1 概述
映射的基本概念
Mapping 也称之为映射,定义了 ES 的索引结构、字段类型、分词器等属性,是索引必不可少的组成部分。
ES 中的 mapping 有点类似与DB中“表结构”的概念,在 MySQL 中,表结构里包含了字段名称,字段的类型还有索引信息等。在 Mapping 里也包含了一些属性,比如字段名称、类型、字段使用的分词器、是否评分、是否创建索引等属性。
1.1 查看索引 mapping
查看完整 mapping
GET /index/_mappings
查看指定字段 mapping
GET /index/_mappings/field/<field_name>
课程DSL
DELETE /test_index
PUT /test_index
GET /test_index
GET /test_index/_mapping/field/namePUT test_index/_doc/1?op_type=index
{
"name":"赵四",
"age":18
}
2、字段数据类型
映射的数据类型也就是 ES 索引支持的数据类型,其概念和 MySQL 中的字段类型相似,但是具体的类型和 MySQL 中有所区别,最主要的区别就在于 ES 中支持可分词的数据类型,如:Text 类型,可分词类型是用以支持全文检索的,这也是 ES 生态最核心的功能。
2.1 数字类型
- long:64位有符号整数,适用于存储大整数值,比如日期时间戳等。
- integer:32位有符号整数,通常用于存储普通整数值,适用于一般的整数计数。
- short:16位有符号整数,适用于需要节省存储空间的场景,比如对内存占用有要求的情况。
- byte:8位有符号整数,适用于存储小整数值,对存储空间要求较高的场景。
- double:64位双精度浮点数,适用于需要高精度的浮点数计算,比如科学计算等。
- float:32位单精度浮点数,适用于需要较高性能和节省存储空间的场景。
- half_float:16位半精度浮点数,适用于需要更高存储效率和较小存储空间的场景。
- scaled_float:缩放类型浮点数,适用于需要按比例缩放的场景,可以提高存储效率。
- unsigned_long:无符号64位整数,适用于需要存储非负整数值的场景,比如计数器等。
2.2 基本数据类型
- binary:binary类型用于存储Base64编码的二进制数据。在某些情况下,可能需要存储一些二进制数据,比如图片、文件等,但Elasticsearch并不直接支持存储原始二进制数据。因此,可以将二进制数据转换为Base64编码的字符串,然后存储在binary类型中。
- boolean:boolean类型用于存储布尔值,即true或false。在数据中有一些字段只需要表示是或否、真或假的情况时,可以使用boolean类型来存储这种信息。比如,表示某个状态是否开启、某个条件是否满足等情况。
- alias:alias类型用于定义字段别名。在Elasticsearch中,可以为字段设置别名,这样可以在查询时使用别名代替字段名称,提高查询的灵活性和可读性。通过定义字段别名,可以简化查询语句,减少重复性代码,同时也可以保护字段名称的一致性。
2.3 Keywords 类型
- keyword:keyword类型适用于索引结构化的字段,可以用于过滤、排序和聚合。该类型的字段只能通过精确值搜索到,不会进行分词或变换。适合存储一些不需要分词处理的字段,比如ID、姓名等。
- constant_keyword:constant_keyword类型是一种常量关键字字段,始终包含相同的值。这种类型的字段通常用于表示固定不变的值或标识符,可以在查询中作为常量使用。
- wildcard:wildcard类型是一种通配符查询类型,类似于grep命令的通配符匹配。使用通配符可以进行模糊匹配和搜索,支持使用*和?等通配符符号进行匹配。适合在需要进行模糊搜索或匹配的场景中使用。
2.4 Dates(时间类型)
-
date:JSON 没有日期数据类型,因此 Elasticsearch 中的日期可以是以下三种
- 包含格式化日期的字符串,例如 “2015-01-01”、 “2015/01/01 12:10:30”
- 时间戳,表示自"1970年 1 月 1 日"以来的毫秒数/秒数。
-
date_nanos:此数据类型是对 date 类型的补充。但是有一个重要区别。date 类型存储最高精度为毫秒,而date_nanos 类型存储日期最高精度是纳秒,但是高精度意味着可存储的日期范围小,即:从大约 1970 到 2262
2.5 对象类型
- object类型:object类型用于表示一个JSON对象,即非基本数据类型之外的默认JSON对象。可以将多个字段组合成一个对象进行存储和检索,方便对复杂数据结构进行管理和查询。
- flattened类型:flattened类型是一种单映射对象类型,其值为JSON对象。在索引时,flattened类型会将嵌套的JSON对象展平为一级字段,使得数据更加扁平化,便于查询和分析。
- nested类型:nested类型是一种嵌套类型,用于存储嵌套结构的数据。当需要在一个文档中存储多个相关子文档时,可以使用nested类型。nested类型支持独立的查询和过滤,但在性能上会有一定的开销。
- join类型:join类型用于表示父子级关系类型的数据结构。通过join类型可以在一个文档中定义父子关系,例如在一个文档中存储多个子文档。这种类型可以用于实现层次化数据结构的存储和查询。
2.6 空间数据类型
- geo_point:geo_point类型用于表示纬度和经度点,即地理坐标点。这种类型适用于存储地理位置信息,比如城市的经纬度坐标。
- geo_shape:geo_shape类型用于表示复杂的空间形状,例如多边形、线条等。这种类型适用于存储地理区域的边界信息,比如国家的边界、地图上的区域等。
- point:point类型表示任意的笛卡尔点,即平面上的点。这种类型适用于存储二维空间中的点坐标。
- shape:shape类型表示任意的笛卡尔几何,即平面上的几何形状。这种类型适用于存储二维空间中的复杂几何形状。
与Redis的GEO数据类型相比,Elasticsearch的空间数据类型在功能和用途上有一些区别:
- Redis的GEO数据类型主要用于存储地理位置信息和进行地理位置相关的查询,比如查找附近的位置、计算距离等。而Elasticsearch的空间数据类型除了能够存储地理位置信息外,还可以存储和处理更复杂的空间几何数据,比如多边形、几何形状等。
- Elasticsearch的空间数据类型适用于存储和检索更复杂的地理空间数据,可以进行更灵活和精确的空间查询和分析。而Redis的GEO数据类型主要用于简单的地理位置存储和查询,功能相对简单。
2.7 文档排名类型
- dense_vector:记录浮点值的密集向量。(机器学习、自然语言处理和推荐系统等)
- rank_feature:记录数字特征以提高查询时的命中率。( 需要根据一些特征:页面排名、点击量、类别, 对文档进行动态的评分的场景)
- rank_features:记录数字特征以提高查询时的命中率。
2.8 文本搜索类型
- text:文本类型(全文检索 ,会被分析,会被分词器进行分词: 这种text默认是不可精准检索)。这是Elasticsearch中用于全文搜索的字段类型。当你需要对字段内容进行全文搜索(例如,使用match、match_phrase等查询)时,应该使用
text类型。
- annotated-text:包含特殊文本 标记。用于标识命名实体。
- completion ★:用于自动补全,即搜索推荐:字段的内容会被特殊地索引,以支持前缀搜索,这使得它可以快速地为输入提供补全建议。
- search_as_you_type: 类似文本的字段,经过优化 为提供按类型完成的查询提供现成支持 用例
- token_count:文本中的标记计数(这个并不会存初始文本)。
3、两种映射类型
3.1 自动映射:Dynamic field mapping
| field type | dynamic |
|---|---|
| true/false | boolean |
| 小数 | float |
| 数字 | long |
| object | object |
| 数组 | 取决于数组中的第一个非空元素的类型 |
| 日期格式字符串 | date |
| 数字类型字符串 | float/long |
| 其他字符串 | text + keyword |
除了上述字段类型之外,其他类型都必须显示映射,也就是必须手工指定,因为其他类型ES无法自动识别。
课程演示DSL:
#Dynamic mapping
DELETE product_mapping
GET product_mapping/_mapping
PUT /product_mapping/_doc/1
{
"name": "xiaomi phone",
"desc": "shouji zhong de zhandouji",
"count": 123456,
"price": 123.123,
"date": "2020-05-20",
"isdel": false,
"tags": [
"xingjiabi",
"fashao",
"buka"
]
}
GET product_mapping/_search
{
"query": {
"match": {
"name.keyword": "xiaomi phone"
}
}
}
3.2 显示映射 Expllcit field mapping
PUT /product
{
"mappings": {
"properties": {
"field": {
"mapping_parameter": "parameter_value",
...
},
...
}
}
}
课程演示DSL:
#手工创建mapping(fields的mapping只能创建,无法修改)
#语法
delete /product
GET product/_mapping
PUT /product
{
"mappings" : {
"properties" : {
"count" : {
"type" : "long"
},
"date" : {
"type" : "date"
},
"desc" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"isdel" : {
"type" : "boolean"
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"price" : {
"type" : "float"
},
"tags" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
PUT /product/_doc/1{
"name": "xiaomi phone",
"desc": "shouji zhong de zhandouji",
"count": 123456,
"price": 123.123,
"date": "2020-05-20",
"isdel": false
}
4、Text 和 Keyword 类型
刚开始学习 Elasticsearch 的人经常会混淆Text 和Keyword数据类型。 它们之间的区别很简单,但非常关键。
原理性的区别:
对于 Text类型,将文本存储到倒排索引之前,会使用分析器对其进行分析,而 Keyword类型则不会分析。
4.1 Text 类型
4.1.1 概述
当一个字段是要被全文搜索的,比如 Email 内容、产品描述,这些字段应该使用 text 类型。设置 text 类型以后,字段内容会被分析,在生成倒排索引以前,字符串会被分析器分成一个一个词项。text类型的字段不用于排序,很少用于聚合。
4.1.2 注意事项
- 适用于全文检索:如 match 查询
- 文本字段会被分词
- 默认情况下,会创建倒排索引
- 自动映射器会为 Text 类型创建 Keyword 字段
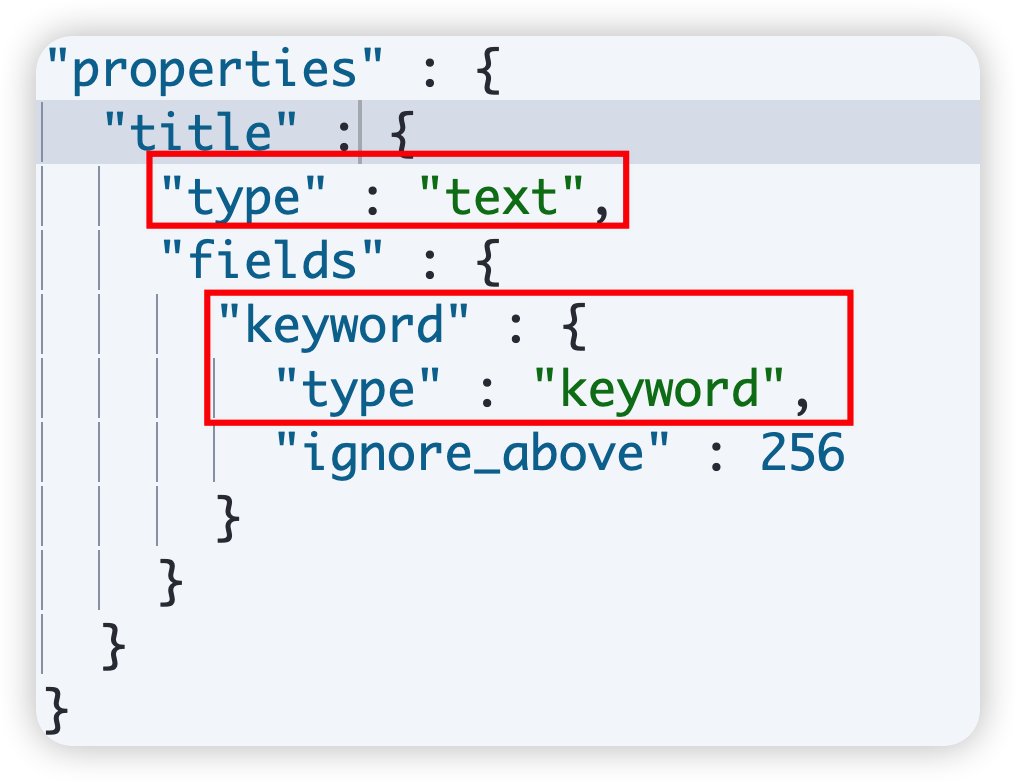
4.2 Keyword 类型
4.2.1 概述
Keyword 类型适用于不分词的字段,如姓名、Id、数字等。如果数字类型不用于范围查找,用 Keyword 的性能要高于数值类型。
4.2.2 语法和语义
如当使用 keyword 类型查询时,其字段值会被作为一个整体,并保留字段值的原始属性。
GET test_index/_search
{
"query": {
"match": {
"title.keyword": "测试文本值"
}
}
}
4.2.3 注意事项
- Keyword 不会对文本分词,会保留字段的原有属性,包括大小写等。
- Keyword 仅仅是字段类型,而不会对搜索词产生任何影响
- Keyword 一般用于需要精确查找的字段,或者聚合排序字段
- Keyword 通常和 Term 搜索一起用(会在 DSL 中提到)
- Keyword 字段的 ignore_above 参数代表其截断长度,默认 256,如果超出长度,字段值会被忽略,而不是截断。
演示DSL
### Text 和 Keyword 类型
delete /text-vs-keyword
#新建索引
PUT /text-vs-keyword
#设置索引mapping
PUT /text-vs-keyword/_mapping
{
"properties": {
"keyword_field": {
"type": "keyword"
},
"text_field": {
"type": "text"
},
"text_and_keyword_mapping": {
"type": "text",
"fields": {
"keyword_type": {
"type": "keyword"
}
}
}
}
}
POST /text-vs-keyword/_doc/example
{
"keyword_field": "The quick brown fox jumps over the lazy dog",
"text_field": "The quick brown fox jumps over the lazy dog"
}
### 使用Term Query查询keyword字段
# term 只有当文本完全匹配才会返回结果
GET /text-vs-keyword/_search
{
"query": {
"term": {
"keyword_field": {
"value": "The quick brown fox jumps over the lazy dog"
}
}
}
}
# Term Query在查询时不会对输入的关键词进行分析。
GET /text-vs-keyword/_search
{
"query": {
"term": {
"keyword_field": {
"value": "The"
}
}
}
}
### 使用Match Query查询keyword字段
# Match Query在查询时会对输入的关键词进行分析
GET /text-vs-keyword/_search
{
"query": {
"match": {
"keyword_field": "The quick brown fox jumps over the lazy dog"
}
}
}
### 使用Term Query查询text字段
# 倒排索引中,索引过程只存储分析后的分词
GET /text-vs-keyword/_search
{
"query": {
"term": {
"text_field": {
"value": "The quick brown fox jumps over the lazy dog"
}
}
}
}
# 标准分析器中的小写字母过滤器会将分词转化为小写
GET /text-vs-keyword/_search
{
"query": {
"term": {
"text_field": {
"value": "The"
}
}
}
}
GET /text-vs-keyword/_search
{
"query": {
"term": {
"text_field": {
"value": "the"
}
}
}
}
### 使用Match Query查询text字段
GET /text-vs-keyword/_search
{
"query": {
"match": {
"text_field": "The"
}
}
}
GET /text-vs-keyword/_search
{
"query": {
"match": {
"text_field": "the LAZ dog tripped over th QUICK brown dog"
}
}
}
5、映射参数
index
index:是否对创建对当前字段创建倒排索引,默认 true,如果不创建索引,该字段不会通过索引被搜索到,但是仍然会在 source 元数据中展示
##index
delete users
PUT users
{
"mappings": {
"properties": {
"age":{
"type": "integer",
"index": false
}
}
}
}
PUT users/_doc/1
{
"age":99
}
GET users/_search
{
"query": {
"term": {
"age": 99
}
}
}
analyzer
analyzer:指定分析器(character filter、tokenizer、Token filters)。
ES提供的分词器——内置分词器
standard Analyzer—默认分词器,英文按单词切分,并小写处理、过滤符号,中文按单字分词。
simple Analyzer—英文按照单词切分、过滤符号、小写处理,中文按照空格分词。
stop Analyzer—中文英文一切按照空格切分,英文小写处理,停用词过滤(基本不会当搜索条件的无意义的词a、this、is等等),会过滤其中的标点符号。
whitespace Analyzer—中文或英文一切按照空格切分,英文不会转小写。
keyword Analyzer—不进行分词,这一段话整体作为一个词。
##analyzer
delete blog
PUT blog
{
"mappings": {
"properties": {
"title":{
"type":"text",
"analyzer": "standard"
}
}
}
}
PUT blog/_doc/1
{
"title":"定义 默认 对索引 和 查询 都是 有效的"
}
GET blog/_search
{
"query": {
"term": {
"title": "查询"
}
}
}
boost
boost:对当前字段相关度的评分权重,默认1
delete blog
PUT blog
{
"mappings": {
"properties": {
"content":{
"type": "text",
"boost": 2
}
}
}
}
GET blog/_search
{
"query": {
"match": {
"content": {
"query": "你好",
"boost": 2
}
}
}
}
coerce
是否允许强制类型转换 true “1”=> 1 false “1”=< 1
#coerce:是否允许强制类型转换
PUT coerce
{
"mappings": {
"properties": {
"number_one": {
"type": "integer"
},
"number_two": {
"type": "integer",
"coerce": false
}
}
}
}
PUT coerce/_doc/1
{
"number_one": "10"
}
#//拒绝,因为设置了false
PUT coerce/_doc/2
{
"number_two": "10"
}
copy_to
copy_to:该参数允许将多个字段的值复制到组字段中,然后可以将其作为单个字段进行查询
#copy_to
delete copy_to
PUT copy_to
{
"mappings": {
"properties": {
"field1": {
"type": "text",
"copy_to": "field_all"
},
"field2": {
"type": "text",
"copy_to": "field_all"
},
"field_all": {
"type": "text"
}
}
}
}
PUT copy_to/_doc/1
{
"field1": "field1",
"field2": "field2"
}
GET copy_to/_search
GET copy_to/_search
{
"query": {
"term": {
"field_all": "field2"
}
}
}
doc_values 和 fielddata
doc_values:为了提升排序和聚合效率,默认true,如果确定不需要对字段进行排序或聚合,也不需要通过脚本访问字段值,则可以禁用doc值以节省磁盘空间(不支持text和annotated_text)
大部分的字段在索引时都会生成 doc_values,除了 text。text 字段在查询时会生成一个 fielddata 的数据结构,fieldata 在字段首次被聚合、排序的时候生成
dynamic
dynamic:控制是否可以动态添加新字段- true 新检测到的字段将添加到映射中。(默认)
false 新检测到的字段将被忽略。这些字段将不会被索引,因此将无法搜索,但仍会出现在_source返回的匹配项中。这些字段不会添加到映射中,必须显式添加新字段。
ignore_above
igbore_above 用于指定分词和索引的字符串最大长度,超过最大长度的话,该字段将不会被索引,这个字段只适用于 keyword 类型
PUT blog
{
"mappings": {
"properties": {
"title":{
"type": "keyword",
"ignore_above": 10
}
}
}
}
PUT blog/_doc/1
{
"title":"javaboy"
}
PUT blog/_doc/2
{
"title":"javaboyjavaboyjavaboy"
}
GET blog/_search
{
"query": {
"term": {
"title": "javaboyjavaboyjavaboy"
}
}
}
ignore_malformed
ignore_malformed 可以忽略不规则的数据,该参数默认为 false
#ignore_malformed
DELETE users
PUT users
{
"mappings": {
"properties": {
"birthday":{
"type": "date",
"format": "yyyy-MM-dd||yyyy-MM-dd HH:mm:ss"
},
"age":{
"type": "integer",
"ignore_malformed": true
}
}
}
}
PUT users/_doc/1
{
"birthday":"2020-11-11",
"age":99
}
PUT users/_doc/2
{
"birthday":"2020-11-11 11:11:11",
"age":"abc"
}
GET users/_doc/2
PUT users/_doc/2
{
"birthday":"2020-11-11 11:11:11aaa",
"age":"abc"
}
index
index 属性指定一个字段是否被索引,该属性为 true 表示字段被索引,false 表示字段不被索引。
# index
DELETE users
PUT users
{
"mappings": {
"properties": {
"age":{
"type": "integer",
"index": false
}
}
}
}
PUT users/_doc/1
{
"age":99
}
GET users/_search
{
"query": {
"term": {
"age": 99
}
}
}
GET users/_doc/1
index_options
index_options 控制索引时哪些信息被存储到倒排索引中(用在 text 字段中),有四种取值
| index_options | 备注 |
|---|---|
| docs | 只存储文档编号,默认即此 |
| freqs | 在 docs 基础上,存储词项频率 |
| positions | 在 freqs 基础上,存储词项偏移位置 |
| offsets | 在 positions 基础上,存储词项开始和结束的字符位置 |
norms
norms 对字段评分有用,text 默认开启 norms,如果不是特别需要,不要开启 norms。
null_value
在 es 中,值为 null 的字段不索引也不可以被搜索,null_value 可以让值为 null 的字段显式的可索引、可搜索(用另外一个字符替代)
#null_value
DELETE users
PUT users
{
"mappings": {
"properties": {
"name":{
"type": "keyword",
"null_value": "javaboy_null"
}
}
}
}
PUT users/_doc/1
{
"name":null,
"age":99
}
GET users/_search
{
"query": {
"term": {
"name": "javaboy_null"
}
}
}
GET users/_doc/1
position_increment_gap
被解析的 text 字段会将 term 的位置考虑进去,目的是为了支持近似查询和短语查询,当我们去索引一个含有多个值的 text 字段时,会在各个值之间添加一个假想的空间,将值隔开,这样就可以有效避免一些无意义的短语匹配,间隙大小通过 position_increment_gap 来控制,默认是 100。
#position_increment_gap
DELETE users
PUT users
PUT users/_doc/1
{
"name":["zhang san","li si"]
}
GET users/_search
{
"query": {
"match_phrase": {
"name": {
"query": "san li"
}
}
}
}
#sanli 搜索不到,因为两个短语之间有一个假想的空隙,为 100
GET users/_search
{
"query": {
"match_phrase": {
"name": {
"query": "san li",
"slop": 100
}
}
}
}
similarity
similarity 指定文档的评分模型
| similarity | 备注 |
|---|---|
| BM25 | es 和 lucene 默认的评分模型 |
| classic | TF/IDF 评分 |
| boolean | boolean 模型评分 |
fields
fields 参数可以让同一字段有多种不同的索引方式
#fields
DELETE blog
PUT blog
{
"mappings": {
"properties": {
"title":{
"type": "text",
"fields": {
"raw":{
"type":"keyword"
}
}
}
}
}
}
PUT blog/_doc/1
{
"title":"javaboy"
}
GET blog/_search
{
"query": {
"term": {
"title.raw": "javaboy"
}
}
}
GET blog/_doc/1
enable
enable:是否创建倒排索引,可以对字段操作,也可以对索引操作,如果不创建索引,让然可以检索并在_source元数据中展示,谨慎使用,该状态无法修改。
PUT my_index
{
"mappings": {
"enabled": false
}
}
6、映射模板
6.1 简介
之前讲过的映射类型或者字段参数,都是为确定的某个字段而声明的,如果希望对符合某类要求的特定字段制定映射,就需要用到映射模板:Dynamic templates。
映射模板有时候也被称作:自动映射模板、动态模板等。
6.2 用法
6.2.1 基本语法
"dynamic_templates": [
{
"my_template_name": {
... match conditions ...
"mapping": { ... }
}
},
...
]
6.2.2 Conditions参数
- match_mapping_type :主要用于对数据类型的匹配
- match 和 unmatch:用于对字段名称的匹配
6.2.3 案例
PUT test_dynamic_template
{
"mappings": {
"dynamic_templates": [
{
"integers": {
"match_mapping_type": "long",
"mapping": {
"type": "integer"
}
}
},
{
"longs_as_strings": {
"match_mapping_type": "string",
"match": "num_*",
"unmatch": "*_text",
"mapping": {
"type": "keyword"
}
}
}
]
}
}
以上代码会产生以下效果:
- 所有 long 类型字段会默认映射为 integer
- 所有文本字段,如果是以 num_ 开头,并且不以 _text 结尾,会自动映射为 keyword 类型
post test_dynamic_template{
"test1":1234,
"num_text":"abc",
"num_123":"abc",
"123_text":"abc"
}
get test_dynamic_template/_mapping
7、 IK分词器设置
在 Elasticsearch 中设置 IK 分词器涉及几个步骤,包括安装 IK 分词器插件、配置分词器以及在索引映射中应用分词器。以下是一个详细的指南,帮助你在 Elasticsearch 中设置 IK 分词器。
安装 IK 分词器插件
1、下载 IK 分词器插件:
- IK 分词器插件需要手动下载并解压到 Elasticsearch 的 plugins 目录下。可以从 GitHub 上获取最新版本的 IK 分词器插件。
- 下载地址: elasticsearch-analysis-ik
2、安装 IK 分词器插件:
-
将下载的 ZIP 文件解压缩到 Elasticsearch 的 plugins 目录下。
-
假设你下载的是 elasticsearch-analysis-ik-7.10.2.zip,解压后应该得到一个名为 elasticsearch-analysis-ik 的目录。
unzip elasticsearch-analysis-ik-7.10.2.zip -d plugins/或者,如果你使用的是 Elasticsearch 的插件管理命令,可以直接安装:
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.10.2/elasticsearch-analysis-ik-7.10.2.zip
3、 重启 Elasticsearch:
- 安装完插件后,需要重启 Elasticsearch 服务以使插件生效。
配置 IK 分词器
一旦安装了 IK 分词器插件,你可以在 Elasticsearch 的索引映射中配置分词器。IK 分词器提供了两种模式:
- ik_max_word:最大词模式,会将文本切分成尽可能多的词汇。
- ik_smart:智能模式,会将文本切分成合理的词汇组合。
创建索引并配置分词器
-
创建索引时配置 IK 分词器:
PUT your_index_name { "settings": { "analysis": { "analyzer": { "ik_analyzer": { "type": "custom", "tokenizer": "ik_max_word", // 使用 IK 最大词模式 "filter": ["lowercase"] // 可选:将所有单词转换为小写 } } } }, "mappings": { "properties": { "content": { // 你想要分词的字段 "type": "text", "analyzer": "ik_analyzer", "search_analyzer": "ik_analyzer" } } } }在这个示例中:
- ik_max_word 是 IK 分词器的最大词模式,它会尽可能多地分词。
- ik_analyzer 是自定义的分析器,使用了 ik_max_word 分词器。
- content 字段的 analyzer 和 search_analyzer 都指定了使用 ik_analyzer。
测试分词效果
在设置了分词器之后,你可以测试分词效果,例如:
PUT your_index_name/doc/1
{
"content": "这是一个测试文档,用来测试中文分词的效果。"
}
GET your_index_name/_analyze
{
"analyzer": "ik_analyzer",
"text": "这是一个测试文档,用来测试中文分词的效果。"
}
// 执行上述命令后,你将看到类似如下的输出:
{
"tokens": [
{
"token": "这是",
"start_offset": 0,
"end_offset": 2,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "一个",
"start_offset": 2,
"end_offset": 4,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "测试",
"start_offset": 4,
"end_offset": 6,
"type": "<ALPHANUM>",
"position": 3
},
{
"token": "文档",
"start_offset": 6,
"end_offset": 8,
"type": "<ALPHANUM>",
"position": 4
},
{
"token": "用来",
"start_offset": 9,
"end_offset": 11,
"type": "<ALPHANUM>",
"position": 5
},
{
"token": "测试",
"start_offset": 11,
"end_offset": 13,
"type": "<ALPHANUM>",
"position": 6
},
{
"token": "中文",
"start_offset": 13,
"end_offset": 15,
"type": "<ALPHANUM>",
"position": 7
},
{
"token": "分词",
"start_offset": 15,
"end_offset": 17,
"type": "<ALPHANUM>",
"position": 8
},
{
"token": "效果",
"start_offset": 17,
"end_offset": 19,
"type": "<ALPHANUM>",
"position": 9
}
]
}
查询示例
GET your_index_name/_search
{
"query": {
"match": {
"content": "测试文档"
}
}
}
//这将返回包含词语“测试文档”的所有文档。
注意事项
- 选择合适的分词模式:
根据你的需求选择合适的分词模式。ik_max_word 适合需要尽可能多的分词结果的场景,而 ik_smart 更适合需要合理分词结果的场景 - 性能考虑:
分词器的选择和配置会影响索引和搜索的性能。选择合适的分词器并合理配置可以提高查询效率。 - 自定义字典
如果需要更精确的分词结果,可以自定义 IK 分词器的字典文件。具体方法可以参考 IK 分词器的文档。