1.生产者消费者模型
前面的同步,我们并没有一个很好的场景来模拟同步,只是简单的将有序的现象输出出来;现在我们来讲解一个比较合理且常见的模型——生产者消费者模型;
1.1模型理解
什么是生产者消费者模型:
这个模型是多线程实现同步与互斥的场景:
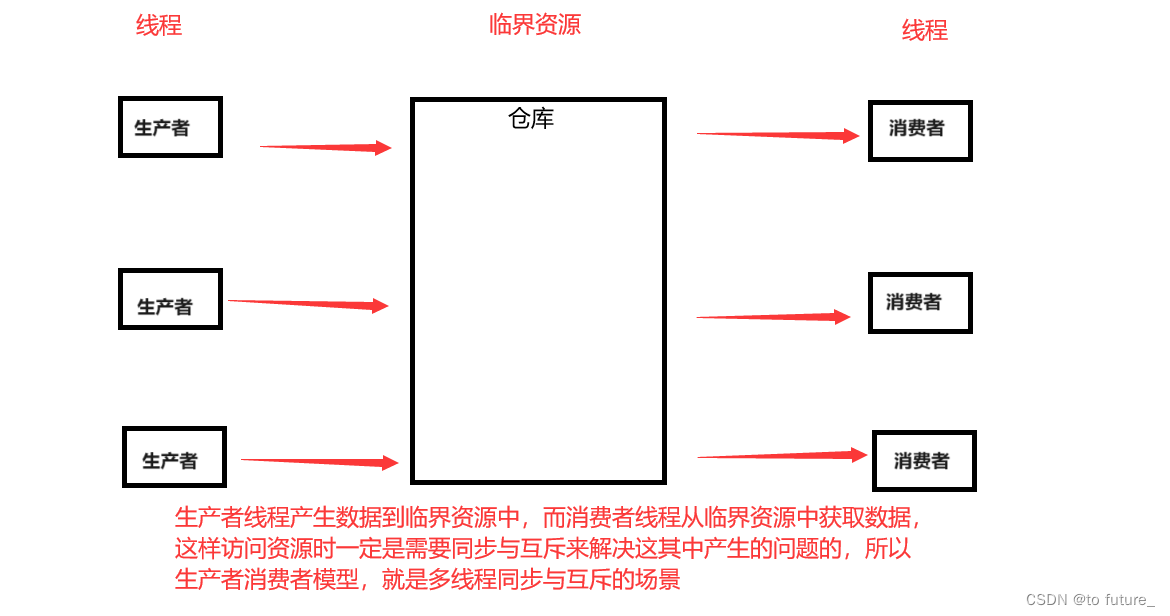
这个场景中有三对关系:
消费者与消费者(互斥关系)
消费者与生产者 (同步与互斥关系)
生产者与生产者 (互斥关系)
两种对象:
生产者与消费者
一个共享资源:
生产者与消费者们都能看到的内存空间
1.2代码实现
接下来就让我们看看我们在实际编程中,这样的单生产单消费模型是什么样的:
#include <iostream>
#include <pthread.h>
#include <unistd.h>
#include <vector>
#include <queue>
using namespace std;
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t c_cond = PTHREAD_COND_INITIALIZER;//其实现在这种场景放在一个队列与两个队列中没有什么区别
pthread_cond_t p_cond = PTHREAD_COND_INITIALIZER;//我认为应该是在之后生产者之间或者是消费者之间
//他们两大类自己内部的互斥需要cond控制顺序,所以这里有两个条件变量
template <class T>
class dataQueue
{
public:
void push(const T &data)
{
pthread_mutex_lock(&mutex);
if (_q.size() >= _size)
{
pthread_cond_signal(&c_cond);//唤醒消费者
pthread_cond_wait(&p_cond, &mutex);
}
_q.push(data);
cout << "comsumer push " << data << " to queue" << endl;
// if(_q.size()>=push_max)//我认为这里的代码是没有必要的,下面同样的地方有解释
// {
// pthread_cond_signal(&c_cond);//唤醒消费者
// }
pthread_mutex_unlock(&mutex);
}
void pop()
{
pthread_mutex_lock(&mutex);
if (_q.size() == 0)
{
pthread_cond_signal(&p_cond);//唤醒生产者
pthread_cond_wait(&c_cond, &mutex);
}
T top = _q.front();
_q.pop();
cout << "productor pop " << top << " from queue" << endl;
// if(_q.size()<=pop_min)//这是蛋哥的代码,我认为这里的控制似乎是没有任何用的,当队列中数据小于了最小pop数时唤醒生产者
// { //而生产者只会在锁被释放时才会被唤醒,而我们自己这个循环会马上去获取锁,而队列中的数据此时是为
//pop_min的,除非我们将等待条件设置为pop_min否则消费者不会停止动作,而如果把等待条件设置为pop_min
//那我们就根本没有必要用两个循环来控制,之间将唤醒与等待放入同一个循环即可,所以我认为这里的代码是没有必要的
// pthread_cond_signal(&p_cond);//唤醒生产者
// }
pthread_mutex_unlock(&mutex);
}
private:
queue<T> _q;
int _size =5;//这是我们控制的一个队列中最多可以容纳的数据量
//我们可以通过这些变量来控制pop与push的动作
// int push_max=8;//当队列中数据压入最多个数
// int pop_min=3;//队列中数据存在最少个数
};
dataQueue<int> q;
struct threadData
{
string _threadName;
threadData(string name)
: _threadName(name)
{
}
threadData() = default;
};
void *productor(void *args)
{
threadData *data = static_cast<threadData *>(args);
int i = 0;
while (true)
{
sleep(1);
q.push(i++);
}
}
void *consumer(void *args)
{
threadData *data = static_cast<threadData *>(args);
while (true)
{
q.pop();
}
}
int main()
{
pthread_t ctid, ptid;
threadData *data1 = new threadData("comsumer");
threadData *data2 = new threadData("productor");
pthread_create(&ctid, nullptr, consumer, data1);
pthread_create(&ptid, nullptr, productor, data2);
void *retData;
pthread_join(ctid, &retData);
pthread_join(ptid, &retData);
return 0;
}现象:
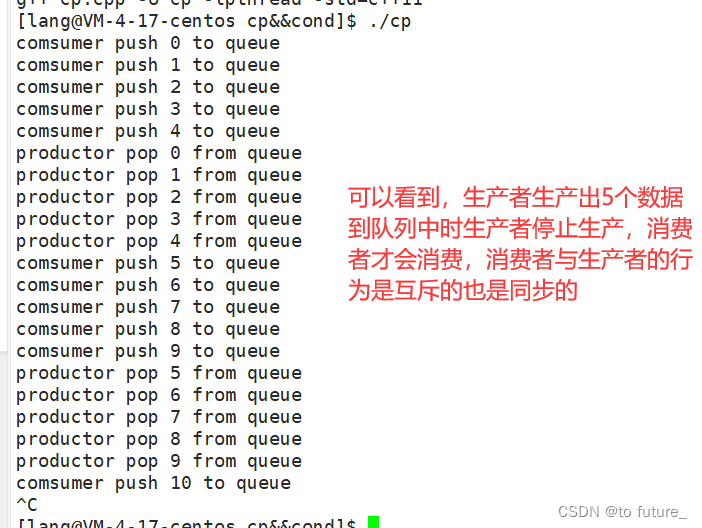
这就是初步的生产消费模型;
所以实现这样的控制需要互斥与同步一起进行,操作有:
1.加锁(保证临界资源的使用)
2.判断(看是否可以进行生产或者消费)->这也解释了上面同步中为什么wait要在加锁之后,因为判断是否具备生产消费的条件需要通过临界资源进行判断,需要在锁内访问;
3.等待(如果不满足生产消费的条件,会进行等待)
4.解锁(释放锁,为唤醒和等待队列中的线程提供条件)
上面就是基本的单生产单消费模型的概念与实现,牢记321口诀即可;
接下来我还实现了生产消费模型的进阶版:
thread2024.5.14/cp&&cond/cp_pro.cpp · future/Linux - 码云 - 开源中国 (gitee.com)
这份文件的代码中,我增加了生产与消费的过程,并将生产者与消费者的数量增加,形成了一个完整的生产消费模型;(代码太长)可以点击上面gitee链接查看我的代码;
2.posix信号量
前面的cp模型是使用cond条件变量与mutex互斥锁来写的单生产单消费,而信号量可以更优雅的创建cp模型;
2.1信号量是什么
信号量的本质是一把计数器,而这把计数器的本质又是临界资源,所以对于信号量的操作,我们的库底层自己进行了封装操作,让信号量的++,--操作是原子的;
我们前面在进程通信部分,我们就讲过了systemV版本的信号量,我们知道信号量就像是门票,我们只有持有了信号量才能访问临界资源;详细的讲解可以看这篇博客中的信号量部分:
进程间通信,管道,匿名管道,共享内存,信号量-CSDN博客
2.2信号量的函数
信号量的初始化函数:

第一个参数是一个sem_t类型的信号量的地址,第二个参数为0时信号量只在当前线程中可见,信号量为非0时在当前进程中都可见,第三个参数是信号量这个计数器的初始值;
信号量的加减操作:
wait操作是减减操作我们又可以称之为P操作,当遇到此函数时,信号量会进行减减操作,让信号量计数器减1;

post函数是加加操作,又可以叫做V操作 ,当遇到此函数时,信号量会进行加加操作,让信号量计数器加1;

上面两个函数参数只需传递信号量的地址即可;
信号量的摧毁函数:

由此可见信号量应该是在堆区上开辟的空间所以,需要一个摧毁函数来释放这份空间,来防止内存泄漏的问题;
2.3信号量创建cp模型
那么信号量究竟是如何做到帮助形成cp模型的呢?我们下面用一个循环队列的例子来表明信号量的作用;

现在看来这样的cp模型似乎和上面使用同步互斥锁的cp模型没有什么不同,只是它们的共享空间不同而已;但是不用着急下面就会说到信号量的作用了;

通过上面,我们就可以明白信号量所起到的作用;当然,现在你可能还有一个疑问,为什么这个cp模型要使用循环队列呢?为什么不和前面的cp模型一样直接使用队列呢?
为什么要使用循环队列作为容器 ?
其实这并不冲突,我们也可以使用普通的队列或者其他数据结构来充当共享空间,但是我们在编代码时,我们就会发现,无论我们用那种数据结构,我们插入数据时,生产者指针的位置会向后移动,并生产一份数据在队列上,消费数据时,消费者的指针也会向后移动,并消费一个数据,让队列中拥有一个空闲位置资源,而数组的大小不是无穷大的,所以我们一定要有某种策略使得,生产者可以移动到消费者消费出来的空闲位置生产数据,消费者可以移动到生产者生产出的数据上消费数据,而循环队列是一个刚好可以满足这种情况的数据结构,所以才使用循环队列来作为容器;

通过上面的图片,我们也可以明白为什么这个cp模型的容器是循环队列,只是根据不同的应用场景来选择罢了;
2.4信号量代码的实现
我们上面讲解了信号量的理论,接下来我们用实际的编码来理解信号量的作用;
thread2024.5.14/4_sem · future/Linux - 码云 - 开源中国 (gitee.com)
由于代码太长,我们需要通过上面链接去gitee观看;

现象:

信号量实现cp模型的代码,我认为文字的讲解太过于复杂,如果你们想分析我的代码,可以使用gpt来分析,我下面就只说一下我自己认为的重要的地方:
互斥锁与信号量操作先后:

因为信号量操作本身是原子的,所以不需要被保护,而信号量的数量是大于锁数量的,当多个线程同时访问临界资源时,这多个线程获取信号量的难度一定是小于锁的, 如果先获取锁,在这时这多个线程一定是串行获取后面的信号量的;而如果先获取信号量,信号量的获取难度小,多个线程可以获取信号量的时间会小一些,可以并行获取信号量之后,再串行获取锁;由此可见先获取信号量在获取锁的方式更优;

3.线程池
3.1池化技术
池化技术,是一种用空间换时间的技术,可以直接申请一大批空间,需要使用时直接使用即可,不需要向系统申请,减少了与系统的交互,提高了效率;
3.2线程池的实现
我们之前的代码中写过进程池,现在我们再来写一份关于线程池的代码,其实线程池和前面的cp模型也没有什么大的区别,线程池顾名思义,就是有很多的线程提供,在任务很多的时候,多个线程共同分担任务;那么我们可以把线程池中的线程看作消费者用来任务,主线程生产任务给这些线程;那这就一个单生产多消费的cp模型;
封装一个线程池的类:
#define THREADNUM 5
template <class T>
class threadPool
{
public:
private:
static void *routine(void *args)
{
threadPool<T> *pool = static_cast<threadPool<T> *>(args);
T task;
while (1)
{
pool->pop();
}
}
public:
threadPool(int num = THREADNUM)
{
pthread_mutex_init(&_mutex, nullptr);
pthread_cond_init(&_cond, nullptr);
_info.resize(THREADNUM);
}
void start()
{
for (int i = 0; i < THREADNUM; i++)
{
pthread_create(&(_info[i]._tid), nullptr, routine, (void *)this);
_info[i]._threadName = "thread" + to_string(i);
}
}
void finish()
{
void *ret;
for (auto tinfo : _info)
{
pthread_join(tinfo._tid, &ret);
}
}
void push(const T &task) // 这里生产任务只需要一直生产即可,不需要访问控制
{
pthread_mutex_lock(&_mutex);
_task.push(task);
pthread_cond_signal(&_cond);
pthread_mutex_unlock(&_mutex);
}
void pop()
{
pthread_mutex_lock(&_mutex);
while (_task.empty())
{
pthread_cond_wait(&_cond, &_mutex);
}
T top = _task.front();
_task.pop();
top();
top.getAnswer(getThreadName(pthread_self()));
pthread_mutex_unlock(&_mutex);
}
string getThreadName(pthread_t tid)
{
for (auto info : _info)
{
if (info._tid == tid)
return info._threadName;
}
return "no thred";
}
int tasknum()
{
return _task.size();
}
private:
struct threadInfo
{
string _threadName;
pthread_t _tid;
};
pthread_mutex_t _mutex;
pthread_cond_t _cond;
queue<T> _task;
vector<threadInfo> _info;
};这个线程池的类可以直接帮助我们生成线程池;
下面是这个模型的代码链接:
thread2024.5.14/5_threadPool · future/Linux - 码云 - 开源中国 (gitee.com)

现象:

还是老样子,想分析代码进入我的链接去询问gpt即可,我这里讲解我认为的重点:
类中的routine函数需注意的地方
1.由于routine函数是在threadPool类中的,类中的函数,第一个参数为隐藏的this指针,所以会导致与pthread_create的参数不匹配,所以需要将此函数声明为static类型,不让this指针影响函数;

2.由于routine函数没有了this指针,所以要将this指针作为参数传递给routine函数

4.线程封装
在C++中有一个thread类,这个封装了线程的各种参数,只需要调用其接口,thread类就可以自动帮我们实现创建线程等功能;我们现在也试着封装一下linux下的posix接口,让我们创建的thread类可以自动帮我们创建,销毁...线程;
typedef void* (*callback)(void *);
class thread
{
public:
thread()
: _threadname(""), _isrunning(false)
{
}
thread(callback threadfun, void *args)
: _threadfun(threadfun), _args(args), _isrunning(false)
{
pthread_create(&_tid, nullptr, _threadfun, _args);
_isrunning = true;
}
void join()
{
void *ret;
pthread_join(_tid, &ret);
}
bool isrunning()
{
return _isrunning;
}
pthread_t gettid()
{
return _tid;
}
private:
void *_args;
string _threadname;
bool _isrunning;
pthread_t _tid;
callback _threadfun;
};我们使用下面的代码测试:
void *routine(void*args)
{
cout<<"i am a thread"<<endl;
}
int main()
{
void *args;
thread t(routine,&args);
sleep(1);
cout<<"thread tid: "<<t.gettid()<<endl;
cout<<"thread is fun? "<<t.isrunning()<<endl;
t.join();
return 0;
}获得现象:

成功的封装了线程,并可以调用其中的接口;
5.单例模式
单例模式是一个设计模式,目的是为了节约空间,提高效率,就比如我们上面的线程池代码,我们只需要一个线程池,发布任务都只需要发布到这一个线程池中即可;所以线程池类只需要示例化出这一个线程池对象,这就是单例模式;一个类只允许实例化出一个对象;
5.1.懒汉饿汉方式
懒汉方式:
不要紧的事情先不做,等到需要做的时候再做;
饿汉方式:
所有事情都提前做好,等到需要的时候可以直接使用;
在我们的程序启动之时,大量的空间申请开辟会减慢进程的启动速度,我们可以使用懒汉的方式让空间先不申请,等需要此空间时再申请,这就是懒汉方式的应用场景
而在程序启动时,我们的全局变量,与类中的静态变量都会直接创建出来,我们即使不实例化我们的类对象,类中的静态变量依然会直接创建出来,即使不直接使用也会被创建,这就饿汉模式;
5.2用懒汉与饿汉方式实现单例:
//饿汉方式实现单例
class hangry
{
private:
static int _data;
public:
static int *getData()
{
return &_data;
}
};
//懒汉方式实现单例
class lazy
{
private:
int _data;
static lazy* _plazy;
public:
static lazy* getData()
{
if(_plazy==nullptr)
{
_plazy= new lazy();
}
return _plazy;
}
} ;
lazy* lazy::_plazy=nullptr;
5.3用懒汉单例模式与线程封装实现的线程池代码:
thread2024.5.14/7_threadpoolSingalCase · future/Linux - 码云 - 开源中国 (gitee.com)
需要注意的地方:
单例模式多线程访问,需要进行保护


用锁锁住单例创建,保证线程安全;
6.自旋锁
这个锁的使用与否和正在临界区使用临界资源的线程有关;当多个线程竞争一把锁,一个线程抢到了锁,这个抢到了锁的线程,占有锁的时间长短(临界区代码的长短);会决定这把锁是否会是自旋锁;当占有锁线程临界区代码长度很短(临界区使用时间短)时,其他的线程会一直等待,不会去做其他事情,在while循环中不断申请锁,直到拥有锁线程释放锁;
6.1自旋锁函数
初始化锁函数

申请锁函数

释放锁函数

我们可以把这个释放锁的函数看作这样的函数:

协助记忆:张三找李四上课的例子
7.读者写者模型
这个模型其实和前面的cp模型是相似的,但是不同的地方在于,cp模型的生产者和消费者都需要,对临界资源进行修改,而读者写者模型中只有写者会修改临界资源,所以我们只需要解决写者和读者之间的互斥同步问题;
由于读者的数量一定是远大于写者的,所以必定会面临着写者存在饥饿的问题,所以为了解决这样的问题,库中是提供了设置读者和写者优先情况的
设置读者或写者优先
pthread_rwlockattr_setkind_np 是一个非标准扩展函数,因此在标准的 man 手册中可能找不到它;
这个函数可以设置读者写者谁优先,减少写者的饥饿问题;
初始化和销毁函数

加锁


读写锁是有读锁和写锁之分的;但是解锁都是相同的接口:
解锁

读者写者模型的原理:
写者在写时读者不能访问临界资源,读者在读时写者不能访问临界资源,但读者之间可以并发访问资源,写者和写者之间只能互斥访问;