文章目录
- 一 . get 和 set
- 二 . keys *
- 三 . exists
- 四 . del
- 五 . expire
- 六 . ttl
- 七 . Redis 的 key 的过期策略
- 八 . 定时器的实现
- 8.1 基于优先级队列
- 8.2 基于时间轮实现的定时器
- 九 . type
- 十 . 数据库管理相关命令
Hello , 大家好 , 这个专栏给大家带来的是 Redis 系列 ! 本篇文章给大家带来的是 Redis 一些最基础的命令 , 那这些命令并没有涉及到 Redis 核心数据结构 , 只是简单的操作键值对 , 难度相对更简单一些 .
本专栏旨在为初学者提供一个全面的 Redis 学习路径,从基础概念到实际应用,帮助读者快速掌握 Redis 的使用和管理技巧。通过本专栏的学习,能够构建坚实的 Redis 知识基础,并能够在实际学习以及工作中灵活运用 Redis 解决问题 .
专栏地址 : Redis 入门实践

一 . get 和 set
get 和 set 是 Redis 中最核心的两个命令
Redis 是按照键值对的方式存储数据的 , 那 get 就是根据 key 去取 value , set 就是把 key 和 value 存储进去
注意 : 必须要先进入到 Redis 客户端 : redis-cli , 才能进行后续操作
set 的语法 : set key value , 其中 key 和 value 都是字符串
127.0.0.1:6379> set key1 value1 # 存储键值对
OK
127.0.0.1:6379> set "key2" "value2" # key 和 value 默认是字符串,我们也可以手动加上引号
OK
对于上面的 key 和 value , 我们并不需要手动加上引号 , 他默认表示的就是字符串 , 加上的话就多此一举了
get 的用法 : get key
127.0.0.1:6379> get key1 # get 命令直接通过 key 就可以找到 value
"value1"
127.0.0.1:6379> get error # 如果当前 key 不存在 , 会返回 nil
(nil)
二 . keys *
Redis 是一个键值对结构 , 那 key 就是固定的字符串 , value 就有很多类型
- 字符串
- 哈希表
- 列表
- 集合
- 有序集合
- …
那我们主要学习的是这几种数据结构中的命令
而 Redis 中还有一些全局命令 , 可以搭配任意一个数据结构来使用
比如 : keys , 他是用来查询当前服务器上匹配的 key
我们就可以通过一些特殊的符号 (通配符) 来描述 key 的模样 , 那如果有匹配上述模样的 key , 就能被查询出来
语法 : keys pattern
pattern 是一个包含特殊符号的字符串 , 它存在的意义就是去描述想要匹配的字符串是长什么样的 (类比正则表达式)
那 pattern 的写法有很多 , 我们来看一下

https://redis.io/commands/keys/
?表示可以匹配任意一个字符
*表示匹配任意个数的字符 (0 个 / 多个)
[ae]表示方括号里面的字母可以被匹配到
比如 : [] 这个位置只能匹配到 a / e , 写的就不行
[^e]表示排除 [] 中的内容
比如 : [^e] 只有 e 匹配不了 , 其他的都能匹配
[a-b]: 匹配 a-b 这个范围内的字符 , 包含两侧边界
那我们就来举个例子 , 了解一下每个通配符的用法
# 设置键值对
127.0.0.1:6379> set hello 1
OK
127.0.0.1:6379> set hallo 2
OK
127.0.0.1:6379> set hbllo 3
OK
127.0.0.1:6379> set hllo 4
OK
127.0.0.1:6379> set heeeeeeeeeeeeeeeeeeeeelo 5
OK
127.0.0.1:6379> keys h?llo # ? 位置匹配任意一个字符
1) "hbllo"
2) "hallo"
3) "hello"
127.0.0.1:6379> keys h*llo # * 位置匹配任意个数个字符
1) "hbllo"
2) "hallo"
3) "hllo"
4) "hello"
127.0.0.1:6379> keys h[abe]llo # [] 位置可以匹配到 a、b、e
1) "hbllo"
2) "hallo"
3) "hello"
127.0.0.1:6379> keys h[^ae]llo # [] 位置匹配不到 a 和 e
1) "hbllo"
127.0.0.1:6379> keys h[a-e]llo # [] 位置可以匹配到 [a,e] 之间的字符
1) "hbllo"
2) "hallo"
3) "hello"
那 keys 这个命令 , 他的时间复杂度是 O(N) , 所以在生产环境中一般都会禁止使用 keys 这个命令
尤其是 keys * , keys * 直接将 Redis 中所有的 key 都会查询出来
那 Redis 通常会被用作缓存 , 也就是说他是挡在 MySQL 前面的 , 那万一 Redis 被 keys * 阻塞住了 , 此时其他的查询 Redis 操作就会超时 , 此时这些请求就会直接查数据库 , 那突然一大波请求过来了 , MySQL 也承受不住压力 , 也会崩溃掉
三 . exists
exists 的作用是判断某个 key 是否存在
语法 : exists key1 [key2 …]
可以查询多个 key 是否存在
他的返回值是给定的 key 存在的个数
他指的是针对多个 key , 判断存在的个数 .
而不是说我们在设置键值对的时候 , key 是可以重复的 , 然后统计同一个 key 对应的 value 的个数
时间复杂度 : O(1) , 但是并不绝对 , 有可能很多数据 , 那时间复杂度就变成了 O(N)
Redis 组织数据就是按照哈希表的方式来组织的 , 所以操作的时间复杂度一般都是 O(1)
127.0.0.1:6379> keys * # 查看所有键值对
1) "heeeeeeeeeeeeeeeeeeeeelo"
2) "hbllo"
3) "key2"
4) "hallo"
5) "\xac\xed\x00\x05t\x00\x132023-10-30 04_41_36"
6) "hllo"
7) "key1"
8) "hello"
127.0.0.1:6379> exists hello # 判断某个 key 是否存在
(integer) 1
127.0.0.1:6379> exists hello hbllo # 判断多个 key 是否存在
(integer) 2 # 返回值代表多个 key 存在的个数
127.0.0.1:6379> exists hello nonono # 只返回 key 存在的个数
(integer) 1
❓ 那比如这条语句 : exists hello hbllo , 我们为什么不选择写两次 exists 呢 ?
✔️ Redis 是一个 “客户端-服务器” 结构的程序 , 那客户端和服务器之间是通过网络来进行通信的 . 如果分开多次写 , 就会产生更多次数的网络通信 , 网络通信相比于操作内存效率又低、成本又高 , 所以能够一次传输的话就尽量一次进行传输
四 . del
del 的用途是删除指定的 key , 他也可以一次删除一个或者一次删除多个
语法 : del key1 [key2 …]
时间复杂度 : O(1)
删除 n 个数据 , 那时间复杂度同 exists , 都是 O(N)
返回值 : 删除掉的 key 的个数 , 如果 key 不存在返回 0
127.0.0.1:6379> keys * # 查看当前所有的键
1) "k1"
2) "k4"
3) "k3"
4) "k2"
127.0.0.1:6379> del k1 # 删除键值对
(integer) 1
127.0.0.1:6379> del k2 k3 # 返回值代表删除元素的个数
(integer) 2
127.0.0.1:6379> del notexist # 如果 key 不存在返回 0
(integer) 0
五 . expire
expire 的作用是给指定的 key 设置过期时间 , 如果 key 超过这个指定的时间就会被自动删除
使用场景比如 : 手机验证码、指定时间内有效的优惠券等
语法 : expire key 秒
还有一个命令 , 是 pexpire key 毫秒 , 这个命令将时间更加细化了
时间复杂度 : O(1)
127.0.0.1:6379> set k1 v1
OK
127.0.0.1:6379> expire k1 3 # 设定过期时间 -> 必须针对已经存在的 key 才能设置
(integer) 1 # 设置成功返回 1
127.0.0.1:6379> expire k2 3 # 针对不存在的 key 设置过期时间就会失败
(integer) 0 # 设置失败返回 0
127.0.0.1:6379> expire k1 3 # 到达过期时间自然就会失效, 再去设置就会失败
(integer) 0
六 . ttl
ttl (time to live) 的作用是用来查询过期时间的
127.0.0.1:6379> set k1 v1 # 设置键值对
OK
127.0.0.1:6379> expire k1 10 # 设置过期时间
(integer) 1
127.0.0.1:6379> ttl k1 # 查询过期时间
(integer) 7
127.0.0.1:6379> ttl k1 # 返回值为 -2 代表已经过期
(integer) -2
七 . Redis 的 key 的过期策略
❓ 我们思考一个问题 : Redis 的 key 的过期策略是怎样实现的 ?
一个 Redis 中可能同时存在很多很多 key , 这些 key 中可能有很大一部分都有过期时间 , 此时 Redis 服务器是怎样知道哪些 key 已经过期要被删除 , 哪些 key 还没过期呢 ?
✔️
如果遍历所有的 key , 显然是行不通的 , 它的效率是非常低的 .
那 Redis 整体的策略是两点 :
- 定期删除 : 隔一段时间删除一批过期的 key
- 惰性删除 : 假设这个 key 已经到过期时间了 , 但是暂时不删除他 , 那他的 key 还存在 . 后续再一次访问 , 正好又访问到了这个 key , 于是这次 Redis 服务器就会触发删除操作 , 返回 nil
比如超市卖饮料 , 老板并不知道这个饮料过没过期 , 超市老板就有两种方案
定期删除 : 每隔一段时间就看饮料过没过期
惰性删除 : 有人买的时候再检查过没过期 , 过期了就不卖了
Redis 采取的策略是每次抽取一部分键值对验证过期时间 , 并且要保证抽查的过程足够快
那为什么要让抽查的过程足够快呢 ?
因为 Redis 是单线程的程序 , 主要任务并不是扫描过期的 key , 如果扫描过期的 key 消耗的时间太多 , 就可能导致正常处理请求的命令就被阻塞了
八 . 定时器的实现
定时器指的是在某个时间到达之后 , 执行指定的任务
那定时器的实现有两种思路
- 基于优先级队列
- 基于时间轮实现的定时器
8.1 基于优先级队列
正常的队列是符合先进先出的规则的 , 但是优先级队列则是按照指定的优先级进行先出操作的 .
那优先级一般来说是可以自定义的 , 那在 Redis 中一般就是 “越早过期 , 优先级越高” .
那现在假设有很多 key 设置了过期时间 , 就可以将这些 key 加入到优先级队列中 , 指定过期时间早的先出队列
我们只需要给定时器分配一个线程 , 让这个线程去检查队首元素 , 看一下是否过期即可 , 如果说队首元素还没过期 , 那后续元素就一定没过期 , 此时扫描线程就不需要遍历所有 key , 只需要关注队首元素即可
另外 , 在扫描队首元素过期时间的时候 , 也不能检查的太过于频繁 , 这样会消耗额外的资源 .
那我们的做法就可以在检查队首元素的时候去看一下队首元素的过期时间 , 然后设置等待时间为当前时刻和队首元素的过期时间的差 , 当过期时间到了就去唤醒队首元素这个线程
但是万一在线程休眠的时候 , 来了一个新任务 , 那我们就需要唤醒一下线程 , 重新检查一下队首元素的过期时间以及新任务的过期时间 , 如果新的线程过期时间更小了 , 那就需要将该任务添加到队首 , 并且更新线程阻塞等待的时间
8.2 基于时间轮实现的定时器
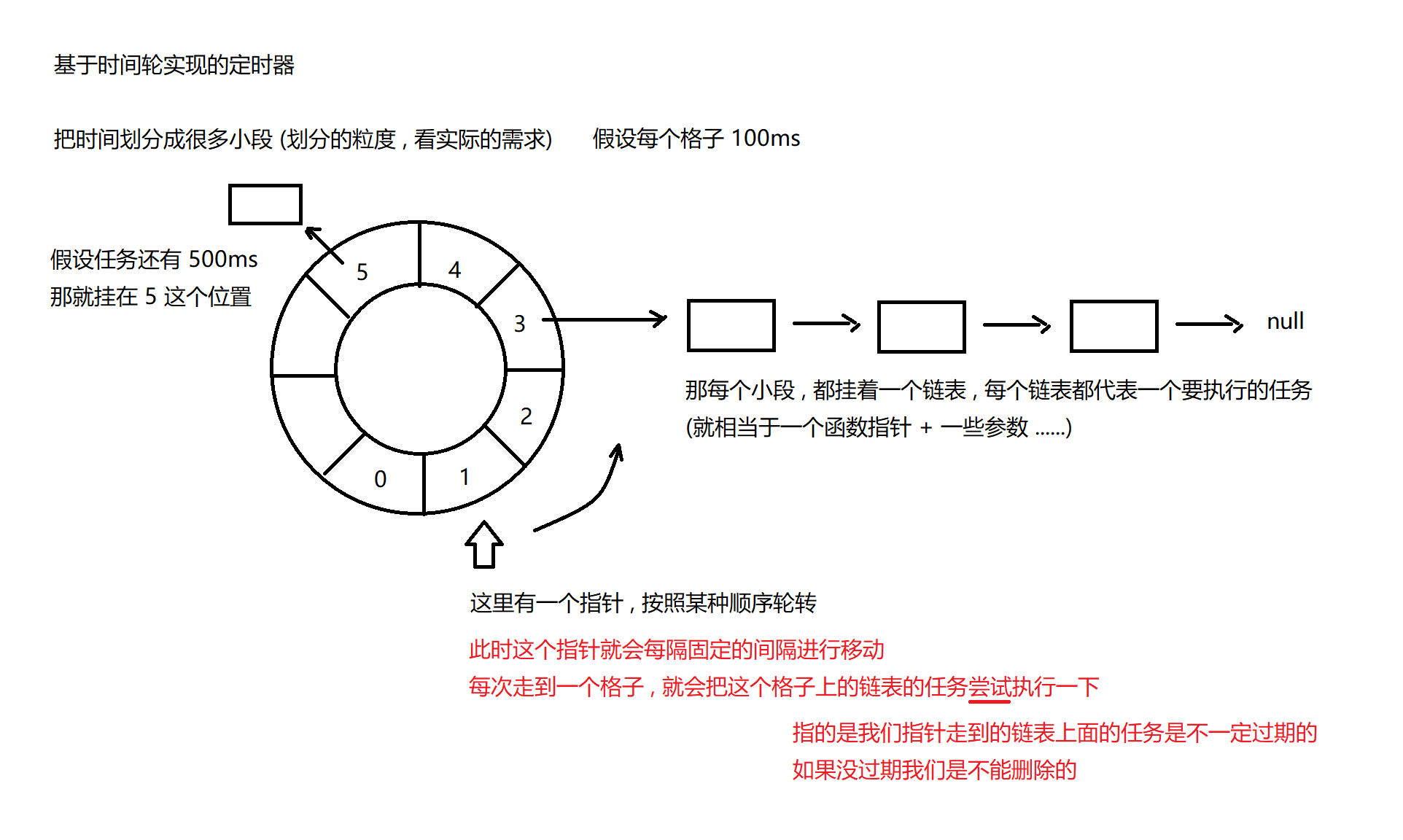
但是 Redis 并没有采取上述的两种方案 , 在这里只是给大家介绍一下
九 . type
type 的作用就是查看 key 对应的 value 的数据类型
Redis 中所有的 key 都是 String 类型 , 而 value 是不同的数据类型
127.0.0.1:6379> set k1 v1 # 设置键值对
OK
127.0.0.1:6379> type k1 # 获取 key 对应的 value 的数据类型
string
127.0.0.1:6379> lpush k2 111 222 333 # 设置列表
(integer) 3
127.0.0.1:6379> type k2 # 获取 key 对应的 value 的数据类型
list
时间复杂度 : O(1)
小结 :
set : 设置键值对
get : 获取键值对
keys : 查看匹配规则的 key
exists : 用来判定指定的 key 是否存在
del : 删除指定的 key
expire : 给 key 设置过期时间
ttl : 查询 key 的过期时间
type : 查询 key 对应的 value 的类型
十 . 数据库管理相关命令
在我们之前学习 MySQL 的时候 , 有一个概念 : database , 一个 MySQL 服务器上可以有很多个 database , 那一个 database 里面还有很多表 .
其实 Redis 中也有 database 这样的概念 , 但是不像在 MySQL 中使用那么随意 , 想创建多少个就多少个 .
在 Redis 中的 database 是现成的 , 我们不能创建新的数据库 , 也不能删除提供的数据库 .
Redis 提供给了我们 16 个数据库 , 编号从 0 到 15 , 那这 16 个数据库之间是相互隔离的 (相互之前都不会有影响) , 默认使用的是 0 号数据库 .
我们可以通过 select dbIndex 来去切换数据库
127.0.0.1:6379> set k1 v1 # 在 0 号数据库中设置键值对
OK
127.0.0.1:6379> get k1 # 在 0 号数据库中能够获取到该键值对
"v1"
127.0.0.1:6379> select 6 # 切换到 6 号数据库
OK
# [6] 表示第 6 号数据库
127.0.0.1:6379[6]> get k1 # 此时就获取不到该键值对了
(nil)
127.0.0.1:6379[6]> select 0 # 此时在切换回 0 号数据库
OK
127.0.0.1:6379> get k1 # 就又可以获取到该键值对了
"v1"
我们还可以通过 dbsize 获取当前数据库中 key 的个数
127.0.0.1:6379> set k1 v1 # 在 0 号数据库设置键值对
OK
127.0.0.1:6379> dbsize # 获取当前数据库的键值对个数
(integer) 1
127.0.0.1:6379> select 6 # 切换到 6 号数据库
OK
127.0.0.1:6379[6]> dbsize # 此时 6 号数据库没设置过任何数据
(integer) 0 # 就会检索到 0 个键值对
接下来就是两个危险又刺激的命令了 : flushdb、flushall
flushdb : 清空当前数据库
flushall : 清空所有数据库
以后在公司中千万不能使用 , 尤其是在生产环境上 , 不然会有很严重的后果 .
对于 Redis 操作键值对的常见命令就已经讲解完毕了 , 如果对你有帮助的话请一键三连~