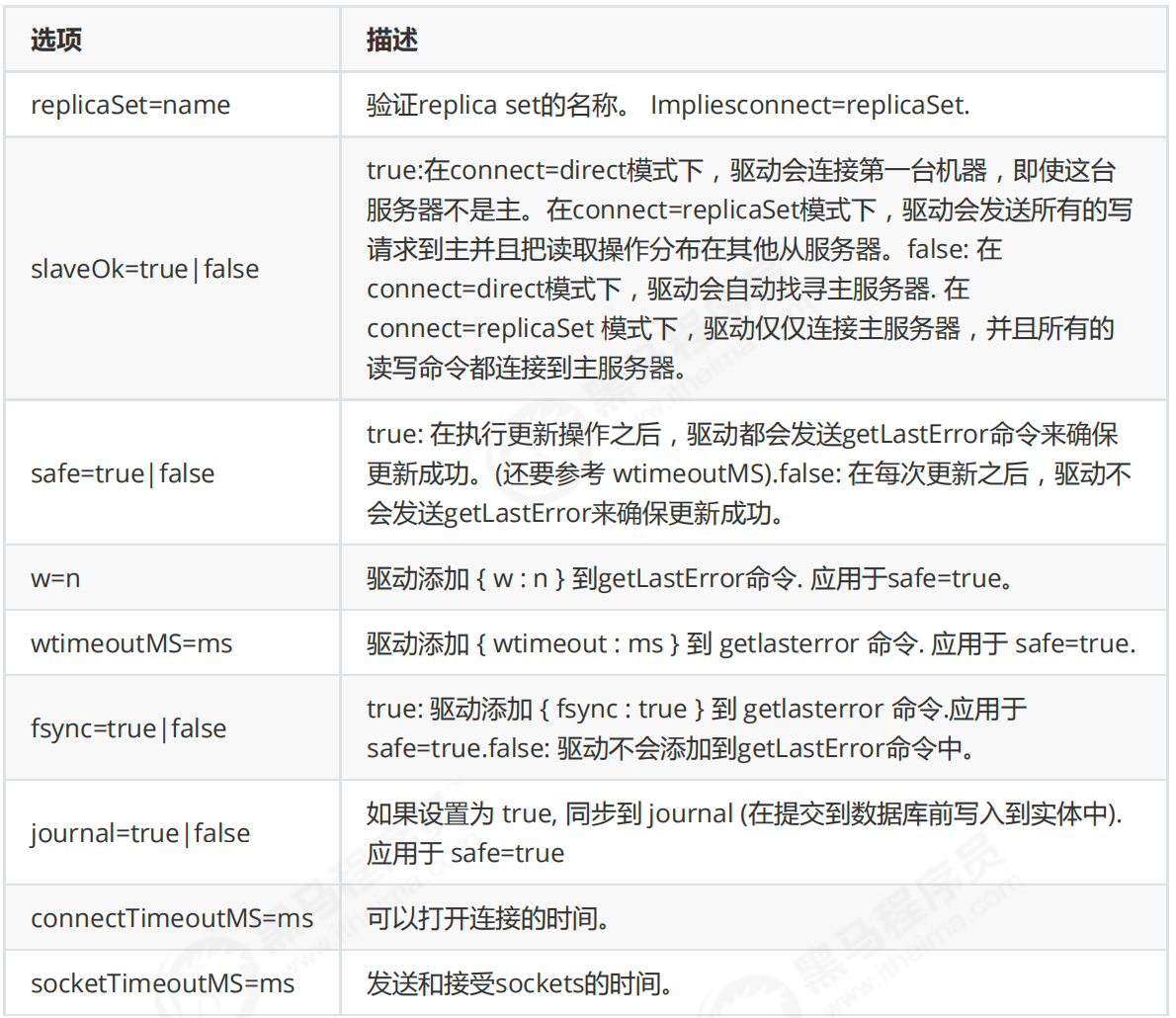
文章目录
实时数仓发展趋势
一、实时数仓现状
二、批流一体
实时数仓发展趋势
一、实时数仓现状
当前基于Hive的离线数据仓库已经非常成熟,随着实时计算引擎的不断发展以及业务对于实时报表的产出需求不断膨胀,业界最近几年就一直聚焦并探索于实时数仓建设。根据数仓架构演变过程,在Lambda架构中含有离线处理与实时处理两条链路,其架构图如下:

正是由于两条链路处理数据导致数据不一致等一些列问题所以才有了Kappa架构,Kappa架构如下:

Kappa架构可以称为真正的实时数仓,目前在业界最常用实现就是Flink + Kafka,然而基于Kafka+Flink的实时数仓方案也有几个非常明显的缺陷,所以在目前很多企业中实时数仓构建中经常使用混合架构,没有实现所有业务都采用Kappa架构中实时处理实现。Kappa架构缺陷如下:
- Kafka无法支持海量数据存储。对于海量数据量的业务线来说,Kafka一般只能存储非常短时间的数据,比如最近一周,甚至最近一天。
- Kafka无法支持高效的OLAP查询,大多数业务都希望能在DWD\DWS层支持即席查询的,但是Kafka无法非常友好地支持这样的需求。
- 无法复用目前已经非常成熟的基于离线数仓的数据血缘、数据质量管理体系。需要重新实现一套数据血缘、数据质量管理体系。
- Kafka不支持update/upsert,目前Kafka仅支持append。实际场景中在DWS轻度汇聚层很多时候是需要更新的,DWD明细层到DWS轻度汇聚层一般会根据时间粒度以及维度进行一定的聚合,用于减少数据量,提升查询性能。假如原始数据是秒级数据,聚合窗口是1分钟,那就有可能产生某些延迟的数据经过时间窗口聚合之后需要更新之前数据的需求。这部分更新需求无法使用Kafka实现。
所以实时数仓发展到现在的架构,一定程度上解决了数据报表时效性问题,但是这样的架构依然存在不少问题,随着技术的发展,相信基于Kafka+Flink的实时数仓架构也会进一步往前发展,那么到底往哪些方向发展,我们可以结合大公司中技术选型可以推测实时数仓的发展大致会走向“批流一体”。
二、批流一体
最近一两年中和实时数仓一样火的概念是“批流一体”,那么到底什么是“批流一体”?在业界中很多人认为批和流在开发层面上都统一到相同的SQL上处理是批流一体,也有一些人认为在计算引擎层面上批和流可以集成在同一个计算引擎是批流一体,比如:Spark/SparkStreaming/Structured Streaming/Flink框架在计算引擎层面上实现了批处理和流处理集成。
以上无论是在业务SQL使用上统一还是计算引擎上的统一,都是批流一体的一个方面,除此之外,批流一体还有一个最核心的方面就是存储层面上的统一。这个方面上也有一些流行的技术:delta/hudi/iceberg,存储一旦能够做到统一,例如:一些大型公司使用Iceberg作为存储,那么Kappa架构中很多问题都可以得到解决,Kappa架构将变成个如下模样:

这条架构中无论是流处理还是批处理,数据存储都统一到数据湖Iceberg上,这一套结构将存储统一后,解决了Kappa架构很多痛点,解决方面如下:
- 可以解决Kafka存储数据量少的问题。目前所有数据湖基本思路都是基于HDFS之上实现的一个文件管理系统,所以数据体量可以很大。
- DW层数据依然可以支持OLAP查询。同样数据湖基于HDFS之上实现,只需要当前的OLAP查询引擎做一些适配就可以进行OLAP查询。
- 批流存储都基于Iceberg/HDFS存储之后,就完全可以复用一套相同的数据血缘、数据质量管理体系。
- 实时数据的更新。
上述架构也可以认为是Kappa架构的变种,也有两条数据链路,一条是基于Spark的离线数据链路,一条是基于Flink的实时数据链路,通常数据都是直接走实时链路处理,而离线链路则更多的应用于数据修正等非常规场景。这样的架构要成为一个可以落地的实时数仓方案、可以做到实时报表产生,这得益于Iceberg技术:
- 支持流式写入-增量拉取
流式写入其实现在基于Flink就可以实现,无非是将checkpoint间隔设置的短一点,比如1分钟,就意味每分钟生成的文件就可以写入到HDFS,这就是流式写入。但是这里有两个问题,第一个问题是小文件很多,但这不是最关键的,第二个问题才是最致命的,就是上游每分钟提交了很多文件到HDFS上,下游消费的Flink是不知道哪些文件是最新提交的,因此下游Flink就不知道应该去消费处理哪些文件。这个问题才是离线数仓做不到实时的最关键原因之一,离线数仓的玩法是说上游将数据全部导入完成了,告诉下游说这波数据全部导完了,你可以消费处理了,这样的话就做不到实时处理。
数据湖就解决了这个问题。实时数据链路处理的时候上游Flink写入的文件进来之后,下游就可以将数据文件一致性地读走。这里强调一致性地读,就是不能多读一个文件也不能少读一个文件。上游这段时间写了多少文件,下游就要读走多少文件。我们称这样的读取叫增量拉取。
- 解决小文件多的问题
数据湖实现了相关合并小文件的接口,Spark/Flink上层引擎可以周期性地调用接口进行小文件合并。
- 支持批量以及流式的Upsert(Delete)功能
批量Upsert/Delete功能主要用于离线数据修正。流式upsert场景上文介绍了,主要是流处理场景下经过窗口时间聚合之后有延迟数据到来的话会有更新的需求。这类需求是需要一个可以支持更新的存储系统的,而离线数仓做更新的话需要全量数据覆盖,这也是离线数仓做不到实时的关键原因之一,数据湖是需要解决掉这个问题的。
- 支持比较完整的OLAP生态
比如支持Hive/Spark/Presto/Impala等OLAP查询引擎,提供高效的多维聚合查询性能。
目前Iceberg部分功能还在开发中,有一些功能还不完善,但是整体实时数仓的发展会大致朝着这个方向行进。目前业界大多数公司还是处于Lambda架构,使用Kappa架构的公司一般都是实时业务居多的公司,随着数据湖技术的发展,这些公司实时数仓的构建慢慢会走向最终的“批流一体”。
-
📢博客主页:https://lansonli.blog.csdn.net
-
📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
-
📢本文由 Lansonli 原创,首发于 CSDN博客🙉
-
📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨