六 块管理器
6.1 块管理方法在调度系统中的应用
在第二篇文章对调度系统的分析中,我们可以看到调度系统中普遍都使用了块管理方法:
- _schedule_prefills
...
# 比较当前seq需要的物理块,gpu可用物理块之间的数量关系. 决定是否能给当前seq_group分配物理块
# can_allocate返回值可能有三种: NEVER:不分配;OK:可以分配;LATER:延迟分配
can_allocate = self.block_manager.can_allocate(seq_group)
...
# 为当前seq_group分配物理块,并将该seq_group中每条seq的status从waiting改为running
self._allocate_and_set_running(seq_group)
- _schedule_running
# 对于这个seq_group,检查对于其中的每一个seq,是否能至少分配一个物理块给它
...
while not self._can_append_slots(seq_group)
...
# 为当前seq_group分配gpu 物理blocks. 这里只分配了逻辑blocks与物理blocks的映射关系
# blocks_to_copy:[旧物理块id, copy - on - write而来的新物理块id]
self._append_slots(seq_group, blocks_to_copy)
- _schedule_swapped
...
# 根据需要的,与可用的物理blocks数量判断,是否可以把当前seq_group从swap队列转移到running队列
alloc_status = self.block_manager.can_swap_in(seq_group, self._get_num_lookahead_slots(is_prefill))
...
# 再把CPU上的blocks转移到GPU block上
self._swap_in(seq_group, blocks_to_swap_in)
...
以上对物理块的操作由BlockSpaceManager(v1或v2) 块管理器类完成,接下来我们看下这个类与调度系统的关系。
块管理器类是在调度类Scheduler中初始化的,Scheduler管理所有的推理请求,是个全局变量,因此块管理器也是一个
全局变量,管控过程中所有seq_group的需求block与物理block的映射情况。
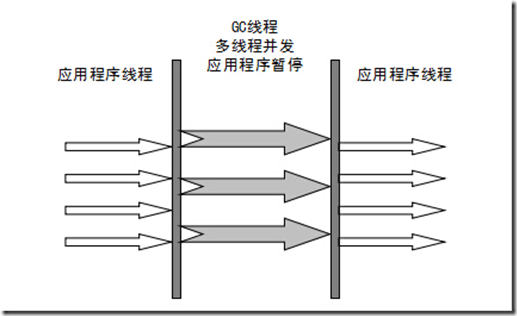
从下图可以看到它们之间从属关系:

class Scheduler:
def __init__(
self,
scheduler_config: SchedulerConfig,
cache_config: CacheConfig,
lora_config: Optional[LoRAConfig],
pipeline_parallel_size: int = 1,
) -> None:
...
version = "v1"
if self.scheduler_config.use_v2_block_manager:
version = "v2"
if self.scheduler_config.embedding_mode:
version = "embedding"
BlockSpaceManagerImpl = BlockSpaceManager.get_block_space_manager_class(version)
...
# Create the block space manager.
self.block_manager = BlockSpaceManagerImpl(
block_size=self.cache_config.block_size,
num_gpu_blocks=num_gpu_blocks,
num_cpu_blocks=num_cpu_blocks,
sliding_window=self.cache_config.sliding_window,
enable_caching=self.cache_config.enable_prefix_caching)
...
def _can_append_slots(self, seq_group: SequenceGroup) -> bool:
"""Determine whether or not we have enough space in the KV cache to
continue generation of the sequence group.
"""
...
# Appending slots only occurs in decoding.
is_prefill = False
return self.block_manager.can_append_slots(
seq_group=seq_group,
num_lookahead_slots=self._get_num_lookahead_slots(is_prefill),
)
6.2 块管理器的定义
目前为止,我们提到了很多次物理块的概念,到底什么是块呢?
首先来看下物理块block (在块管理器BlockSpaceManager中使用) 长什么样:
- vllm/block.py
class PhysicalTokenBlock:
"""Represents the state of a block in the KV cache."""
def __init__(
self,
device: Device,
block_number: int,
block_size: int,
block_hash: int,
num_hashed_tokens: int,
) -> None:
self.device = device
# 该物理块在对应设备上的全局block索引号
self.block_number = block_number
# 每个block槽位数量(默认16)
self.block_size = block_size
# 在prefix caching场景下使用,其他场景值为-1
self.block_hash = block_hash
# 该物理块的hash值是由多少个前置token计算而来的,非prefix caching场景值为0
self.num_hashed_tokens = num_hashed_tokens
# 该物理块被引用次数
self.ref_count = 0
# 物理块最后一个被访问时间,非prefix caching场景值为-1
self.last_accessed = DEFAULT_LAST_ACCESSED_TIME
# 该物理块是否被计算过,只在prefix caching场景下启用
self.computed = False
def __repr__(self) -> str:
return (f'PhysicalTokenBlock(device={self.device}, '
f'block_number={self.block_number}, '
f'num_hashed_tokens={self.num_hashed_tokens}, '
f'ref_count={self.ref_count}, '
f'last_accessed={self.last_accessed}, '
f'computed={self.computed})')
# Mapping: logical block number -> physical block.
BlockTable = List[PhysicalTokenBlock]
从类定义可以看出,调度系统的物理块并不执行存储kv值的操作,它的用途是记录物理block的状态,
我们不生产kv-cache,只是kv-cache的搬运工~ (如swapp操作中,kv-cache从GPU向CPU转移)
真实的物理块是gpu/cpu上的物理内存,真实存在,也实际存储着token的kv-cache,但调度系统和块管理器中使用的是这些真实物理块的编号、状态等信息。就像战时指挥部(Scheduler)会指挥军队(blocks)具体的行动细节,但指挥部却不会亲自上战场
如self.block_number记录了真实存储kv-cache的block的索引号。
BlockTable 则记录着多个物理块编号的列表(记录着seq_group中每条seq的具体tokens存储在哪些物理块上)。
块管理器的作用是物理块结构,逻辑块-物理块映射,物理块新增与释放等操作,vllm现有2个版本的块管理器,目前系统默认使用的是v1,接下来我们也以v1版来讲解
class BlockSpaceManagerV1(BlockSpaceManager):
"""Manages the mapping between logical and physical token blocks."""
def __init__(
self,
block_size: int,
num_gpu_blocks: int,
num_cpu_blocks: int,
watermark: float = 0.01,
sliding_window: Optional[int] = None,
enable_caching: bool = False,
) -> None:
self.block_size = block_size
self.num_total_gpu_blocks = num_gpu_blocks
self.num_total_cpu_blocks = num_cpu_blocks
...
self.watermark = watermark
assert watermark >= 0.0
self.enable_caching = enable_caching
# 水位线,是一个数量阈值,设置它的目的是避免gpu上物理块全部使用完。
self.watermark_blocks = int(watermark * num_gpu_blocks)
# 根据是否做了prefix caching限制,来选择不同的allocator
if self.enable_caching:
logger.info("Automatic prefix caching is enabled.")
self.gpu_allocator: BlockAllocatorBase = CachedBlockAllocator(
Device.GPU, block_size, num_gpu_blocks)
self.cpu_allocator: BlockAllocatorBase = CachedBlockAllocator(
Device.CPU, block_size, num_cpu_blocks)
else:
self.gpu_allocator = UncachedBlockAllocator(
Device.GPU, block_size, num_gpu_blocks)
self.cpu_allocator = UncachedBlockAllocator(
Device.CPU, block_size, num_cpu_blocks)
# Mapping: seq_id -> BlockTable.
# 记录每个seq对应的BlockTable(这是一个包含物理块索引号的list)
self.block_tables: Dict[int, BlockTable] = {}
# Mapping: req_id -> BlockTable. Note that each SequenceGroup has a unique equest ID
# 功能同上,但cross_block_tables记录的是encoder-decode类型的模型,暂时混略
self.cross_block_tables: Dict[str, BlockTable] = {}
从以上初始化代码可以看出:
BlockManager这个class下维护着两个重要属性:
-
BlockAllocator:物理块分配者,负责实际为seq做物理块的分配、释放、拷贝等操作。我们推理时使用gpu_allocator,和 cpu_allocator用于gpu资源不足时临时存储kv-cache,对应的swapped队列。
其中,BlockAllocator又分成两种类型:
CachedBlockAllocator:按照prefix caching的思想(prompt共享)来分配和管理物理块。带有这些相同prefix信息(如"提示词 你是一个助手")的prompt完全可以共享用于存放prefix的物理块,这样既节省显存,也不用再对prefix做推理。
UncachedBlockAllocator:正常分配和管理物理块,没有额外实现prefix caching的功能。 -
block_tables:负责维护每个seq下的物理块列表,本质上它是一个字典,因为调度器是全局的,所以它下面的的BlockManager自然也是全局的。因为seq_id也是全局唯一,所以这个字典维护着调度系统中所有待推理的seq(即使它们在不同的seq_group中)的物理块。
经过层层转包后,我们发现最终干活的是gpu_allocator。让我们接着看下allocator长什么样,下面代码比较简单,大家看注释就能明白了
class UncachedBlockAllocator(BlockAllocatorBase):
def __init__(
self,
device: Device,
block_size: int,
num_blocks: int,
) -> None:
self.device = device
self.block_size = block_size
self.num_blocks = num_blocks
# Initialize the free blocks.
self.free_blocks: BlockTable = []
# 假设系统GPU可用显存能容纳256个block,那就在这里直接
# 初始化256个block,用时从free_blocks中取就好。
for i in range(num_blocks):
block = PhysicalTokenBlock(device=device,
block_number=i,
block_size=block_size,
block_hash=-1,
num_hashed_tokens=0)
self.free_blocks.append(block)
def allocate(self,
block_hash: Optional[int] = None,
num_hashed_tokens: int = 0) -> PhysicalTokenBlock:
"""分配block: 从自由态block列表中取出一个block,并将引用计数设为1"""
if not self.free_blocks:
raise ValueError("Out of memory! No free blocks are available.")
block = self.free_blocks.pop()
block.ref_count = 1
return block
def free(self, block: PhysicalTokenBlock) -> None:
"""释放block,引用计数置为0"""
if block.ref_count == 0:
raise ValueError(f"Double free! {block} is already freed.")
block.ref_count -= 1
if block.ref_count == 0:
self.free_blocks.append(block)
def get_num_free_blocks(self) -> int:
"""获得当前gpu上可用block数量"""
return len(self.free_blocks)
def get_num_total_blocks(self) -> int:
"""获得当前gpu所有block总数"""
return self.num_blocks
...
6.3 块管理器方法解析
调度系统中所有与块相关的方法都来自BlockSpaceManagerV1类,下面我们解析下这个类的一些重要方法
- vllm_module/core/block_manager_v1.py:class BlockSpaceManagerV1
6.31 can_allocate
- 是否可为seq_group分配足够物理块用于prefill(_schedule_prefills中有使用)
以下代码中,_num_required_blocks是当前seq_group需要的block数量,完全替代了logical table的作用
def can_allocate(self, seq_group: SequenceGroup) -> AllocStatus:
# FIXME(woosuk): Here we assume that all sequences in the group share
# the same prompt. This may not be true for preempted sequences.
# 只对encoder-decode模型有效,忽略
check_no_caching_or_swa_for_blockmgr_encdec(self, seq_group)
# 计算当前seq序列需要的物理block数量
# 这是seq的一个属性,对于waiting状态的seq,n_blocks=len(prompt)/16, 向上取整
self_num_required_blocks = self._get_seq_num_required_blocks(
seq_group.get_seqs(status=SequenceStatus.WAITING)[0])
# 又是encoder-decode相关,忽略
cross_num_required_blocks = self._get_seq_num_required_blocks(seq_group.get_encoder_seq())
num_required_blocks = self_num_required_blocks + cross_num_required_blocks
滑窗,忽略
if self.block_sliding_window is not None:
num_required_blocks = min(num_required_blocks, self.block_sliding_window)
# 当前gpu空闲的blocks数量
num_free_gpu_blocks = self.gpu_allocator.get_num_free_blocks()
# Use watermark to avoid frequent cache eviction.
# 如果设备中所有的物理块数量 - 该seq实际需要的物理块数量 < 水位线block数量,则不分配
# 说明当前seq太长了,标记为NEVER,以后也不处理这个seq_group了
if self.num_total_gpu_blocks - num_required_blocks < self.watermark_blocks:
return AllocStatus.NEVER
# 如果设备中可用的物理块数量 - 该seq实际需要的block数量 >= 水位线block数量,则分配
if num_free_gpu_blocks - num_required_blocks >= self.watermark_blocks:
return AllocStatus.OK
# 否则,现在不能分配(暂时没足够的blocks),但可以延迟分配
else:
return AllocStatus.LATER
6.32 allocate
- 为当前seq_group分配物理块用于prefill(_schedule_prefills中有使用)
def allocate(self, seq_group: SequenceGroup) -> None:
is_encoder_decoder = seq_group.is_encoder_decoder()
# 只对encoder-decode模型有效,忽略
check_no_caching_or_swa_for_blockmgr_encdec(self, seq_group)
# Allocate decoder sequences
#
# NOTE: Here we assume that all sequences in the group have the same
# decoder prompt.
# 对于WAITING装的seq_group,seq只有1条,就是prompt
seq = seq_group.get_seqs(status=SequenceStatus.WAITING)[0]
# block_table:list,存储的是当前seq用到的物理块的索引号
block_table: BlockTable = self._allocate_sequence(seq,
seq_group.num_seqs(),
is_encoder_decoder)
# Assign the self-attention block tables for each sequence.
# 记录每一个seq序列使用的block_table,block_tables是一个全局变量,记录这所有
# seq_group的seq,根据add_request()中代码可知,不同seq_group的seq.id也不会重复,没有相互覆盖的风险
for seq in seq_group.get_seqs(status=SequenceStatus.WAITING):
self.block_tables[seq.seq_id] = block_table.copy()
# Allocate encoder sequence
# 忽略
if is_encoder_decoder:
# A SequenceGroup has only a single encoder sequence (at most),
# thus allocate with a ref count of 1
block_table = self._allocate_sequence(seq_group.get_encoder_seq(),
1, is_encoder_decoder)
# Assign the cross-attention block table for the SequenceGroup.
self.cross_block_tables[seq_group.request_id] = block_table
6.33 _allocate_sequence
- allocate中分配物理的方法是:_allocate_sequence,从以下代码可以看出,vllm删除了logical block,取而代之的关系在这里呈现
。从空闲的物理blocks中取出 num_prompt_blocks 个block,映射给当前seq_group中的seq。
def _allocate_sequence(self, \
seq: Sequence, \
ref_count: int, \
is_encoder_decoder: bool = True) -> BlockTable:
# Allocate new physical token blocks that will store the prompt tokens.
# 当前seq需要的物理块数量
num_prompt_blocks = seq.n_blocks
block_table: BlockTable = []
for logical_idx in range(num_prompt_blocks):
# 滑窗,忽略
if (self.block_sliding_window is not None
and logical_idx >= self.block_sliding_window):
block = block_table[logical_idx % self.block_sliding_window]
# Set the reference counts of the token blocks.
block.ref_count = ref_count
elif not is_encoder_decoder and self.enable_caching:
block = self.gpu_allocator.allocate(
seq.hash_of_block(logical_idx),
seq.num_hashed_tokens_of_block(logical_idx))
# 默认情况下走下面的分支
else:
block = self.gpu_allocator.allocate()
# Set the reference counts of the token blocks.
# 由于seq_group下的所有seq共享一个prompt,所以有ref_count = num_seqs
# 表示这些seqs的逻辑块都引用它了
block.ref_count = ref_count
block_table.append(block)
return block_table
6.34 can_append_slots
- 是否可以为推理中的seq_group分配空间(在_schedule_running有使用)
def can_append_slots(self,
seq_group: SequenceGroup,
num_lookahead_slots: int = 0) -> bool:
assert (num_lookahead_slots == 0
), "lookahead allocation not supported in BlockSpaceManagerV1"
# Simple heuristic: If there is at least one free block
# for each sequence, we can append.
num_free_gpu_blocks = self.gpu_allocator.get_num_free_blocks()
num_seqs = seq_group.num_seqs(status=SequenceStatus.RUNNING)
return num_seqs <= num_free_gpu_blocks
细心的你一定发现了,在_schedule_prefills和_schedule_running两个调度方法各有一个判断是否可分配的空间的方法
,can_allocate和 can_append_slots,它们有什么区别呢?
我们来分析下这两个方法区别:
- 对处于waiting状态的seq_group,首先要给他分配block,做prefill,即prompt的token产生的kv-cache存放在block中。此时占用block数量根据prompt长度而定。假设prompt长度为20,block_size为16,则需要2个block。
- 对处于running状态的seq_group,处于解码状态,每个seq每次推理会产生1个tokens,有num_seqs个seq则会产生num_seqs个token,最好的情况是:每个seq对应的last block都没满,不需要新增block就能完成新kv-cache的存储,此时需要的blocks为0, 最坏的情况是:
每个seq last block都满了,再进来的token只能开辟新的block,此时需要的blocks数量为num_seqs,所有当可用blocks数量多于或等于num_seqs,当前seq_group就能继续做推理。
6.35 append_slots
- 为推理进行中的seq分配填充kv-cache的槽位(_schedule_running和_schedule_swapped都有用到)
def append_slots(
self,
seq: Sequence,
num_lookahead_slots: int = 0,
) -> List[Tuple[int, int]]:
"""Allocate a physical slot for a new token."""
n_blocks = seq.n_blocks
# 读取这个seq的物理块,List[PhysicalTokenBlock]
block_table = self.block_tables[seq.seq_id]
# If we need to allocate a new physical block
# 如果实际物理块数量 < seq需要的物理块数量(说明此时需要分配新的物理块了),为什么会出现这种情况?
# 因为上1个推理阶段完毕后,seq的需求的块数量更新了,但物理块数量还没更新
if len(block_table) < n_blocks:
# Currently this code only supports adding one physical block
# 需要声明物理块只允许比需求的块少1块
assert len(block_table) == n_blocks - 1
# 如果使用滑动窗口,忽略
if self.block_sliding_window and len(block_table) >= self.block_sliding_window:
# reuse a block
block_table.append(block_table[len(block_table) % self.block_sliding_window])
# 其余情况,直接分配一个新的物理块给当前序列
else:
# The sequence hash a new logical block.
# Allocate a new physical block.
new_block = self._allocate_last_physical_block(seq)
block_table.append(new_block)
return []
# We want to append the token to the last physical block.
# 取出最后一个物理块
last_block = block_table[-1]
# 断言该块必须是gpu物理块
assert last_block.device == Device.GPU
# 如果最后一个物理块的引用数量为1, 说明只有当前这个seq在用它
if last_block.ref_count == 1:
# Not shared with other sequences. Appendable.
# 是在做prefix caching,暂时忽略
if self.enable_caching:
# If the last block is now complete, we may reuse an old block
# to save memory.
maybe_new_block = self._maybe_promote_last_block(seq, last_block)
block_table[-1] = maybe_new_block
return []
# 如果最后一个物理块的引用数量为 > 1, 说明有别的seq在用它,不允许这样情况发生
# 因为两个seq生成的内容可能不同,同时向一个位置添加kv-cache会出现相互覆盖的情况
else:
# The last block is shared with other sequences.
# Copy on Write: Allocate a new block and copy the tokens.
# 触发copy-on-write机制,分配一个新的物理块
new_block = self._allocate_last_physical_block(seq)
# 用新分配的block替换之前分配的那个
block_table[-1] = new_block
# 把之前分配的block释放掉, 也即该物理块ref_count -= 1,
# 如果-=1后ref_count=0,说明该物理块变为自由状态;但当前语境下不可能为0,因为
# 正是因为last_block.ref_count>1才会走到这里,此时last_block.ref_count最小为1
self.gpu_allocator.free(last_block)
return [(last_block.block_number, new_block.block_number)]
6.36 swap_out
- 将gpu block转移到CPU上,释放gpu block,保证推理正常进行(在_schedule_running中使用)
在调度系统中对swap_out有多层调用,抽丝剥茧后发现实际工作的还是swap_out这个方法,这些调用代码不难,在_schedule_running中,有兴趣可以自己去看下,代码太多,这里不展示了。
def swap_out(self, seq_group: SequenceGroup) -> List[Tuple[int, int]]:
request_id = seq_group.request_id
# GPU block -> CPU block.
# dict is efficient in lookup `if gpu_block in mapping`
mapping: Dict[PhysicalTokenBlock, PhysicalTokenBlock] = {}
# 遍历当前seq_group中每条seq,gpu->cpu
for seq in seq_group.get_seqs(status=SequenceStatus.RUNNING):
self.block_tables[seq.seq_id] = \
self._swap_block_table(self.block_tables[seq.seq_id],
self.gpu_allocator,
self.cpu_allocator,
mapping)
# 忽略
if seq_group.is_encoder_decoder():
self.cross_block_tables[request_id] = \
self._swap_block_table(self.cross_block_tables[request_id],
self.gpu_allocator,
self.cpu_allocator,
mapping)
return [(cpu_block.block_number, gpu_block.block_number)
for cpu_block, gpu_block in mapping.items()]
def _swap_block_table(
self, block_table: BlockTable, src_allocator: BlockAllocatorBase,
dest_allocator: BlockAllocatorBase,
mapping: Dict[PhysicalTokenBlock,
PhysicalTokenBlock]) -> BlockTable:
new_block_table = []
for from_block in block_table:
# mapping 为空,走不到if
if from_block in mapping:
to_block = mapping[from_block]
to_block.ref_count += 1
# 会走else分支
else:
# 在CPU上分配物理块
to_block = dest_allocator.allocate(
from_block.block_hash, from_block.num_hashed_tokens)
# 记录GPU与CPU上物理块的索引号映射,便于以后cpu->gpu找回。
mapping[from_block] = to_block
# 记录CPU物理块的索引号,CPU物理块与CPU物理块一一对应
new_block_table.append(to_block)
# Free the source block swapped in to destination.
# 释放GPU物理块
src_allocator.free(from_block)
return new_block_table
经过swap_out操作后,self.block_tables中存储的是被操作seq_id与cpu block的映射关系。
mapping存储的是CPU block与gpu block之间一一对应的索引号,便于以后cpu->gpu转移时找回。
6.37 swap_in
- 如果有足够block,会把swapd中的seq_group移回running(在_schedule_swapped中使用)
def can_swap_in(self,
seq_group: SequenceGroup,
num_lookahead_slots: int = 0) -> AllocStatus:
assert num_lookahead_slots == 0, "BlockSpaceManagerV1 does not support lookahead allocation"
# 当前seq_group正在使用的不重复的物理块
blocks = self._get_physical_blocks(seq_group)
# 当前处于SWAPPED状态的seq数量
num_swapped_seqs = seq_group.num_seqs(status=SequenceStatus.SWAPPED)
# 忽略
if seq_group.is_encoder_decoder():
num_swapped_seqs += 1
# 当前GPU可用的物理块数量
num_free_blocks = self.gpu_allocator.get_num_free_blocks()
# NOTE: Conservatively, we assume that every sequence will allocate
# at least one free block right after the swap-in.
# NOTE: This should match the logic in can_append_slot().
# len(blocks)是移动回GPU时应该使用的物理块数量,prompt+已完成解码的output 的kv-cache 需要使用这些block
# num_swapped_seqs是预备生成的token所使用的block,前面我们分析过,解码阶段,一个seq可能使用的
# block最小为0(最后一个block槽位没满,还能继续添加),最大为1(最后的block槽位满,要新增block才能完成推理)
# 随意二者加起来的block的数量才是能绝对满足该seq_group推理的block数量
num_required_blocks = len(blocks) + num_swapped_seqs
# 如果GPU总共的blocks(不是可用block,是所有的block)都小于num_required_blocks,
# 这条seq_group没法推理(GPU装不下这条数据),
if self.gpu_allocator.get_num_total_blocks() < num_required_blocks:
return AllocStatus.NEVER
# 在水位线以上,合格
elif num_free_blocks - num_required_blocks >= self.watermark_blocks:
return AllocStatus.OK
# 小于水位线,GPU block数量暂时不够,稍后在处理这条数据
else:
return AllocStatus.LATER
def swap_in(self, seq_group: SequenceGroup) -> List[Tuple[int, int]]:
request_id = seq_group.request_id
# CPU block -> GPU block.
# dict is efficient in lookup `if cpu_block in mapping`
mapping: Dict[PhysicalTokenBlock, PhysicalTokenBlock] = {}
for seq in seq_group.get_seqs(status=SequenceStatus.SWAPPED):
self.block_tables[seq.seq_id] = \
self._swap_block_table(self.block_tables[seq.seq_id], # 取出该seq用到的GPU block
self.cpu_allocator, # CPU物理块分配器
self.gpu_allocator, # GPU物理块分配器
mapping)
if seq_group.is_encoder_decoder():
self.cross_block_tables[request_id] = \
self._swap_block_table(self.cross_block_tables[request_id],
self.cpu_allocator,
self.gpu_allocator,
mapping)
return [(cpu_block.block_number, gpu_block.block_number)
for cpu_block, gpu_block in mapping.items()]
可以看到swap_in的代码与前面swap_out很像,只是self._swap_block_table方法,CPU,GPU块分类器次序变了。
感觉swap_in和swap_out这两个方法会在后期版本迭代时合并在一起。
到此,调度系统中涉及的block操作已经全部讲完,代码量挺多,但不是很复杂,总体来说,就是比较物理块数量来决定seq_group推理状态。 注意,只是调度(seq.id与block索引号映射, gpu与CPU block之间的kv-cache转移等),并不是实际填充kv-cache, 填充操作在推理过程由另外的模块完成(在attention的计算中完成, 在后续篇幅讲解)。
遗留工作:
在BlockSpaceManagerV1类初始化时,我们讲到BlockAllocator有两种,目前仅讲了一种,另一种更复杂的block分配方式CachedBlockAllocator并没有提到。要启用这个模式,需要在vllm 加载LLM时传入enable_prefix_caching= True。
CachedBlockAllocator模式核心思想是带有这些相同prefix信息(如"提示词 你是一个助手")的prompt和decode的token的kv-cache完全可以共享,存放在同一个物理块,达到节省显存的目的。
目前我们使用UncachedBlockAllocator的方法也能走通推理流程,CachedBlockAllocator逻辑比较复杂,这篇文章已经写的很长,不再这里展开了,以后有机会再解析吧。








![[数据集][目标检测]电动车头盔佩戴检测数据集VOC+YOLO格式4235张5类别](https://i-blog.csdnimg.cn/direct/afcfb8ac908a4fb196ce0191978570d3.png)