据国际数据公司(IDC)的报告显示,预计到2025年,全球范围内每天将产生高达180ZB的庞大数据量,这一趋势预示着企业将面临着更加严峻的海量数据处理挑战。随着数据日渐庞大,一些存储系统会出现诸如存储空间扩展难、性能下降甚至卡顿的情况,影响业务系统的正常运转,增加企业的数据处理成本。众多企业已经开始积极寻求如何在保证处理效率的同时,进一步降低数据处理成本。特别是在历史库(冷数据)场景中,这种需求显得尤为普遍。
那么,作为一款帮助企业在历史库场景下成本至少降低50%的数据库,OceanBase 的核心技术是什么?本文将详细解读OceanBase 存储引擎技术。
一套存储引擎支持业务全阶段,极致节约资源成本
在传统数据库选型过程中(见下图),起初单机小规格的 MySQL 即可支撑业务需要。但随着业务的发展,MySQL 逐渐在数据增长的过程中无法满足性能和存储需求。这时,将系统升级为高规格机器的 Oracle 成为众多企业的选择,当高规格单机 Oracle 也无法满足的数据量时,则会考虑使用 RAC 共享存储,甚至为核心业务更换数据库类型,如 Db2。然而众所周知,数据系统作为“底座”和“心脏”,在更替时不仅要将对业务的影响降至最低,还必须考虑替换成本,因此一套顺滑可扩展的系统会大大降低成本和风险。那么,有没有一套系统可以应对客户不同业务规模下的数据管理需求呢?
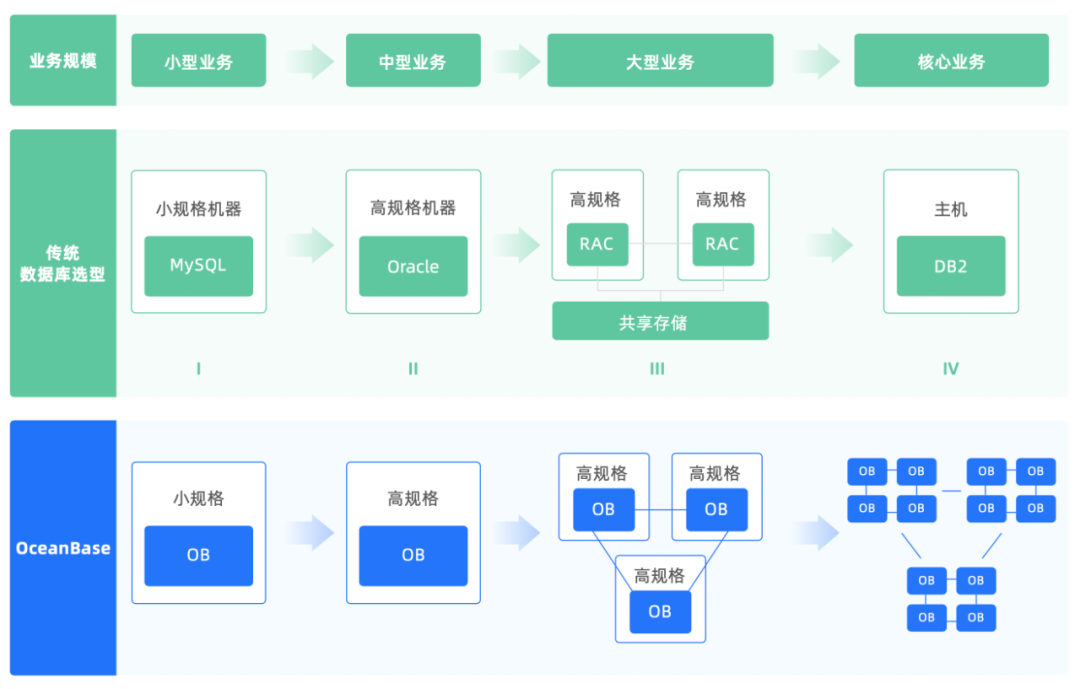
OceanBase 4.0提出的单机分布式一体化设计就能够满足业务不同阶段的需求。其兼具分布式的扩展性和集中式数据库的功能与单机性能。通过动态日志流的方式,实现了系统静态下的单机高性能,以及动态调整日志流平滑快速扩展的目的。对于存储引擎,则通过资源开销的小型化轻量化,使得同一个引擎支持不同部的署形态,支持轻松从小数据量到海量数据的平滑增长。
因此,在小型业务小数据量场景下,一个小规格 OceanBase单机实例便可支撑。随着业务数据量的缓慢增长,通过最简单的垂直扩容,即租户配置升级到高规格即可满足。当业务发展需要有容灾或者负载均衡时,OceanBase可轻松切换至三副本,每个副本的数据存储仍然保证高压缩比,用以降低多副本带来的成本增长。对于大型业务,则可通过在集群内水平扩容的方式来满足需求。这就是OceanBase 单机分布式一体化的重要意义和作用。
另外,在OceanBase 4.x 版本,存储引擎在资源管理方面更加轻量化、小型化和可扩展,使企业更充分、更合理地使用资源,节约资源使用成本。
单机百万分区支持,元数据小型化,按需加载,提高资源使用效率
OceanBase 创新地提出了日志流概念,用以降低海量数据分区下的网络、CPU 开销。每个数据分区的多副本都是一个Paxos成员组,用以保证数据的多副本的一致性。为了降低多分区或是小规格下的一致性协议开销,将相同成员组的数据分区日志聚集在一起,即所谓的单日志流。只需要一个日志流负责同步或选举即可实现一组分区副本的容灾及 Paxos 高可用。
而对于海量数据下的内存,OceanBase 存储引擎设计了元数据按需加载,智能区分冷热分区和必要的元数据,极大降低内存占用。
如下图所示,日志流下面有很多 Tablet ,即数据分片,可以理解为用户表的一个分区。它是分布式系统负载均衡和容灾恢复等最基础的单位。Tablet 的数量 与 Log Stream 相比是指数级的,原因在于一个集群里的可用区的拓扑关系是有限和少量的。但是对分区来说,其数量是会根据业务需求来调整,分区数量可能上万。
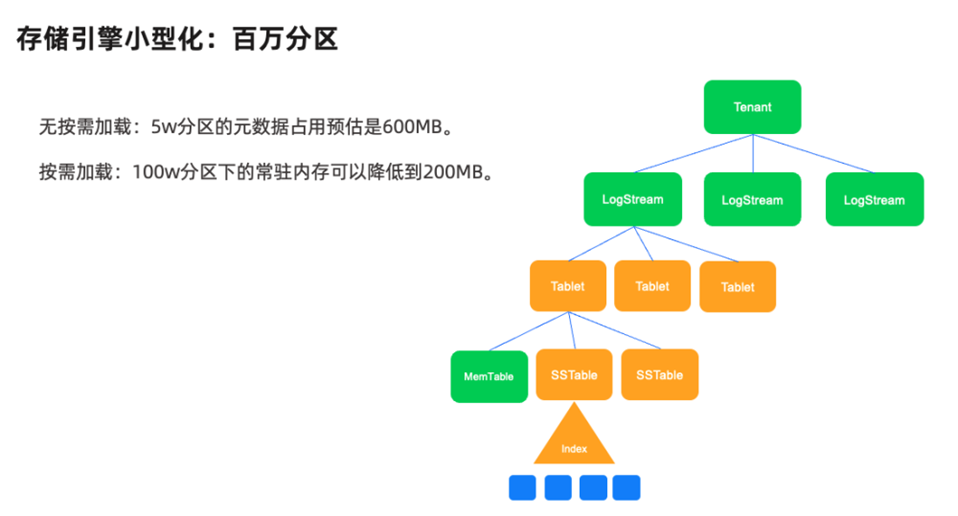
在OceanBase 4.x版本中,存储引擎不再将用户的所有分区下的元数据常驻在内存里,而是按需加载。所谓元数据,是指分区副本的一些基本属性,用以支持数据的增删改查、LSM-Tree的变更、负载均衡、容灾恢复等单机和分布式功能。所谓按需加载,是指将热分区下的元数据保持在内存里,不加载不经常访问的冷分区或是其元数据。通过冷热分离手段,使内存的使用效率发挥到极致。在老版本中,5W 分区的元数据占用预估 600MB内,而4.x 版本中100w 分区下的常驻内存可以降低到 200MB。小规格机器下,就能支持更多的分区。类似历史库按时间分区的场景,就能在不升级机器规格的情况下,存储更久远的历史数据。
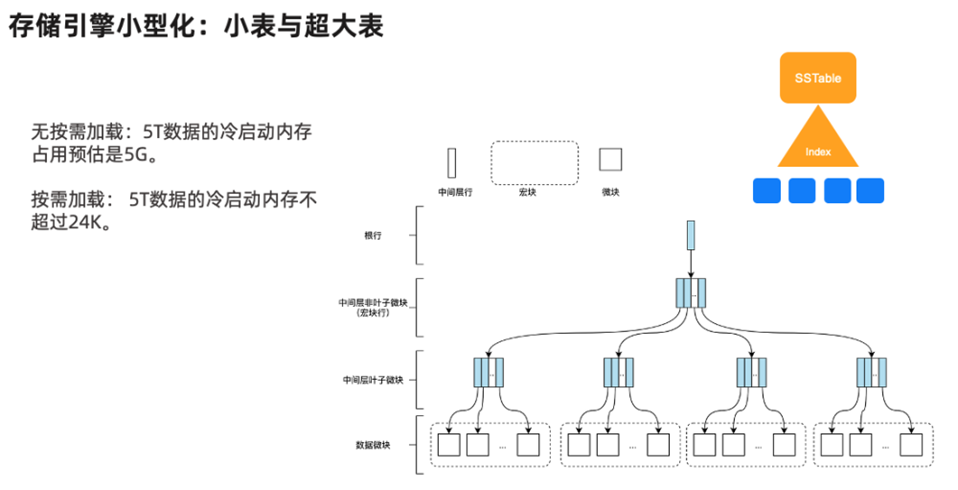
此外,在OceanBase 老版本中,无论是冷数据还是热数据,查询这些数据依赖的数据块元数据都会常驻在内存里。预计一张 5TB 容量的表的冷启动内存占用是 5GB 内存,但是,随着单表或单分区内的数据量增加,有限内存下很难做到同步扩展用以支撑数据查询。
对于历史库的场景而言,其特点往往是写多、读极少,单表体量极大,企业用户在配置历史库时更关注成本,往往使用小内存、大磁盘的机型。因此,在OceanBase 4.X 版本中,存储引擎对磁盘上的 SSTable 存储格式做了重构,将原本根据数据主键定位宏块的索引层(元数据的一种),从一层换成了树状结构。用于数据查询的元数据不再会常驻内存,而是动态地根据请求负载加载那些查询路径上有关的微块。同等对比下,一张 5TB 容量的表的冷启动内存不超过 24KB,不论数据规模如何膨胀,也不影响单机内存的使用。进一步在历史库的机型选择上降低了对内存的要求成本。
更灵活的磁盘I/O隔离策略,更安全、更充分地使用资源
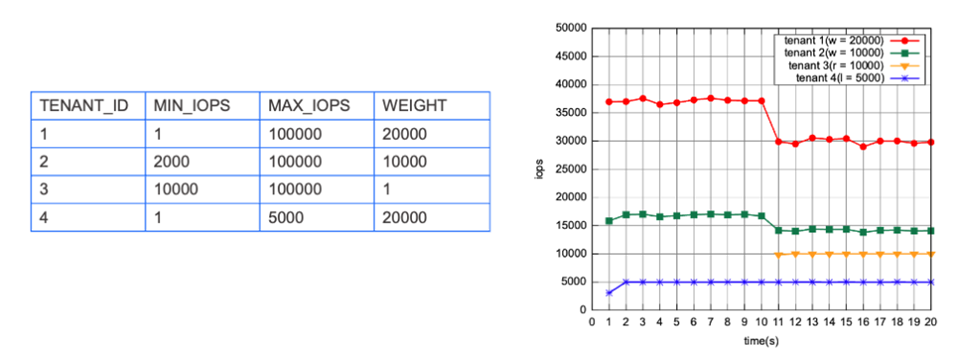
OceanBase 存储引擎提供一套完整的语法支持,为每个租户配置最大或最小 IOPS 及权重的能力。让用户能灵活调配租户所使用的I/O资源,进一步均衡流量高低峰间对磁盘的性能要求,降低成本。
如下图,4 号租户(蓝线,可以限制 IOPS)要求最大 IOPS 不超过 5000 ,在业务上可以防止并发流量过大影响其他租户, 1 号(红线)、2 号(绿线)租户本身 IOPS 量比较大,配置上限是 10 万,权重比可以控制流量比较大的租户之间的关系,比如永远保持 2:1 的关系。如果 3 号(黄线)租户新加入这个集群,会对集群产生什么冲击呢?由于 4 号租户有限制,因此不受影响,3 号租户的 IOPS 可以向 1 号、2 号租户借,1 号、2 号租户按照比例下降权重,这样就可以起到租户间的隔离作用。
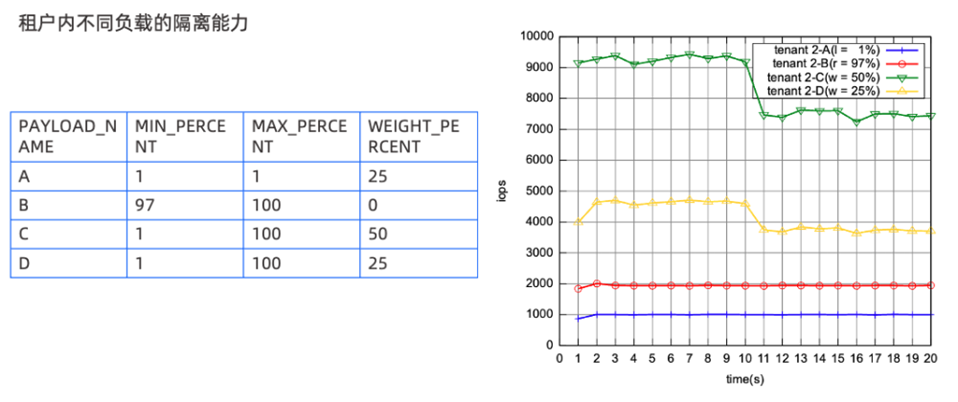
除了租户间的隔离外,还有租户内的隔离。为什么要做租户内的隔离呢?
从两个场景来看:第一,HTAP 场景,比如同时需要承担 TP 和 AP 业务流量的情况下,避免对于延迟敏感的TP型请求受到干扰,影响正常业务流量的稳定性;第二,前台流量和后台流量隔离,如果后台资源隔离做不好,则会影响前台的查询请求,进而产生用户可感知的抖动。租户内隔离可以做到不同负载混合场景下都能安全有效地使用资源,举个例子,下图中ABCD 可以是不同的负载,B 的 Min Percent 设置 97%,意味着虽然 B 是最小的 IOPS,但希望能保证最小的 IOPS 不至于跌的很低(蓝线),A 和 C 本身的权重是 50:25,从图中也可以看到保持着 2:1 的关系,去保证不同的负载能够拿到相应的 IOPS 。
Compaction优化,降低空间放大和磁盘开销
作为存储引擎中另一个对系统资源依赖比较重的领域,Compaction 一直是基于LSM-Tree架构的系统里最值得深入研究和探索的核心技术热点之一。各家厂商都在解决读放大、写放大和空间放大间上的权衡问题上,有着这各自的优化。Compaction 的技术掌控力,关系到能不能为用户节省下更多的计算资源,投入到处理更多的业务请求,达到更佳的性价比。OceanBase 存储引擎经过十多年的自研探索,在 compaction 的计算性能提升和磁盘空间等资源成本降低方面应用了许多有效的优化方法。
OceanBase 存储引擎的 Compaction 整体采用的是业内熟知的Tiered & Leveled Policy,在此基础上,根据事务特性、数据特征、资源依赖等因素,设计不同类型的compaction。
如下图,整个LSM-Tree的持久化SSTable只有三层,有别于RocksDB、Cassandra和一些其他系统的多层优化。虽然层数不多,但每一层SSTable都有其设计目的。L0 层目的在于尽快释放内存,其中对于数据的处理逻辑必须是低耗且快速的;L1 层则是尽可能地消除读放大,因为数据之间可能出现交叉,包括空间上的数据冗余及时间是多版本间的冗余,还需要考虑磁盘开销;L2层不仅要彻底解决空间放大的问题,还要做到数据校验、回收和压缩等较复杂且带有事务和分布式特性的功能点。
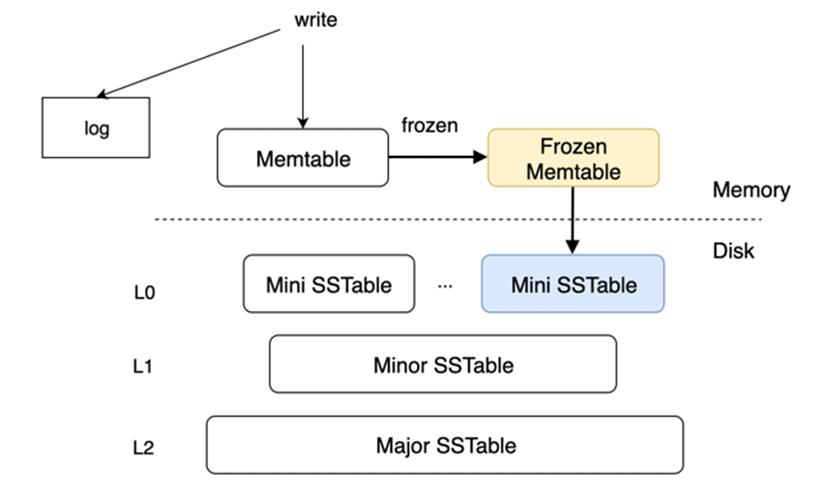
基于数据处理和系统资源两方面的深入分析,OceanBase 存储引擎在4.x版本中设计了多类型的 compaction (mini、minior、medium、major),能够依据系统内资源的实时状况,结合统计采样,自动调用相应的compaction,达到动态平衡缓解资源瓶颈、提高系统稳定性的目的。其中:
- Mini Compaction 负责生成L0层的SSTable,磁盘格式上采用高效的稠密格式,不采用耗时较大的压缩技术,在最大化iops的同时,对CPU消耗最小。
- Minor Compaction 负责生成L1层,合并多个L0和L1层SSTable。其功能是重新整理同一主键上的多版本数据,提高查询性能,自动探测增量数据间的重叠范围,做宏块级别的数据块重用,降低空间放大。未来,还会支持数据编码和压缩,进一步降低磁盘开销。
- Major Compaction 产生L2层的基线数据。在降本方面,major是主要的贡献者。除了进一步回收增量数据中的老版本数据、磁盘格式根据用户的表格属性会采用高级压缩技术降低存储成本以外,4.x版本中还对于离散插入导致的数据空洞做重整和压缩,对于不同类型的数据更新模型有好的支持。另外,major还负责多副本间的数据校验,保证数据存储的安全可靠。
而Medium Compaction,作用之一是解决LSM-Tree 架构中著名的queuing表问题。举个例子,如下图中用户插入 6 行数据,随后又删除这 6 行数据。从逻辑上来说,Table 是空的,但实际查询扫描的物理行数仍然是12 行。再例如 update 和 inset 交互的场景,也会出现聚合count为2行,但实际扫描代价为7行的问题。这类现象归结为物理行数与逻辑行数的巨大差异造成了查询性能的不及预期。
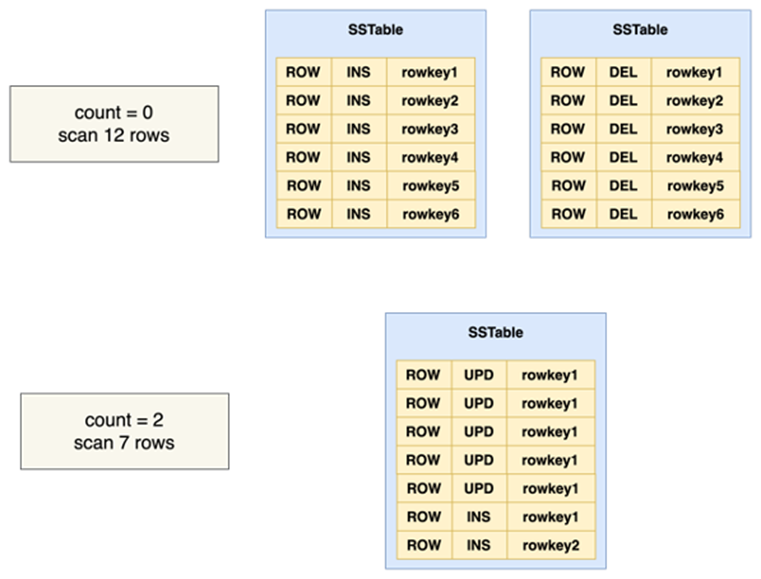
在 OceanBase 的老版本中,用户在建表时需要显式指定 buffer 表属性,以提示存储引擎发现行数比较多的buffer表,尽快触发特殊的 compaction 动作把一些行压缩掉。OceanBase 4.1 版本里,存储引擎在每次生成 SSTable 时,会智能地对数据做统计信息收集。对于每个SSTable,通过一组向量来表示这组数据的更新特征,当发现符合queuing表的特征时,系统会自动发起medium compaction,消除冗余数据。这一过程对于用户是无感的,不需要用户在建表前感知业务特性,也不会在系统上线后被迫做一次DDL,降低了使用OceanBase 的门槛,提高业务切流后的稳定性。
编码与压缩,存储空间极致降本
除了在资源利用、磁盘占用、内存占用方面降低整体成本外,还有一个关键在于降低存储成本,其中的核心技术在于存储引擎。尤其是在海量数据的历史库场景中,越是好的存储引擎带来的降本收益越是可观。
很直白地说,OceanBase 存储引擎在降成本方面有着传统数据库不具备的架构优势。一般而言,基于 B+ Tree 的传统数据库,由于是in place update,底层的 block 又是定长的,因此在存储压缩后会有写放大的碎片问题需要解决,同时会对查询性能造成一定影响。OceanBase使用LSM-Tree 存储架构,为数据库压缩提供了更多可能。首先,消除了传统 B+Tree 的磁盘随机写瓶颈和存储空间碎片化问题,相比传统实时更新数据块的方式,拥有更高的写入性能。其次,可以将数据更新(增删改)与压缩动作解耦,数据更新路径中没有压缩动作,对性能影响更小。同时,在批量落盘的过程中,数据库可以自适应地调整数据块中的数据量,并在连续对数据块进行压缩的过程中,利用上一个块的压缩率等先验知识对下一个块进行更好地压缩。
如下图所示,OceanBase 存储引擎针对高压缩比的磁盘格式,采用行列混存模式。区别于行存模式,微块内的数据不再是一条条铺平的行,而是按列先组织在一起。Compaction生成SStable期间,对于微块的编码和压缩是分两步进行的。第一步会利用某一列上相邻行的数据特征,挑选比较合适的算法进行编码,经过第一层编码后的压缩率往往能够达到 50%,第二步再对编码后的微块进行一次通用压缩,最终甚至能达到平均30%更极致的压缩率。
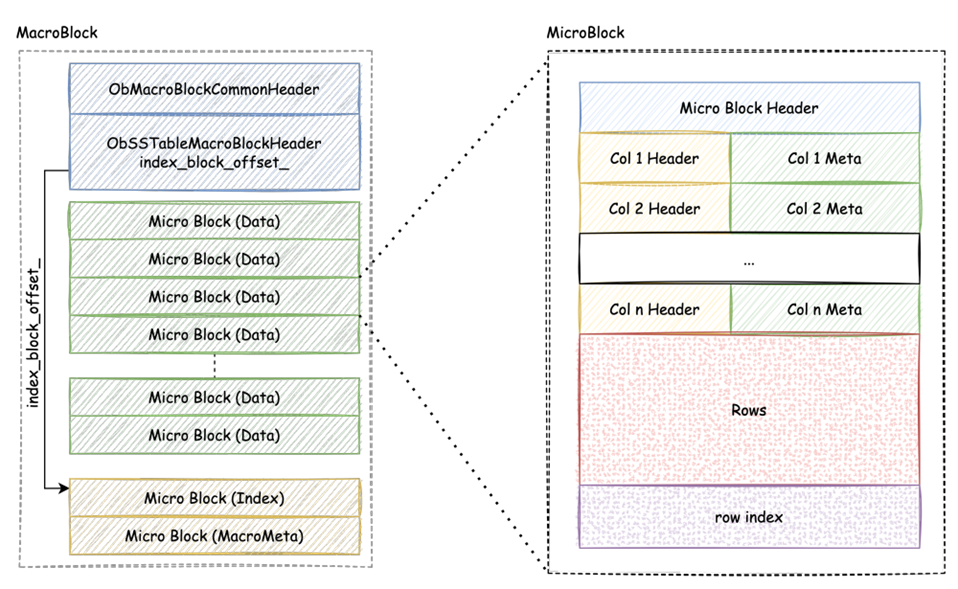
OceanBase 存储引擎在选择编码算法时,会自动分析数据类型、值域、NDV 等特征,参考相邻微块的编码压缩历史,是自适应启发式的算法。例如,对于用小范围的字符串像车辆牌照等,支持 Bit-packing 和 HEX 编码,能够有效降低存储的位宽,达到编码压缩的效果;对于列数据重复率高的例如性别、星座等,会采用字典编码和 RLE 编码做单列数据去重;对于字符串或值域相近的采用差值编码;当数据列与列之间存在关联或者前缀相近时,如商品大类之间的条形码,采用列间编码减小多列数据冗余。
对于编码数据的查询是不需要解码的,除了直接查询以外,还支持聚合与过滤的下压、支持 SIMD 向量化运算。后续OceanBase 将发布真正的列存版本,能对数据编码特征做探测和自适应调整,支持更高级的skip index功能,对 AP 的查询性能会有非常明显的提升。
总结:OceanBase 存储引擎低成本、高效管理数据的秘诀
OceanBase的存储引擎经过多年全自研探索,从数据流入到流出的各个环节都对资源开销成本做了极致优化,形成一套统一的高效、可扩展的数据存储架构。
- 在数据组织上,对各层元数据采用了按需加载的方式,使系统的内存资源服务于访问更频繁的热点数据,进一步降低单机规格依赖,提升小规格场景的收益。
- 在数据写入路径,多层次、多类型compaction策略,在保证高效写入性能的同时,又能保证平滑不抖动,自动压缩数据空洞,高压缩比基线数据,降低存储成本。
- 在数据查询方面,不同格式均支持聚合和过滤下推、SIMD向量化以及未来的skip index,提升了大查询和AP性能。
- 在资源管控中,租户间CPU、内存和I/O等资源隔离逐步完善,使同一套集群服务于多业务系统,降低系统整体成本。
以上只是存储引擎中的冰山一角,希望后续有更多机会立足用户的实际体验和场景,与大家交流存储引擎的技术内幕和细节。