时序领域又有新突破啦!谷歌最新提出TimesFM,仅需200M参数,零样本预测性能超越有监督!成功入选ICML 2024!
TimesFM是一种全新的时间序列通用基础模型,这类模型相比传统时序模型,拥有整合和利用广泛知识库的能力,在处理复杂、非线性、非平稳的时序数据时性能更高,能给我们提供更高精度的预测结果。
因此在时序领域,关于通用基础模型的研究非常火热,不仅是TimesFM,还有很多效果很赞的研究被顶会收录,实力证明这是个发论文的好方向。
目前这个方向主流的研究路线是从头开始预训练时序基础模型,建议想发论文的同学从这个角度入手,如果感觉没思路,可以看我整理好的8篇时间序列通用基础模型论文作参考,都是最新且高质量,代码基本都有。
论文原文+开源代码需要的同学看文末
A decoder-only foundation model for time-series forecasting
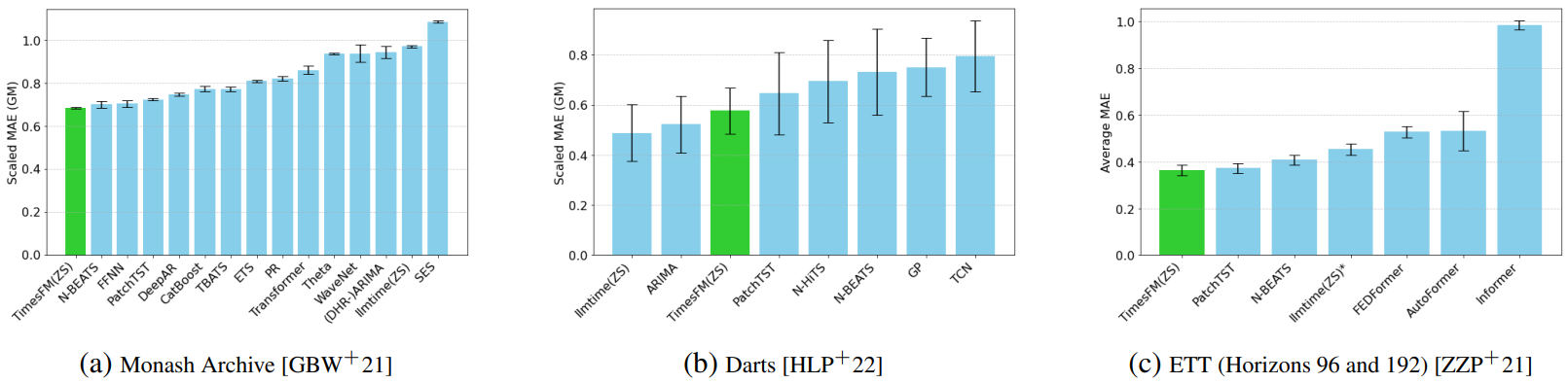
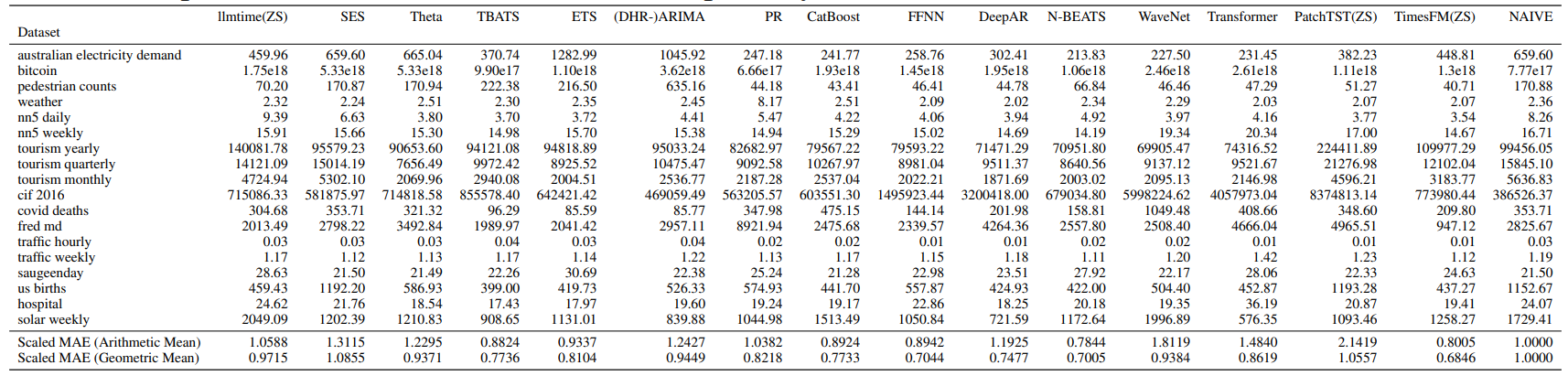
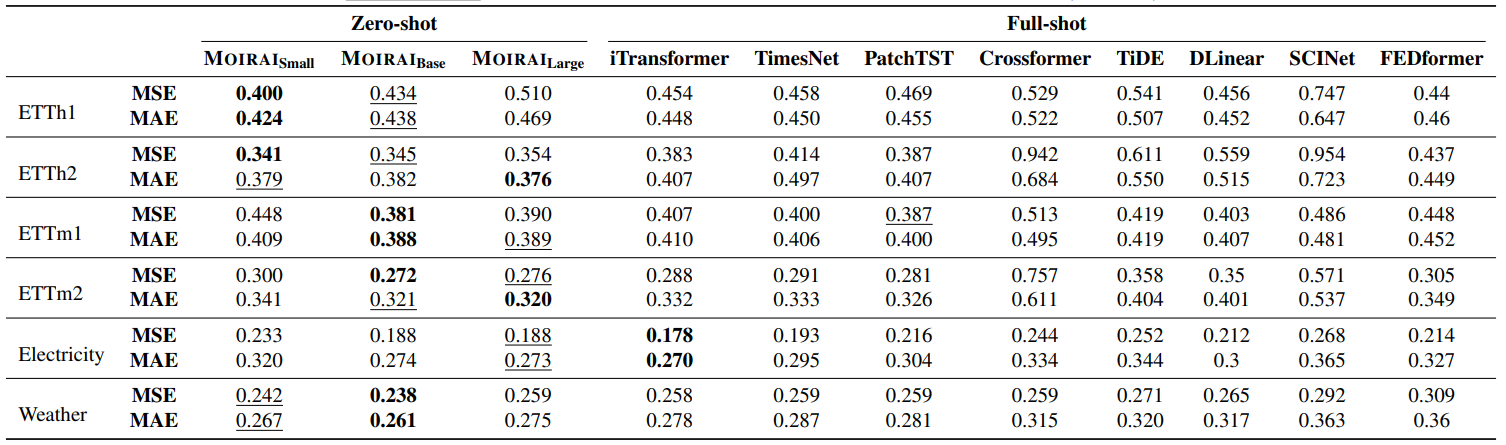
方法:论文介绍了TimesFM,一个用于时间序列预测的实用基础模型,其零-shot表现接近于完全监督的预测模型的准确性,并在各种时间序列数据上进行了预训练。该模型的预训练数据集包括1000亿个时间点的真实世界和合成数据集。
创新点:
-
TimesFM是一种基于预训练的时间序列基础模型,具有接近最先进的有监督预测模型的零-shot性能。
-
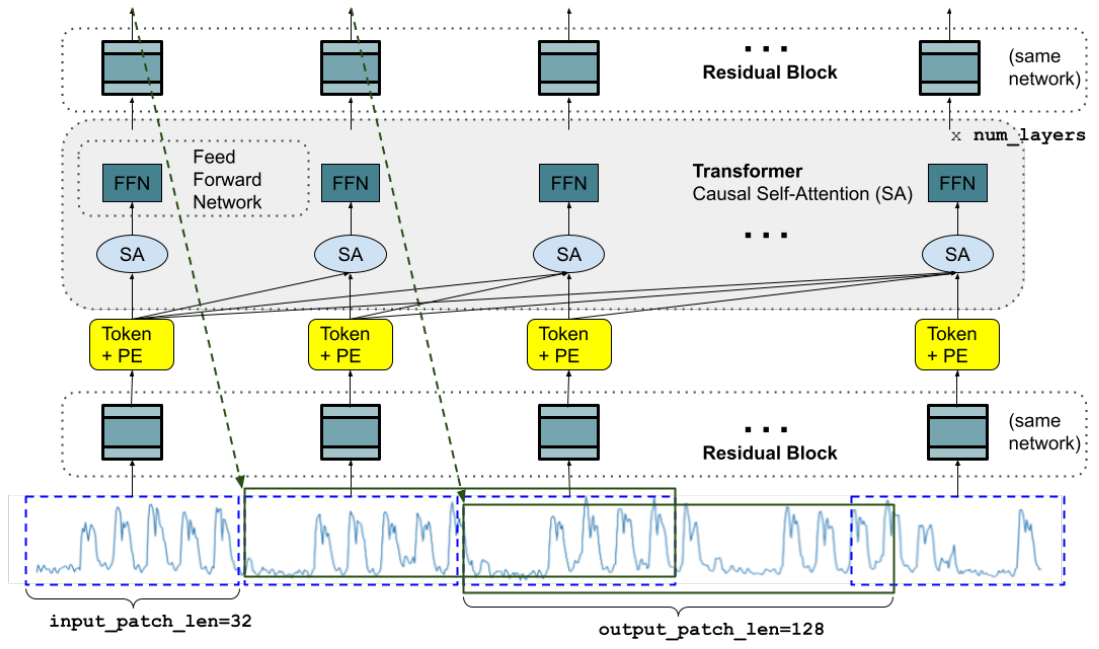
TimesFM的模型架构是基于解码器-只有模型,采用了输入分块和较长的输出分块的设计。
-
TimesFM在多个公开数据集上进行了零-shot评估,并且在准确度上超过了其他基线模型。
Unified Training of Universal Time Series Forecasting Transformers
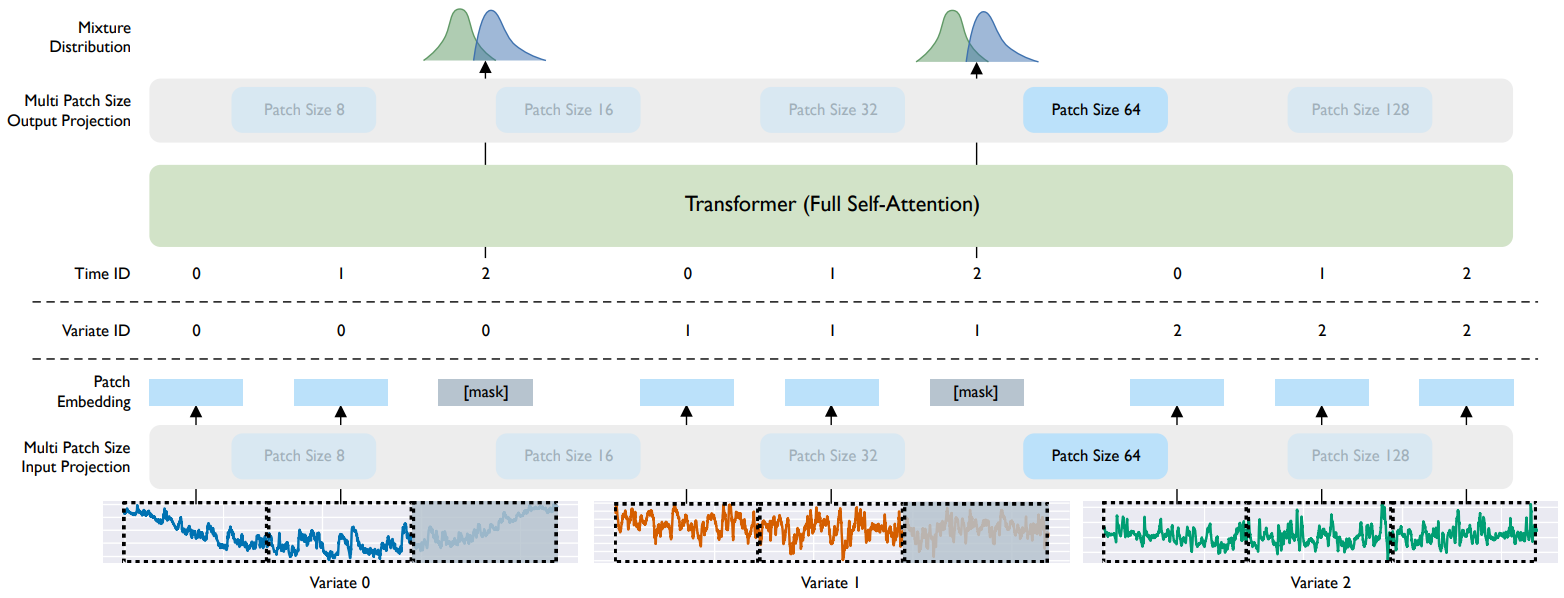
方法:本文介绍了一个名为MOIRAI的基于掩码编码器的通用时间序列预测Transformer,旨在解决通用预测范式中遇到的问题。研究者引入了LOTSA,这是一个用于预训练时间序列预测模型的最大开放数据集合。MOIRAI在分布内和分布外的设置下进行评估,并能够进行概率和长序列预测。
创新点:
-
提出了在预训练的基础上进行微调的方法,以提高时间序列预测的性能和数据效率。此方法能够在不同数据集和任务上进行泛化和适应,从而实现更广泛的应用。
-
提出了一个新的大规模时间序列数据集,其中包含来自九个领域的超过270亿个观测数据。通过使用这个数据集对模型进行训练,作者的模型在零样本预测任务上取得了竞争性或优越的性能。
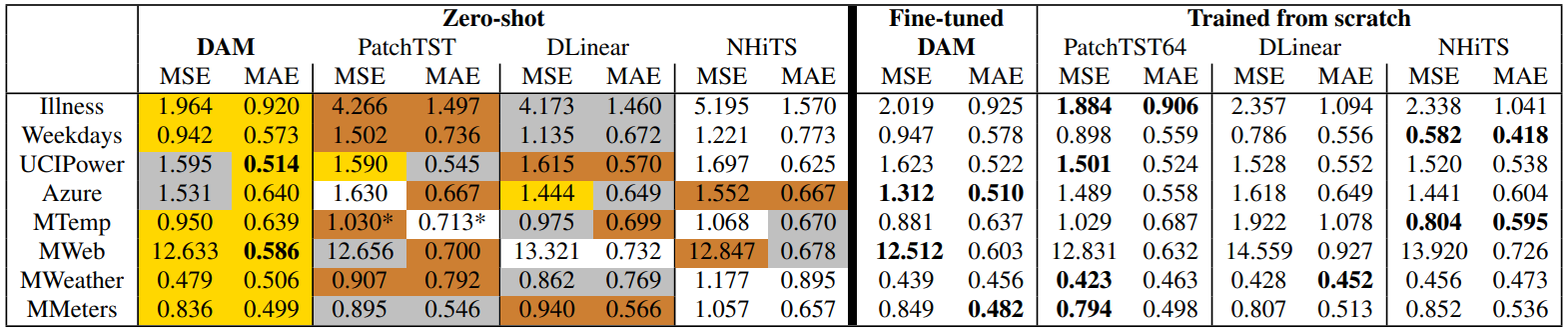
DAM: Towards A Foundation Model for Time Series Forecasting
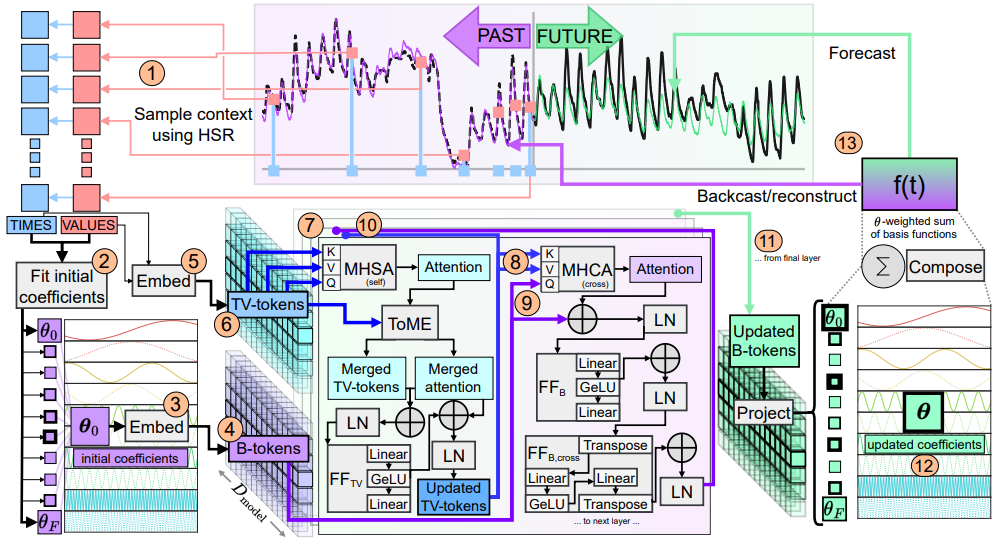
方法:论文介绍了一种称为DAM的深度数据依赖近似分析模型,它是一种通用的时间序列预测基础模型,可以同时适用于多个不同的数据集和领域,并能够根据不同的预测需求进行灵活调整。
创新点:
-
DAM是第一个可在各种不同的领域和数据集上进行准确预测的通用时间序列预测模型,可以在训练集内外都有良好的泛化能力。
-
DAM使用了灵活的历史采样策略,可以高效地获取过去的全局信息,并保持对最近历史的关注。这种采样策略使得DAM能够在不同的数据集上进行预测,而不受固定长度和定期采样的限制。
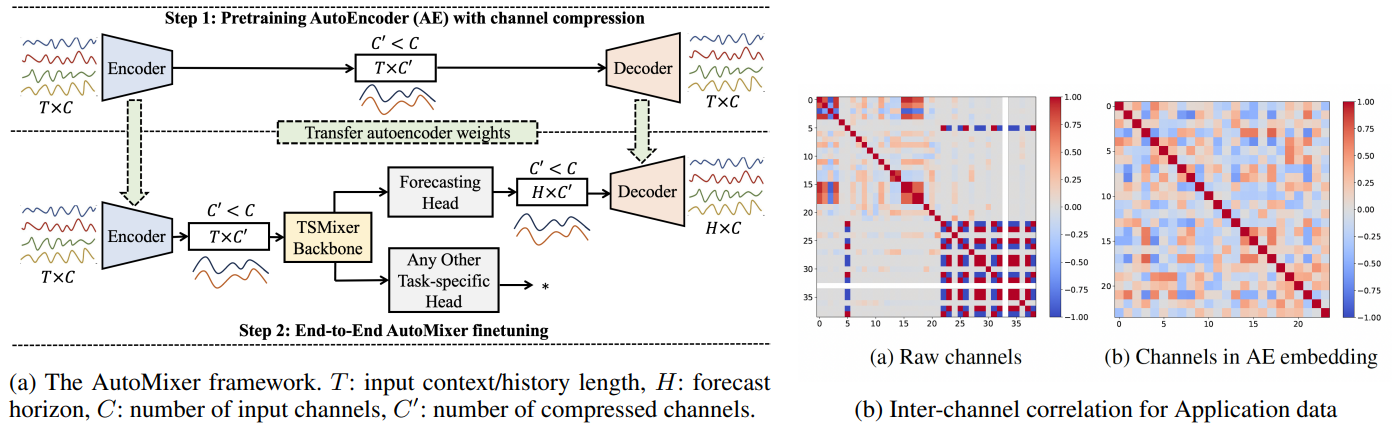
Automixer for improved multivariate time-series forecasting on business and it observability data
方法:论文提出了一个通用时序预测基础模型,名为AutoMixer。这个模型专注于业务关键绩效指标(Biz-KPIs)的预测,这些指标可能会受到IT故障的负面影响。在商业和IT可观测性(BizITObs)数据中,Biz-KPIs和IT事件通道被融合在一起,形成了多变量时序数据。
创新点:
-
AutoMixer是一种新颖的时间序列基础模型,通过利用AutoEncoder和TSMixer的组合能力,对BizITObs数据进行改进的多变量时间序列预测。
-
AutoMixer利用压缩通道空间中的压缩通道的威力,简化了通道相关性任务,显著提高了TSMixer在压缩通道空间中的性能,从而实现了更准确的预测。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“时序基础”获取全部论文+开源代码
码字不易,欢迎大家点赞评论收藏