上下文学习
- 上下文学习
- 什么是上下文学习
- 2. 示例的选择
- 2.1 相关度排序
- 2.2 集合多样性
- 2.3 大语言模型
- 3. 示例格式
- 3.1 人工标注
- 3.2 利用大语言模型自动生成
- 4. 示例顺序
- 5. 上下文学习为什么可以work
- 5.1 能力来源
- 5.2 ICL的能力
- Reference
在GPT-3的论文中,OpenAI 研究团队首次提出上下文学习(In-contextlearning, ICL) 这种特殊的提示形式。
什么是上下文学习
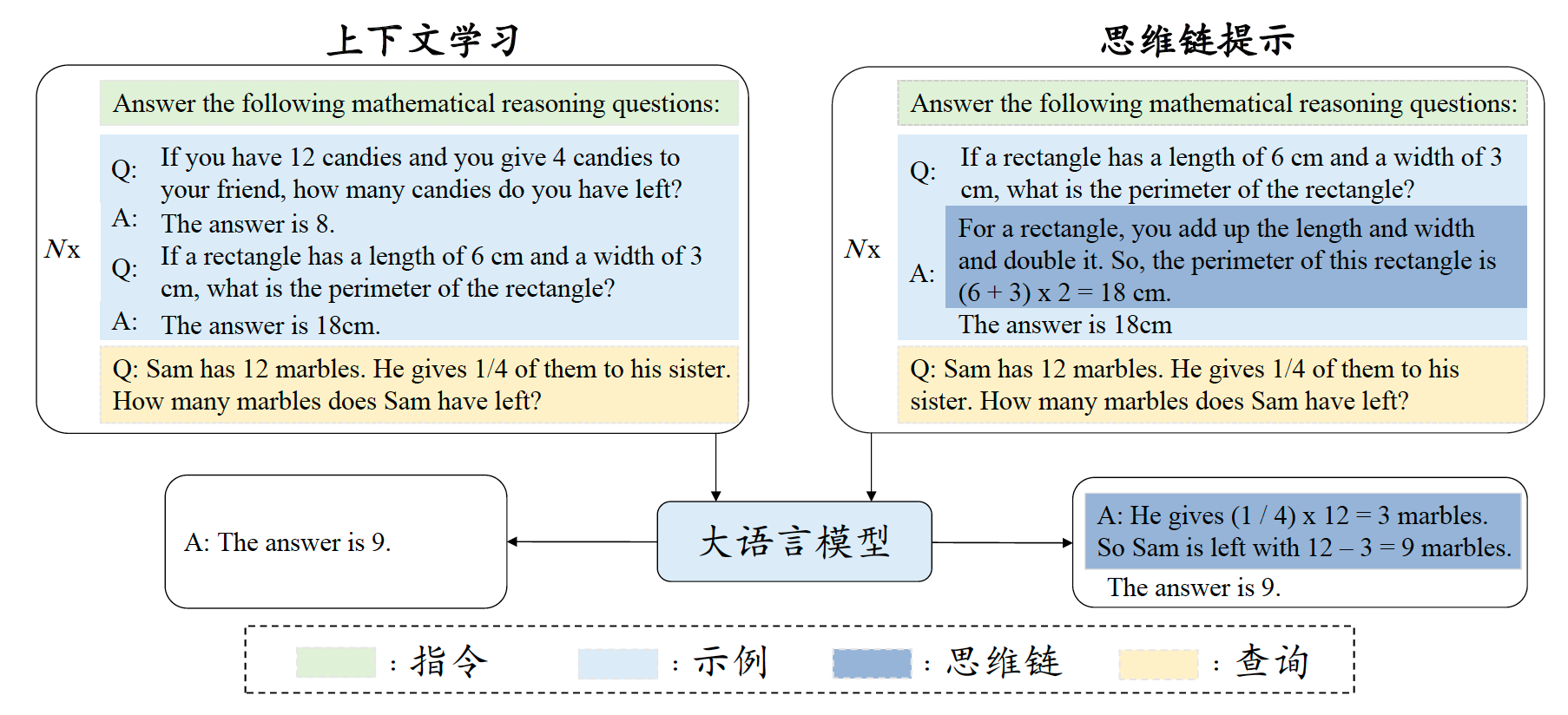
上下文学习是使用由任务描述和(或)示例所组成的自然语言文本作为提示的提示策略。如下图所示,首先,通过自然语言描述任务,并从任务数据集中选择一些样本作为示例。其次,根据特定的模板,将这些示例按照特定顺序组合成提示内容。最后,将测试样本添加到提示后面,整体输入到大语言模型以生成输出。基于任务描述以及示例信息,LLM无需显式的梯度更新即可识别和执行新的任务。
给定由
k
k
k 个样本组成的示例数据集合
D
k
=
{
f
(
x
1
,
y
1
)
,
.
.
.
,
f
(
x
k
,
y
k
)
}
D_k=\{f(x_1,y_1), ...,f(x_k,y_k) \}
Dk={f(x1,y1),...,f(xk,yk)},其中
f
(
x
k
,
y
k
)
f(x_k, y_k)
f(xk,yk)为将样本转为提示的函数,可以是模型也可以是手工定义。给定任务描述
I
I
I、示例
D
k
D_k
Dk以及新的输入
x
k
+
1
x_{k+1}
xk+1,LLM基于给予的提示,生成答案
y
k
+
1
y_{k+1}
yk+1:
L
L
M
(
I
,
f
(
x
1
,
y
1
)
,
.
.
.
,
f
(
x
k
,
y
k
)
,
f
(
x
k
+
1
,
‾
)
)
→
y
k
+
1
LLM(I,f(x_1,y_1), ...,f(x_k,y_k),f(x_{k+1}, \underline{})) \rightarrow y_{k+1}
LLM(I,f(x1,y1),...,f(xk,yk),f(xk+1,))→yk+1

如上图所示,以一个分类任务进行举例,从训练集中抽取了 k = 3 k=3 k=3个包含输入输出的实例,使用换行符"\n"来区分输入和输出。在预测时,可以更换测试样本输入(绿色部分),并在末尾留出空间让LLM生成。
在原始的GPT-3 论文中,作者将上下文学习的提示定义为任务描述和示例的组合,这两部分均为可选。按照这个定义,如果大语言模型仅通过任务描述(即任务指令)来解决未见过的任务(Zero-shot),也可以被看作是上下文学习的一种特例。
指令微调和上下文学习的区别:
- 指令微调需要对大语言模型进行微调,而上下文学习仅通过提示的方式来调用大语言模型解决任务。
- 指令微调还可以有效提升大语言模型在执行目标任务时的上下文学习能力,尤其是在零样本(Zero-shot)场景下(即仅依赖任务描述而无需额外的示例)。
2. 示例的选择
示例选择的目的是从含有大量样本的数据集中选取最有价值的示例,进而帮助LLM更为有效的激发模型效果。示例的选择原则:示例包含丰富的任务信息且与测试样本保持高度相关性。
2.1 相关度排序
基于 k k k 近邻(K-Nearest Neighbors,K-NN)的相似度检索算法:使用文本嵌入模型(如BERT)将所有候选样本映射到低维嵌入空间中,然后根据候选样本与测试样本的嵌入语义相似度进行排序,并选择出最相关的 k k k 个示例,最后将筛选出的示例作为上下文学习的示例集合。
Note:需要拿到全部或部分测试样本
2.2 集合多样性
尽管 k k k近邻检索算法简单易行,但是它通常独立地评估每个示例的相关性,而忽略了示例集合的整体效果。为了弥补这一不足,我们可以采取基于集合多样性的示例选择策略。这种策略旨在针对特定任务选择出具有代表性的、信息覆盖性好的示例集合,从而确保所选示例能够反应尽可能多的任务信息,从而为大语言模型的推理提供更丰富、更全面的信息。在选择过程中,除了考虑样本与目标任务的相关性,同时也要考虑与已选样本的相似性,需要综合考虑相关性与新颖性的平衡。在实现中,可以采用经典启发式的MMR 算法(Maximum Margin Ranking)以及基于行列式点过程的DPP 算法(DeterminantalPoint Process),从而加强示例集合的多样性。
2.3 大语言模型
- 将大语言模型作为评分器对候选样本进行评估,选择出优质的示例。
- 通过计算在加入当前示例后大语言模型性能的增益来评估示例的有效性
- 根据大语言模型的评分结果选择出少量的正负示例用于训练一个分类器,该分类器通过正负示例能够学习到如何准确地区分和筛选出高质量示例,从而更准确地来指导后续的示例选择过程。
3. 示例格式
3.1 人工标注
- 定义好输入与输出的格式,添加详细的任务描述, 帮助大语言模型更好地理解当前示例所要表达的任务需求。下图示例展示了人工标注的示例格式的例子。最简单的示例格式只需要显式标识出输入与输出,让大语言模型自动学习到输入与输出之间的语义映射关系。
- 在提示内部加入相关的任务描述有助于模型更精准地理解任务的要求,从而生成更准确的答案。
- 为了更好地激发大语言模型的推理能力,可以在输出中加入思维链

3.2 利用大语言模型自动生成
借助大语言模型的上下文学习能力,进而大规模扩充新任务的示例模版。具体来说,首先人工标注一部分的示例模板作为种子集合加入到大语言模型的输入中。然后,利用大语言模型强大的少样本学习能力,指导其为新任务生成相应的示例模版。最后,对这些生成的示例模版进行筛选与后处理,使之符合任务要求。
4. 示例顺序
在上下文学习中,大语言模型往往会受到位置偏置的影响,表现为对示例顺序具有一定的敏感性。因此,设计合理的示例顺序也是上下文学习中需要考虑的一个问题,旨在为所选择的示例找到最有效的排序方式以提升模型性能。确定大语言模型的最优的示例顺序通常分为两个步骤:产生示例的候选顺序和评估示例顺序的有效性。
- 产生示例顺序:
- 首先最为直接的方法是给出所有示例的排列组合,从中随机选择一个示例组合作为示例顺序。这种随机选择的方式,产生的方差较大。
- 根据示例与测试样本之间的语义相似度进行排序,然后将与测试样例相似度更高的示例放在更靠近测试样本的位置。这种方法可以加强大语言模型在推理过程中对于语义相关的示例进行利用,从而提升模型性能。
- 顺序质量评估:
- 直接测试大语言模型基于该示例顺序的任务性能,以此作为当前示例顺序的评分。
- 采用模型对于预测结果的不确定性作为评估指标。具体来说,计算基于该示例顺序大语言模型预测分布的熵值,选择熵值较低的示例顺序作为较为有效的顺序。熵值越低,意味着模型预测分布越不均匀,则模型预测的置信度更高。
5. 上下文学习为什么可以work
5.1 能力来源
预训练阶段主要有两个关键因素对大语言模型上下文学习能力产生影响:**预训练任务和预训练数据。**这两方面分别关注如何设计训练任务和如何选择训练数据来提升模型的上下文学习能力。
- 预训练任务:上下文学习的概念最初在GPT-3 的论文中被正式提出,论文通过相关实验发现上下文学习能力随着模型规模的增大而增强。随着预训练技术的改进,后续研究发现(MetaICL),即使是小规模的模型,通过设计专门的训练任务(如根据示例和输入来预测标签),进行继续预训练 或微调,也能够获得上下文学习能力。
- 预训练数据. 通过混合不同领域的预训练数据,增强预训练语料的多样性可以提高大语言模型的上下文学习能力。此外,预训练数据的长程依赖关系也是改善模型上下文学习能力的重要因素。通过将前后相关的文本直接拼接进行训练,模型能够更好地理解文本之间的关联性,从而提升上下文学习的能力。
由此,LLM具备了以下能力:
-
知识积累:预训练阶段,模型会接触到大量的无标注或弱标注数据,从而学习到丰富的语言知识、常识和上下文信息。这些积累的知识和信息为ICL提供了坚实的基础,使得模型能够利用上下文信息做出更准确的预测。 -
泛化能力:预训练过程使模型具备了较强的泛化能力,即模型能够将在预训练阶段学到的知识和技能应用到新的、未见过的任务和数据上。这种泛化能力是ICL得以实现的关键,因为ICL正是利用了模型在预训练阶段学到的知识来进行少量样本学习。 -
参数初始化:预训练为模型的参数提供了良好的初始化值。在ICL过程中,模型不需要对参数进行大量的更新,而只需要根据少量标注样本进行微调,即可快速适应新的任务。这种快速的适应能力是ICL的一个重要优势。
5.2 ICL的能力
利用上下文信息:LLMs能够充分利用输入序列中的上下文信息来做出决策。例如,在文本分类任务中,模型可以通过分析整个句子的语境来判断句子的情感倾向。设计提示模板:对于特定的任务,LLMs可以通过设计任务相关的指令形成提示模板。这些提示模板可以包含少量标注样本,用于指导模型生成预测结果。少样本学习:LLMs在只有少量标注数据可用时仍能表现出良好的性能。通过利用预训练阶段学到的知识和泛化能力,模型可以在少量样本上快速学习并适应新的任务。性能提升:实验表明,ICL方法的表现大幅度超越了Zero-Shot-Learning(示例样本为0的特殊ICL),为少样本学习提供了新的研究思路。在多个自然语言处理任务上,采用ICL方法的LLMs相比传统的微调方法取得了更好的性能。
Reference
https://www.cnblogs.com/ting1/p/18254665