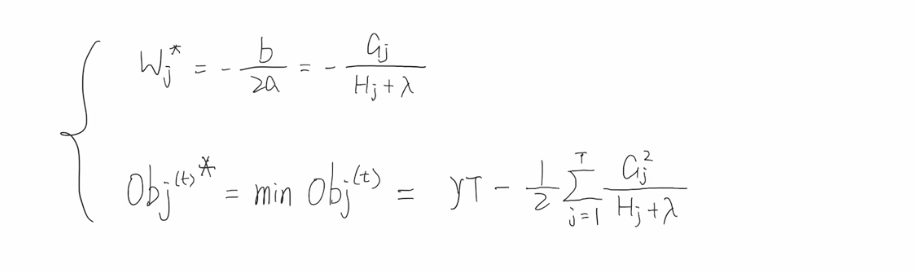论文精读-Supervised Raw Video Denoising with a Benchmark Dataset on Dynamic Scenes
优势
1、构建了一个用于监督原始视频去噪的基准数据集。为了多次捕捉瞬间,我们手动为对象s创建运动。在高ISO模式下捕获每一时刻的噪声帧,并通过对多个噪声帧进行平均得到相应的干净帧。
2、有效的原始视频去噪网络(RViDeNet),通过探索非局部的空间、信道和时间相关性。由于噪声输入具有拜耳模式特征,将其分割为4个独立序列,即RGBG序列,分别经过预去噪、对齐、非局部注意和时间融合模块,然后通过空间融合重建无噪声版本。
3、在RAW域的去噪结果,通过ISP之后得到的RGB域图像也比普通的图像RGB域去噪效果好。 (**有待商榷。**因为原始噪声图就是RAW域的,模型是在RAW域训练的,当然去噪效果后。你将原始噪声图经过ISP后得到的RGB噪声图,然后使用普通的图像RGB域模型去噪,如果之前训练中模型没有考虑到ISP噪声,显然效果不好,这对模型来说是不公平的。如果要对比,也应该是在RAW域的图像去噪模型,然后将各自的去噪图经过ISP得到RGB图,再进行比较)
方法
动机
1、常用的方法通常是为高斯或合成噪声去除而设计的,而没有考虑在低光捕获条件下产生的复杂的真实噪声。即使少数工作涉及视频的逼真噪声去除。然而,他们的训练数据库只包含静态序列,这在探索动态序列的时间相关性方面效率很低。(->构建了一个动态噪声视频数据集,并相应地提出了一个RViDeNet,以充分利用空间、信道和时间相关性。)
常规的视频去噪:先进行空间去噪再进行时间去噪(ViDeNN)、使用静态帧作为训练数据,先将RAW域图像转为RGB域,再执行去噪。
raw域图像去噪:1、存在较好的数据集2、考虑将RGB域图像通过反向ISP还原回RAW域图像,然后再进行去噪
本文将原始数据映射到原始和sRGB输出来训练RViDeNet,即在local本地去噪,然后再通过ISP转为RGB域图像。
噪声数据集构建方式
1、通过平均一个静态场景的多帧来生成无噪声图像,所有图像都由固定设置的静止相机捕获[28,45,38,1]。通过这种方式,干净的图像与有噪声的图像具有相似的亮度。
2、在低/高ISO设置下捕获静态场景,并使用低ISO图像作为噪声高ISO图像的地面真值。例如RENOIR数据集[3],DND数据集[29]和SIDD数据集。它们均以原始格式捕获,并根据某些图像ISP模块合成sRGB图像。
3、Seeing motion in the dark工作在静态场景构建了一个noisy-clean的数据集,其中一个干净的帧对应多个噪声帧。
目前还没有噪声清洁的视频数据集?
因为在不引入模糊伪影的情况下,长时间曝光或多次拍摄的动态场景是不可能捕捉到的。
方法:通过手动为物体创建运动来解决这个问题。
数据集
捕获RAW视频数据
关键问题:在动态场景,如何同时捕捉噪声视频和相应的干净视频?
- 使用低ISO和高曝光时间捕捉干净的动态视频将导致运动模糊。
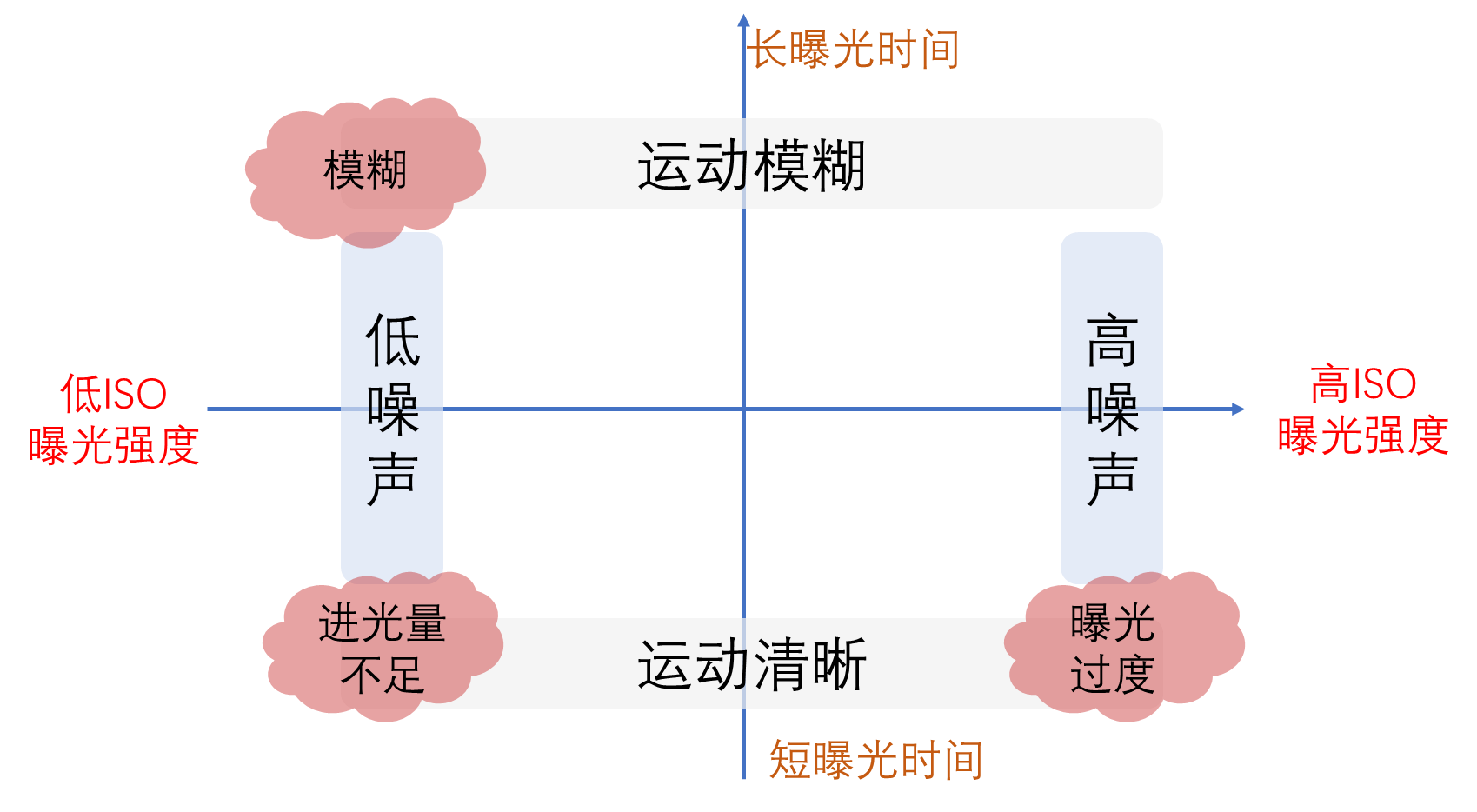
解决:
捕捉可控制的物体,比如玩具,并手动为它们制作动作。
每个动作,我们连续捕捉M个有噪声的帧。M帧的平均是地面真值(GT)无噪声帧。不使用长曝光来捕捉GT无噪帧,因为它会使GT帧和有噪帧具有不同的亮度。
移动对象并再次保持它不动,以捕捉下一个无噪声的配对帧。
最后,我们根据它们的时间顺序将所有的单帧分组在一起,生成有噪声的视频及其对应的干净视频。
在5种不同的ISO感光度(从1600到25600)下共拍摄了11个不同的室内场景。不同的ISO设置用于捕捉不同级别的噪声。对于每个视频,我们捕获了7帧。
在高ISO场景25600,捕获了500帧进行平均,并且使用BM3D应用平均帧。
合成视频数据
将高质量的sRGB数据集MOTChallence,通过unprocessing方法将sRGB转为RAW视频,并通过添加噪声得到RAW视频。
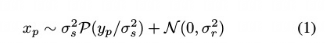
其中x是噪声观测值,yp是像素p处的真实强度。or和os是读取和拍摄噪声的参数,随着传感器增益(ISO)的变化而变化。第一项表示均值yp和方差os^2的泊松分布,第二项表示均值为0和方差为or2的高斯分布。
本文的不同点在于,使用平场帧‘1和偏置帧’2来校准给定相机的噪声参数。
其中平场帧是传感器均匀照射时捕获的图像。具体来说,将相机调到特定的ISO,我们只需要在不同的曝光时间下,在均匀照明的墙壁上拍摄一张白纸的图像。然后,我们根据修正方差计算估计的信号强度,以确定σs偏置帧是在完全黑暗的环境下捕获的图像。由于偏置帧中没有镜头噪
声,我们使用它们来估计σr‘3。
1https://en.wikipedia.org/wiki/Flat-field correction
2https://en.wikipedia.org/wiki/Bias frame
3The technical details can be found in the supplementary material.
模型
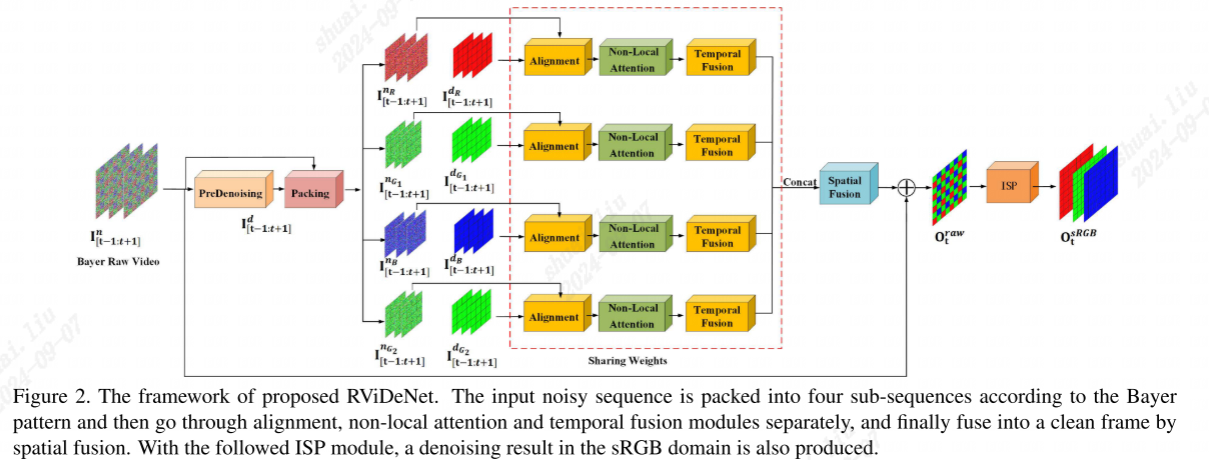
概述:给定一组连续帧(本作品中有三帧),我们的目标是通过探索中间帧内部的空间相关性和相邻帧之间的时间相关性来恢复中间帧。
预去噪和打包
1、预去噪的目的是为了更好的估计密集对应。因为噪声将严重干扰密集对应的预测。本文训练了一个U-Net结构的去噪网络用于单帧预去噪,去噪结果使用Id表示,噪声使用In表示。
2、由于RAW视频数据是bayer格式,4通道,每个像素的相邻像素实际应该为次相邻像素,为了方便构建空间结构,这里使用打包的方式,将原始RAW视频数据流拆分成4个子数据流。
特征对齐
在视频去噪的上下文中,对齐用于确保连续帧中相应的像素点在空间位置上是一致的,这样可以利用时间上的冗余信息来改善去噪性能。
总结来说,对齐是确保不同帧之间的特征能够正确合并的关键步骤。
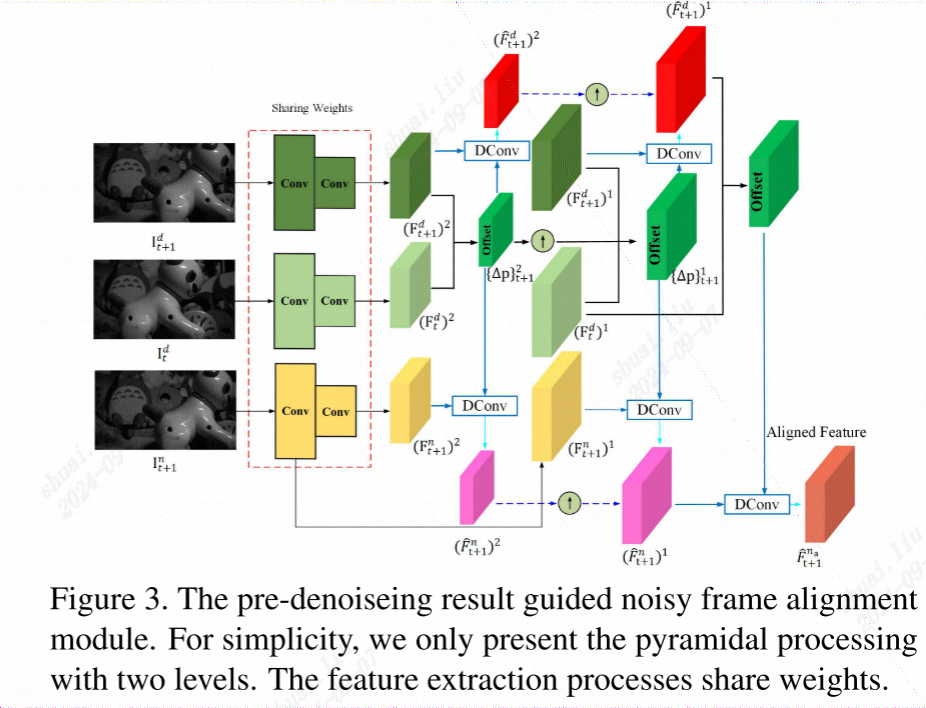
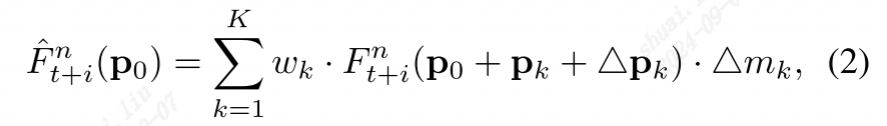
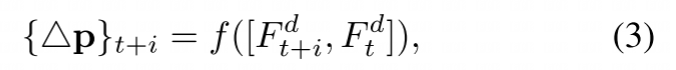
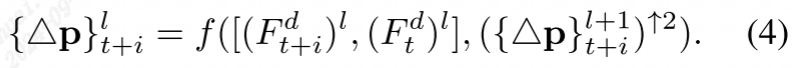
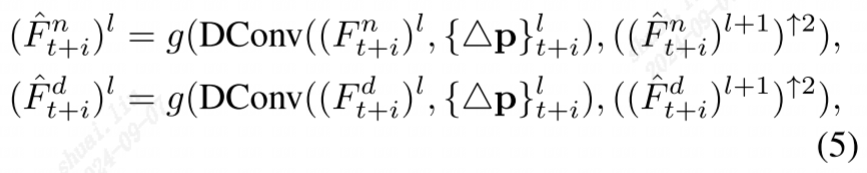
(暂时不太懂。。。)
网络结构
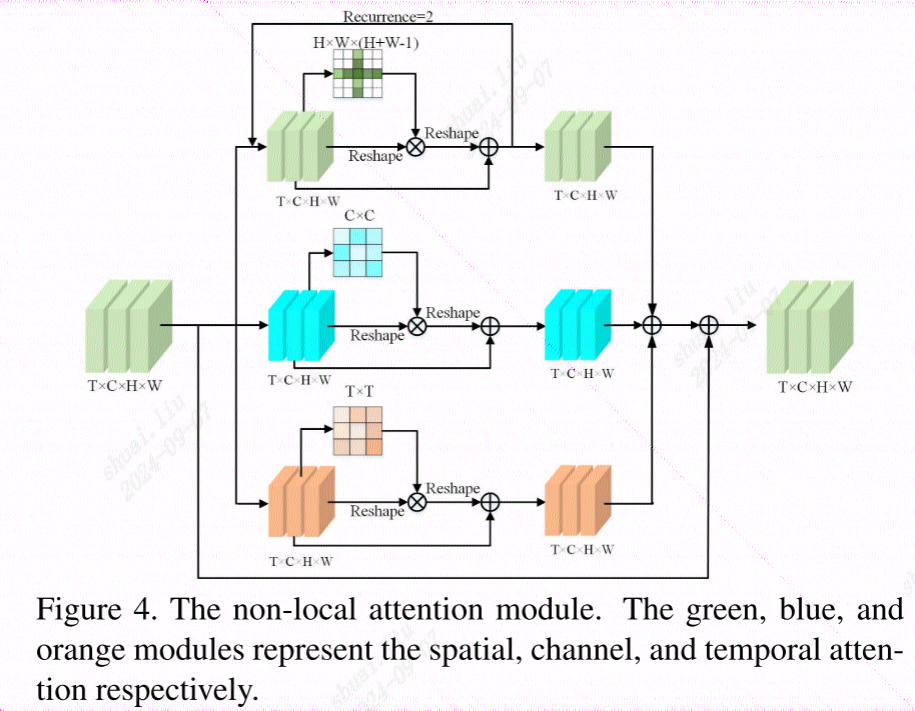
1、使用DConv进行非局部相似聚合
2、使用语义分割任务的非局部自注意加强特征表示
由于3D非局部注意力消耗巨大的成本,使用分离的注意力模块,包括空间注意力,通道注意力,时间增强注意力(时序)。
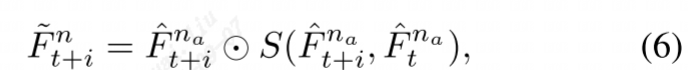
空间融合
将时间融合模块中的特征FfusR、FfusG1、FfusB和FfusG2连接在一起,然后通过空间融合网络
进行融合。空间融合网络包含10个残差块、一个CBAM[37]模块来增强特征表示,以及一个卷积层来预测大小为4 ×H ×W的噪声。
Loss函数

包括重建损失(reconstruction loss)和时间一致性损失(temporal consistent loss)。重建损失确保去噪后的图像在原始域和sRGB域与真实图像相似,而时间一致性损失则确保视频序列中连续帧之间的一致性。
QA
对齐输入帧?
可形变卷积对齐输入帧,而不是显示使用流信息?
temporal -poral域?
噪声将严重干扰密集对应的预测?密集对应?