可变参数模板
在C++11中模板也可以接收多个不定参数,就和int printf(const char *format, ...);函数一般模板也可以接收多个参数;
// 可变参数模板
template<class ...Args>
void testArgs(Args... args)
{
}
int main()
{
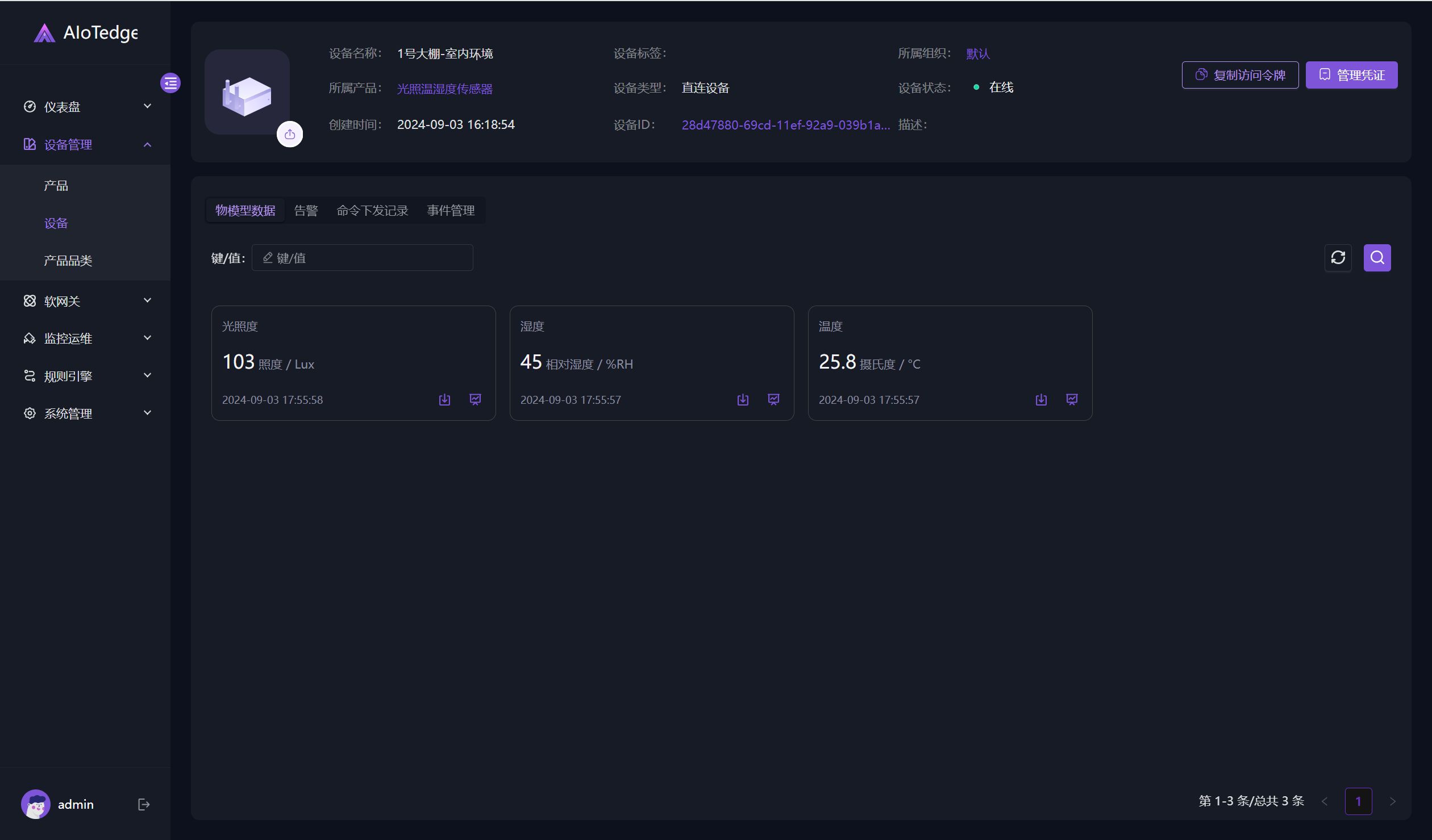
testArgs(123, 'a', "abc", string("yes"), vector<int>(12));
return 0;
}看上面的testArgs函数接收了多个不同类型的参数(可变参数包),由于模板的参数包将这些类型打包,从而使得函数可以接收多个,且不确定的参数类型;模板定义了可变参数包类型,函数接收可变参数包类型的参数;
展开可变参数包
递归展开:
// 可变参数模板
template<class T>
void getArgs(const T& val)
{
cout << val << endl;
}
template<class T,class... Args>
void getArgs(const T& val,Args... args)
{
cout << val << " ";
getArgs(args...);
}
template<class ...Args>
void testArgs(Args... args)
{
getArgs(args...);
}
int main()
{
testArgs(123, 'a', "abc", string("yes"));
return 0;
}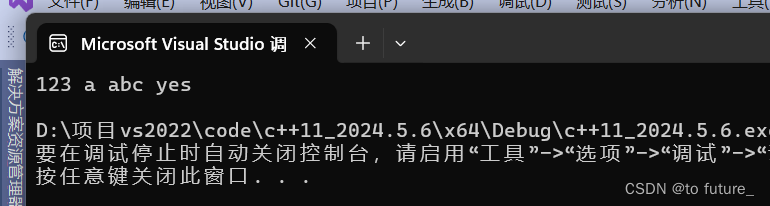
其实这种方式就是利用了参数包的特性,会将模板参数中除去显示接收的参数剩余的参数打包成为参数包;

利用数组展开:
//利用数组展开
template<class T>
int getArg(const T& val)
{
cout << val << " ";
return 0;
}
template<class ...Args>
void testArgs(Args... args)
{
int arr[] = { getArg(args)... };
}
int main()
{
testArgs(123, 'a', "abc", string("yes"));
return 0;
}
我们通过初始化arr这个变长数组,从而会不断调用getArg函数使得包中的参数一个个被传递,将getArg函数的返回值展开成为逗号表达式的序列,直到包为空时,停止初始化,包也被解析完毕;
emplace接口
在stl容器中我们要是细心看的话,就可以找到emplace接口;

看基本上所有的容器都支持了这个emplace接口,那么这个emplace接口到底做了什么呢?
emplace其实和我们容器前面学的insert,push_back,push这样的接口是一样的,都是用来向容器插入数据的,但是呢,emplace的插入有所不同,它是通过直接构造节点然后再插入容器中的;而我们之前所学的插入都是通过深拷贝或者移动构造拷贝出一份节点来进行构造的;
// emplace接口
class A {
public:
A(int a = 1)
: _a(a)
{
cout << "A(int a = 1)构造函数" << endl;
}
A(const A& it)
:_a(it._a)
{
cout << "A(const A& it)拷贝构造" << endl;
}
A(A&& it)
:_a(it._a)
{
cout << "A(A&& it)移动构造" << endl;
}
private:
int _a;
};
int main()
{
A a(10);
system("cls");
vector<A> v;
vector<A> v1;
vector<A> v2;
vector<A> v3;
cout << "emplace: " << endl;
v.emplace_back(a);
cout << "emplace: " << endl;
v1.emplace_back(10);
cout << "---------------------" << endl;
cout << "push_back: " << endl;
v2.push_back(a);
cout << "push_back: " << endl;
v3.push_back(10);
return 0;
}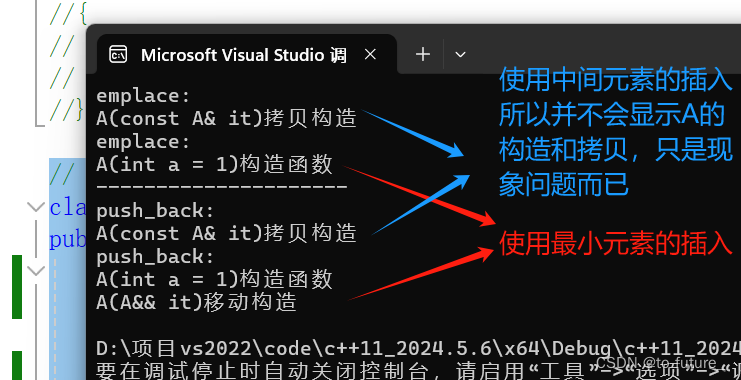
其实也并没有很大的优化;
lambda表达式
lambda产生原因
在C语言时我们传递函数需要使用函数指针来传递,到了c++98的时候,我们增加了一种方式仿函数,仿函数的传递使得我们的代码更加清晰明了,但仿函数毕竟也是定义在外部的函数,我们没法直接看到函数内部的实现,从而无法清楚直到函数功能,并且随着代码量的增加,仿函数也会随着增加,使得命名冲突也会出现;
如:不同类的仿函数比较,会导致增加很多不同的仿函数类,这些类的命名会困扰程序员(其实我觉得还好,也有可能是我接触的项目代码量太少了);
为了可以清楚的直到函数功能还可以将函数传递,lambda表达式就起到了它的作用;我们可以在传递函数参数的时候直接传递lambda表达式,使得代码功能十分清晰;
也就是说lambda是一种增加啊代码易读性的方式;
lambda使用
我们先使用一下lambda方法再来讲解:
// lambda
struct student {
student(string name,int age,int score)
:_name(name)
,_age(age)
,_score(score)
{}
string _name;
int _age;
int _score;
};
int main()
{
vector<student> v{ {"张三", 18, 96 }, {"李四", 17, 95}, {"王五", 20, 99} };
sort(v.begin(), v.end(), [](student& s1, student& s2)->bool {return s1._age > s2._age; });
int tmp = 1;
return 0;
}
lambda语法
[](student& s1, student& s2)->bool {return s1._age > s2._age; }
1.[]捕捉列表可以用来捕获当前所处作用域的内容
int main()
{
int a = 10, b = 20;
cout << "a: " << a << " b: " << b << endl;
//[a, b]()->void {//这样会报错,因为a,b为const类型,如果想要能修改的话,要加上mutable才能修改
// int tem = a;
// a = b;
// b = tem;
// }();
[a, b]()mutable->void {//这样就可以修改了
int tem = a;
a = b;
b = tem;
}();//记住了要加上()代表执行这个匿名对象的operator()函数
[=]()mutable->void {
int tem = a;
a = b;
b = tem;
}();
[&a, &b]()->void {
int tem = a;
a = b;
b = tem;
}();
[&]()->void {
int tem = a;
a = b;
b = tem;
}();
//[&, a]()->void {//这样是错误的因为a单独被列出,是拷贝的const变量
// b = 10;
// a = 100;
//}
[=,&a]()mutable->void {//只有a是引用其他为拷贝
a = 100;//成功修改
b = 200;//修改失败
}();
cout << "a: " << a << " b: " << b << endl;
return 0;
}[]中为变量名时例如a,b,代表获得了当前作用域中的a,b的拷贝,并且此拷贝是const类型的,不能修改的;
如果需要修改的话要再参数列表()后加上mutable修饰符,且()不能省略;
[]中为=代表获得当前作用域中所有的变量拷贝;
[]中为&加变量名时例如&a,&b,代表获得了当前作用域中的a,b的引用
[]中为&时,代表获得当前作用域中,所有变量的引用;
[]中&与变量名混合出现时,代表此变量为拷贝,其他所有变量为引用
[]中=与变量名混合出现时,代表此变量为引用,其他所有变量为拷贝
2.参数列表
这个包含的是我们传递给lambda方法的参数,lambda可以通过其内部参数才进行操作;其实就是和函数的参数是一个性质;此参数列表可以省略;
// 参数列表
int main()
{
auto D = [](int a, int b)->int {return a + b; };
int a = 10, b = 20;
cout << D(a, b);
return 0;
}3.返回值与{}函数体
返回值通过
->(某类型)
这样标识,标识返回一个(某类型的数据),也可以省略;
{}里面包含的是lambda方法的行为,就和函数的函数内容是一样的没有任何区别;
lambda底层
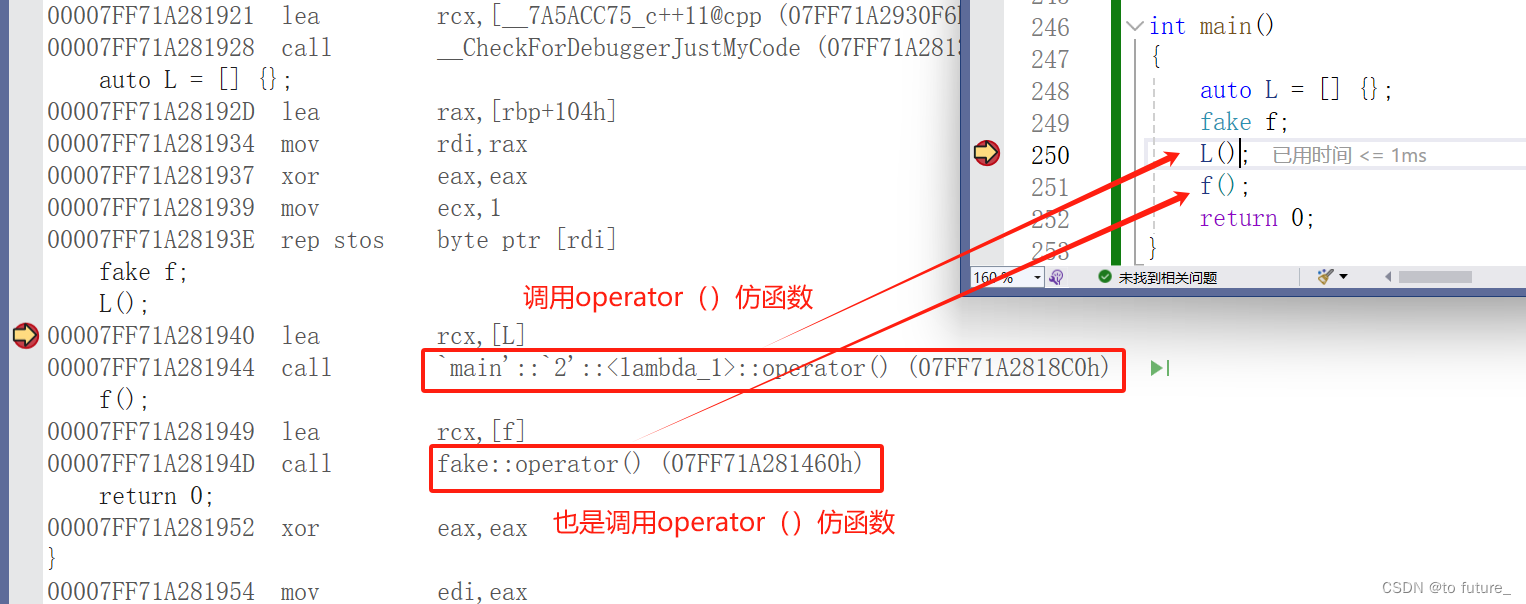
1.lambda其实在底层编译时,它被编译成了仿函数类,而我们之所以不需要显示的创建类是因为,编译器将这个类自动生成了匿名对象;
2.编译器为了区分lambda方法会自动给这个匿名对象取一个随机的名字,为了区分产生的lambda类对象这些名字不会重复;
// 证明lambda方法其实是仿函数
struct fake
{
void operator()()
{}
};
int main()
{
auto L = [] {};
fake f;
L();
f();
return 0;
}
包装器
在我们前面的编程中,对于函数,仿函数,lambda,这三种函数虽然各有千秋,但作用非常相似,那么我们有没有什么办法可以将它们三者用相同的办法整合起来呢。今天包装器它来了,我们的函数指针与lambda的类型非常复杂,而仿函数又过于笨重;使用包装器,可以将它们三者用相同的方法进行调用;下面让我们看看实现的现象吧:
包装器的使用;
function<函数返回值类型(函数参数1,函数参数2,......)> f=函数指针等类型;
// 包装器
#include<functional>
void FunPointerAdd(int a, int b)
{
cout << a + b << endl;
}
struct StructAdd {
void operator()(int a, int b)
{
cout << a + b << endl;
}
};
int main()
{
int a = 5, b = 10;
//虽然这里用auto可以直接获取lambda类型,但是我们无法显式的获取
//当然,使用前面的decltype也是可以推出类型
auto LambdaAdd = [](int a, int b)->void {cout << a + b << endl; };
map<string, function<void(int a, int b)>> m = { {"函数指针",FunPointerAdd},{"仿函数",StructAdd()} ,{"lambda",LambdaAdd}};
m["函数指针"](a,b);
m["仿函数"](a, b);
m["lambda"](a, b);
}现象:

我们可以看到,我们的三种函数都被包装器接收了,所以它们可以有同样的使用方式,一种方式使用三种不同的函数;
function的底层是仿函数
我们通过上面现象,我们可以发现function这个类在使用的时候,是和函数一样的:
void FunPointerAdd(int a, int b)
{
cout << a + b << endl;
}
int main()
{
int a = 5, b = 10;
function<void(int a, int b)> f = FunPointerAdd;
f(a,b);
}现象:

上面的现象中f本身是一个类,但是却使用了f(a,b)函数的形式调用了包装的函数,所以说其实,包装器的底层其实也是封装了仿函数来包装我们所需要的函数的;
逆波兰表达式包装器解法
150. 逆波兰表达式求值 - 力扣(LeetCode)
class Solution {
public:
int evalRPN(vector<string>& tokens) {
stack<int>num;
map<string,function<int(int,int)>> m=
{
{"+",[](int a,int b)->int{return a+b;}},
{"-",[](int a,int b)->int{return a-b;}},
{"*",[](int a,int b)->int{return a*b;}},
{"/",[](int a,int b)->int{return a/b;}}
};
for(int i=0;i<tokens.size();i++)
{
if(m.count(tokens[i]))
{
int right=num.top();
num.pop();
int left=num.top();
num.pop();
num.push(m[tokens[i]](left,right));
}
else
{
num.push(stoi(tokens[i]));
}
}
return num.top();
}
};我们利用包装器的办法,使得函数的调用变得更加清晰明了;
包装器包装类成员函数
当包装器包装的函数指针是成员函数时会有一些需要注意的地方:
// 包装器包装类成员函数
struct A {
void a()
{
cout << "我是成员函数" << endl;
}
};
int main()
{
A b;
function<void(A*)> f = &A::a;//由于a是成员函数,这里编译器有特殊处理需要带上&在类前面
f(&b);
function<void(A)> f1 = &A::a;//这样使用也可以,这又是一种特殊处理,可以直接转递类,和传递this指针是同样的效果
f1(b);
}1.包装器在包装A类中的成员函数a时会取地址+类名作为类域符:

这是编译器的一个特殊处理;
2.包装器包装成员变量时,参数需要将成员函数隐藏的this指针参数带上:

我们这里给f的参数this指针不能是匿名对象的地址,因为匿名对象是右值,无法取地址
也可以直接传递类,和传递this指针是同样的效果:

绑定函数bine
使用方法:
bine(函数名,palcholders::_1,palcholders::_2,......);
_1,_2代表着函数的第几个参数;_1,_2是封装在palcholders中的类型
绑定函数可以用来调整函数参数的顺序,和写死函数的某个参数;
1.调整函数参数顺序
// 绑定函数bind
void print(char a,char b)
{
cout << "a: " << a << endl;
cout << "b: " << b << endl;
}
int main()
{
char a = 'a', b = 'b';
//我们使用bind交换了函数print的参数位置
function<void(char, char)> f = bind(print, placeholders::_2, placeholders::_1);
f(a, b);
}现象:

2.写死函数参数,修改函数参数个数:


由此可见写死的顺序为,你要写死哪个参数就将第几个位置上写入你的值,其他剩余的参数按照1234...的顺序排序;