关联比赛: Apache Flink极客挑战赛——Flink TPC-DS性能优化
作者:沙晟阳
本文是根据 Apache Flink 系列直播课程整理而成,由阿里巴巴高级开发工程师沙晟阳分享,主要面向于初次接触 Flink、或者对 Flink 有了解但是没有实际操作过的同学。希望帮助大家更顺利地上手使用 Flink,并着手相关开发调试工作。
主要内容:
-
Flink 开发环境的部署和配置
-
运行 Flink 应用
-
单机 Standalone 模式
-
多机 Standalone 模式
-
Yarn 集群模式
一. Flink 开发环境部署和配置
Flink 是一个以 Java 及 Scala 作为开发语言的开源大数据项目,代码开源在 GitHub 上,并使用 Maven 来编译和构建项目。对于大部分使用 Flink 的同学来说,Java、Maven 和 Git 这三个工具是必不可少的,另外一个强大的 IDE 有助于我们更快的阅读代码、开发新功能以及修复 Bug。因为篇幅所限,我们不会详述每个工具的安装细节,但会给出必要的安装建议。
关于开发测试环境,Mac OS、Linux 系统或者 Windows 都可以。如果使用的是 Windows 10 系统,建议使用 Windows 10 系统的 Linux 子系统来编译和运行。

建议选用社区已发布的稳定分支,比如 Release-1.6 或者 Release-1.7。
1. 编译 Flink 代码
在我们配置好之前的几个工具后,编译 Flink 就非常简单了,执行如下命令即可:
mvn clean install -DskipTests# 或者mvn clean package -DskipTests
常用编译参数:
Dfast 主要是忽略QA plugins和JavaDocs的编译
Dhadoop.version=2.6.1 指定hadoop版本
settings=${maven_file_path} 显式指定maven settings.xml配置文件
当成功编译完成后,能在当前 Flink 代码目录下的 flink-dist/target/子目录 中看到如下文件(不同的 Flink 代码分支编译出的版本号不同,这里的版本号是 Flink 1.5.1):
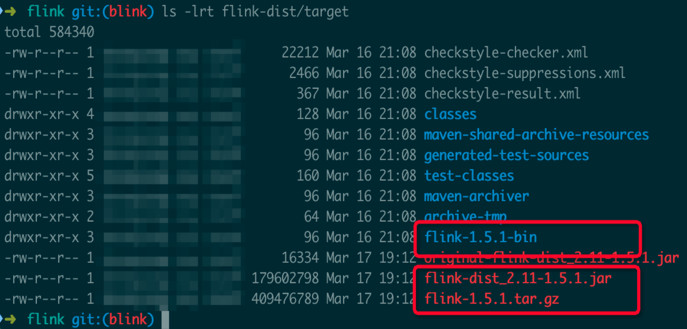
其中有三个文件可以留意一下:

版本注释flink-1.5.1.tar.gzBinary 的压缩包flink-1.5.1-bin/flink-1.5.1解压后的 Flink binary 目录flink-dist_2.11-1.5.1.jar包含 Flink 核心功能的 jar 包
注意: 国内用户在编译时可能遇到编译失败“Build Failure”(且有 MapR 相关报错),一般都和 MapR 相关依赖的下载失败有关,即使使用了推荐的 settings.xml 配置(其中 Aliyun Maven 源专门为 MapR 相关依赖做了代理),还是可能出现下载失败的情况。问题主要和 MapR 的 Jar 包比较大有关。遇到这些问题时,重试即可。在重试之前,要先根据失败信息删除 Maven local repository 中对应的目录,否则需要等待 Maven 下载的超时时间才能再次出发下载依赖到本地。
2. 开发环境准备
推荐使用 IntelliJ IDEA IDE 作为 Flink 的 IDE 工具。官方不建议使用 Eclipse IDE,主要原因是 Eclipse 的 Scala IDE 和 Flink 用 Scala 的不兼容。
如果你需要做一些 Flink 代码的开发工作,则需要根据 Flink 代码的 tools/maven/目录 下的配置文件来配置 Checkstyle ,因为 Flink 在编译时会强制代码风格的检查,如果代码风格不符合规范,可能会直接编译失败。
二、运行 Flink 应用
1. 基本概念
运行 Flink 应用其实非常简单,但是在运行 Flink 应用之前,还是有必要了解 Flink 运行时的各个组件,因为这涉及到 Flink 应用的配置问题。图 1 所示,这是用户用 DataStream API 写的一个数据处理程序。可以看到,在一个 DAG 图中不能被 Chain 在一起的 Operator 会被分隔到不同的 Task 中,也就是说 Task 是 Flink 中资源调度的最小单位。

图 2 所示,Flink 实际运行时包括两类进程:
-
JobManager(又称为 JobMaster):协调 Task 的分布式执行,包括调度 Task、协调创 Checkpoint 以及当 Job failover 时协调各个 Task 从 Checkpoint 恢复等。
-
TaskManager(又称为 Worker):执行 Dataflow 中的 Tasks,包括内存 Buffer 的分配、Data Stream 的传递等。
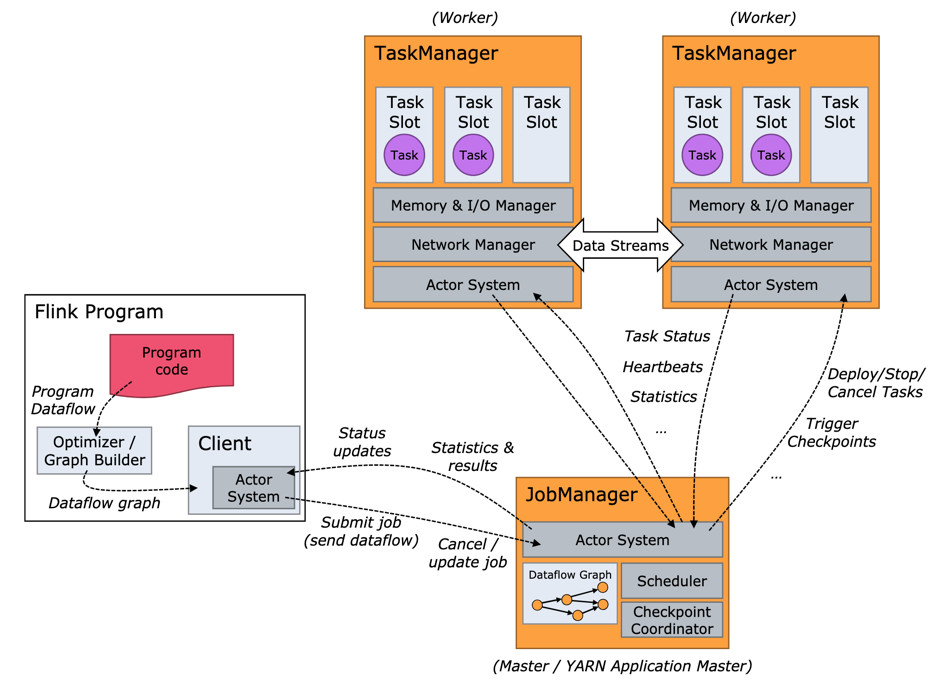
图 3 所示,Task Slot 是一个 TaskManager 中的最小资源分配单位,一个 TaskManager 中有多少个 Task Slot 就意味着能支持多少并发的 Task 处理。需要注意的是,一个 Task Slot 中可以执行多个 Operator,一般这些 Operator 是能被 Chain 在一起处理的。
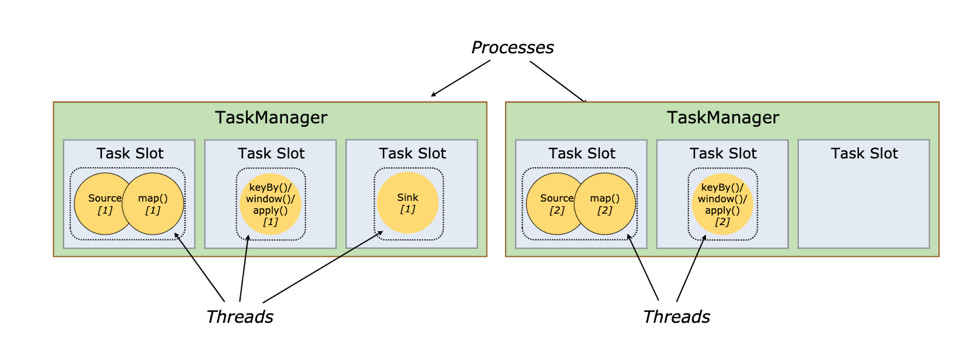
2. 运行环境准备
-
准备 Flink binary
-
直接从 Flink 官网上下载 Flink binary 的压缩包
-
或者从 Flink 源码编译而来
-
安装 Java,并配置 JAVA_HOME 环境变量
3. 单机 Standalone 的方式运行 Flink
(1)基本的启动流程
最简单的运行 Flink 应用的方法就是以单机 Standalone 的方式运行。
启动集群:
./bin/start-cluster.sh
打开 http://127.0.0.1:8081/ 就能看到 Flink 的 Web 界面。尝试提交 Word Count 任务:
./bin/flink run examples/streaming/WordCount.jar
大家可以自行探索 Web 界面中展示的信息,比如,我们可以看看 TaskManager 的 stdout 日志,就可以看到 Word Count 的计算结果。
我们还可以尝试通过“–input”参数指定我们自己的本地文件作为输入,然后执行:
./bin/flink run examples/streaming/WordCount.jar --input ${your_source_file}
停止集群:
./bin/stop-cluster.sh