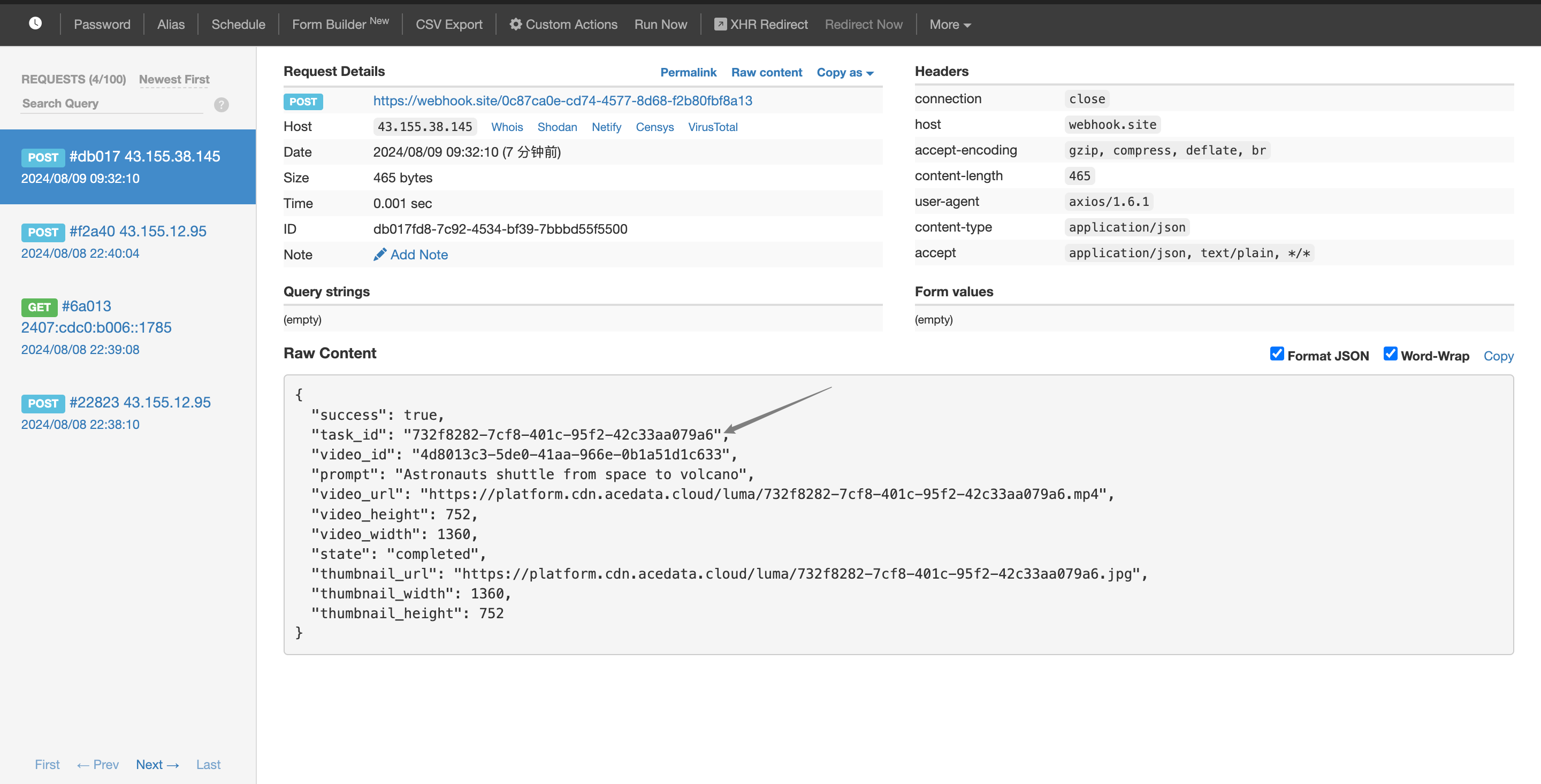
作者:谷乂
RocketMQ 的目标,是致力于打造一个消息、事件、流一体的超融合处理平台。这意味着它需要满足各个场景下各式各样的要求,而批量处理则是流计算领域对于极致吞吐量要求的经典解法,这当然也意味着 RocketMQ 也有一套属于自己风格的批处理模型。
至于什么样的批量模型才叫“属于自己风格”呢,且听我娓娓道来。
什么是批处理
首先,既然谈 RocketMQ 的批处理模型,那就得聊聊什么是“批处理”,以及为什么批处理是极致吞吐量要求下的经典解法。在我看来,批处理是一种泛化的方法论,它处在各个系统的方方面面,无论是传统工业还是互联网,甚至在日常生活中,都能看到它的身影。

批处理的核心思想是将多个任务或数据集合在一起,进行统一处理。这种方法的优势在于可以充分利用系统资源,减少任务切换带来的开销,从而提高整体效率。比如在工业制造中,工厂通常会将相同类型的零部件批量生产,以降低生产成本和提高生产速度。在互联网领域,批处理则表现为批量数据的存储、传输和处理,以优化性能和提升系统吞吐量。
批处理在极致吞吐量需求下的应用,更加显著。例如,在大数据分析中,海量的数据需要集中处理才能得出有意义的结果。如果逐条处理数据,不仅效率低下,还可能造成系统瓶颈。通过批处理,可以将数据划分为若干批次,在预定的时间窗口内统一处理,从而提高系统的并行处理能力,提升整体吞吐量。
此外,批处理其实并不意味着牺牲延时,就比如在 CPU Cache 中,对单个字节的操作无论如何时间上都是会优于多个字节,但是这样的比较并没有意义,因为延时的感知并不是无穷小的,用户常常并不关心 CPU 执行一条指令需要花多长时间,而是执行完单个“任务/作业”需要多久,在宏观的概念上,反而批处理具有更低的延时。
RocketMQ 批处理模型演进
接下来我们看看,RocketMQ 与批处理的“如胶似漆、形影相随”吧,其实在 RocketMQ 的诞生之初,就已经埋下了批处理的种子,这颗种子,我们暂且叫它——早期的批处理模型。
早期批处理模型
下图,是作为用户视角上感知比较强的老三样,分别是 Producer、Consumer、Broker:
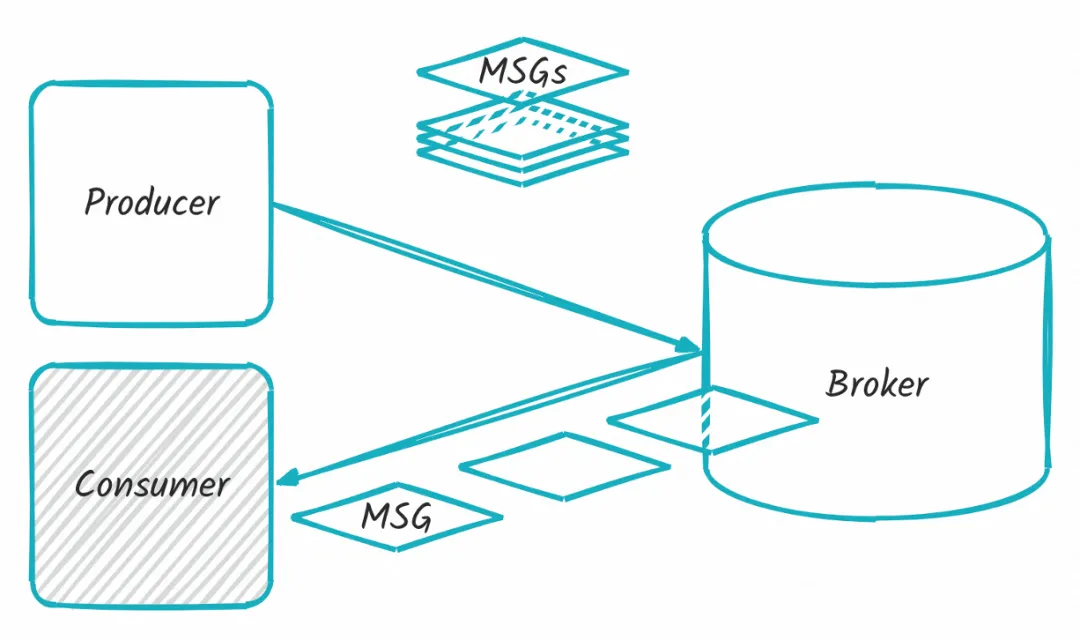
而早期批处理模型,实际上只和 Producer、Broker 有关,在这条链路上会有批量消息的概念,当消息到达 Broker 后这个概念就会消失。
基于这点我们来看具体是怎么回事。首先批量消息的源头实际上就是 Producer 端的 Send 接口,在大部分场景下,我们发送一条消息都会使用以下的形式去操作:
SendResult send(Message msg);
非常地简明扼要,将一条消息发送到 Broker,如果我们要使用上早期的批处理模型,也只需要稍作修改:
SendResult send(Collection<Message> msgs)
可以看到,将多条消息串成一个集合,然后依旧是调用 send 接口,就可以完成早期批处理模型的使用了(从用户侧视角看就已经 ok 了),就像下图一样,两军交战,谁火力更猛高下立判~

那么真就到此为止了吗?当然不是,首先这里的集合是有讲究的,并不是随意将多条消息放在一起,就可以 send 出去的,它需要满足一些约束条件:
- 相同 Topic。
- 不能是 RetryTopic。
- 不能是定时消息。
- 相同 isWaitStoreMsgOK 标记。
这些约束条件暂时先不展开,因为就如同它字面意思一样浅显易懂,但是这也意味着它的使用并不是随心所欲的,有一定的学习成本,也有一定的开发要求,使用前需要根据这些约束条件自行分类,然后再装进“大炮”中点火发射。
这里可能有人会问,这不是为难我胖虎吗?为什么要加这么多约束?是不是故意的?实际上并非如此,我们可以想象一下,假如我们是商家:
- 客户 A 买了两件物品,在发货阶段我们很自然的就可以将其打包在一起(将多个 Message 串成一个 ArrayList),然后一次性交给快递小哥给它 Send 出去,甚至还能省一笔邮费呢~
- 客户 B 和客户 C 各买了一件物品,此时我效仿之前的行为打包到一起,然后告诉快递小哥这里面一个发到黑龙江,一个发到海南,然后掏出一笔邮费,然后。。。就没有然后了。
很显然,第二个场景很可能会收到快递小哥一个大大的白眼,这种事情理所应当的做不了,这也是为什么属于同一个 Collection 的消息必须要满足各种各样的约束条件了,在 Broker 实际收到一个“批量消息”时,会做以下处理:
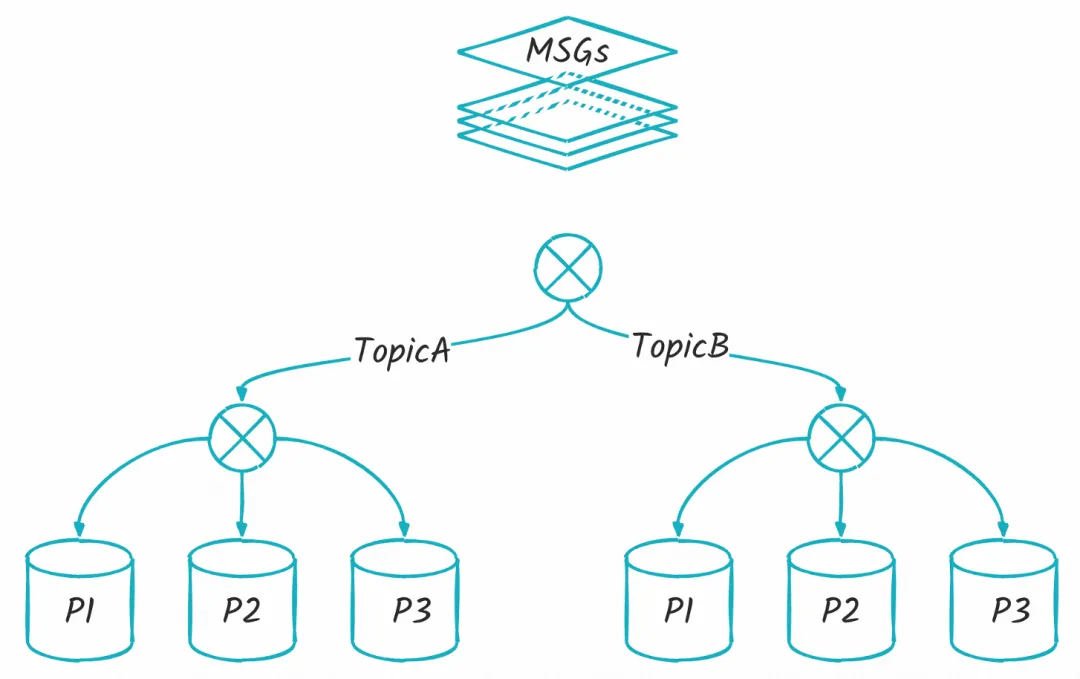
首先它会根据这一批消息的某些属性,挑选出对应的队列,也就是上图中最底下的「p1、p2…」,在选定好队列之后,就可以进行后续的写入等操作了,这也是为什么必须要求相同 Topic,因为不同的 Topic 是没法选定同一个队列的。
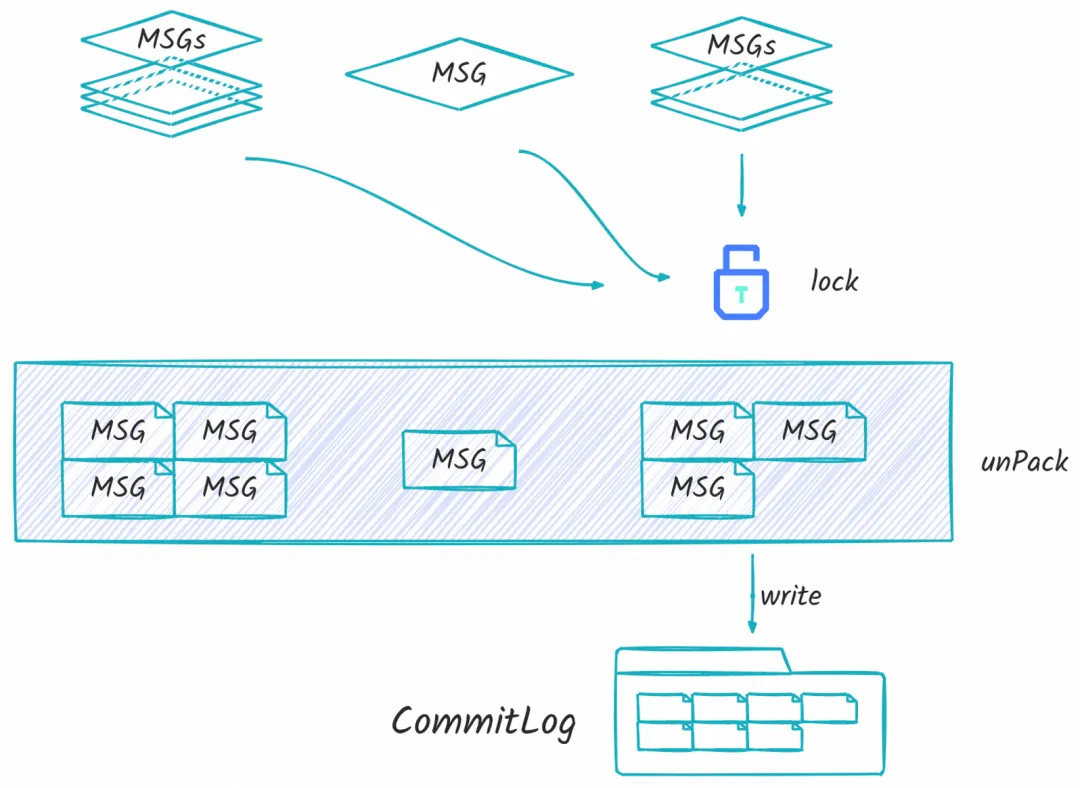
接下来就到了上图所示流程,可以看到这里分别来了三个消息,分别是 《四条消息》《一条消息》《三条消息》,接下来他们会依次进入 unPack 流程,这个流程有点像序列化过程,因为从客户端发送上来的消息都是内存结构的,距离实际存储在文件系统中的结构还有一些不同。在 unPack 过程中,会分别解包成:四条消息、一条消息、三条消息;此时和连续 Send 八条消息是没有任何区别的,也就是在这一刻,批量消息的生命周期就走到了尽头,此刻往后,“众生平等、不分你我”。
也正是这个机制,Consumer 其实并不知道 Producer 发送的时候“到底是发射弓箭,还是点燃大炮”。这么做有个非常好的优点,那就是有着最高的兼容性,一切的一切好像和单条消息 Send 的经典用法没有任何区别,在这种情况下,每条消息都有最高的自由度,例如各自独立的 tag、独立的 keys、唯一的 msgId 等等,而基于这些所衍生出来的生态(例如消息轨迹)都是无缝衔接的。也就是说:只需要更换发送者使用的 Send 接口,就可以获得极大的发送性能提升,而消费者端无需任何改动。
索引构建流水线改造
我一向用词都非常的严谨,可以看到上一段的结尾:“获得极大的发送性能提升”,至于为什么这么讲,是因为距离整体系统的提升还有一些距离,也就是这一段的标题“索引构建流水线改造”。
首先我们要有一个共识,那就是对于消息队列这种系统,整体性能上限比值“消费/生产”应该要满足至少大于等于一,因为大部分情况下,我们的生产出来的消息至少应该被消费一次(否则直接都不用 Send 了岂不美哉)。
其实在以往,发送性能没有被拔高之前,它就是整个生产到消费链路上的短板,也就是说消费速率可以轻松超过生产速率,整个过程也就非常协调。but!在使用早期批处理模型后,生产速率的大幅度提升就暴露了另外一个问题,也就是会出现消费速率跟不上生产的情况,这种情况下,去谈整个系统的性能都是“无稽之谈”。
而出现消费速率短板的原因,还要从索引构建讲起。由于消费是要找到具体的消息位置,那就必须依赖于索引,也就是说,一条消息的索引构建完成之前,是无法被消费到的。 下图就是索引构建流程的简易图:
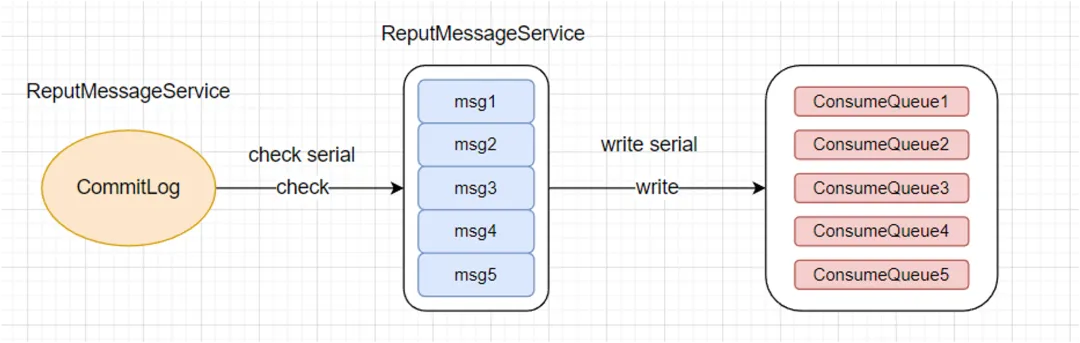
这是整个直接决定消费速率上限的流程。通过一个叫 ReputMessageService 的线程,顺序扫描 CommitLog 文件,将其分割为一条一条的消息,再对这些消息进行校验等行为,将其转换成一条条的索引信息,并写入对应分区的 ConsumeQueue 文件。
整个过程是完全串行的,从分割消息,到转换索引,到写入文件,每一条消息都要经过这么一次流转。因为一开始是串行实现,所以改造起来也非常的自然,那就是通过流水线改造,提高它的并发度,这里面有几个需要解决的问题:
- CommitLog 的扫描过程并行难度高,因为每条消息的长度是不一致的,无法简单地分割出消息边界来分配任务。
- 单条消息的索引构建任务并不重,因此不能简单忽略掉任务流转过程中的开销(队列入队出队)。
- 写入 ConsumeQueue 文件的时候要求写入时机队列维度有序,否则会带来额外的检查开销等。
针对这几个难点,在设计中也引入了“批量处理”的思路,其实大到架构设计、小到实现细节,处处都体现了这一理念,下图就是改造后的流程:
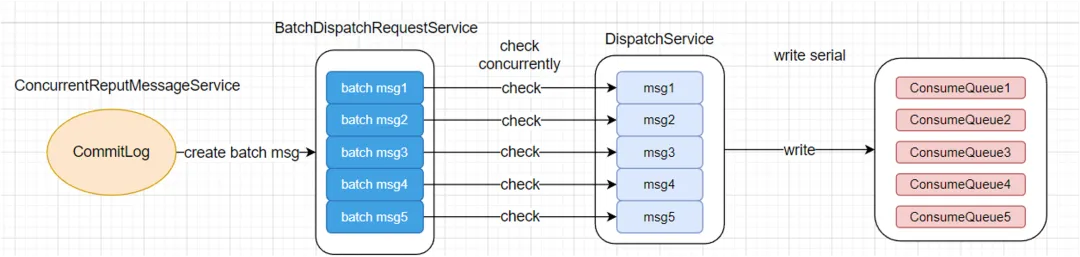
由于 CommitLog 扫描过程很难并行化处理,那就干脆不做并行化改造了,就使用单线程去顺序扫描,但是扫描的时候会进行一个简单的批处理,扫描出来的消息并不是单条的,而是尽可能凑齐一个较大的 buffer 块,默认是 4MB,这个由多条消息构成的 buffer 块我们不妨将其称为一个 batch msg。
然后就是对这些 batch msg 进行并行解析,将 batch msg 以单条消息的粒度扫描出来,并构建对应的 DispatchRequest 结构,最终依次落盘到 ConsumeQueue 文件中。其中的关键点在于 batch msg 的顺序如何保证,以及 DispatchRequest 在流转时怎么保证顺序和效率。为此我专门实现了一个轻量级的队列 DispatchRequestOrderlyQueue,这个 Queue 采用环状结构,可以随着顺序标号不断递进,并且能做到 “无序入队,有序出队” ,详细设计和实现均在开源 RocketMQ 仓库中,这里就不多赘述。
在经过改造后,索引构建流程不再成为扯后腿的一员,从原本眼中钉的角色美美隐身了~
BatchCQ 模型
经过上述索引构建流水线改造后,整个系统也就实现了最基本的批处理模型,可以在最小修改、最高兼容性的情况下让性能获得质的飞跃。
但是这并不够!因为早期的模型出于兼容性等考虑,所以依旧束手束脚的,于是 BatchCQ 模型诞生了,主要原因分为两个维度:
-
性能上:
- 早期模型中,Broker 端在准备写入阶段需要进行解包,会有一定的额外开销。
- CommitLog 文件中不具备批量信息,索引需要分多次构建。
-
能力上:
- 无法实现端到端的批量行为,如加密、压缩。
那 BatchCQ 又是如何改进上述的问题的呢?其实也非常地直观,那就是“见字如面”,将 ConsumeQueue 也批量化。这个模型去掉 Broker 端写入前的解包行为,索引也只进行一次构建:

就像上图所示,如果把索引比做信封,原先每个信封只能包含一份索引信息,在批量化后则可以塞下任意数量的索引信息,具体的存储结构也发生了较大变化:
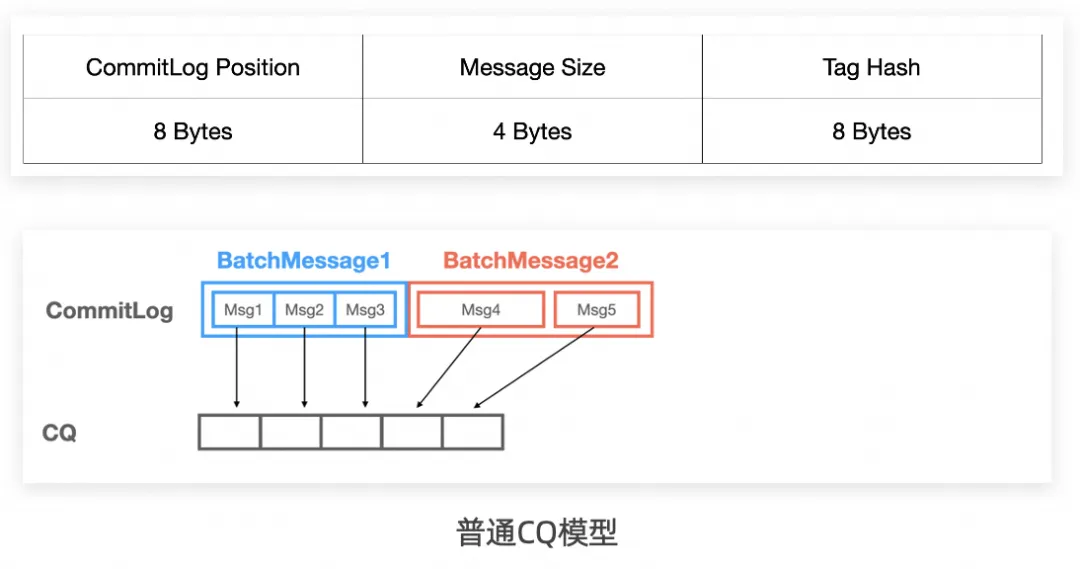
比如说如果来了两批消息,分别是(3+2)条,在普通的 CQ 模型里会分别插入 5 个 slot,分别索引到 5 条消息。但是在 BatchCQ 模型中,(3+2)条消息会只插入 2 个 slot,分别索引到 3 条以及 2 条。
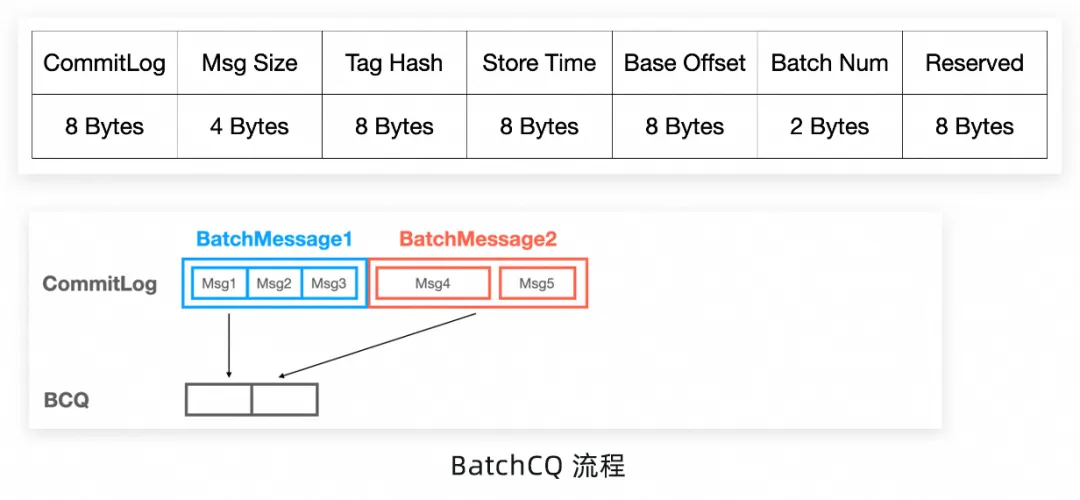
也是因为这个特点,所以 CQ 原有的格式也发生了变化,为了记录更多信息不得不加入 Base Offset、Batch Num 等元素,而这些更改也让原来定位索引位置的逻辑发生了变化。
- 普通 CQ:每个 Slot 定长,【Slot 长度 * QueueOffset】位点可以直接找到索引,复杂度 O(1)。
- BatchCQ:通过二分法查找,复杂度 O(log n)。
虽然这部分只涉及到了 ConsumeQueue 的修改,但是它作为核心链路的一环,影响是很大的,首先一批的消息会被当作同一条消息来处理,不需要重新 unPack ,而且这些消息都会具有相同的 TAG、Keys 甚至 MessageId,想唯一区分同一批的消息,只能根据它们的 QueueOffset 了,这一点会让消息轨迹等依靠 MessageId 的能力无法直接兼容使用,但是消息的处理粒度依然可以保持不变(依赖的是 QueueOffset)。
AutoBatch 模型
通过 BatchCQ 改造之后,我们其实已经获得极致的吞吐量了。那个 AutoBatch 又是个啥呢?
这里又要从头说起,在早期批处理模型的总结里,提到了一个比较大的缺陷,那就是“使用起来不够顺手”,用户是需要关心各种约束条件的,就像前面提到的 Topic、消息类型、特殊 Flag 等,在 BatchCQ 里面其实是新增了 Keys、Tag 等维度的限制,错误使用会出现一些非预期的情况。
不难看出,无论是早期批处理模型、还是 BatchCQ 模型,使用起来都有一定的学习成本,除了需要关注各种使用方式外,想要用好,还有一些隐藏在暗处的问题需要主动去解决:
- 无论是早期的批处理模型,还是 batchCQ 模型,都需要发送端自行将消息分类打包。
- 消息分类和打包成本高,分类需要关心分类依据,打包需要关心触发时机。
- 分类依据复杂,早期批处理模型需要关注多个属性,batchCQ 在这基础上新增了多个限制。
- 打包时机不易掌握,使用不当容易出现性能下降、时延不稳定、分区不均衡等问题。
为了解决以上问题,AutoBatch 应运而生,它就是一台能自动分拣的无情打包机器,全天候运转,精密又高效,将以往需要用户关注的细节统统屏蔽,它具有以下几个优点:
- AutoBatch 托管分类和打包能力,只需要简单配置即可使用。
- 用户侧不感知托管的过程,使用原有发送接口即可享受批处理带来的性能提升,同时兼容同步发送和异步发送。
- AutoBatch 同时兼容早期的批处理模型和 batchCQ 模型。
- 实现轻量,性能优秀,设计上优化延时抖动、小分区等问题。

首先到底有多简单呢?让我们来看一下:
// 发送端开启 AutoBatch 能力
rmqProducer.setAutoBatch(true);
也就是说,只需要加入这么一行,就可以开启 RocketMQ 的性能模式,获得早期的批处理模型或者 BatchCQ 模型带来的极致吞吐量提升。在开启 AutoBatch 的开关后,用户所有已有的行为都不需要作出改变,使用原来经典的 Send(Message msg)即可;当然也可以进行更精细的内存控制和延时控制:
// 设置单个 MessageBatch 大小(kb)
rmqProducer.batchMaxBytes(32 * 1024);
// 设置最大聚合等待时间(ms)
rmqProducer.batchMaxDelayMs(10);
// 设置所有聚合器最大内存使用(kb)
rmqProducer.totalBatchMaxBytes(32 * 1024 * 1024);
那么它具体轻量在哪?又高效在哪?下面这个简易的流程图应该能给大家一个答案:
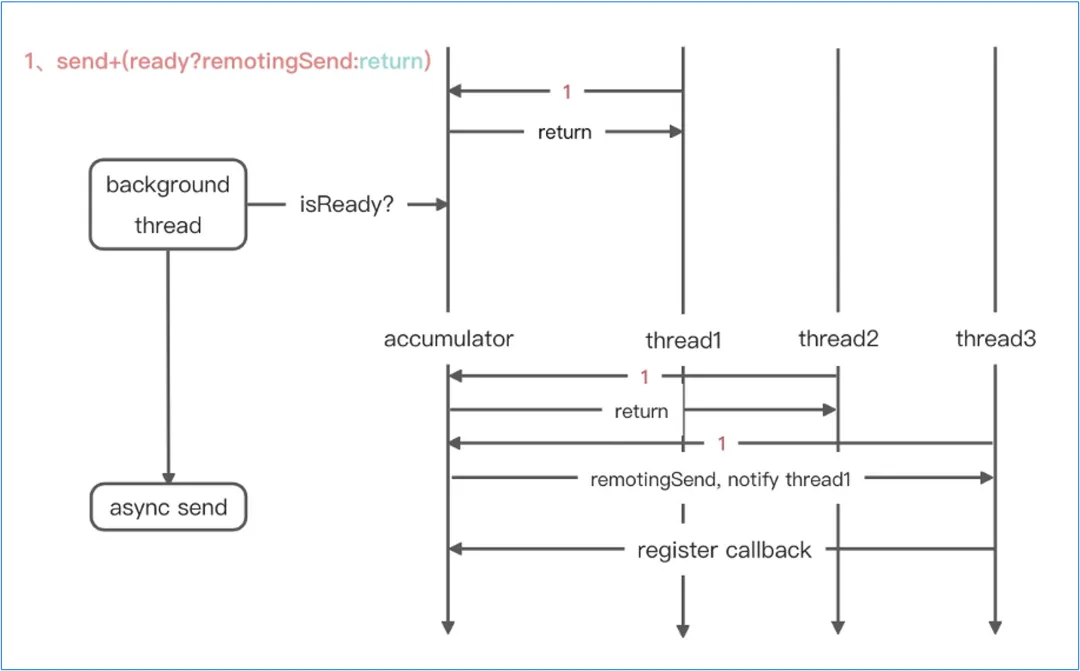
首先它只引入了一个单线程的背景线程——background thread,这个背景线程以 1/2 的 maxDelayMs 周期运行,将扫描到超过等待时机缓冲区的消息提交到异步发送的线程池中,此时就完成了时间维度的聚合。空间维度的聚合则是由发送线程在传递时进行检查,如果满足 maxBytes,则原地发送。
整个设计非常地精简,只额外引入了一个周期运行的线程,这样做可以避免因为 AutoBatch 模型本身出现性能短板,而且 batchMessage 的序列化过程也做了精简,去掉了发送时候所有的检测(在聚合过程中已提前分类)。
才艺展示
上面分享了 RocketMQ 在批处理模型上的演进,那么它们具体效果也就必须拉出来给大家做一个才艺展示了,以下所有的压测结果均来自于 Openmessaging-Benchmark 框架,压测中使用的各项配置如下所示:
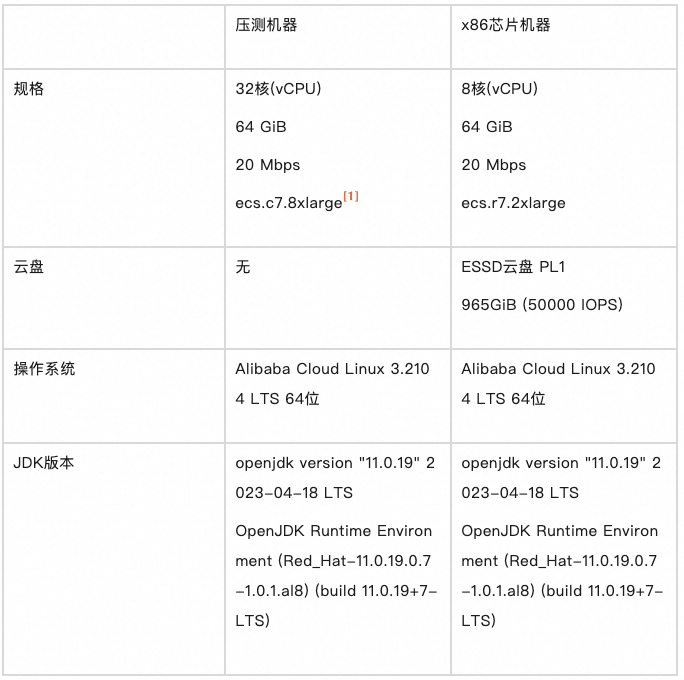
准备工作
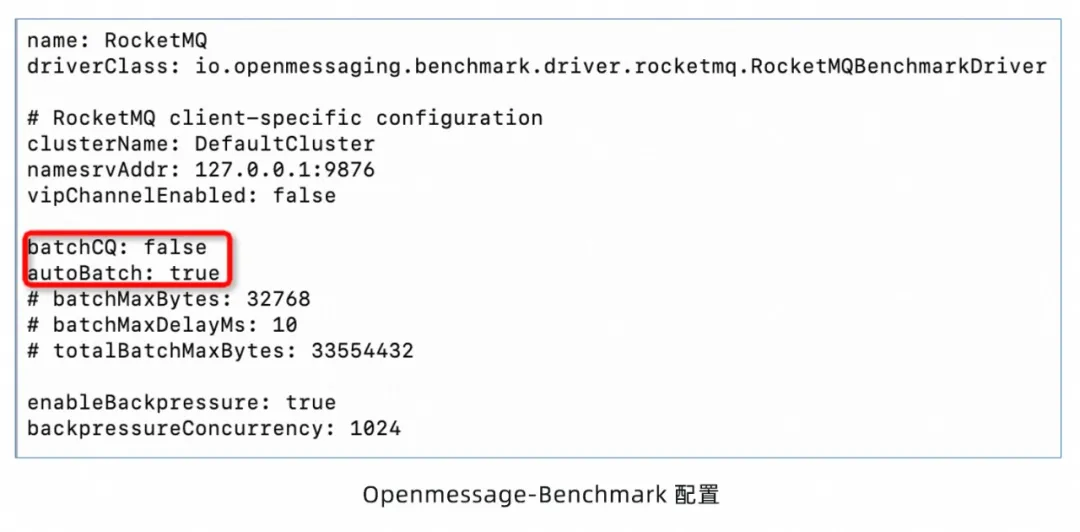
为 Openmessaging-Benchmark 进行压测环境,首先部署一套开源社区上最新的 RocketMQ,然后配置好 Namesrv 接入点等信息,然后打开 RocketMQ 的性能模式——AutoBatch,将 autoBatch 字段设置为 true:
早期批处理模型**
bin/benchmark --drivers driver-rocketmq/rocketmq.yaml workloads/1-topic-100-partitions-1kb-4p-4c-1000k.yaml
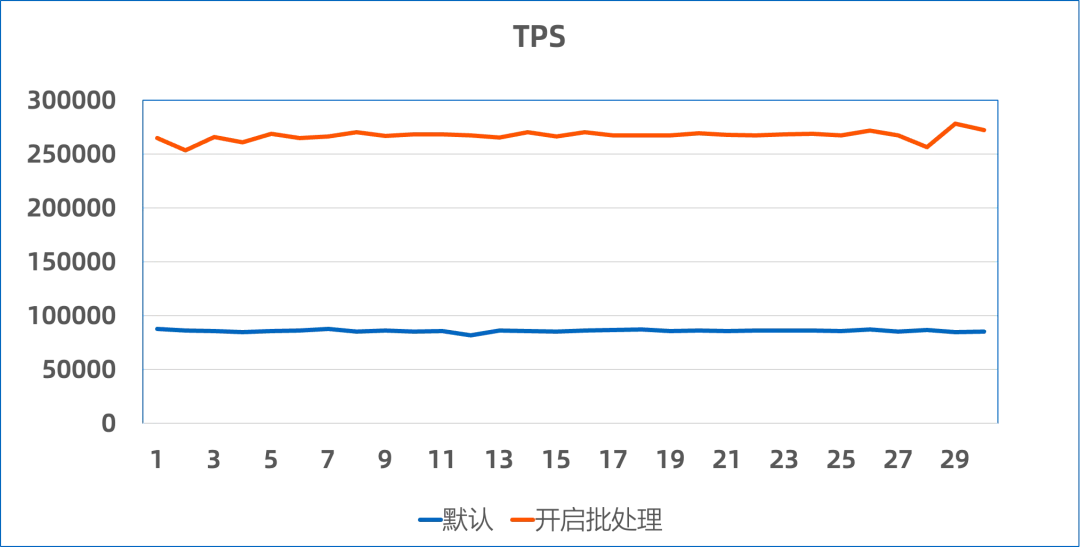
开启 autobatch 能力后,就会使用早期批处理模型进行性能提升,可以看到提升幅度非常大,由原来的 8w 提升至 27w 附近,为原来的 300%。
索引构建流水线优化
流水线优化是需要在服务端开启的,下面是一个简单的配置例子:
// 开启索引构建流水线优化
enableBuildConsumeQueueConcurrently=true
// 调整内存中消息最大消费阈值
maxTransferBytesOnMessageInMemory=256M
maxTransferCountOnMessageInMemory=32K
// 调整磁盘中消息最大消费阈值
maxTransferBytesOnMessageInDisk=64M
maxTransferCountOnMessageInDisk=32K
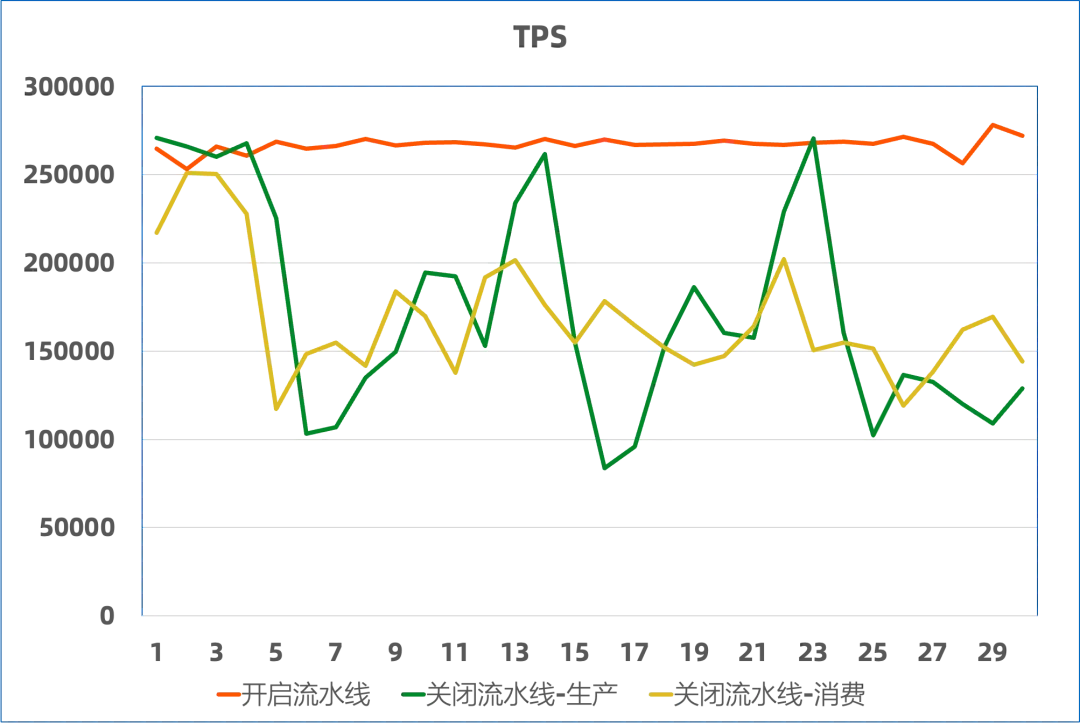
可以看到,只有开启索引构建优化,才能做到稳稳地达到 27w 的吞吐,在没有开启的时候,消费速率不足会触发冷读直至影响到整个系统的稳定性,同时也不具备生产意义,所以在使用批量模型的时候也务必需要开启索引构建优化。
BatchCQ 模型
BatchCQ 模型的使用与前面提到的两者不同,它不是通过开关开启的,BatchCQ 其实是一种 Topic 类型,当创建 topic 的时候指定其为 BatchCQ 类型,既可拥有最极致的吞吐量优势。
// Topic 的各种属性在 TopicAttributes 中设置
public static final EnumAttribute QUEUE_TYPE_ATTRIBUTE = new EnumAttribute("queue.type", false, newHashSet("BatchCQ", "SimpleCQ"), "SimpleCQ");
topicConfig.getAttributes().put("+" + TopicAttributes.QUEUE_TYPE_ATTRIBUTE.getName(), "BatchCQ");
当使用 BatchCQ 模型的时候,与早期批处理模型已经有了天壤之别,因此我们寻求了和开源 Kafka 的对比,部署架构如下:
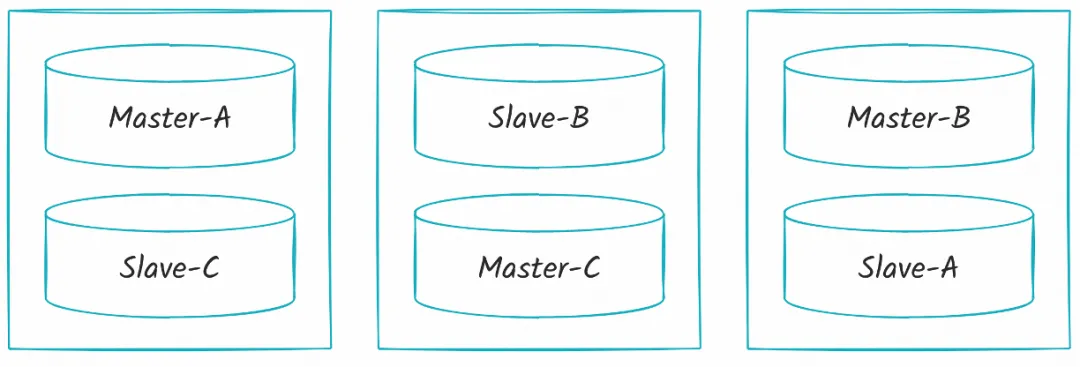
RocketMQ
3 主 3 备架构,使用轻量级 Container 部署。
- 节点 1: Master-A,Slave-C
- 节点 2: Master-C,Slave-B
- 节点 3: Master-B,Slave-A
Kafka
3 个节点,设置分区副本数为 2。
压测结果
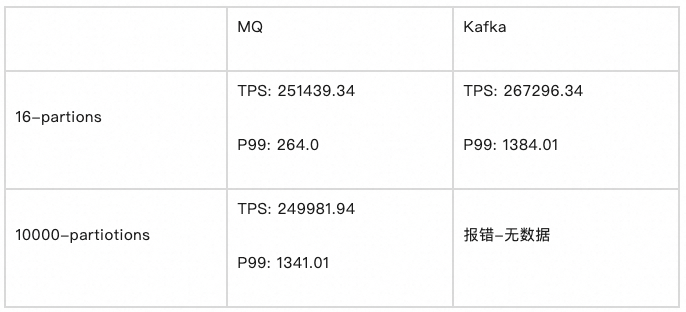
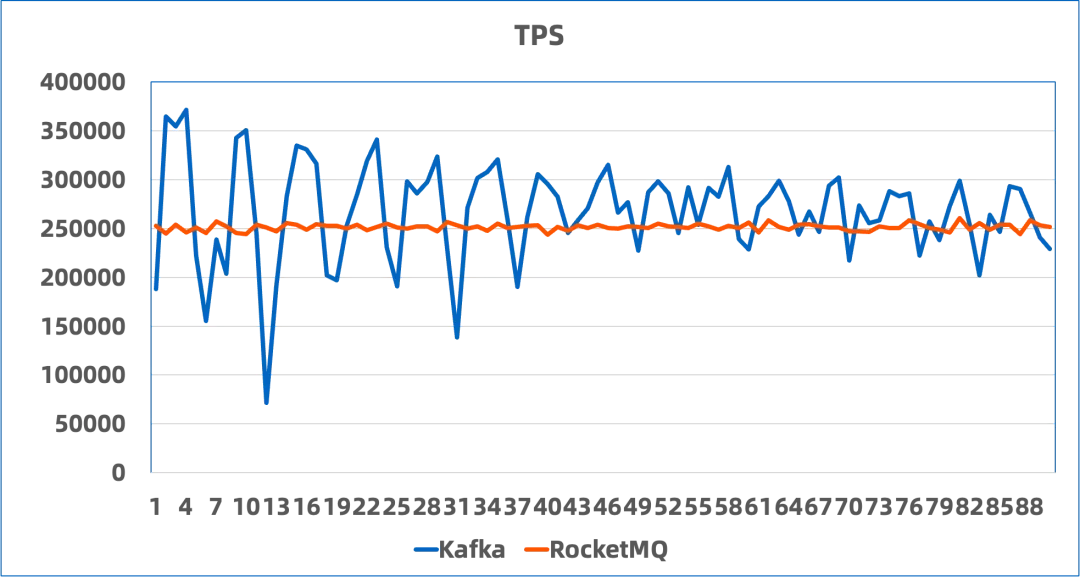
可以看到,在使用 BatchCQ 类型的 Topic 时,RocketMQ 与 Kafka 的性能基本持平:
- 16-partitions,二者吞吐量相差 5% 以内,且 RocketMQ 则具有明显更低的延时表现。
- 10000-partitions,得益于 RocketMQ 的存储结构更为集中,在大量分区场景下吞吐量几乎保持不变。而Kafka在默认配置的情况下出现报错无法使用。
因此在极致吞吐量的需求下,BatchCQ 模型能够很好地承接极致需求的流量,而且如果更换性能更好的本地磁盘,同样的机器配置能达到更高的上限。
相关链接:
[1] ecs.c7.8xlarge
https://help.aliyun.com/zh/ecs/user-guide/overview-of-instance-families

若您希望深入了解 RocketMQ,推荐访问并收藏网站:https://rocketmq-learning.com/