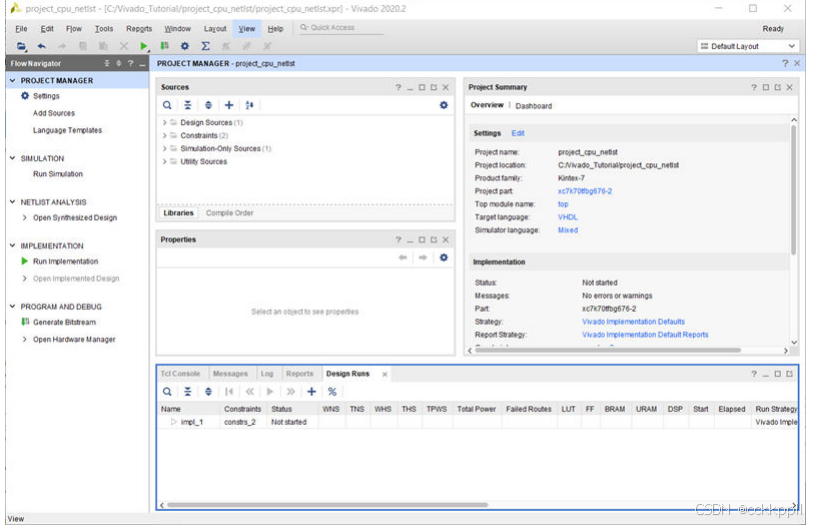
在Spark程序结束之后我们也想看到运行过程怎么办?
Yarn模式下,通过以下步骤配置历史服务器即可:
mv spark-defaults.conf.template spark-defaults.conf- 修改spark-default.conf 文件,配置日志存储路径
spark.eventLog.enabled true
spark.eventLog.dir hdfs://master:9000/directory
注意:需要启动hadoop集群;如果directory不存在,先用如下命令创建
hdfs dfs -mkdir /directory或hadoop dfs -mkdir /directory或hadoop fs -mkdir directory
这里的端口号和Hadoop的core-site.xml中fs.defaultFS的路径保持一致
3. 修改spark-env.sh文件,配置日志
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://master:9000/directory
-Dspark.history.retainedApplications=30"
WEB UI访问的端口号
指定历史服务器日志存储路径
指定Application历史纪录的保存个数,这个是内存中的应用数,不是页面上显示的应用数
- 修改 spark-defaults.conf
spark.yarn.historyServer.address=master:18080
spark.history.ui.port=18080
- 启动历史服务
sbin/start-history-server.sh
- 用spark-submit提交任务
- Web页面查看日志:http://master:8088

- 点击history之后:













![[Algorithm][综合训练][kotori和n皇后][取金币][矩阵转置]详细讲解](https://i-blog.csdnimg.cn/direct/ea5089a6fd844206afd37583023865b2.png)