Redis 集群:如何实现数据的高效分片与负载均衡
- 一 . 基本概念
- 二 . 数据分片算法
- 2.1 哈希求余算法
- 2.2 一致性哈希算法
- 2.3 哈希槽分区算法
- 核心思路
- Redis 集群中最多只能有 16384 个分片吗 ?
- 为什么一定要是 16384 个槽位 ?
- 三 . 基于 docker 进行集群的搭建
- 3.1 创建目录和配置
- 3.2 编写 generate.sh
- 编写脚本
- 脚本含义
- 3.3 编写 docker-compose.yml
- 编写脚本
- 脚本含义
- 3.4 构建集群
- 3.5 使用集群
- 四 . 模拟主节点宕机
- 4.1 流程模拟
- 4.2 故障转移处理流程
- (1) 故障判定
- (2) 故障迁移
- 4.3 特殊情况
- 五 . 集群扩容
- 5.1 把新的主节点加入到集群中
- 5.2 重新分配槽位号
- 5.3 将从节点加入到集群中
Hello , 大家好 , 这个专栏给大家带来的是 Redis 系列 ! 本篇文章给大家讲解的是 Redis 的 Sentinel . Sentinel 是 Redis 的高可用性解决方案,它通过监控 Redis 主从集群的状态、执行故障转移以及更新配置来提供高可用性。Sentinel 系统由多个 Sentinel 节点组成,这些节点是独立运行的进程,它们负责监控 Redis 主从集群的状态,并在主节点出现故障时自动进行故障转移,将一个从节点提升为新的主节点。
本专栏旨在为初学者提供一个全面的 Redis 学习路径,从基础概念到实际应用,帮助读者快速掌握 Redis 的使用和管理技巧。通过本专栏的学习,能够构建坚实的 Redis 知识基础,并能够在实际学习以及工作中灵活运用 Redis 解决问题 .
专栏地址 : Redis 入门实践

一 . 基本概念
集群这个词 , 是存在狭义和广义的概念的
- 广义的集群 : 只要是多个机器构成了分布式系统 , 就可以称为一个集群 . 我们之前学习过的主从结构、哨兵模式也可以是广义的集群
- 狭义的集群 : Redis 提供的集群模式 , 在这个集群模式下主要是用来解决存储空间不足的问题 (扩展存储空间)
我们之前学习过哨兵模式 , 他提高了系统的可用性 . 但是哨兵模式本质还是 Redis 的主从节点存储数据 , 其中就要求一个主节点 / 从节点来存储所有数据 , 而 Redis 是内存型数据库 , 主要在内存中存储数据 , 而内存大小也是有限制的 , 所以我们就需要引入多台机器 , 每台机器存储一部分数据 .
假设我们有 1TB 的数据需要存储
- 如果使用两台机器来存 , 每个机器只需要存储 512GB 即可
- 如果使用三台机器来存 , 每个机器只需要存储 300 多 GB 即可
- 如果使用四台机器来存 , 每个机器只需要存储 256GB 即可
随着机器数目的增加 , 每个机器存储的数据量就减少了 , 只要机器的规模足够多就可以存储任意大小的数据了 .
那如果其中的某个机器挂了 , 那咋办 ?
我们还需要每个存储数据的机器 , 也需要搭配若干个从节点 .

那既然我们要把数据分成多份 , 但是应该怎么分呢 ?
二 . 数据分片算法
在集群中 , 我们把每一个分出来的部分叫做分片
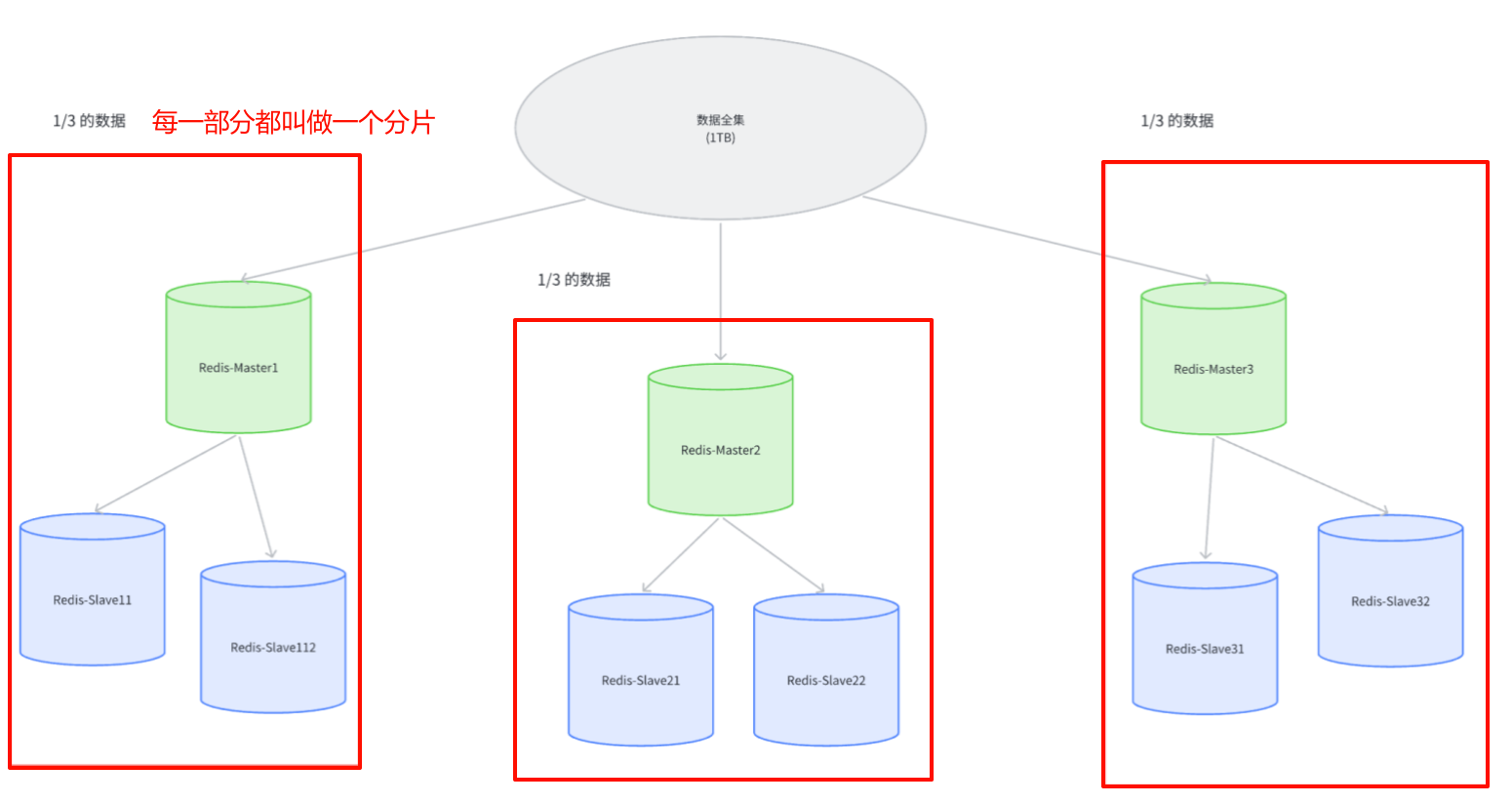
那我们需要考虑一下 , 新增加的数据应该放到哪个分片中 , 后续我想查询数据应该从哪个分片中查询呢 ?
这就需要用到我们的数据分片算法
2.1 哈希求余算法
哈希求余算法通过借助一个 hash 函数 , 把一个 key 映射成一个整数 , 再针对数组长度进行取余操作 , 就可以得到一个数组下标 . 可以用一个公式进行概括 : hash(key) % N .
比如目前有三个分片 , 编号为 0、1、2 , 此时就可以针对要插入的数据的 key 通过某种算法 (比如 md5 算法) 来去计算 hash 值 , 再把 hash 值对分片个数就行取余操作 , 就会得到一个下标 . 我们就可以把这个数据放到该下标对应的分片中了 .
md5 是一个计算 hash 值的算法 , 他可以针对一个字符串把里面的内容进行一系列的变换 , 最终得到一个 16 进制的数字
MD5 是一个非常广泛使用的 hash 算法
- md5 计算结果是定长的 : 无论输入的原字符串有多长 , 得到的结果长度都是固定位数的 (32 位 / 16 位的)
- md5 计算的结果是分散的 : 两个原字符串哪怕大部分都相同 , 只有一个小部分不同 , 那算出来的 md5 值也会差别很大 ,这样就有效的减少了哈希冲突
- md5 计算结果是不可逆的 [存疑 , 彩虹表] : 通过原字符串可以很容易算出 md5 的值 . 但是通过 md5 的值很难还原出原始的字符串 , 但是现在已经有很多可以进行 md5 破解的网站了

但是哈希求余算法也存在很大的问题 : 一旦服务器需要进行扩容 , 就需要更高的成本了 . 分片的目的主要是为了能够提高存储能力 , 那分片分的越多 , 能够存储的数据也就越多 , 但是成本也就越高 .
一般情况下 , 都是先少设置几个分片 , 但是随着业务数据的增长 , 几个分片就保存不下数据了 , 就需要进行扩容 .
那我们就可以继续引入多个分片 , 但是这样的话 hash(key) % N 中的 N 发生了改变 , 整体的分片结果就会发生变化 . 如果我们发现某个数据在扩容之后 , 就不应该继续待在当前分片中了 , 就需要进行重新分配 (搬运数据) .

2.2 一致性哈希算法

2.3 哈希槽分区算法
核心思路
这个算法是目前 Redis 真正采用的分片算法 .
哈希槽分区算法提供了一个公式 : hash_slot = crc16(key) % 16384
crc16 也是一个计算哈希值的算法
其中 , 16384 是 16 * 1024 乘积的值 , 也就是 2^14 = 16k
那就是把当前算出来的哈希值映射到 16384 这么大的空间上 , 得到了哈希槽这样的概念 .
然后再把得到的哈希槽均匀地分配到不同的分片上 .
我们举个例子 : 假设当前有三个分片 , 其中一种可能的分配方式
- 0 号分片 : [0,5461] , 共 5462 个槽位
- 1 号分片 : [5462,10923] , 共 5462 个槽位
- 2 号分片 : [10924,16383] , 共 5460 个槽位
虽然并未达到完全均匀 , 但是已经很接近了 . 此时我们可以认为这三个分片上的数据是比较均匀的了 .
这种算法本质上就是把哈希求余算法和一致性哈希算法这两种方式相结合
哈希求余算法就是针对 16384 进行取余
一致性哈希算法是将哈希槽均匀地分配到不同的分片上
这里列举出的只是一种可能的分片方式 , 实际上分片是非常灵活的 , 每个分片持有的槽位号 , 可以连续也可以不连续 . 每个分片都会使用位图这样的数据结构 , 表示出当前有多少槽位号 . 那 16384 个 bit 位 , 就可以用 0/1 来区分自己这个分片当前是否属于该槽位号 .
那怎样来去实现分区扩容呢 ?
还是假设当前有三个分片 , 其中一种可能的分配方式
- 0 号分片 : [0,5461] , 共 5462 个槽位
- 1 号分片 : [5462,10923] , 共 5462 个槽位
- 2 号分片 : [10924,16383] , 共 5460 个槽位
如果我们需要新增分片 , 就可以把每个分片持有的槽位各拿出一点点分给新的分片
那新的分配方式就变成了
- 0 号分片 : [0,4095] , 共 4096 个槽位
- 1 号分片 : [5462,9557] , 共 4096 个槽位
- 2 号分片 : [10924,15019] , 共 4096 个槽位
- 3 号分片 : [4096,5461] + [9558,10923] + [15020,16383] , 共 4096 个槽位
在 Redis 中 , 当前某个分片包含多少槽位也是可以手动配置的
那某个分片上面的槽位号也不一定非得是连续的区间 , 因为我们可以借助位图这样的数据结构 , 将该位设置成 0/1 就代表自己这个分片当前是否属于该槽位号 .
另外 , 在上述过程中 , 只有被移动的槽位对应的数据才需要被搬运 , 这样搬运次数也大大减少了
Redis 集群中最多只能有 16384 个分片吗 ?
Redis 集群中最多有 16384 个槽位 , 如果 16384 个分片的话 , 这就代表每个分片都只有一个槽位 .
此时很难保证数据在各个分片上面的均衡性 .
实际上 Redis 的作者建议集群分片数不能超过 1000
为什么一定要是 16384 个槽位 ?
我们在 Redis 的 Github 仓库上 , 也能看到作者对于此答案的回答 : https://github.com/redis/redis/issues/2576
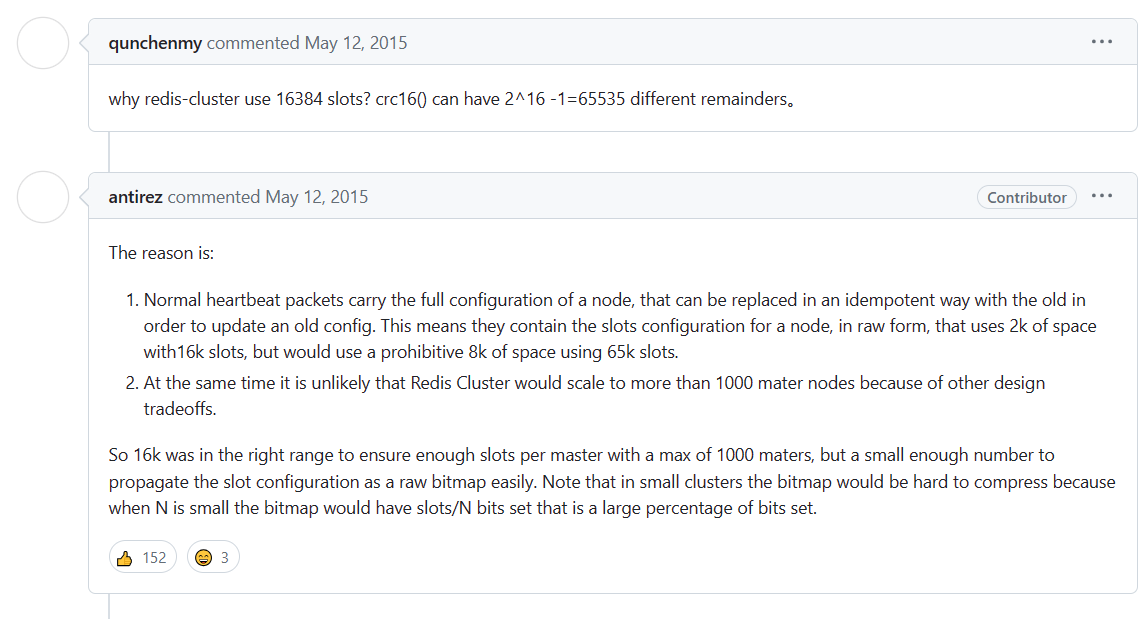
意思就是
- 节点之间通过心跳包通信 , 心跳包中包含了该节点持有哪些槽位 (也就是需要表示出当前节点需要多少槽位) , 那就需要使用位图这样的数据结构进行表示 . 如果要表示 16384 个槽位的话 , 就需要的位图大小为 2kb , 如果给定的槽位更多 , 那就需要消耗更多的空间 . 这对于内存来说 , 并不算什么 , 但是对于频繁的周期性的心跳包监测机制中开销还是比较大的 .
- 另一方面 , Redis 集群要求一般不能超过 10000 个分片 , 所以 16384 个槽位对于 1000 个分片来说足够用 , 同时也会让对应分片的位图体积不会很大 .
三 . 基于 docker 进行集群的搭建
我们需要通过 docker 在云服务器上搭建出一个 Redis 集群 , 我们要搭建的 Redis 集群长这个样子
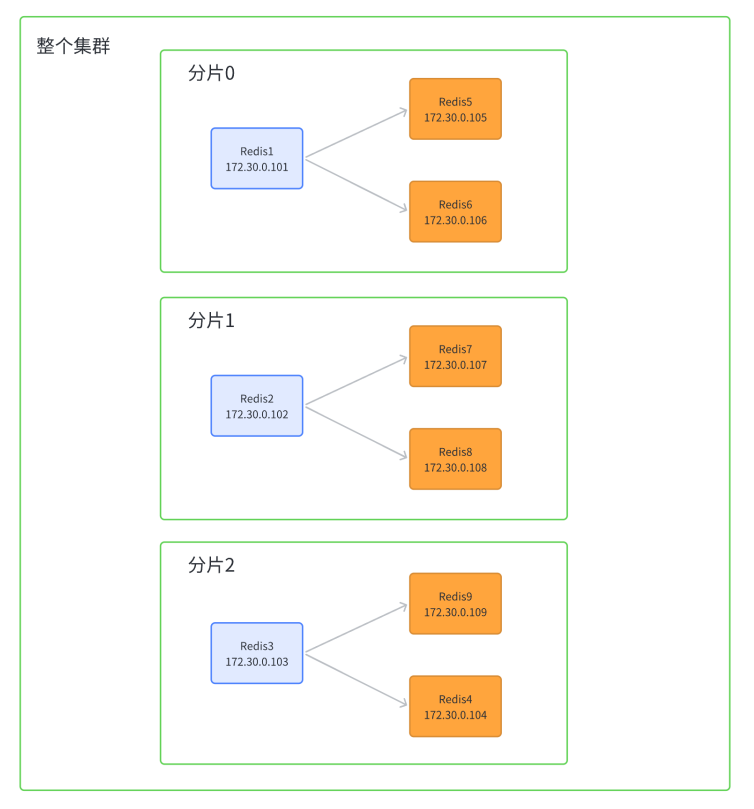
我们预期要有三个分片 , 每个分片中有一个主节点和两个主节点 , 每个分区中的数据是一样的 , 但是不同分区的数据是不一样的 , 主要是用来进行备份的 .
当前阶段主要是因为我们只有一个云服务器 , 去实现一个真正的分布式系统不太现实 .
在工作中是通过多台主机来去搭建集群的 .
3.1 创建目录和配置
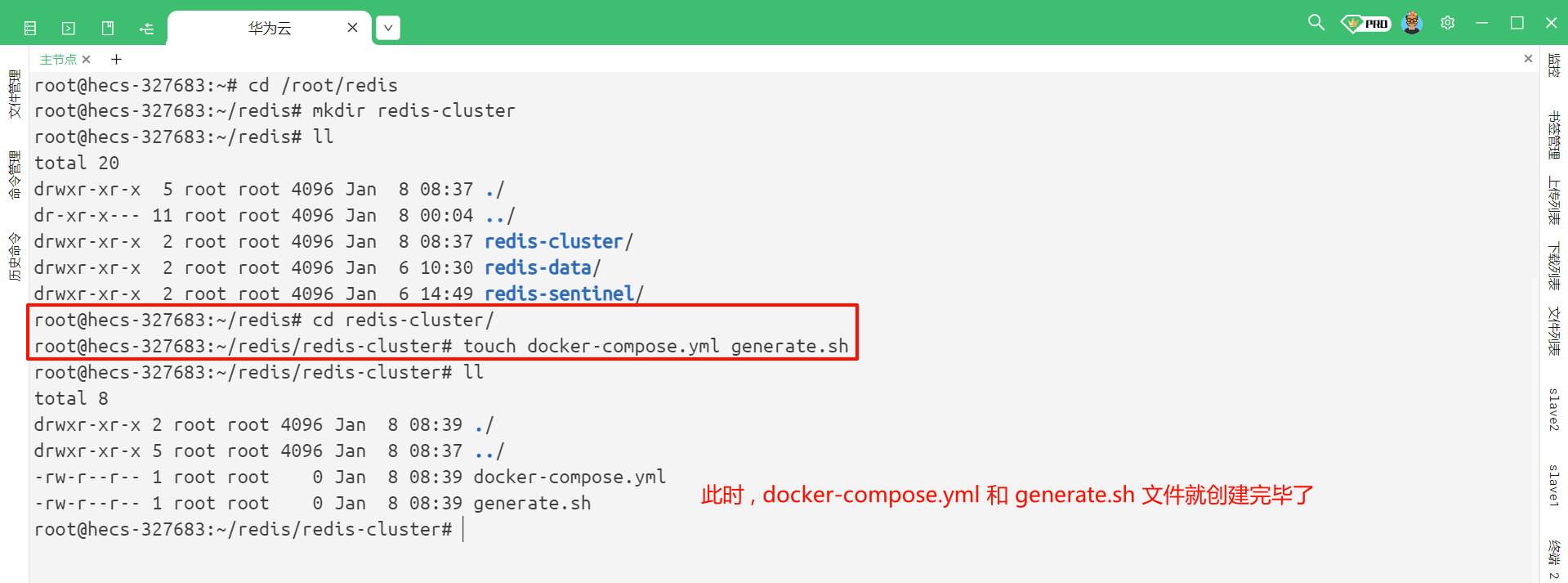
在 /root/redis 目录下 , 再创建一个文件夹叫做 redis-cluster
cd /root/redis
mkdir redis-cluster

然后进入到 redis-cluster 目录中 , 再创建两个文件 : docker-compose.yml、generate.sh
cd /redis-cluster
touch docker-compose.yml generate.sh
然后一定要记得 , 将之前启动的 Redis 容器停掉
cd /root/redis/redis-sentinel
# docker-compose 命令必须切换到对应的目录才能成功执行
docker-compose down

cd /root/redis/redis-data
# docker-compose 命令必须切换到对应的目录才能成功执行
docker-compose down

现在 , 我们就可以通过 docker ps -a 命令来去查看一下是否还有容器正在执行

3.2 编写 generate.sh
编写脚本
在 Linux 系统中 , 以 .sh 后缀结尾的文件 , 称为 Shell 脚本
使用 Linux 系统的时候 , 都是通过一些命令来进行操作的 .
使用多个命令操作就非常适合把命令给写入到一个文件中 , 批量化执行 .
那 Shell 脚本还支持加入条件、循环、函数等机制 , 因此就可以完成一些更复杂的操作了
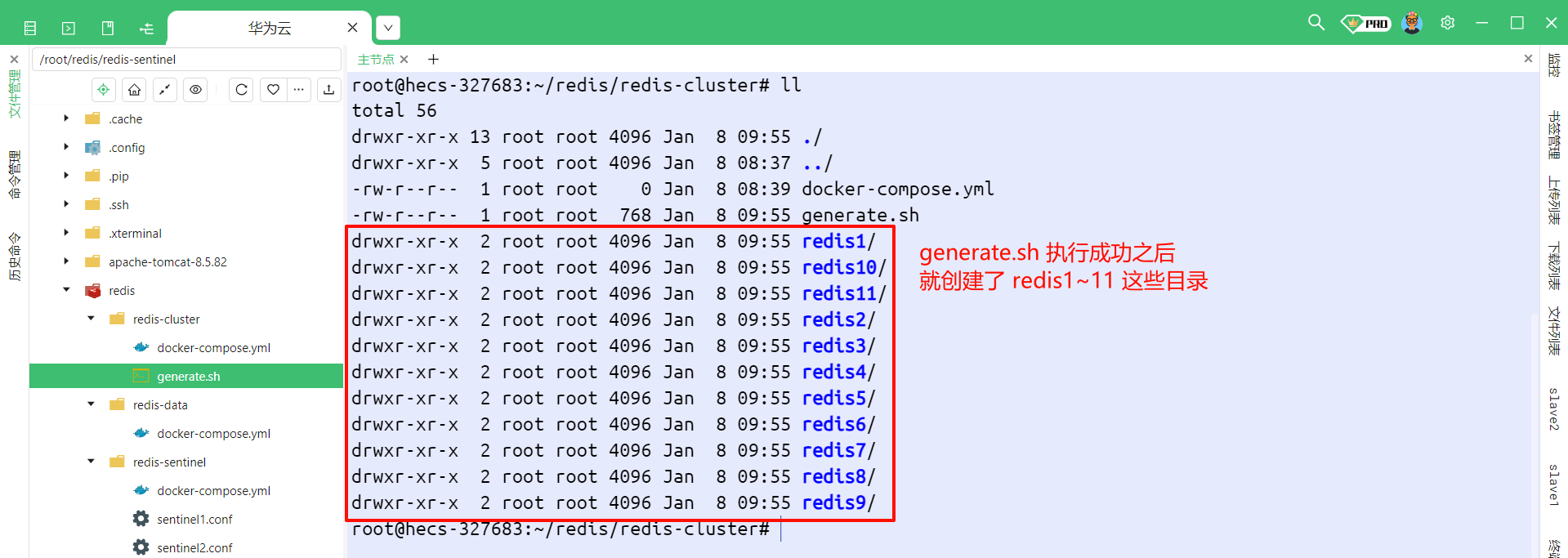
我们需要创建 11 个 Redis 节点 , 这些 Redis 的配置文件的内容大同小异 , 那我们就可以通过脚本来批量生成
当然我们也可以不通过脚本 , 一个文件一个文件修改
我们就需要将下面的配置粘贴到 generate.sh 中

cd /root/redis/redis-cluster
vim generate.sh
for port in $(seq 1 9); \
do \
mkdir -p redis${port}/
touch redis${port}/redis.conf
cat << EOF > redis${port}/redis.conf
port 6379
bind 0.0.0.0
protected-mode no
appendonly yes
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
cluster-announce-ip 172.30.0.10${port}
cluster-announce-port 6379
cluster-announce-bus-port 16379
EOF
done
# 注意 cluster-announce-ip 的值有变化.
for port in $(seq 10 11); \
do \
mkdir -p redis${port}/
touch redis${port}/redis.conf
cat << EOF > redis${port}/redis.conf
port 6379
bind 0.0.0.0
protected-mode no
appendonly yes
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
cluster-announce-ip 172.30.0.1${port}
cluster-announce-port 6379
cluster-announce-bus-port 16379
EOF
done
粘贴并保存成功之后 , 我们来执行脚本 , 使用命令 bash generate.sh 命令
如果报了这个错误
generate.sh: line 1: syntax error near unexpected token
$'\\\r'' 'enerate.sh: line 1:for port in $(seq 1 9); </font>使用 sed -i ‘s/\r$//’ generate.sh 命令即可 , 这是由于存在 Windows 隐藏的换行符是 \r\n , 而 Linux 中换行符是 \n, 这样就导致不兼容 .
我们执行之后可以就看到 , 创建了 11 个 Redis 目录
我们再进入某一个 redis 目录中 , 可以看到配置文件也创建成功

脚本含义
我们也来看一下这个脚本的含义

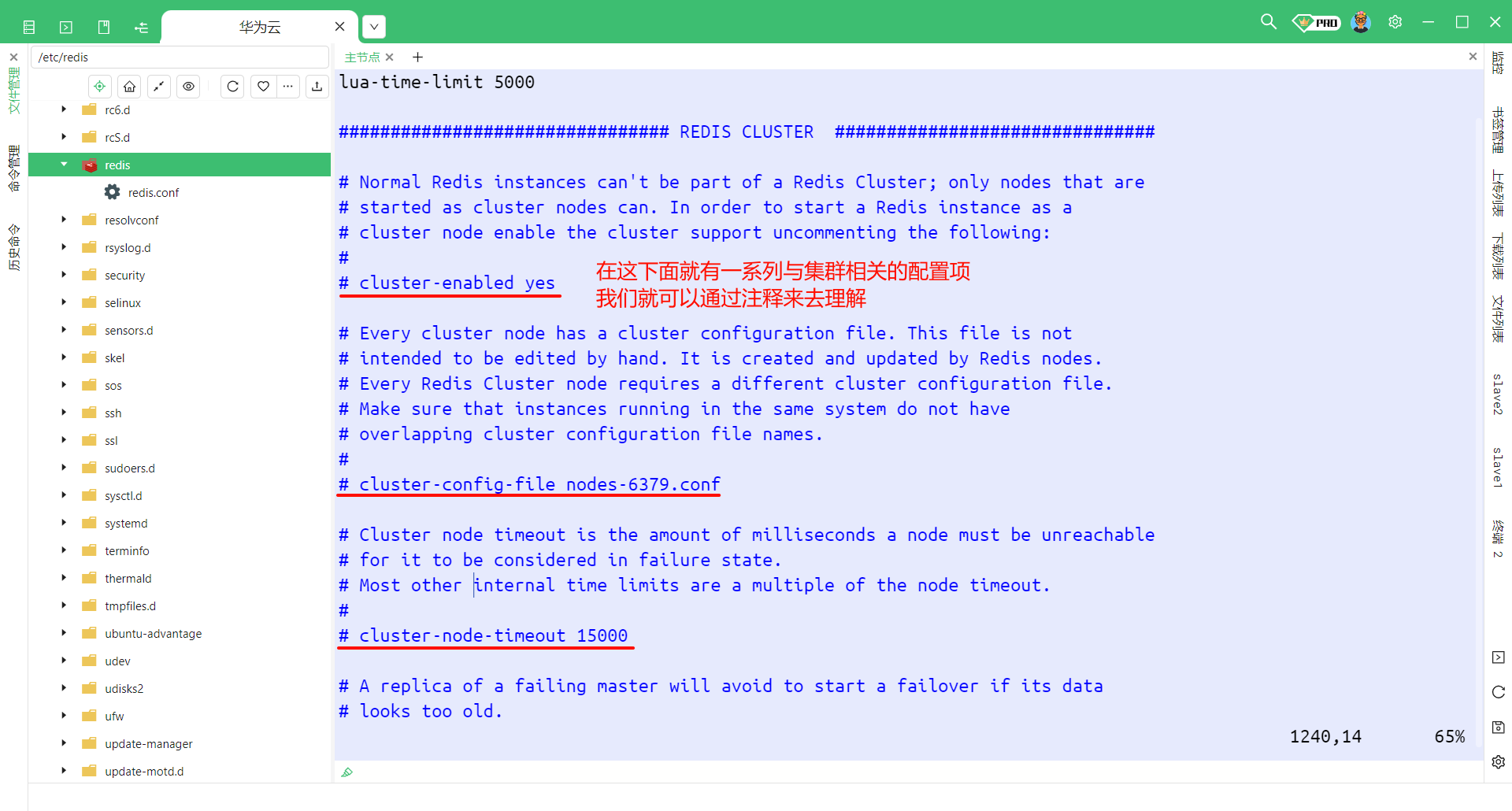
其实这些配置在 Redis 的配置文件中 , 也有讲解
3.3 编写 docker-compose.yml
编写脚本
我们将下面的配置粘贴到 docker-compose.yml 中

cd /root/redis/redis-cluster
vim docker-compose.yml
version: '3.7'
networks:
mynet:
ipam:
config:
- subnet: 172.30.0.0/24
services:
redis1:
image: 'redis:5.0.9'
container_name: redis1
restart: always
volumes:
- ./redis1/:/etc/redis/
ports:
- 6371:6379
- 16371:16379
command:
redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.101
redis2:
image: 'redis:5.0.9'
container_name: redis2
restart: always
volumes:
- ./redis2/:/etc/redis/
ports:
- 6372:6379
- 16372:16379
command:
redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.102
redis3:
image: 'redis:5.0.9'
container_name: redis3
restart: always
volumes:
- ./redis3/:/etc/redis/
ports:
- 6373:6379
- 16373:16379
command:
redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.103
redis4:
image: 'redis:5.0.9'
container_name: redis4
restart: always
volumes:
- ./redis4/:/etc/redis/
ports:
- 6374:6379
- 16374:16379
command:
redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.104
redis5:
image: 'redis:5.0.9'
container_name: redis5
restart: always
volumes:
- ./redis5/:/etc/redis/
ports:
- 6375:6379
- 16375:16379
command:
redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.105
redis6:
image: 'redis:5.0.9'
container_name: redis6
restart: always
volumes:
- ./redis6/:/etc/redis/
ports:
- 6376:6379
- 16376:16379
command:
redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.106
redis7:
image: 'redis:5.0.9'
container_name: redis7
restart: always
volumes:
- ./redis7/:/etc/redis/
ports:
- 6377:6379
- 16377:16379
command:
redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.107
redis8:
image: 'redis:5.0.9'
container_name: redis8
restart: always
volumes:
- ./redis8/:/etc/redis/
ports:
- 6378:6379
- 16378:16379
command:
redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.108
redis9:
image: 'redis:5.0.9'
container_name: redis9
restart: always
volumes:
- ./redis9/:/etc/redis/
ports:
- 6379:6379
- 16379:16379
command:
redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.109
redis10:
image: 'redis:5.0.9'
container_name: redis10
restart: always
volumes:
- ./redis10/:/etc/redis/
ports:
- 6380:6379
- 16380:16379
command:
redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.110
redis11:
image: 'redis:5.0.9'
container_name: redis11
restart: always
volumes:
- ./redis11/:/etc/redis/
ports:
- 6381:6379
- 16381:16379
command:
redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.111
然后我们就可以启动了
注意 : 在启动之前 , 一定要把之前已经运行的 Redis 结束掉 , 否则就有可能因为端口冲突等原因 , 导致现在的启动失败
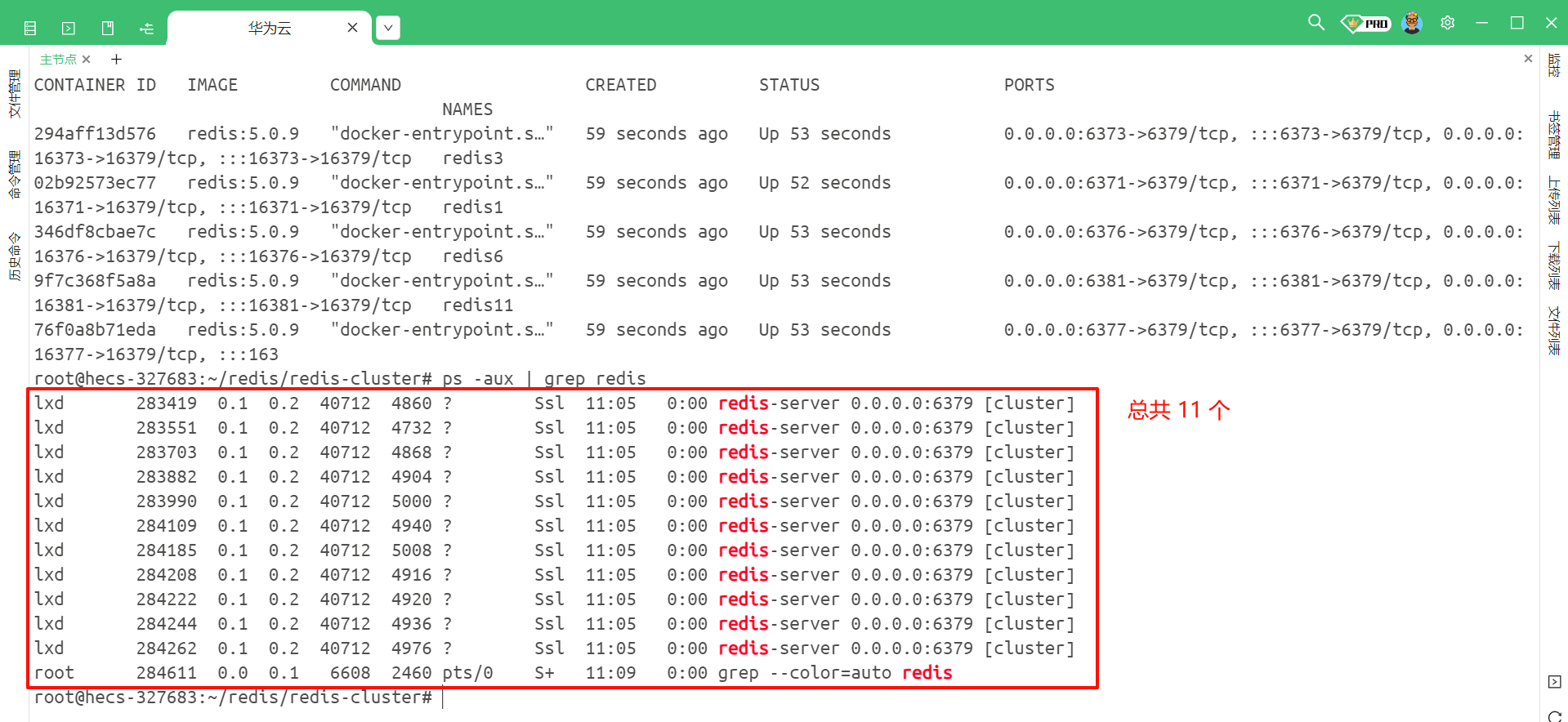
我们检查一下目前是否有 Redis 的进程正在工作 , 使用 ps -aux | grep redis 和 docker ps -a
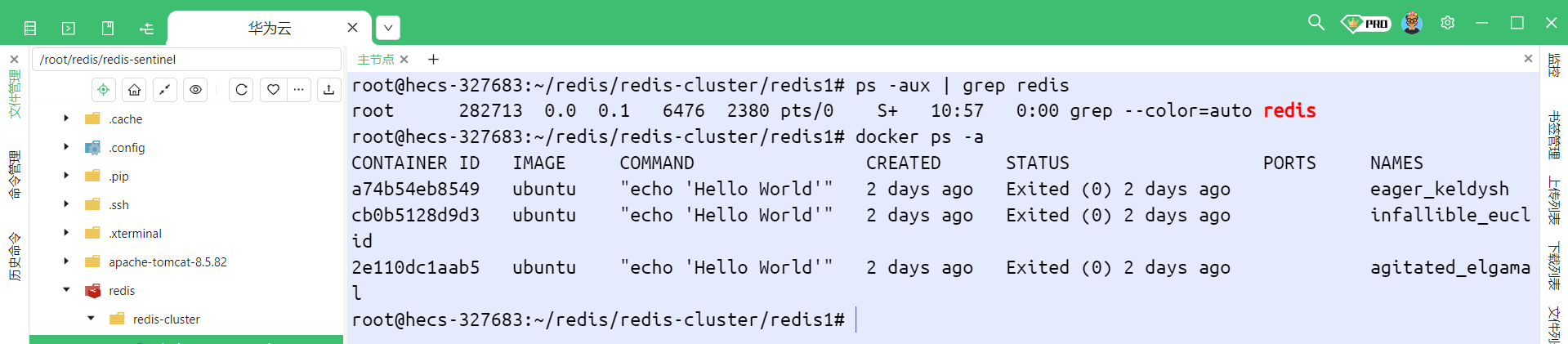
此时我们就可以启动这些 Redis 容器
cd /root/redis/redis-cluster
docker-compose up -d
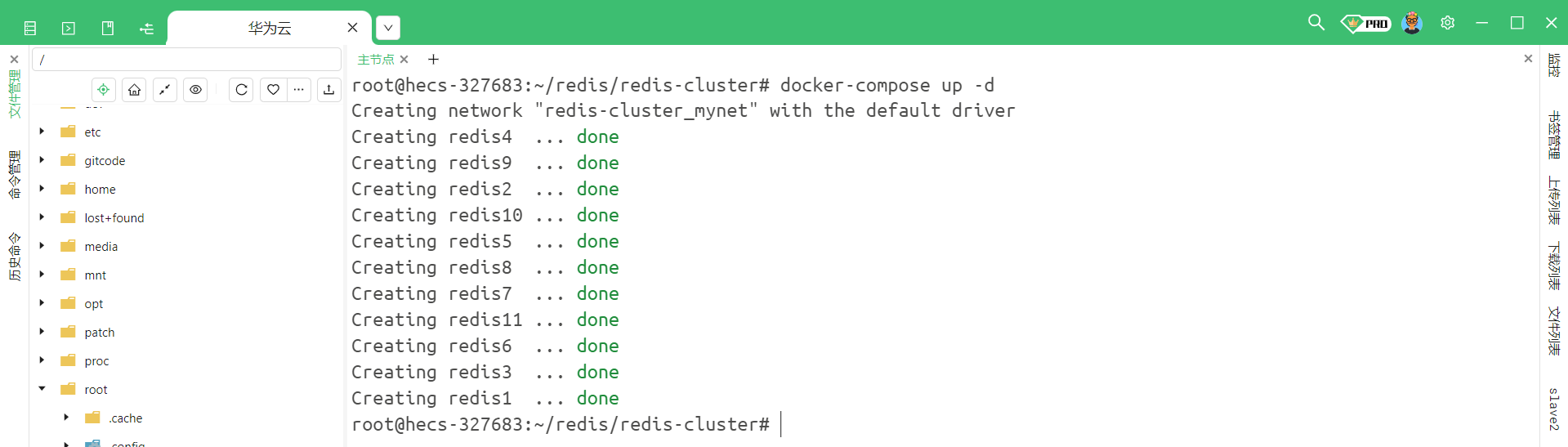
此时 , 这些节点就成功启动了
如果发现报错了
我们就可以来看一下 82 行有什么错误 , 使用 vim 打开
输入
:set nu就可以显示行号 , 输入 :82 就可以跳转到第 82 行

然后通过 docker ps -a 也可以观察到这些节点已经启动

也可以通过 ps -aux | grep redis 来去查看
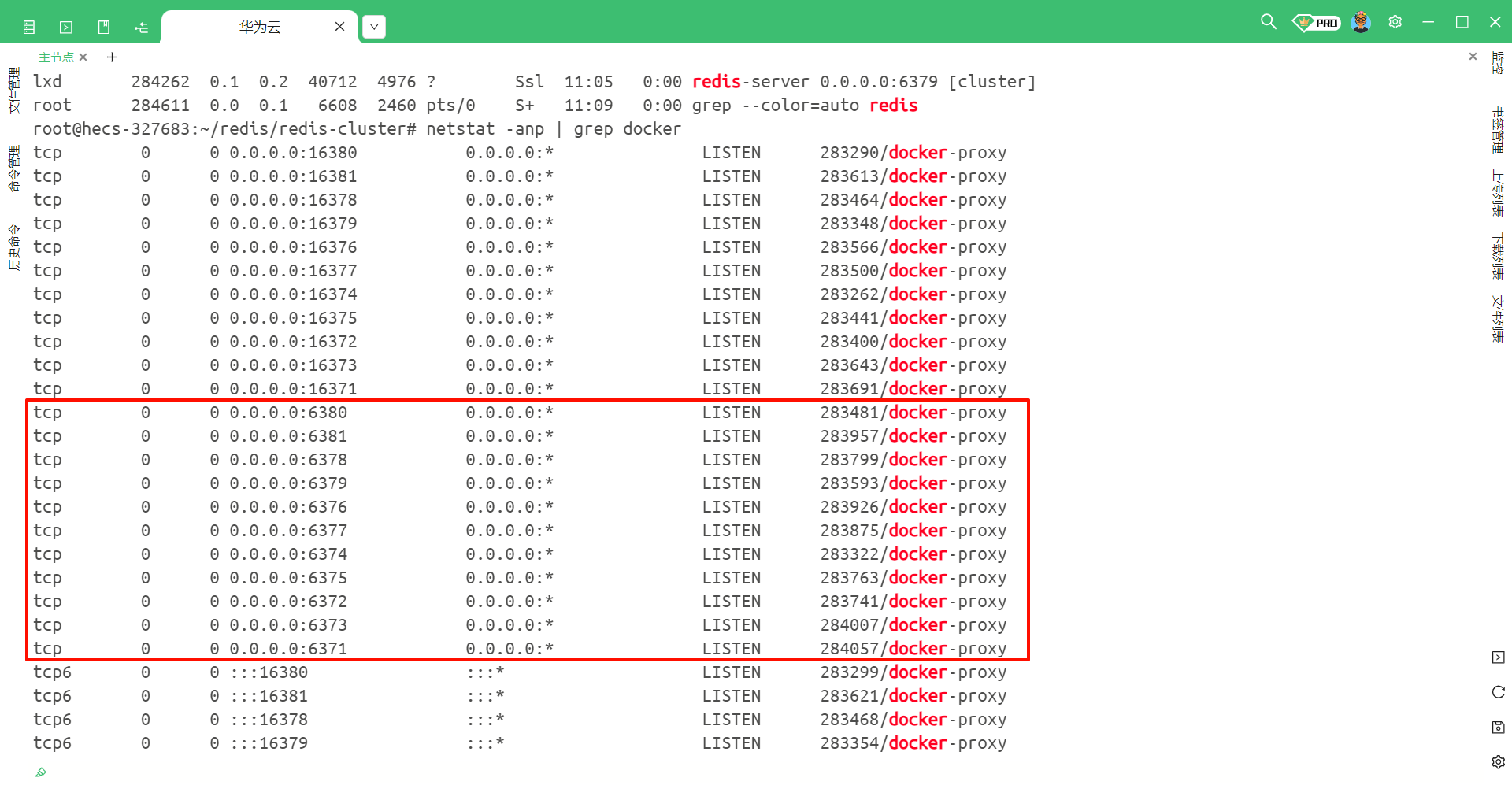
也可以通过 netstat -anp | grep docker 来去查看
脚本含义

3.4 构建集群
我们需要将刚才创建的所有 Redis 节点构建成集群
使用这个命令来去指定每个参与构建集群的 IP 和端口 (注意 : 端口都是写容器内部的端口号 , 也就是 6379)
redis-cli --cluster create 172.30.0.101:6379 172.30.0.102:6379 172.30.0.103:6379 172.30.0.104:6379 172.30.0.105:6379 172.30.0.106:6379 172.30.0.107:6379 172.30.0.108:6379 172.30.0.109:6379 --cluster-replicas 2

要注意的是 , 这个命令是直接在命令行中执行的 , 并不是在 redis-cli 中执行的
另外 , 要保证我们的 IP 和端口号一定是跟 docker 中配置的网络号和端口号一致 , 不然后续会出现其他问题
那我们就执行这个命令

然后我们还需要输入 yes 确认

然后我们就构建成功了

3.5 使用集群
我们使用 redis-cli -h 172.30.0.101 -p 6379 就可以连接到 101 这个节点了
或者使用 redis-cli -p 6371 也可以连接到 101 这个节点

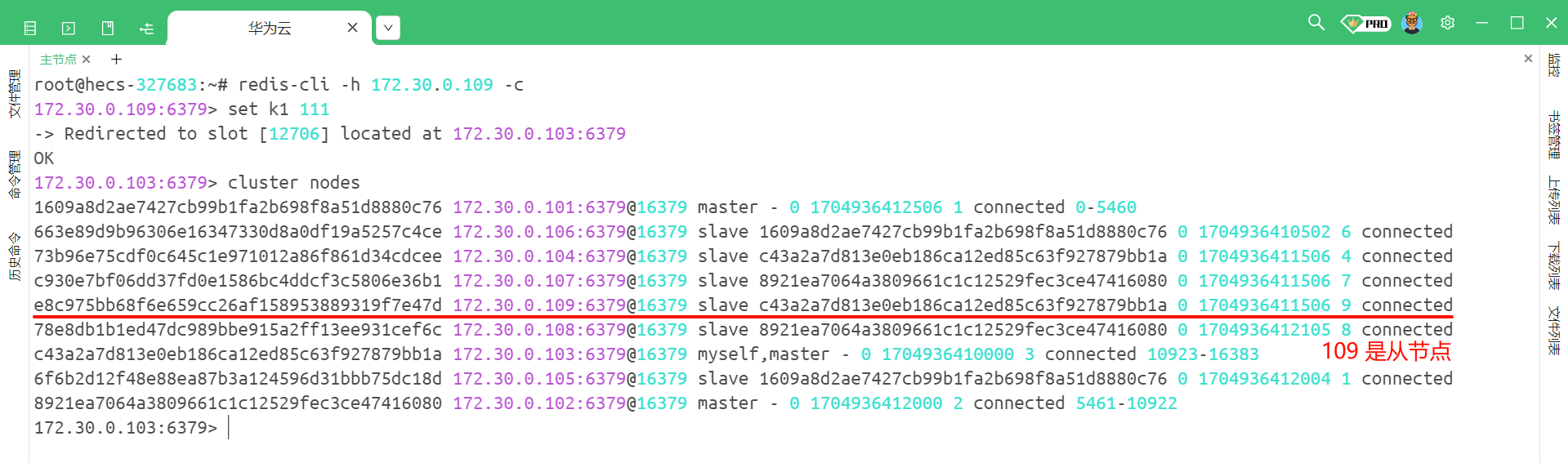
101 节点 ~ 109 节点此时现在是一个集群 , 我们使用客户端连接上任意一个节点 , 本质上都是一样的 .
我们可以使用 cluster nodes 来去查看当前集群的信息
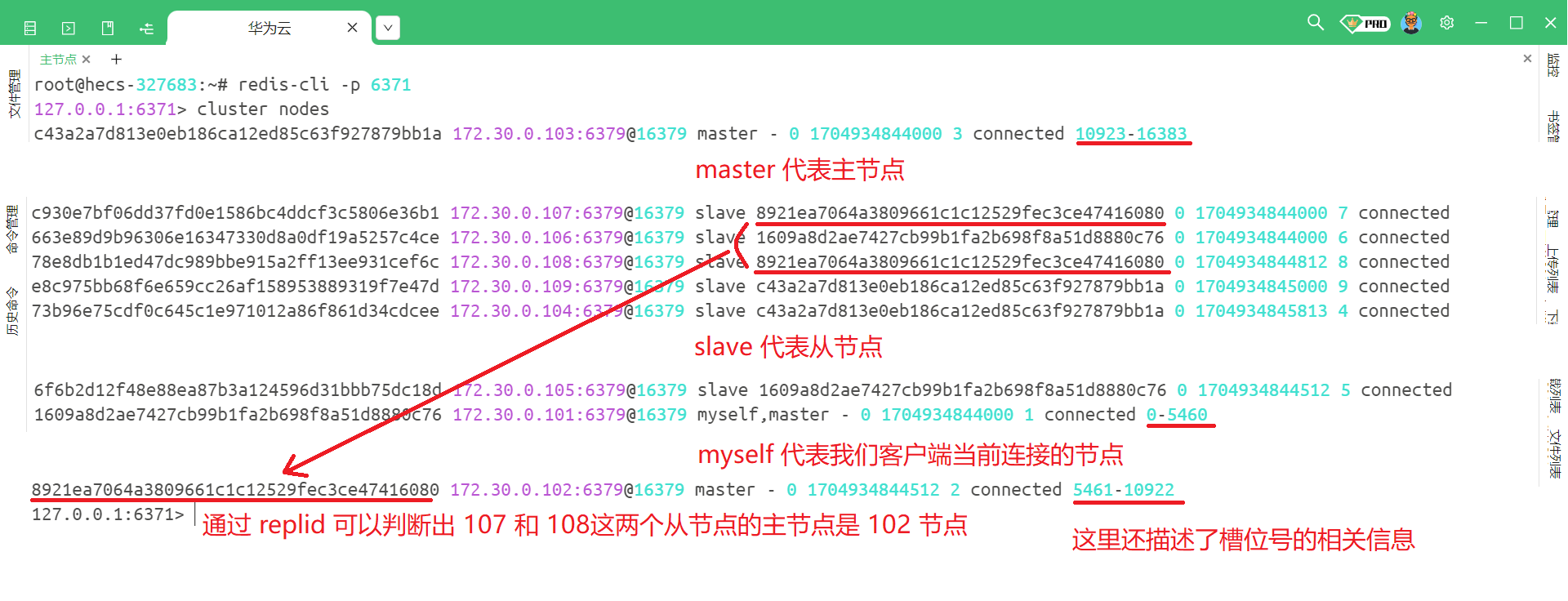
但是我们主要的目的还是使用集群来存储数据
但是我们插入数据之后 , 还出错了

出错的原因是因为我们设置成集群模式之后 , 当前数据就被分片了 . 那我们的 k1 这个键被 hash 之后 , 得到的槽位号为 12706 , 而这个 12706 是属于 103 这个节点的

所以我们一般实际的做法是在启动 Redis 客户端的时候 , 加上 -c 选项 , 此时客户端发现当前 key 的操作不在当前分片上 , 就能够自动的重定向到对应的分片主机

而且下面的端口号也发生了变化 , 把请求转发给了 103 节点

但是有一种情况 , 我们之前学习过的一些命令 , 比如 : mset、mget 等等 , 他们是可以操作多个 key 的 . 但是如果 key 是分散在不同的分片上的 , 就可能会出现问题了 .

因此我们在使用集群的时候 , 就需要慎重使用这种命令了
四 . 模拟主节点宕机
如果集群中有节点挂了 , 都会产生什么情况呢 ?
- 如果挂的是从节点 , 无伤大雅
- 如果挂的是主节点 , 比较难受 , 因为只有主节点才能进行写操作 .
当我们在从节点上进行写操作 , 此时就会自动的被重定向到指定的主节点上
但是在集群中 , 如果主节点挂了 , 集群就会选择主节点下面的某个从节点升级成主节点 , 我们可以模拟一下
4.1 流程模拟
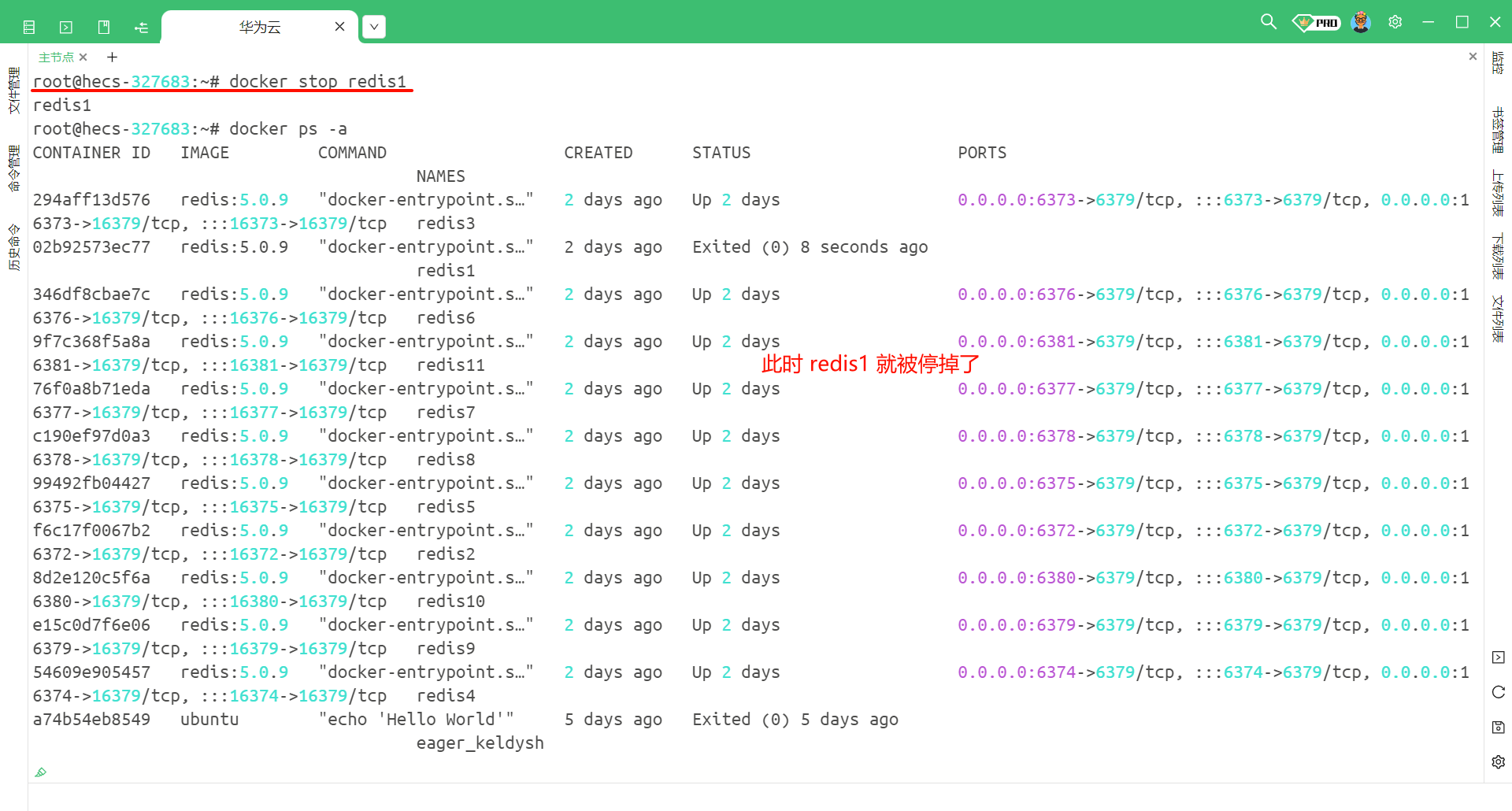
首先 , 通过 docker ps -a 命令查看我们目前 docker 相关的进程

然后我们看到了 redis1 , 而 redis1 正好是主节点 , 那我们就可以将 redis1 停掉 , 使用 docker stop redis1
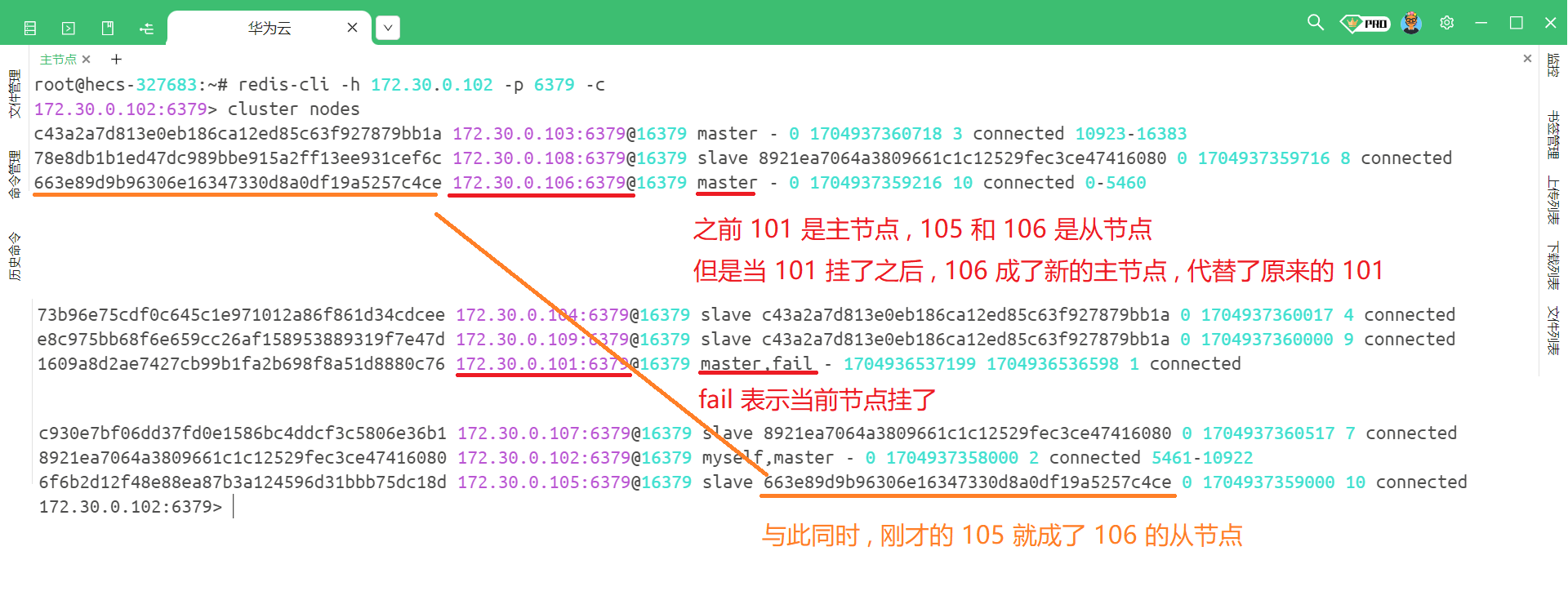
此时我们随便连接一个客户端 , 然后使用 cluster nodes 来查看当前的节点信息
那此时我们把 redis1 , 也就是将之前的主节点重新启动会发生什么 ?
使用 docker start redis1 命令
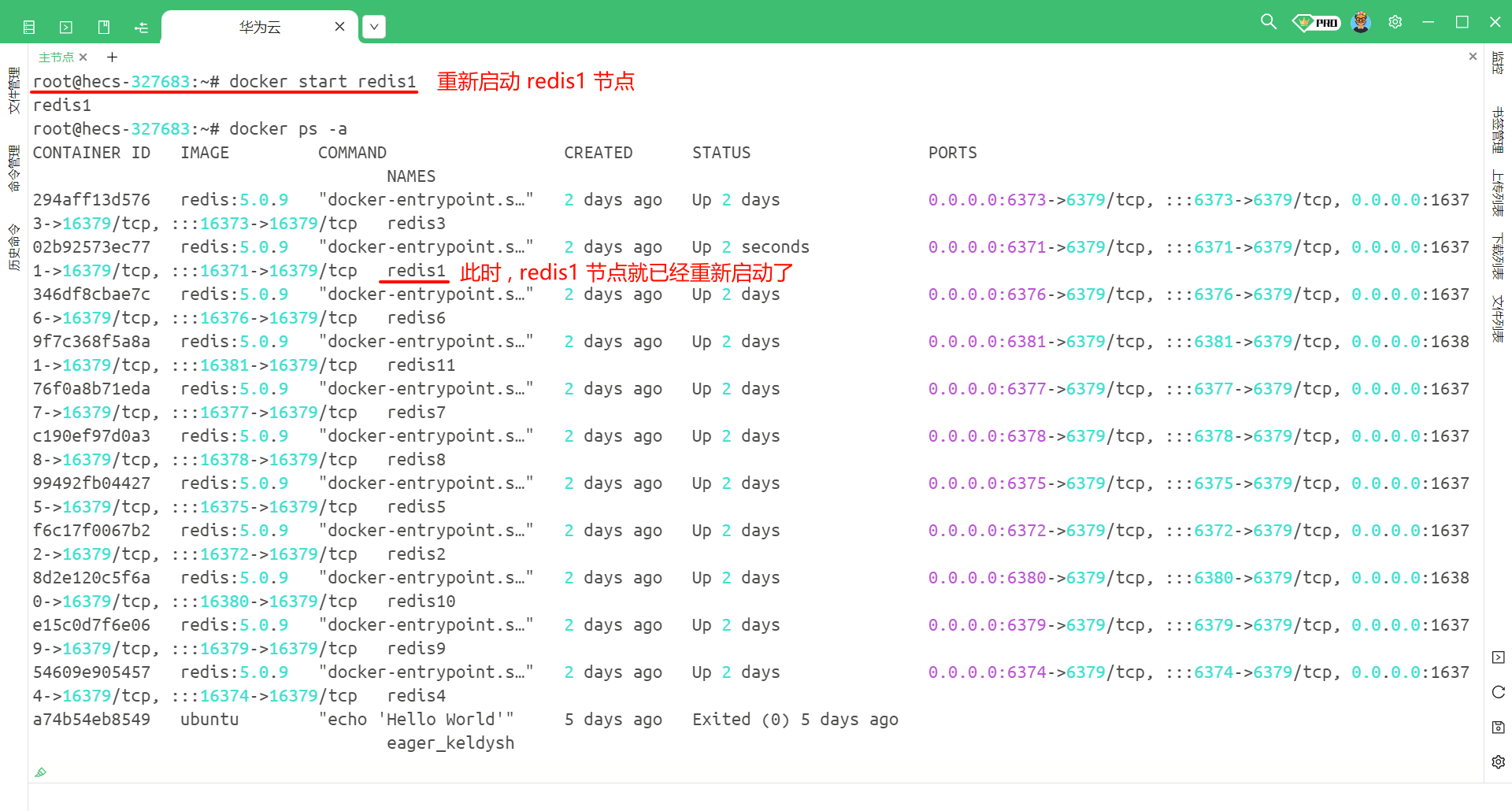
然后我们再随便连接一个节点 , 然后查看一下当前节点的信息
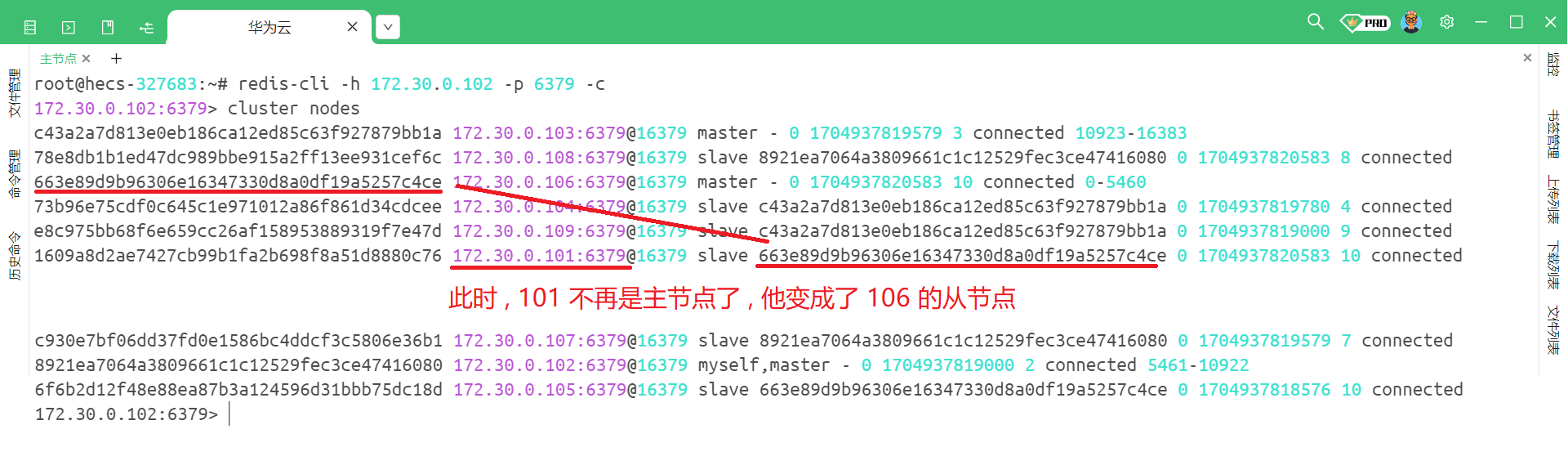
那我们能看到 , 集群机制是能够进行故障转移的 .
4.2 故障转移处理流程
(1) 故障判定
故障判定是用来判断某个节点是否已经挂了 , 他的流程如下 :
- 集群中不同的节点互相之间会传输心跳包 (ping-pong) , ping 和 pong 除了 message type 属性之外 , 其他部分都是一样的 , 都包含了集群的配置信息 (该节点的 ID、该节点属于哪个分片、当前节点是主节点还是从节点、从节点从属于谁、持有哪些 slots 的位图 …)
- 每个节点每秒钟会随机给一些节点发起 ping 包
- 当节点 A 给节点 B 发起 ping 包 , 如果 B 不能够如期回复 , 此时节点 A 就会尝试重置和 B 的 tcp 连接 , 查看一下重新连接能否成功 . 如果依然连接失败 , 节点 A 就会把节点 B 标记为 PFAIL 状态 (就相当于主观下线了)
- 节点 A 判定节点 B 为 PFAIL 状态之后 , 就会通过 Redis 的内置 Gossip 协议和其他节点进行沟通 , 就会向其他节点确认 B 的状态 .
- 此时节点 A 发现已经超过一般的节点认为节点 B 已经下线 , 那么节点 A 就会把节点 B 标记成 FAIL , 并且把这个消息告诉给其他的节点
(2) 故障迁移
如果节点 B 是从节点 , 那就不需要进行故障迁移 . 如果 B 是主节点 , 那么节点 B 的从节点触发故障迁移
故障迁移的具体流程如下 :
- 从节点判定自己是否有参选资格 : 如果从节点和主节点已经太久没有通信过了 (此时从节点的数据基本就和主节点数据差异较大了) , 就会失去竞选资格
- 具有资格的节点 (比如 : C 和 D) , 就会先休眠一段时间 . 休眠时间 = 500ms 基础时间 + [0ms , 500ms] 随机时间 + 排名 * 1000ms . (offset 越大 , 排名越靠前 , 意味着排名也就越小 , 休眠时间也就越短)
- 假如 C 的休眠时间到了 , C 就会给其他所有集群中的节点进行拉票操作 (但是只有主节点才有投票资格)
- 当 C 收到的票数超过了主节点数目的一半 , C 就会晋升成主节点 (C 自己执行 slaveof no one , 并且通知 D 执行 slaveof C)
- 同时 , C 还会把自己成为主节点的消息通知给其他集群的节点 , 大家都会更新自己的集群结构信息
通过这个流程中可以发现 : 谁休眠时间短 , 大概率就是新的主节点 .
这个流程就叫做 Raft 算法 , Raft 算法经常在分布式系统中使用 .
4.3 特殊情况
有的情况下 , 某个或者某些节点宕机 , 就有可能导致整个集群都宕机 (这种叫做 fail 状态)
以下三种情况就会出现集群宕机
- 某个分片 , 所有的主节点和从节点都挂了 -> 该分片就无法提供数据服务了
- 某个分片 , 主节点挂了但是他没有从节点 -> 该分片就无法提供数据服务了
- 超过一半的 master 节点都挂了 -> 可以认为整个集群遇到了非常严重的情况 , 此时就需要赶紧停止集群服务来去检查存在什么问题
五 . 集群扩容
我们之前介绍的哈希槽分区算法 , 他的目的就是为了更好更方便地去进行扩容 .
我们接下来演示一下怎样进行集群扩容
目前我们已经有了 101~109 这 9 个主机 , 已经构成了 3 个一主二从的集群了 , 那么我们就需要将 110 和 111 也加入到集群中 , 让 110 作为主节点 , 111 作为从节点 . 这样的话分片就从 3 个变成了 4 个
主要明确的是 : 集群扩容操作 , 是一件风险极高、成本较大的操作
5.1 把新的主节点加入到集群中
# 新增一个节点
redis-cli --cluster add-node 172.30.0.110:6379 172.30.0.101:6379

我们执行命令看一下
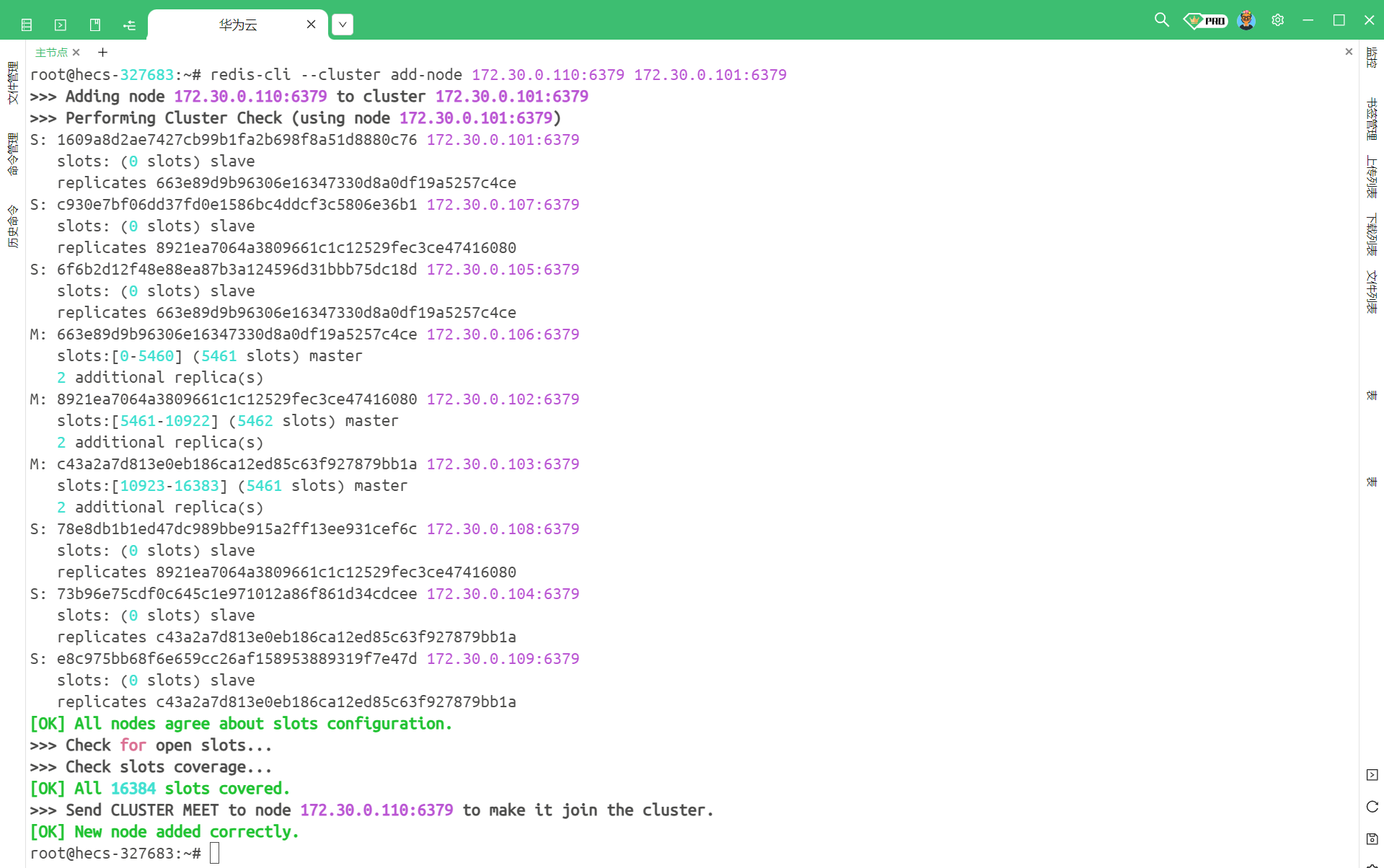
此时我们可以看到下面成功的提醒了 , 那我们再连接一个 Redis 客户端来去查看集群节点结构

5.2 重新分配槽位号
我们需要将之前三组的 master 上面的槽位分配一些给新的 master
# 对哈希槽重新分配
redis-cli --cluster reshard 172.30.0.101:6379
我们来执行命令

接下来 , 我们就需要手动分配槽位号了 , 有一系列的操作 , 我们分别来看

我们可以看一下集群的节点配置
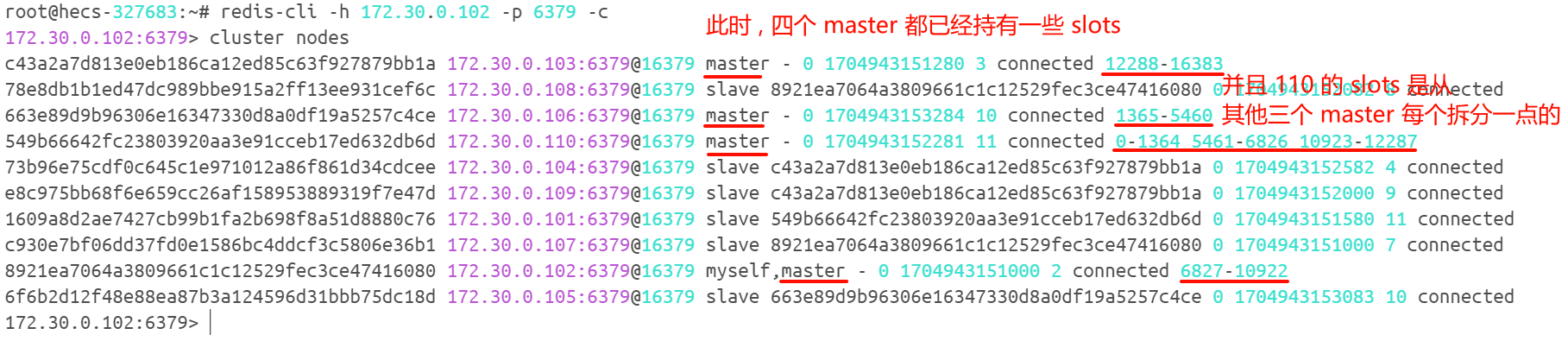
那如果我们在扩容搬运 slots / key 的过程中 , 此时客户端能否访问 Redis 集群呢 ?
搬运 key 的时候 , 如果使用哈希槽分区算法的话 , 大部分的 key 是不用搬运的 , 针对这些未搬运的 key , 此时都是可以正常访问的 . 那针对正在搬运的 key , 是有可能出现访问出错的情况的 .
那如果我们想要让扩容对于用户的影响更小的话 , 就需要搞一组新的机器 , 重新搭建集群 , 然后将数据导入进来 , 之后使用新集群来去替代旧集群 (成本很高)
5.3 将从节点加入到集群中
我们的目的就是将 111 节点添加进来 , 让它作为 110 的从节点
redis-cli --cluster add-node 172.30.0.111:6379 172.30.0.101:6379 --cluster-slave --cluster-master-id [110 节点的 nodeId]
# redis-cli --cluster add-node 172.30.0.111:6379 172.30.0.101:6379 --cluster-slave --cluster-master-id 549b66642fc23803920aa3e91cceb17ed632db6d
我们可以看到 , 这条命令最后需要获取 110 节点的 nodeId , 所以我们需要先获取一下

然后就可以使用命令了
注意 : 这个命令依然是在命令行中使用 , 而不是 Redis 的客户端中使用
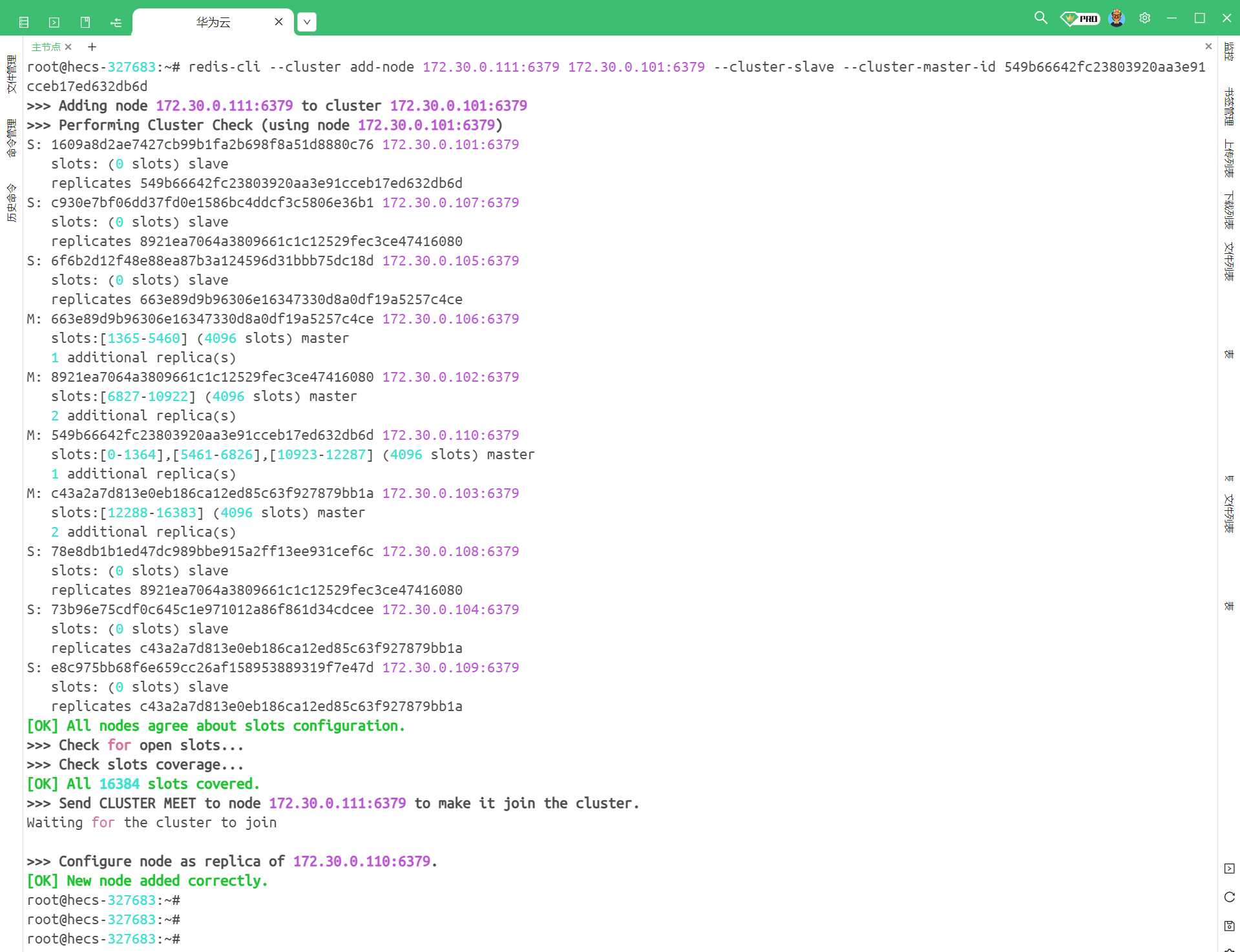
此时显示新节点添加成功 , 我们就可以连接到这个集群

Redis 集群相关的内容就给大家介绍完毕了 , 如果对你有帮助的话 , 还请一键三连 , 你的鼓励是对我最大的支持~