如何以人性化的方式解释你的模型
可直接在橱窗里购买,或者到文末领取优惠后购买:

数据科学家职责的一个重要部分是解释模型预测。通常,接受解释的人不是技术人员。如果你开始谈论成本函数、超参数或 p 值,你将会遇到茫然的表情。我们需要将这些技术概念转化为外行人能理解的术语。这个过程可能比构建模型本身更具挑战性。
我们将探索如何给出人性化的解释。我们将通过讨论良好解释的一些关键特征来做到这一点。重点将放在解释个别预测上。最后,我们将通过使用「SHAP 值」解释模型来应用其中的一些知识。我们将看到,当你想要给出人性化的解释时,SHAP 非常有用。
本地解释与全球解释
在深入讨论之前,让我们先讨论一下你要解释什么以及向谁解释。作为一名数据科学家,你可能需要与各种各样的人沟通。这包括同事、监管者或客户。这些人的技术专长水平各不相同。因此,你需要根据他们的专业知识调整解释的水平。
在某些情况下,你可能会被要求解释整个模型。我们称之为全局解释。我们希望了解模型总体上捕捉到了哪些趋势。我们可能需要回答诸如“哪些特征最重要?”或“特征 X 与目标变量有什么关系?”之类的问题。
在其他情况下,我们需要给出局部解释。这就是我们解释单个模型预测的时候。事实上,我们通常必须解释由模型预测得出的决策。这些解释也可以回答诸如“我们为什么拒绝这个贷款申请?”或“为什么给我这个电影推荐?”之类的问题。

与同事或监管者交谈时,你可能需要给出更多技术性解释。相比之下,客户会期望更简单的解释。你也不太可能需要向客户提供全面的解释。这是因为他们通常只关心对他们个人有影响的决定。我们将重点关注这种情况。即向非技术人员解释个别预测。
良好解释的特征
当我们谈论一个好的解释时,我们指的是一个容易被接受的解释。换句话说,它应该让听众相信一个决定是正确的。要给出这样的解释,你需要考虑一些关键方面。你可以在图 1 中看到这些方面的摘要。在本节的其余部分,我们将深入讨论每一个方面。
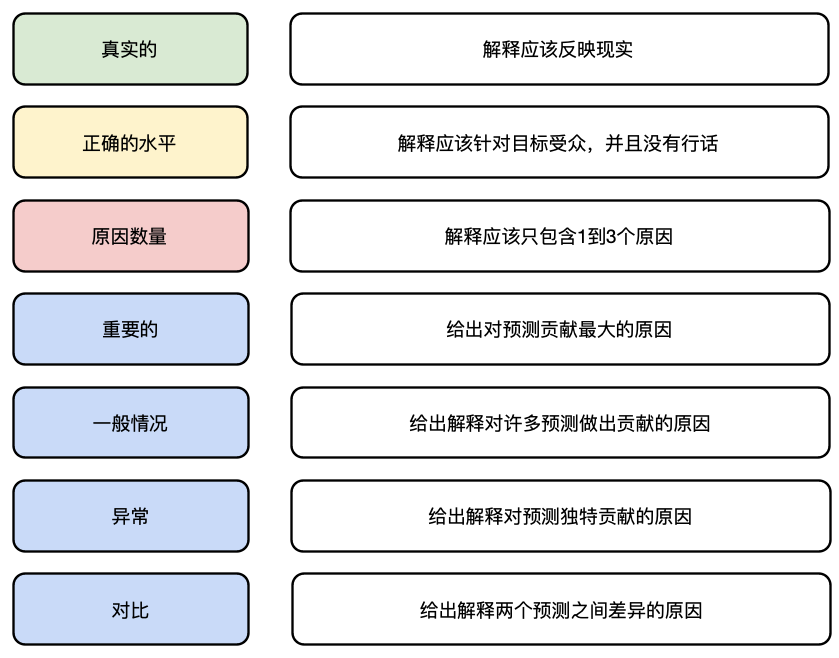
真实的
这似乎很明显,但一个好的解释应该是真实的。当你考虑我们正在解释的内容时,这可能比你想象的要难。也就是说,我们正在对模型预测给出解释。问题是这些预测可能是不正确的。例如,我们的模型可能过度拟合。这意味着预测可能反映了已建模的噪声。对这些预测的解释不会反映数据中真正的潜在关系。

在给出解释时,我们需要考虑我们的模型如何很好地代表现实。我们可以通过评估模型的性能来做到这一点。例如使用交叉验证准确率。即使总体表现良好,一些预测也可能比其他预测更不确定。例如,逻辑回归预测的概率约为 0.5。在你的解释中,我们可能想提及这种不确定性。
针对目标受众
措辞方式很重要。我们拒绝你的贷款是因为 — “你是加密货币交易员”、“你从事高风险行业”或“你的收入太不稳定”。这些都是相同的原因,只是措辞不同。某些措辞方式可以更好地表达你的观点。有些人可能还会觉得某些方式令人反感。例如,第一个解释可能会被视为个人问题。
你还应避免使用任何技术或商业术语。“收入在我们的模型中有一个正参数,而你的收入值很低。因此,你被拒绝了,因为你的收入值显著增加了你的违约风险。”这是一个糟糕的解释,因为我们使用了技术术语(即“模型”和“参数”)。我们也有一些商业术语(即“违约风险”)。
选择最佳的解释方式才是艺术的真正所在。这可能是解释预测最困难的部分。数据科学课程或大学也没有很好地涵盖这一点。最终,这项技能将随着经验和与客户建立关系而获得。
原因数量
人们只想知道事件的主要原因。“为什么通货膨胀这么高?”——“因为油价上涨。”事实上,通货膨胀可能是由多种因素造成的,包括工资增长、政府支出增加或汇率。然而,这些因素可能没有能源成本上涨那么显著。
在机器学习中,人们并不想知道每个模型特征如何影响预测。通常,解释 1 到 3 个特征的贡献就足够了。问题是你选择解释哪些贡献?接下来的 4 个特征可以帮助你选择最合适的原因。

重要的
我们应该选择最重要的原因。换句话说,我们只解释那些影响巨大的因素。对于我们的通货膨胀示例,我们将给出导致最大涨幅的原因。这些原因比那些影响较小的原因更容易被接受。
对于 ML,我们希望解释对预测贡献最大的特征。我们确定这些特征的方式取决于所使用的模型。对于线性模型,我们可以查看参数权重和特征值。稍后我们将看到 SHAP 值如何用于非线性模型。
一般的
一个好的理由可以解释许多决定。“你为什么拒绝我的贷款申请?”-“因为你有很多现有债务。”假设这是拒绝许多贷款申请的原因。这个理由更容易被接受,因为它的作用被广泛理解。
对于 ML,我们可以通过查看某些特征重要性度量来找到一般解释。例如,排列特征重要性。通过 SHAP 值,我们可以查看平均绝对 SHAP。无论采用哪种度量,高值都表明某个特征总体上做出了重大贡献。
异常
在其他情况下,一个好的理由可能并不常见。这些理由可以解释对特定决策的重大贡献。但是,一般来说,它们无法解释决策。“你为什么拒绝我的贷款申请?”-“因为你是加密货币交易员”这些类型的理由可能会被接受,因为它们更个人化。也就是说,人们可以理解它对他们有何具体影响。
对于 ML,我们可以通过查看特征重要性和对各个预测的贡献的组合来查找异常原因。这些特征可能不具有很高的特征重要性。但是,对于特定的预测,它们做出了很大的贡献。

对比
我们经常需要解释一个决定与另一个决定的区别。客户可能不会问“为什么我的申请被拒绝?”而是问“为什么我的申请被拒绝而他们的申请被接受?”可能是因为两个客户都负债累累。这个原因可能在第一个问题中被接受,但在第二个问题中却不被接受。换句话说,我们需要给出一个能够区分这两个决定的理由。
对于 ML 来说,这意味着我们需要根据两个客户具有不同值的特征来做出解释。该特征还需要有所不同,从而导致不同的预测。例如,我们可能会发现第一个客户的收入较高。收入特征不同,但这不是一个很好的理由。也就是说,更高的收入不会导致申请被拒绝。
最后这四个特点似乎相互矛盾。异常原因不可能具有普遍性。异常或普遍原因可能不是最重要的。对比原因既不重要,也不普遍,也不异常。但是,我们可以在解释中使用多种原因。你选择的原因将取决于问题、人以及你认为最有说服力的原因。
用 SHAP 解释模型
现在让我们把这些特征付诸实践。我们将尝试解释一个用于预测保险收费金额(费用)的模型。你可以在表 1 中看到此数据集的快照。我们的模型特征基于前 6 列。例如,children 是受抚养人的数量。
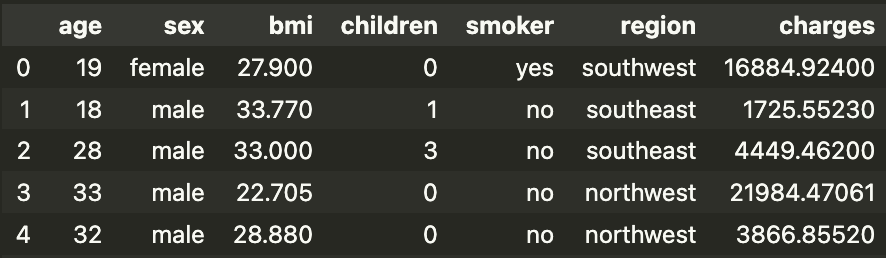
(数据集:[kaggle]1, 许可证 - 数据库:开放数据库)
我们不会详细介绍代码,但你可以在我的 [GitHub]2 上找到完整的项目。
总而言之,我们首先进行一些特征工程。我们将性别和吸烟者转换为二进制特征。区域可以采用 4 个不同的值,因此我们从此列创建 4 个虚拟变量。这给我们留下了总共 9 个模型特征。我们使用这些特征来训练一个 XGBoost 模型,以预测收费情况。 模型训练完成后,我们将计算每次预测的 SHAP 值。
对于每个预测,每个特征都会有一个 SHAP 值。SHAP 值给出了该特征对预测的贡献。换句话说,该特征增加或减少了预测费用。要了解哪些特征很重要,我们可以看看图 2。这里我们取了所有预测的 SHAP 值的绝对平均值。高平均值表示该特征总体上对预测做出了很大贡献。
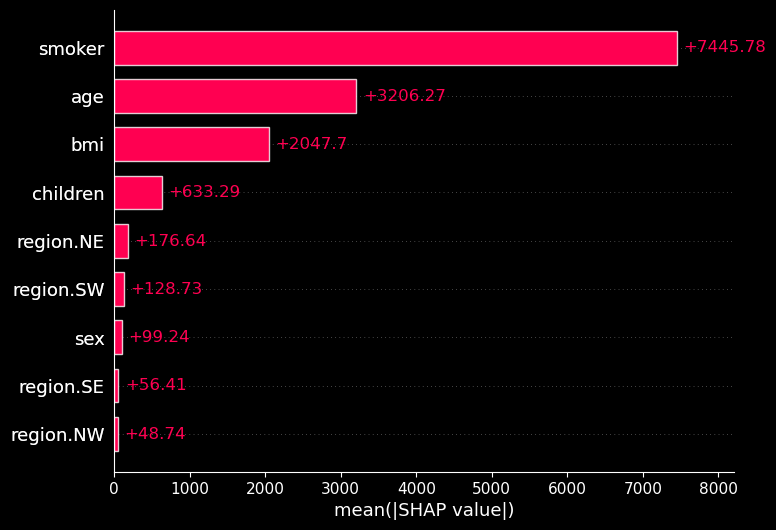
我们可以使用图 2 来帮助确定良好的一般原因或异常原因。例如,我们可以看到吸烟者的绝对平均值较高。这告诉我们,一般来说,该特征可以为预测提供良好的理由。绝对平均值较低的特征可能会提供良好的异常原因。也就是说,如果对于特定预测,它们具有较大的贡献。
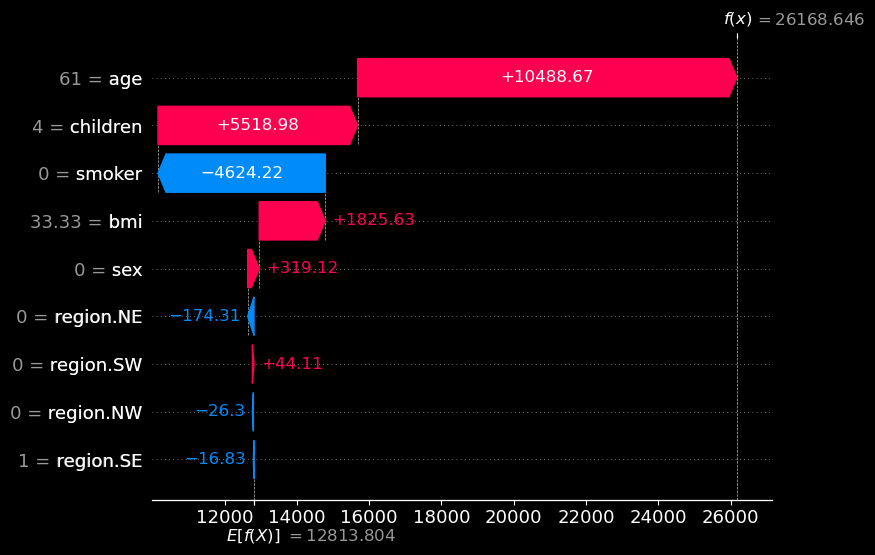
让我们尝试解释一下我们的第一个预测。你可以在图 3中看到此预测的 SHAP 瀑布图。查看 x 轴,我们可以看到基值为 E[f(x)] = 12813。这是所有客户的平均预测费用。最终值为 f(x) = 26726。这是针对该特定客户的预测费用。SHAP 值是介于两者之间的所有值。它们告诉我们与平均预测相比,每个特征如何增加或减少了预测。
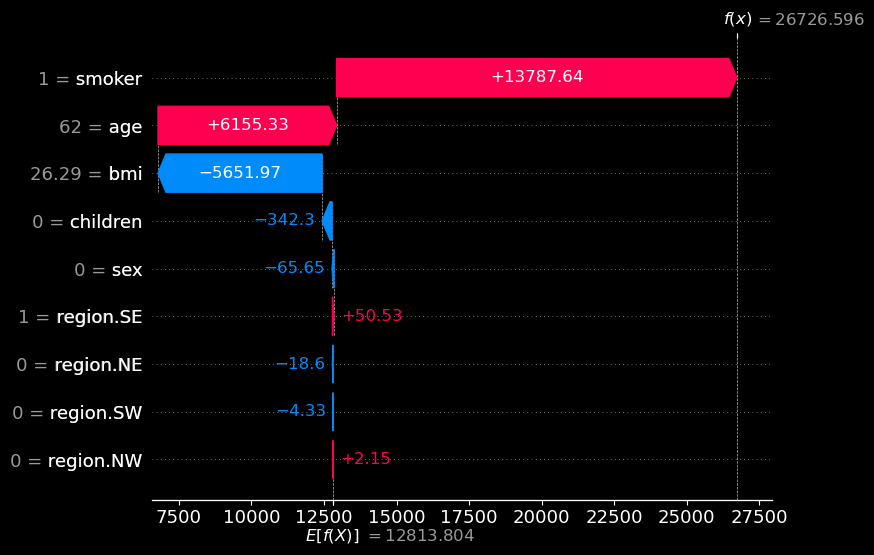
从图 3 中我们可以看到,吸烟者是最重要的特征。也就是说,它使预测费用增加了最多的量。特征值在 y 轴上给出。例如,我们可以看到 1 = smoker 表示该客户吸烟。因此,如果客户问“为什么我的保险费这么高?”,一个很好的解释可能是“你是吸烟者”。我们还看到,在图 2 中,这是一个很好的一般原因。
因此,吸烟既是重要原因,也是普遍原因。这可能足以让这个人相信保险费是正确的。如果我们想确定,我们可以提到第二重要的特征。查看 y 轴,我们可以看到此人是 62 岁。因此,我们可以跟进第二个原因,“而且你老了。”(我们可能想用更好的方式来表达这一点。)
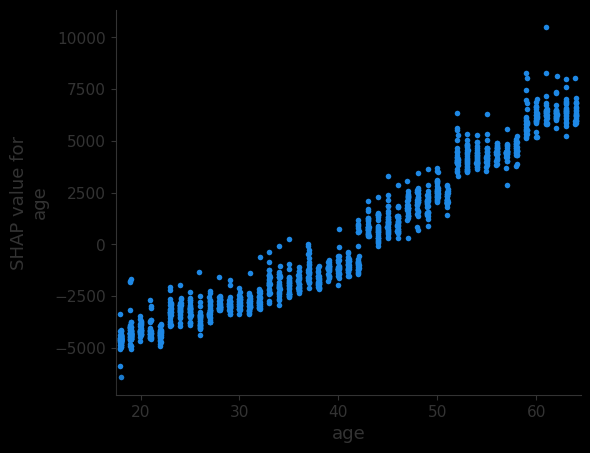
出于第二个原因,我们猜测了与目标变量的关系。也就是说,随着年龄的增长,你的费用也会增加。其他特征的关系可能不那么明显。这意味着为了给出好的理由,我们需要一些特征值的背景信息。为此,我们可以使用 SHAP 值的散点图。查看图 4,我们可以看到我们的猜测是正确的。随着年龄的增长,SHAP 值会增加。换句话说,预测的费用会增加。
在图 5 中,你可以看到第二个预测的瀑布图。为了解释这一点,我们可能会直接跳到客户的年龄。但是,请注意,孩子也做出了重大贡献。请记住,我们在图 2 中看到,这个特征总体上并不重要。换句话说,children 的数量可能是一个很好的异常原因。我们可能更愿意将其作为主要原因。
从本质上讲,SHAP 值允许你给出对比解释。但是,这仅限于我们想要将预测与平均预测进行比较时。回答诸如“为什么我的收费高于平均水平?”之类的问题很容易。回答诸如“为什么我的收费比我姐姐的要高?”之类的问题需要做更多工作。还有其他计算 SHAP 值的方法可以使这更容易。例如,基线 SHAP 将计算相对于特定预测的值。
我们专注于使用 SHAP 值来解释单个预测。它们也可用于给出全局解释。即解释整个模型的工作原理。我们通过聚合 SHAP 值并创建不同的图来实现这一点。我们已经看到了一个——平均 SHAP 图。之前写过一篇《[使用 Python 进行 SHAP 简介](Python 中的 SHAP 简介)》,大家可以看看,其中讨论了更多内容。我们还会讨论用于计算 SHAP 值和创建这些图的 Python 代码。
希望这篇文章对你有所帮助!你还可以阅读我的其他文章,或者查看有关企业 AI 实战项目的教程,相信会让你拥有更多收获。

参考
C. Molnar, Interpretable Machine Learning, 2021, https://christophm.github.io/interpretable-ml-book/explanation.html
T. Miller, Explanation in artificial intelligence: Insights from the social sciences, 2017, https://arxiv.org/abs/1706.07269
S. Lundberg & S. Lee, A Unified Approach to Interpreting Model Predictions, 2017, https://arxiv.org/pdf/1705.07874.pdf
「AI秘籍」系列课程:
- 人工智能应用数学基础
- 人工智能Python基础
- 人工智能基础核心知识
- 人工智能BI核心知识
- 人工智能CV核心知识

M. Choi,医疗费用个人数据集(许可证 - 数据库:开放数据库)https://www.kaggle.com/datasets/mirichoi0218/insurance/metadata ↩︎
Github, https://github.com/hivandu/public_articles/blob/main/src/interpretable_ml/SHAP/SHAP_explanation.ipynb ↩︎











![[LLM][Prompt Engineering]:思维链(CoT)](https://img-blog.csdnimg.cn/img_convert/641e41c292cc42c3da7d6ab1a727de2c.png)






