本文详细解析了RAG技术,包括其定义、作用、技术架构和检索模块的实现与优化,全面展示了RAG在自然语言处理中的重要性和广泛应用前景。
关注TechLead,复旦AI博士,分享AI领域全维度知识与研究。拥有10+年AI领域研究经验、复旦机器人智能实验室成员,国家级大学生赛事评审专家,发表多篇SCI核心期刊学术论文,上亿营收AI产品研发负责人。
一、RAG的定义和作用
RAG的定义
Retrieval-Augmented Generation(RAG)是一种结合了检索和生成技术的自然语言处理(NLP)模型。该模型由Facebook AI提出,旨在提升生成式模型在处理开放域问答、对话生成等任务中的性能。RAG模型通过引入外部知识库,利用检索模块(Retriever)从大量文档中提取相关信息,并将这些信息传递给生成模块(Generator),从而生成更加准确和有用的回答或文本。
RAG模型的核心思想是通过检索和生成的有机结合,弥补生成模型(如GPT-3、BERT等)在处理知识密集型任务时的不足。传统的生成模型在面对复杂问题时,常常因缺乏足够的知识而生成出错误或无关的回答。而RAG通过检索模块获取相关的背景信息,能够在生成过程中参考这些信息,生成更具可信度和准确性的答案。
RAG的工作原理
RAG模型的工作流程可以分为两个主要阶段:检索阶段和生成阶段。
检索阶段
在检索阶段,RAG模型首先接收输入的查询(如用户提问),然后通过检索模块从预定义的知识库中查找与查询相关的文档或段落。这一步骤通常涉及到高效的向量搜索技术,如基于BERT的向量化方法,将文档和查询映射到相同的向量空间中,从而能够快速计算出文档与查询的相似度。检索模块会返回若干个与查询最相关的文档,这些文档将作为生成阶段的输入。
生成阶段
在生成阶段,RAG模型将检索到的文档和原始查询一起输入到生成模块中。生成模块通常是一个强大的生成模型,如T5或BART,它将利用检索到的文档信息生成最终的回答或文本。在这一过程中,生成模块能够参考检索到的背景信息,从而生成内容更加丰富、信息更加准确的回答。
RAG的优势

RAG模型相较于传统的生成模型,具有以下几个显著的优势:
-
知识丰富性:通过引入检索模块,RAG能够在生成过程中参考大量的外部文档,极大地丰富了模型的知识基础,从而生成出更具深度和准确性的回答。
-
动态更新:检索模块使用的是预定义的知识库,这意味着RAG模型能够随时更新知识库内容,而无需重新训练生成模型。这样可以保证生成的答案始终基于最新的信息。
-
高效性:尽管RAG需要进行检索操作,但现代向量搜索技术和高效的生成模型使得整个过程仍然能够在较短时间内完成,保证了实用性。
-
多样性:RAG通过多文档检索和参考,可以生成多样性更高的回答,从而提升用户体验。
RAG的应用场景
RAG技术在多个领域中展现了其强大的应用潜力,以下是一些典型的应用场景:
开放域问答
在开放域问答任务中,RAG通过检索相关文档并生成基于这些文档的回答,能够处理范围更广、问题更复杂的用户提问,提供更精确和全面的答案。
对话生成
在对话系统中,RAG能够利用检索到的上下文信息生成更连贯和自然的对话内容,从而提升对话系统的智能化水平和用户满意度。
信息抽取
RAG还可以用于信息抽取任务,通过检索相关文档并生成包含关键信息的文本,帮助用户快速获取所需的信息。
知识图谱构建
RAG模型能够从大量文档中提取并生成结构化的信息,有助于构建和扩展知识图谱,为各类知识密集型应用提供支持。
二、RAG的技术架构
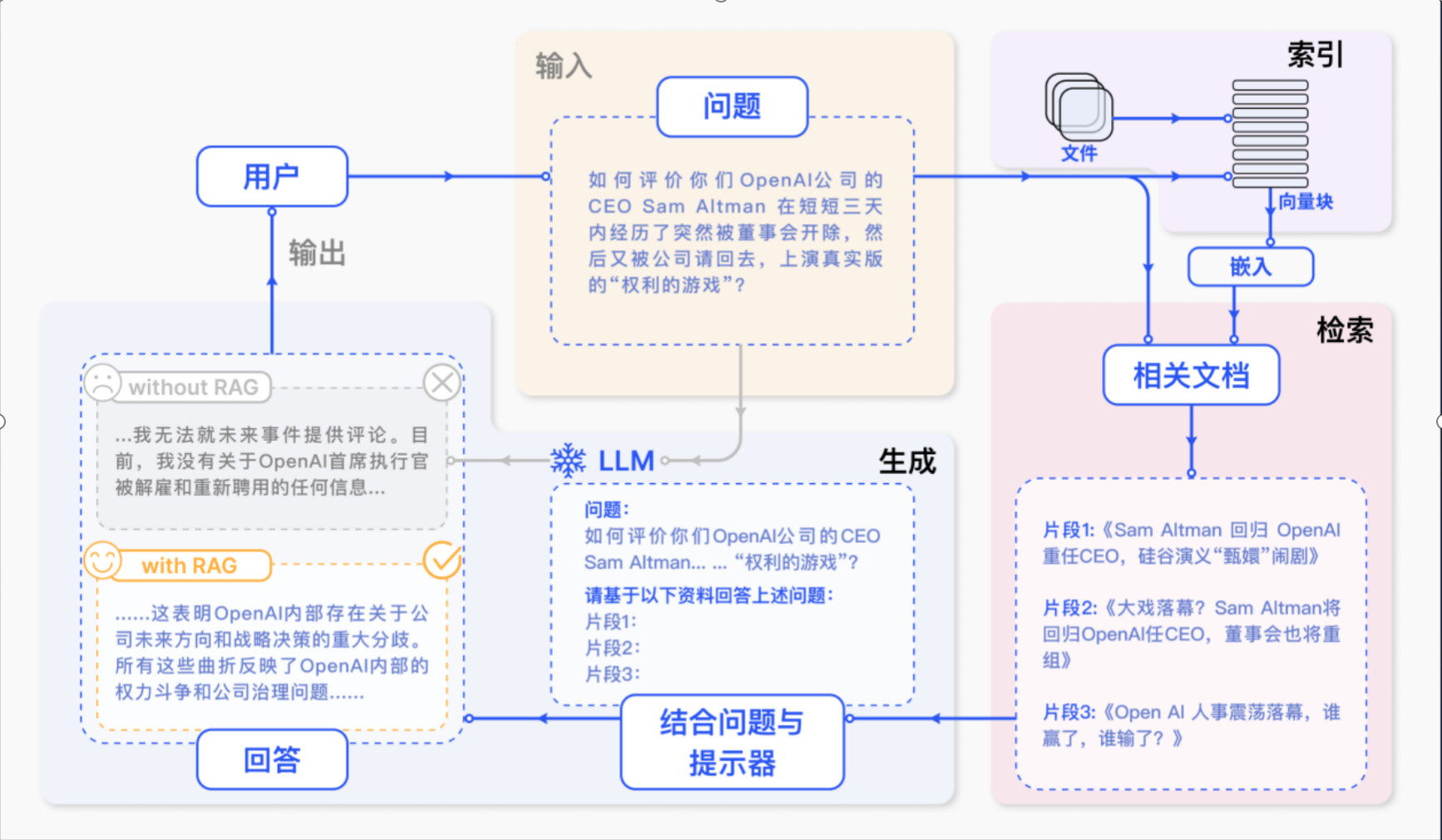
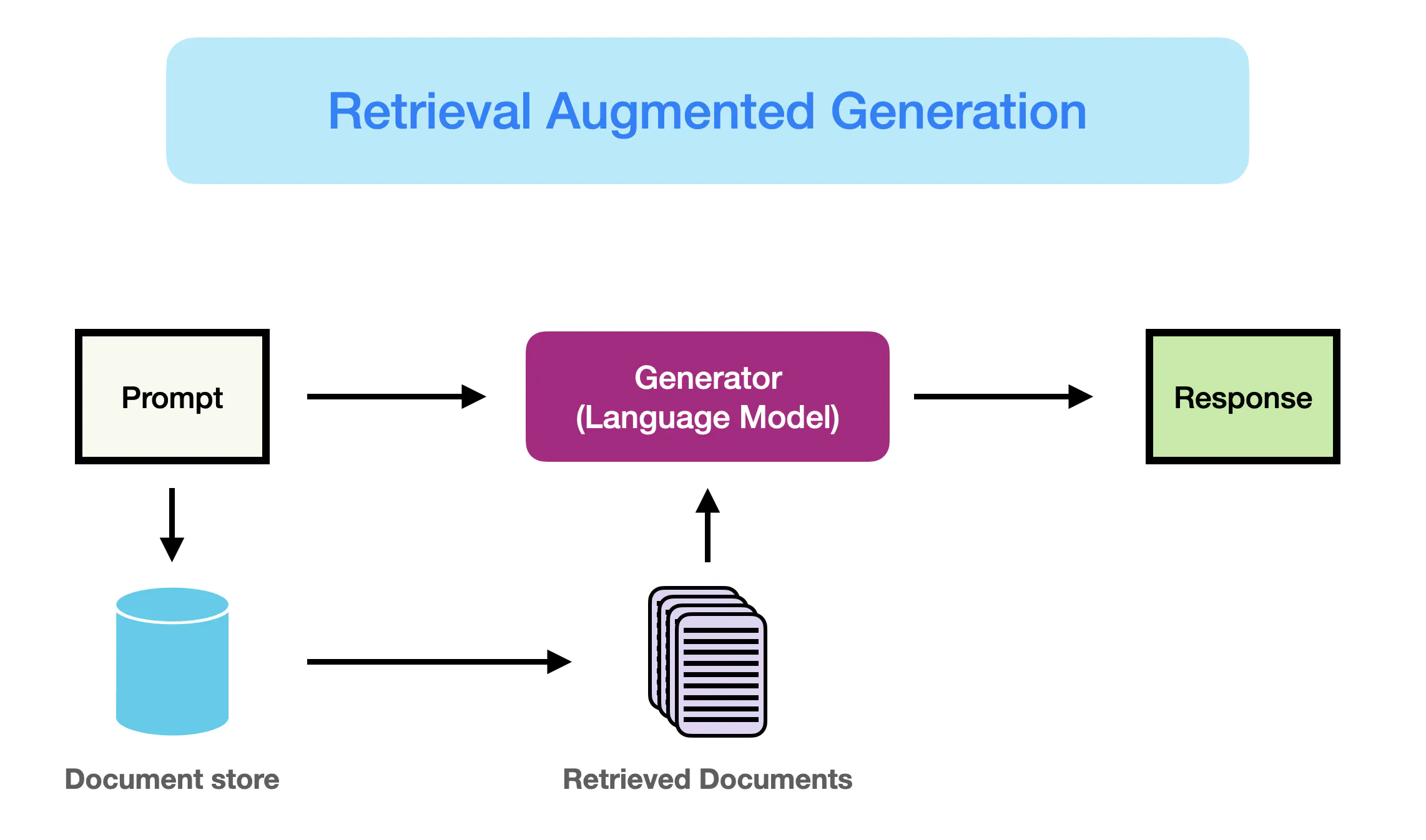
RAG模型整体架构
RAG(Retrieval-Augmented Generation)模型的技术架构包括两个主要部分:检索模块(Retriever)和生成模块(Generator)。这两个模块通过一个统一的框架无缝集成,以实现高效的检索和生成任务。
-
检索模块(Retriever):
- 负责从大规模的知识库或文档集合中检索与输入查询相关的信息。
- 使用预训练的双塔模型(dual-encoder)进行高效的向量化检索。
- 输出若干个与查询相关的文档或段落,作为生成模块的输入。
-
生成模块(Generator):
- 负责根据检索到的文档和输入查询生成最终的回答或文本。
- 使用强大的生成模型(如T5或BART)对输入进行处理。
- 输出连贯、准确且信息丰富的生成内容。
技术架构图
以下是RAG模型的技术架构图,展示了检索模块和生成模块的工作流程:
输入查询
│
▼
检索模块
│
├──> 文档1
│
├──> 文档2
│
└──> 文档n
│
▼
生成模块
│
▼
输出回答
检索模块(Retriever)
双塔模型(Dual-Encoder)
检索模块使用双塔模型进行高效的向量化检索。双塔模型由两个独立的编码器组成,一个用于编码查询,另一个用于编码文档。这两个编码器将查询和文档映射到相同的向量空间中,以便进行相似度计算。
查询编码器
查询编码器(Query Encoder)接收输入的查询,并将其转换为一个固定维度的向量。常用的查询编码器是基于BERT或其变种的模型。
from transformers import BertModel, BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
query = "What is the capital of France?"
inputs = tokenizer(query, return_tensors='pt')
query_vector = model(**inputs).last_hidden_state.mean(dim=1)
文档编码器
文档编码器(Document Encoder)将预定义知识库中的文档逐一编码成向量。为了提高检索效率,这些向量通常会预先计算并存储起来。
documents = ["Paris is the capital of France.", "Berlin is the capital of Germany.", ...]
document_vectors = []
for doc in documents:
inputs = tokenizer(doc, return_tensors='pt')
doc_vector = model(**inputs).last_hidden_state.mean(dim=1)
document_vectors.append(doc_vector)
向量检索
通过计算查询向量与文档向量之间的余弦相似度,检索模块能够快速找到与查询最相关的文档。
import torch
def cosine_similarity(vec1, vec2):
return torch.nn.functional.cosine_similarity(vec1, vec2)
similarities = [cosine_similarity(query_vector, doc_vec) for doc_vec in document_vectors]
top_k_docs = sorted(zip(documents, similarities), key=lambda x: x[1], reverse=True)[:k]
生成模块(Generator)
生成模型
生成模块使用强大的生成模型(如T5或BART)根据检索到的文档和输入查询生成最终的回答。这些生成模型已经在大规模数据上进行预训练,并且在生成自然语言文本方面表现出色。
输入处理
生成模块接收检索模块输出的若干个文档和原始查询,将它们拼接成一个序列,作为生成模型的输入。
from transformers import T5ForConditionalGeneration, T5Tokenizer
tokenizer = T5Tokenizer.from_pretrained('t5-base')
model = T5ForConditionalGeneration.from_pretrained('t5-base')
input_text = query + " ".join([doc for doc, _ in top_k_docs])
inputs = tokenizer(input_text, return_tensors='pt')
文本生成
生成模型根据输入生成最终的回答或文本。
outputs = model.generate(**inputs, max_length=50)
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
多文档融合
为了提高回答的准确性和信息丰富性,生成模块通常会融合多个检索到的文档进行生成。这种多文档融合策略能够综合不同文档中的信息,生成更加全面和准确的回答。
RAG的训练流程
RAG模型的训练流程包括两个主要阶段:预训练和微调。
预训练
在预训练阶段,检索模块和生成模块分别在大规模语料上进行预训练。检索模块使用双塔模型架构进行向量化检索的预训练,而生成模块在大量文本数据上进行生成任务的预训练。
微调
在微调阶段,RAG模型在特定任务的数据集上进行微调,使得模型能够更好地适应具体任务的需求。微调过程中,检索模块和生成模块可以联合训练,以优化整个模型的性能。
# Example of fine-tuning process (pseudocode)
for batch in dataloader:
query, target = batch['query'], batch['target']
doc_vectors = retriever(query)
generated_text = generator(query, doc_vectors)
loss = compute_loss(generated_text, target)
optimizer.step(loss)
三、RAG检索精讲
概述
在RAG(Retrieval-Augmented Generation)模型中,检索模块(Retriever)承担着从大规模文档集合中快速提取与输入查询相关的信息的关键任务。检索模块的性能直接影响RAG模型的整体效果,因此深入理解其工作原理、技术实现和优化策略是非常重要的。本章将详细解析RAG检索模块的各个方面,包括其架构、实现细节、优化方法以及实际应用中的注意事项。
检索模块架构
RAG的检索模块通常采用双塔模型(Dual-Encoder)架构,由两个独立的编码器组成:一个用于编码查询(Query Encoder),另一个用于编码文档(Document Encoder)。这两个编码器将查询和文档分别映射到相同的向量空间中,从而可以通过计算它们之间的相似度来实现高效的检索。
双塔模型的工作原理
- 查询编码器(Query Encoder):接收输入查询,并将其编码为一个固定维度的向量。
- 文档编码器(Document Encoder):将预定义知识库中的每个文档编码为一个向量。
- 相似度计算:通过计算查询向量与所有文档向量之间的相似度,找到与查询最相关的文档。
向量表示
向量表示是双塔模型的核心,通过预训练的语言模型(如BERT、RoBERTa等)将文本映射到高维向量空间。向量的质量直接影响检索的效果,因此选择合适的预训练模型和向量表示方法至关重要。
检索模块实现
查询编码
查询编码器将输入查询转换为向量。常见的实现方法是使用预训练的BERT模型进行编码。以下是使用Python和PyTorch的实现示例:
from transformers import BertTokenizer, BertModel
# 加载预训练的BERT模型和分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# 输入查询
query = "What is the capital of France?"
inputs = tokenizer(query, return_tensors='pt')
# 获取查询的向量表示
query_vector = model(**inputs).last_hidden_state.mean(dim=1)
文档编码
文档编码器将知识库中的每个文档编码为向量。这一步通常在离线阶段进行,以便在检索时可以快速计算相似度。
documents = ["Paris is the capital of France.", "Berlin is the capital of Germany.", ...]
document_vectors = []
# 编码每个文档
for doc in documents:
inputs = tokenizer(doc, return_tensors='pt')
doc_vector = model(**inputs).last_hidden_state.mean(dim=1)
document_vectors.append(doc_vector)
向量检索
检索阶段通过计算查询向量与文档向量之间的相似度,找到与查询最相关的文档。常用的相似度度量是余弦相似度。
import torch
# 计算余弦相似度
def cosine_similarity(vec1, vec2):
return torch.nn.functional.cosine_similarity(vec1, vec2)
# 找到最相关的文档
similarities = [cosine_similarity(query_vector, doc_vec) for doc_vec in document_vectors]
top_k_docs = sorted(zip(documents, similarities), key=lambda x: x[1], reverse=True)[:k]
优化策略
为了提升检索模块的性能,通常需要进行以下优化:
向量化技术
- 使用高效的向量化算法:采用高效的向量化算法,如Faiss、Annoy等,可以显著提升向量检索的速度和准确性。
- 减少向量维度:通过主成分分析(PCA)等方法减少向量维度,可以在保持性能的同时减少计算开销。
数据预处理
- 文本标准化:对输入查询和文档进行标准化处理,如去除停用词、词干提取等,可以提高检索的准确性。
- 数据增强:通过数据增强技术生成更多的训练数据,有助于提升模型的鲁棒性和泛化能力。
模型优化
- 联合训练:在微调阶段,联合训练查询编码器和文档编码器,可以进一步优化它们在特定任务上的性能。
- 知识蒸馏:通过知识蒸馏,将大模型的知识迁移到小模型中,可以在保证性能的同时减少模型的计算开销。
实际应用中的注意事项
- 知识库的更新:知识库内容需要定期更新,以保证检索模块能够提供最新的信息。更新频率应根据具体应用场景的需求来确定。
- 向量存储和检索:大规模向量的存储和检索需要高效的数据库和检索系统支持,如Elasticsearch、Milvus等。
- 性能评估:定期对检索模块的性能进行评估,使用适当的指标(如MRR、Recall等)来衡量其检索效果,并据此进行优化。