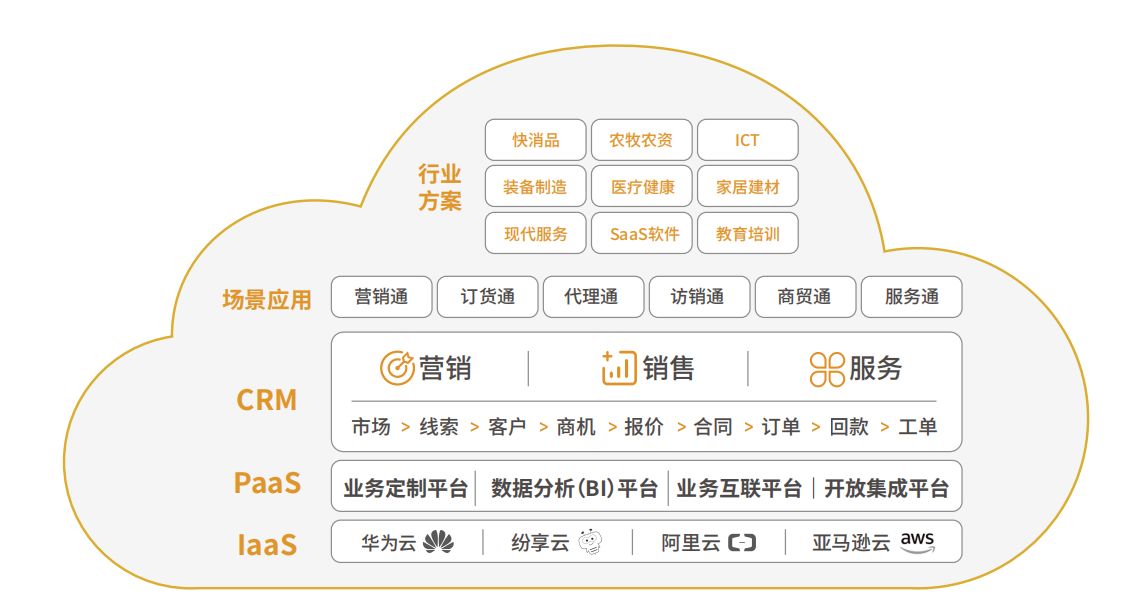
服务器环境以及配置
【机型】虚机
| 处理器: | Kunpeng-920 |
| 内存: | 40G |
【内核版本】
4.19.90-23.8.v2101.ky10.aarch64
【OS镜像版本】
银河麒麟操作系统 Kylin-Server-10-SP1-Release-Build20-20210518-arm64
【第三方软件】
智能运维系统、mysql数据集群
现象描述
环境描述:Cas虚拟化平台,三台运行智能运维系统和mysql数据库集群的,银河麒麟虚拟机跑在一台物理机上。
故障现象:反馈智能运维系统登录页面提示500。初步排查,发现虚机B系统日志显示在系统出现软中断,并持续15分钟时间。虚机C系统日志也有软中断报错,虚机A系统日志无21号日志,因此无法判断是否有软中断报错,影响智能运维系统服务中断。
现象分析
分析B虚机系统messages日志,可以看到,xxx开始输出“watchdog: BUG: soft lockup - CPU#29 stuck”软中断相关堆栈日志信息,持续到xxx停止输出,日志信息输出时间在15分钟左右。查看Call trace相关堆栈信息,主要集中在,调用smp_call_function_many+0x348/0x3a0这个函数过程中产生,如图1:

图1
分析C虚机系统messages日志,也有相关软中断堆栈信息输出,日志信息输出时间在5分钟左右。查看Call trace相关堆栈信息,同样集中在,调用smp_call_function_many+0x348/0x3a0这个函数过程中产生,如图2:

图2
进一步分析,smp_call_function_many这个call trace堆栈函数的功能和产生的原因。可知,它的功能是在多个CPU上执行一个函数,smp_call_function_many函数发生soft lockup的原因是CPU在一段时间内没有响应中断,可能是由于CPU卡住或者CPU负载过高导致的。
分别分析查看,故障时间段,虚拟机B和C,系统sar性能日志,可知,内存使用率不高,性能瓶颈,不在内存使用,如图3和图4:

图3 虚拟机B内存使用率

图4 虚拟机C内存使用率
分析CPU使用情况和系统负载,可知,故障时间段内,CPU使用率比较高,%system和%iowait占用高,说明CPU处理内核态执行进程时间较长,CPU用于等待I/O操作时间较长,硬盘存在IO性能瓶颈。系统负载也高。如图5-图8:

图5 虚拟机B CPU使用率

图6 虚拟机C CPU使用率

图7 虚拟机B 系统负载

图8 虚拟机C 系统负载
分析系统磁盘IO使用情况,可知,故障时间段内,dev8-0系统磁盘、dev8-16和dev8-32应用磁盘的await,每次IO请求消耗时间大,有异常。%util ,I/O请求占用的CPU百分高,IO处理慢。说明磁盘IO存在比较严重性能问题,会影响系统正常IO读写,如图9和图10:

图 9 虚拟机B 磁盘IO

图10 虚拟机C 磁盘IO
分析结果
综上,系统日志和系统性能分析情况,可见,系统产生软中断,是因为故障时间段内,系统负载高,导致CPU没有正常响应中断请求。系统软中断,不是导致智能运维系统中断的原因。从sar性能日志,分析的情况,可知,CPU使用率较高,系统负载高,iowait较高,%util和await较高,这些性能相关指标,分析下来基本都指向磁盘IO性能出现问题。
结合智能运维系统厂商的问题分析情况,出故障时间段虚拟机A/B/C三台机器均出现网络连通性问题。怀疑,故障时间段内,虚机系统的状态,有暂停或卡死的可能性。
后续计划与建议
因麒麟系统是运行在Cas虚拟化平台上的虚机,建议虚拟化平台侧,排查虚拟化平台相关日志,分析运行虚机的宿主机日志。进一步分析,故障原因。