简介
之前在“ARM V2处理器微架构介绍”一文中介绍了面向服务器、云计算等应用的ARM V2处理器微架构,V系列具有更强性能,N系列强调性能和功耗等方向的平衡,本文就将介绍一下ARM N2处理器微架构相比较前代的一些提升。尽管ARM还具备一代N1/V1的服务器端处理器,但严格意义讲N2是ARM相对成熟的第一代服务器端处理器IP。
前端Front-End
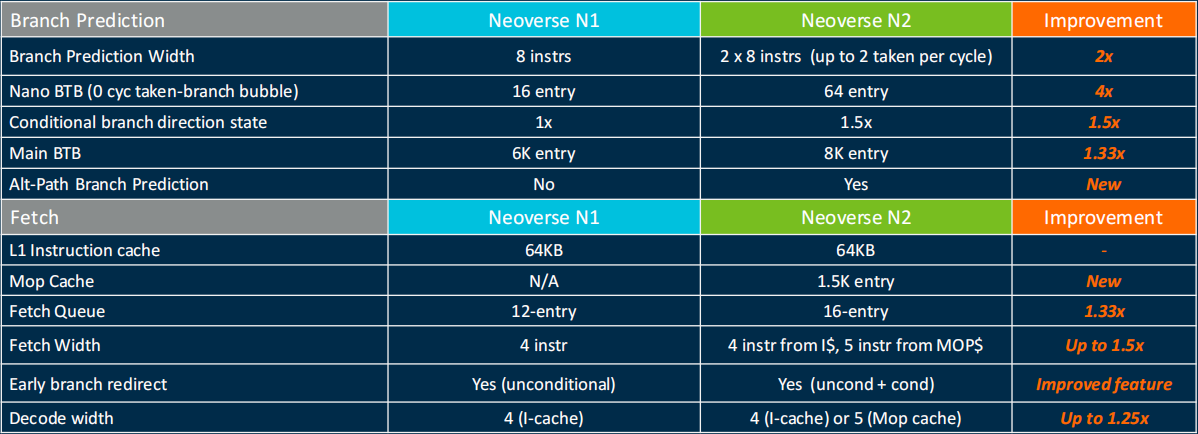
前端的设计相比较前代可以说是巨大提升,预测和取指依然是解耦设计,本代CPU对预测器做了重点的升级。
预测器方面,原来的8instrs/cycle提升为2x8instrs/cycle,每个周期可以处理2个分支,相对应的分支执行也是每个周期处理2个分支。这个特性属于一个相对复杂的实现,AMD的Zen4 Epyc也是同样实现了这个特性,具体的实现方案没有查到更多的资料,最近亦安有进展会写文章讨论一下。
BTB方面,NanoBTB是由原来的16 entries提升到64 entries,早期的快速重定向能力有比较大的提升。Main BTB的大小由6K entries提升到8K entries,并且延迟更低,分支目标tagged关联了上下文以强化安全问题。
ICache是64KB,4路组相联,依然是VIPT组织结构,校验方式是奇偶,Cache line是64bytes。值得一提的是Mop Cache,这个是首次在服务器端使用该特性,在手机端是A77开始具有该特性,主要为了绕过decode快速进入下一个模块。具有1536 entries,4-way skewed组相联,VIVT的组织结构,Cache替换算法PLRU,公开资料显示Mop Cache命中率有85%,命中率还不错。不过不管是服务器还是移动端,这个特性都被舍弃了,服务器是N3/V3放弃的,移动端应该是X4放弃的。
Fetch Queue从原来的12 entries提升到16 entries,decode宽度4(ICache)5(Mop Cache)
Mid-Core & Back-End
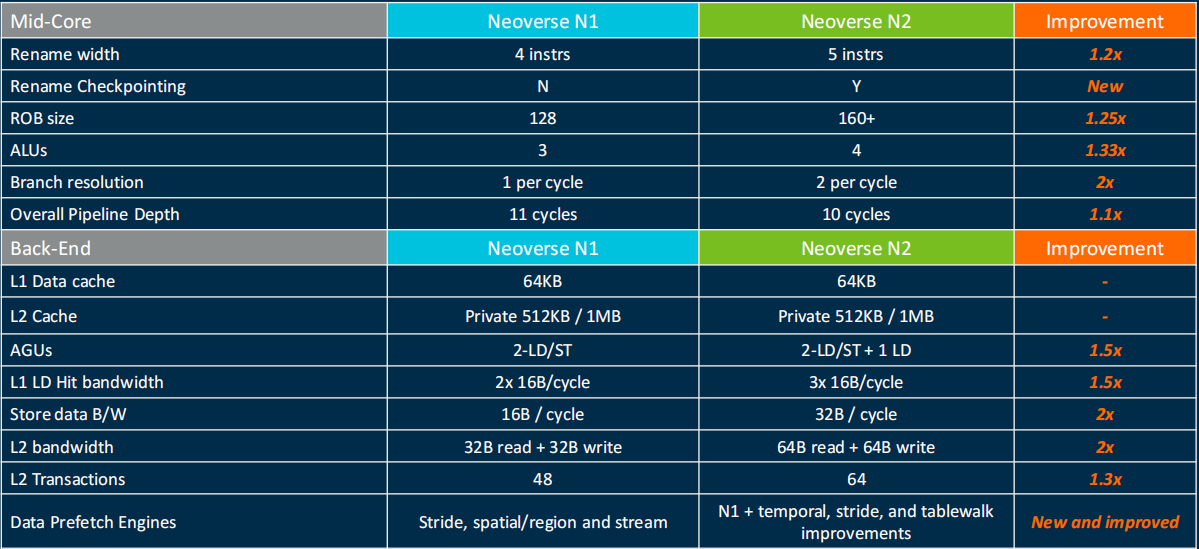
rename宽度由4instrs提升到5instrs,增加了checkpointing,ROB也由128提升到160,ALU从3提升到4,降低了分支预测错误惩罚,从11cycle降到10cycle。
L1 Dcache 64KB,4-way组相联,使用VIPT的组织方式,校验方式是ECC,替换算法是PLRU,后面一代的N3改为RRIP。具有2-LD/ST和1-LD。L2的带宽翻倍,变为64B读+64B写。预取引擎也有所优化,例如Temporal预取器可以预取任意的、重复的访问模式,以加速使用时间流的工作负载。
关于CCS
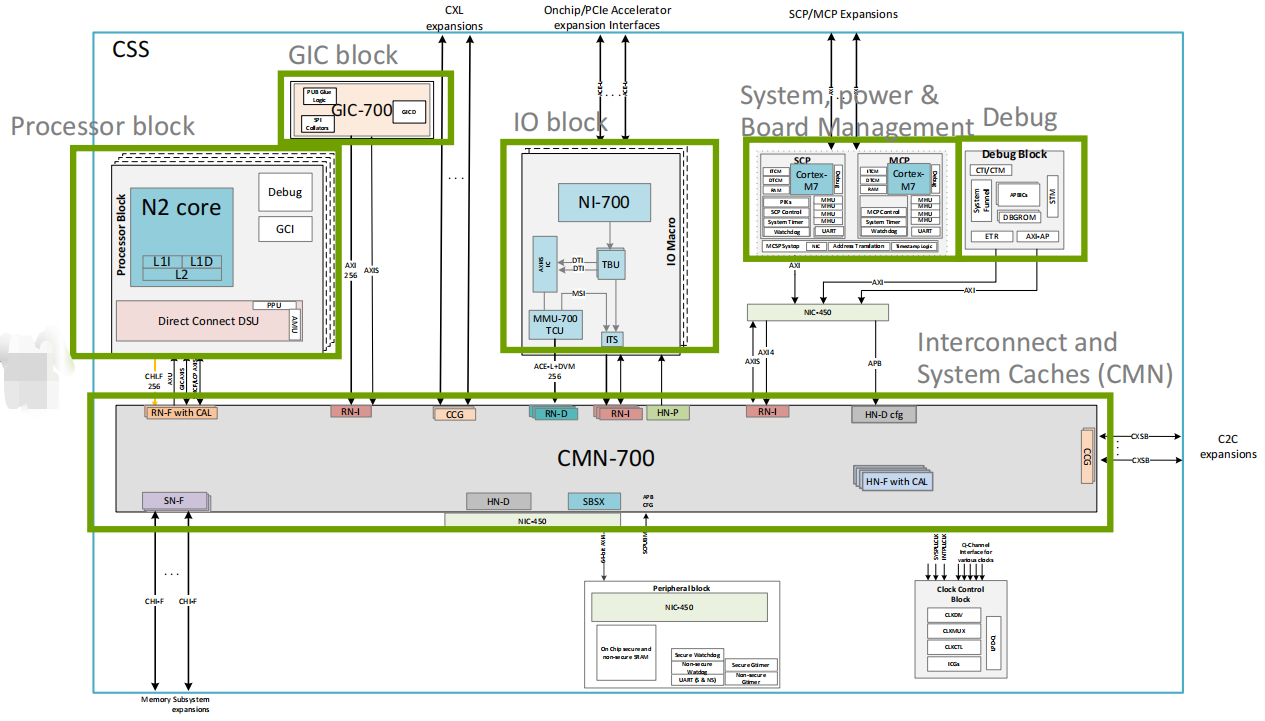
N2的一个其它重点就是加入CCS,对用户而言搭建复杂系统更加便捷,不过这不是本文的重点,简单描述。互联系统升级为CMN700,各种连接口实际都升级到下一代,但互联属于核心关键技术。
总结
ARM N2还是属于比较经典的一代CPU,不少的公司都在使用,其很多微架构的设计都比较有趣,很多特新大家也可以参考相关的论文研究。



![BUUCTF—[BJDCTF2020]The mystery of ip](https://i-blog.csdnimg.cn/direct/514af8bc867e423f8dea082a8f05be02.png)