看出,y的值随着x的不同而变化,但不论x怎么变化,和y的概率分布是正态分布,并且具有相同的方差。
(4)回归方程
1、描述y的平均值或期望值如何依赖于x的方程称为回归方程;
2、一元线性回归方程的形式如下:
方程的图示是一条直线,也称为直线回归方程
是回归直线在y轴上的截距,是当x=0时y的期望值
是直线的斜率,称为回归系数,表示当x每变动一个单位时,y的平均变动值。
参数的最小二乘估计
作用是估计回归方程中的值。
1、使因变量的观察值与估计值之间的离差平方和达到最小来求的方法。即
最小
2、用最小二乘法拟合的直线来代表x和y之间的关系与实际数据的误差比其他任何直线都小。

根据最小二乘法的要求,可以求解的公式如下:

上述案例中不良贷款与各项贷款余额之间的回归方程




3、利用回归方程进行估计和预测
变差
1、因变量y的取值是不同的,y取值的这种波动性称为变差。变差来源于两个方面:
由于自变量x的取值不同造成的
除了x以为的其他因素(x对y的非线性影响,测量误差等)的影响。
2、对一个具体的观测值来说,变差的大小可以通过该实际观测值与其均值之差表示

误差平方和的分解
1、总平方和(SST):反映因变量n个值观察值与其均值的总误差;
2、回归平方和(SSR):反映自变量X的变化对因变量Y取值变化的影响,即由于x和y之间的线性关系引起的取值变化,也成为可解释的平方和;
3、残差平方和:反映除X以为的其他因素对Y取值的影响,也成为不可解释的平方和或剩余平方和。

判定系数R方
1、回归平方和占总方差平方和的比例

2、反映回归直线的拟合程度;
3、取值范围在[0,1]之间;
4、说明回归方程拟合的越好;
说明回归方程拟合的越差;
5、判定系数等于相关系数的平方,即。
计算上述案例中不良贷款对单款余额回归的判定系数,并解释其意义。

判定系数的实际意义是:在不良贷款取值的变差中,有71.16%可以由不良贷款与贷款余额之间的线性关系来解释,或者说,在不良贷款的取值的变动中,有71.16%是由贷款余额所决定的。也就是说,不良贷款取值的差异2/3以上是由贷款余额决定的。可见不良贷款与贷款余额之间有较强的线性相关性。
估计标准误差
1、实际观察值与回归估计值离差平方和的均方根;
2、反映实际观察值在回归直线周围的分散状况;
3、对误差项的标准差
的估计,是在排除x对y的线性影响后,y随机波动大小的一个估计量;
4、反映用估计的回归方程预测y时预测误差的大小;
5、计算公式为

根据上述案例的计算结果,计算不良贷款对余额回归的估计标准误差,并解释其意义

实际上,Excel计算表中直接给出了该值,即标准误差为1.979948,根据贷款余额来估计不良贷款时,平均的估计误差为1.979948亿元。
显著性检验
回归分析的主要目的是根据所建立的估计方程,用自变量x来预测因变量y的取值。
建立估计方程后,不能立马使用其去预测,因为该估计方程是通过样本数据得出的方程,是否置信需要通过验证来证实。
回归分析中的显著性检验主要包含两个方面内容:一是线性关系的检验;二是回归系数的检验。
概念
1、检验自变量与因变量之间的线性关系是否显著;
2、将回归均方(MSR)同残差均方(MSE)加以比较,用用F检验来分析二者之间的差别是否显著:
- 回归均方MSR:回归均方和SSR除以相应的自由度(SSR的自由度是自变量的个数k,一元线性回归中自由度为1)
- 残差均方MSE:残差平方和SSE除以相应的自由度(SSE的自由度n-k-1,一元线性回归中自由度为n-2)
线性关系的检验
1.提出假设:两个变量之间的线性关系不显著;
2.计算检验统计量
3.作出决策:确定显著性水平,并根据分子自由度1和分母自由度n-2找出临界值
,若
拒绝
;若
不拒绝
。

回归系数检验
概念
1.检验x和y之间是否具有线性关系,或者说,检验自变量x对因变量y的影响是否显著;
2.理论基础是回归系数的抽样分布;
3.在一元线性回归中,等价于线性关系的显著性检验。
样本统计量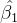 的分布
的分布
1.是分局最小二乘法求出的样本统计量,它有自己的分布;
2.分布具有如下性质:
- 分布形式:正态分布
- 数学期望:

检验步骤
1、提出假设
没有线性关系
有线性关系
2、计算检验的统计量
3、确定显著性水平,进行决策


在实际应用中,可以直接利用Excel输出的参数估计表进行检验。表中给出了用于检验的P值(P-value)。检验时可以直接将P- value与给定的显著性水平。进行比较。在本例中,P-value=0.000<0.05,所以拒绝
。
利用回归方程进行估计和预测
概念
1.根据自变量X的取值估计或预测因变量Y的取值;
2.估计和预测的类型;
- 点估计
- Y平均值的点估计
- Y个别值的点估计
- 区间估计
- Y平均值的区间估计
- Y的个别值的区间估计
点估计
1.对于自变量X的一个给定值,根据回归方程得到因变量y的一个估计值
;
2.点估计值:平均值和个别值的点估计;
3.在点估计条件下,平均值的点估计和个别值的点估计是一样的,在区间估计中则不同。
Y的平均值的点估计
利用估计的回归方程,对于自变量x的一个给定值,求出因变量y的平均值的一个估计值
,就是平均值的点估计。
在前面的例子中,假如我们要估计贷款余额为100亿时,所有分行不良贷款的平均值,就是平均值的点估计。根据估计的回归方程得
![]()
区间估计
概念
1、利用估计的回归方程,对于自变量x的一个给定,求出因变量y的一个个别值的估计区间,这一区间成为预测区间。
2、在
置信水平下的预测区间为


影响区间宽度的因素
1.置信水平():区间宽度随置信水平的增大而增大;
2.数据的离散程度S:区间宽度随离散程度的增大而增大;
3.样本容量:区间宽度样本容量的增大而减小;
4.用于预测的与
的差异程度:差异程度越大区间宽度越大

4、残差分析
残差与残差图
在回归模型中,假定
是期望为0,方差相等且服从正态分布的一个随机变量。如果关于
的假定不成立,那么所做的检验以及估计和预测也许就站不住脚,确定
的假定是否成立的方法之一就是进行残差分析。
残差
变量的观测值与根据估计的回归方程求出的预测值之差,用e表示,反映了用估计的回归方程去预测而引起的误差。
残差图
表示残差的图形,关于x的残差图、关于y的残差图、标准化残差图。


若对所有的x值,残差的方差都相同,而且假定描述变量X和Y之间关系的回归模型是合理的,那么残差图中所有点都应该落在一条水平带中间,如图(a)所示。
对于所有的值,残差是不同的,例如对于较大的X值,相应的残差也较大,如图(b)所示,这就意味着违背了残差方差相等的假设。
如果残差图如c那样,则表明所选择的回归模型不合理,这时应该考虑曲线回归,或多元回归模型。

通过上图可以看出各残差几本位于水平带中间,表明关于不良贷款与贷款余额回归的线性假定以及对误差项残差的假定时成立的。