
💎所属专栏:MySQL


1. 索引概述
MySQL中的索引是帮助MySQL高效获取数据的数据结构,可以极大地提高数据库的查询效率,减少数据库的I/O成本,就像书的目录一样,它可以帮助我们快速定位到书中的内容。
优势:
- 提高数据检索的效率,降低数据的IO成本
- 通过索引列对数据进行排序,降低数据排序的成本,降低CPU的消耗
劣势:
1. 索引列需要占用一定的空间
2. 索引大大提高了查询效率,同时也降低了更新表的效率,例如对表进行INSERT,UPDATE,DELETE时,效率会降低
在实际开发中,查询操作要远远多于更新操作,还是更推荐使用索引。
2. 索引的分类

3. 索引的使用
3.1. 查看索引

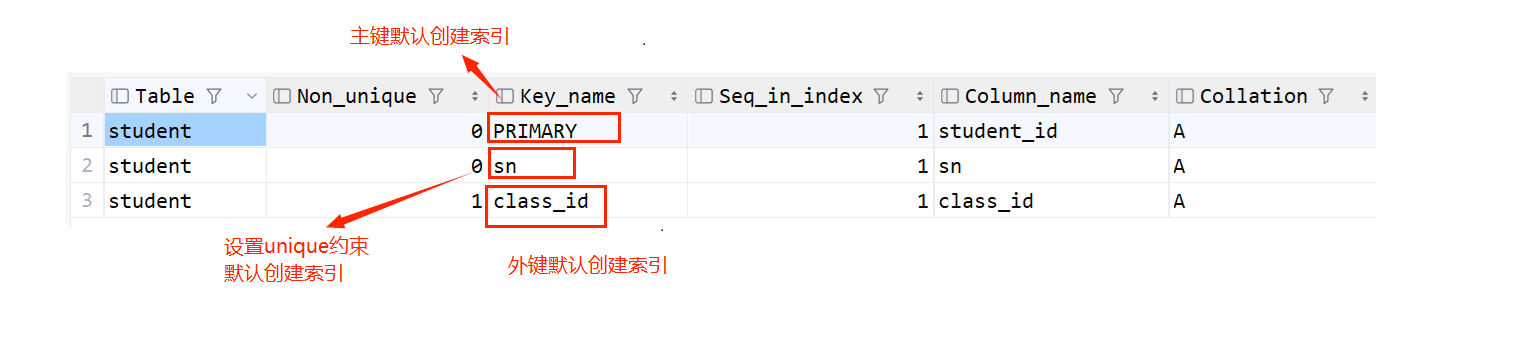
show index from student;索引是按照列的方式创建的,可以给某个列创建索引
primary key,unique,foreigh key都会自带索引,不需要手动创建,只需要建表的时候指定约束,就会自动生成索引
生成索引之后,假如只有student_id有索引,那么只有select * from student where student_id = 1;这样这对有索引的那一列的查询才会提高效率,其他的话还是遍历整个表
3.2. 创建索引

-- 创建索引
create index name_index on student (name);
-- 查看索引
show index from student;
创建索引其实是一个危险操作:
如果是针对空表或表中的数据量小,创建索引问题不大,但是在日常开发中,正常来说数据规模都是比较大的,一旦创建索引之后,就可能触发大量的硬盘IO,机器就会卡死
所以说,在最初创建表的时候就要提前规划出需要给那些列加上索引,如果说某个表中确实需要加索引,那么就需要重新换一个数据库,把原来的数据导入到新库中
3.3. 删除索引

-- 删除索引
drop index name_index on student;
-- 查看索引
show index from student;
unique自动生成的索引可以被删除,但是primary key 还有 foreigh key自动生成的索引是不可以删除的
既然创建索引就已经是危险操作了,那么删除索引肯定也是一个危险操作,具体原因是一样的,在实际开发中,一般也不会去删除一个索引
4. 索引结构
MySQL的索引是在存储引擎层实现的,不同的存储引擎有不同的结构,主要包括以下几种:
| 索引结构 | 描述 |
| B+Tree索引 | 最常见的索引类型,大部分引擎都支持B+Tree索引 |
| Hash索引 | 底层是哈希表,只有精确匹配索引列的查询才有效,不支持范围查询 |
| R-tree(空间索引) | 空间索引是MyISAM引擎的一个特殊索引类型,主要用于地理空间数据类型,使用较少 |
| Full-text(全文索引) | 通过建立倒排索引,快速匹配文档的方式。类似于Lucene,Solr,Es |
后面两种索引都使用的很少,主要介绍前面两种
在我们学过的数据结构之中,适合作为查询的有哈希表,二叉搜索树,哈希表就不多说了,二叉搜索树可能会变成一个单分支树,或是一条链表,最坏情况下查询的时间复杂度是O(n)的,所以就有了红黑树,边插入边调整,使其保证二叉树的结构,但是当数据量特别大时,尤其是对于数据库这样级别的数据量,红黑树的树高也会非常大,查询的效率还是不够高,所以就又出现了一种为数据库量身打造的数据结构——B+树,B+树是对B树做出了进一步的改进
4.1. B-tree(多路平衡查找树)
B树就是在二叉搜索树的基础上,允许多于两个子节点的多路平衡查找树,有N个key,划分成N+1个区间,通过这样的结构,进行查询的时候,针对每一个节点,都要比较多次,才能确定下一步要走哪个区间,虽然说相比于二叉树,树的高度变低了,但是比较次数变多了,相比于二叉树效率真的提高了吗?
其实,对于每一个节点,访问的时候是一次硬盘IO就可以了,和某个节点比较的的时候,是先一次硬盘IO,把这个节点上的内容都读取出来,接下来的比较都是在内存中进行的了,所以说减少了硬盘IO的次数,因此这种结构效率更高

4.2. B+树
B+树是B树的一种变形形式,
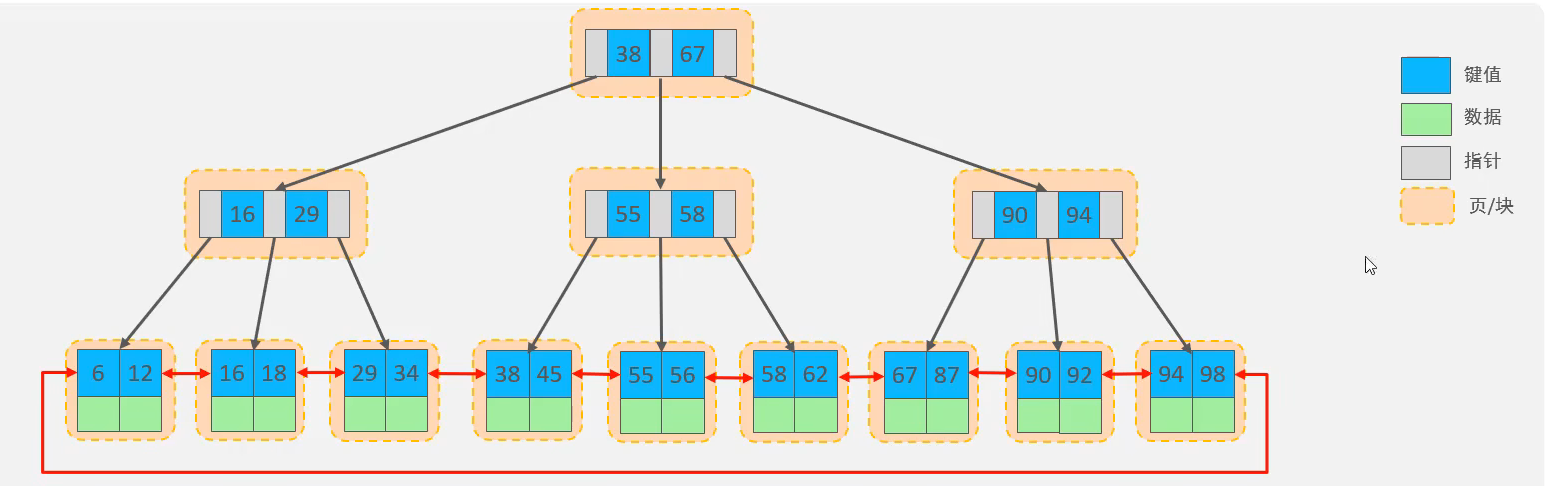
B+树的优势:
- N叉搜索树,高度比较低,硬盘IO比较次数就少
- 叶子节点是全集,并且用链表结构连接,方便进行范围查询
- 在B+树中,所有查询都是要落在叶子节点上完成的,每次查询经历的IO次数和比次数都是差不多的,查询的开销比较稳定
- 还是由于叶子节点是全集的性质,非叶子节点不必存储数据行,只需要存储索引列的key即可,这使得非叶子节点占用的空间也比较小


















