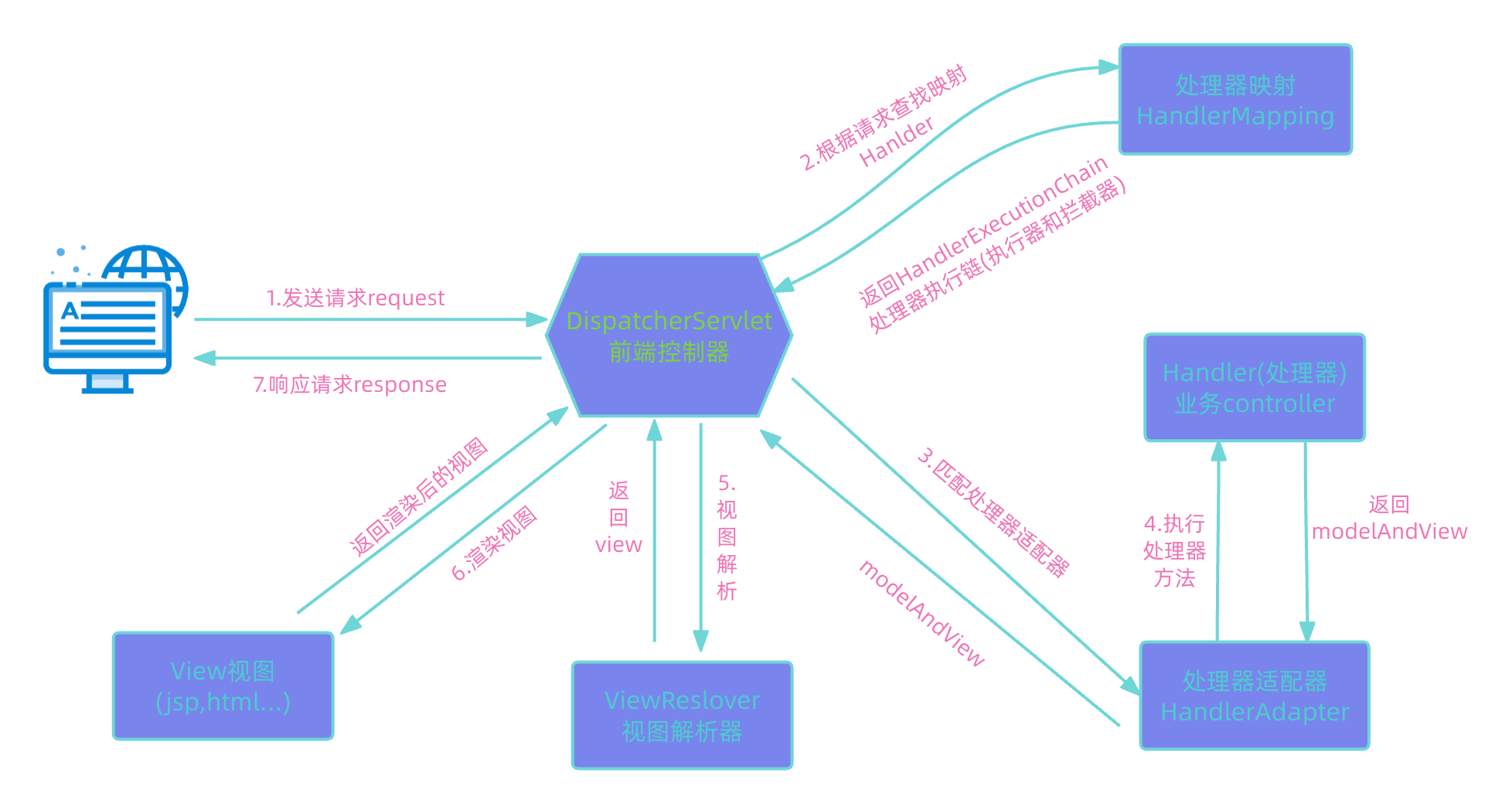
在进行网络爬虫时,使用代理IP可以有效地避免被目标网站封禁,提升数据抓取的成功率。本文将详细介绍如何在Java爬虫中设置代理IP,并提供一些实用的技巧和示例代码。

为什么需要代理IP?
在进行爬虫操作时,频繁的请求可能会引起目标网站的注意,甚至导致IP被封禁。就像一只贪心的小猫不停地偷鱼吃,迟早会被发现。为了避免这种情况,我们可以使用代理IP,模拟多个用户,从而降低被封禁的风险。
获取代理IP
获取代理IP的方式有很多种,你可以选择免费代理IP或者付费代理IP。免费代理IP通常质量不稳定,速度慢,容易失效;而付费代理IP则提供更高的稳定性和速度,适合需要高频率爬取数据的场景。
天启IP代理-企业级HTTP代理|Socks5代理|动静态IP代理服务商【在线免费试用】天启HTTP专注企业级优质高匿IP代理服务,提供https代理、Socks5代理、动静态代理、爬虫代理等国内外IP代理服务器,在线网页或软件app代理IP方便快捷,可定制HTTP代理IP池,已为数万用户提供私人代理IP定制,助力大数据云时代。![]() https://www.tianqiip.com/?did=aEoezZ
https://www.tianqiip.com/?did=aEoezZ
在Java中使用代理IP
在Java中使用代理IP可以通过设置系统属性或使用HttpClient库来实现。下面将分别介绍这两种方法。
方法一:设置系统属性
通过设置系统属性,我们可以全局地使用代理IP。以下是示例代码:
import java.net.*;
import java.io.*;
public class ProxyExample {
public static void main(String[] args) throws Exception {
// 设置代理IP
System.setProperty("http.proxyHost", "123.123.123.123");
System.setProperty("http.proxyPort", "8080");
System.setProperty("https.proxyHost", "123.123.123.123");
System.setProperty("https.proxyPort", "8080");
// 发送请求
URL url = new URL("http://example.com");
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
BufferedReader in = new BufferedReader(new InputStreamReader(connection.getInputStream()));
String inputLine;
while ((inputLine = in.readLine()) != null) {
System.out.println(inputLine);
}
in.close();
}
}
在这个例子中,我们通过设置系统属性来配置代理IP,从而使所有的HTTP和HTTPS请求都通过代理IP发送。
方法二:使用HttpClient库
Apache的HttpClient库提供了更灵活的方式来设置代理IP。以下是示例代码:
import org.apache.http.HttpHost;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import java.io.BufferedReader;
import java.io.InputStreamReader;
public class HttpClientProxyExample {
public static void main(String[] args) throws Exception {
// 设置代理IP
HttpHost proxy = new HttpHost("123.123.123.123", 8080, "http");
RequestConfig config = RequestConfig.custom()
.setProxy(proxy)
.build();
CloseableHttpClient httpClient = HttpClients.custom()
.setDefaultRequestConfig(config)
.build();
// 发送请求
HttpGet request = new HttpGet("http://example.com");
CloseableHttpResponse response = httpClient.execute(request);
BufferedReader in = new BufferedReader(new InputStreamReader(response.getEntity().getContent()));
String inputLine;
while ((inputLine = in.readLine()) != null) {
System.out.println(inputLine);
}
in.close();
response.close();
httpClient.close();
}
}
通过这种方式,我们可以更灵活地设置和管理代理IP,适合需要动态切换代理IP的场景。
代理池的使用
为了更加高效地使用代理IP,我们可以创建一个代理池,随机选择代理IP进行请求。这样可以进一步降低被封禁的风险。以下是一个简单的代理池示例:
import org.apache.http.HttpHost;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.util.Random;
public class ProxyPoolExample {
public static void main(String[] args) throws Exception {
// 代理IP列表
String[] proxies = {
"123.123.123.123:8080",
"124.124.124.124:8080",
"125.125.125.125:8080"
};
// 随机选择一个代理IP
Random random = new Random();
String proxyAddress = proxies[random.nextInt(proxies.length)];
String[] proxyParts = proxyAddress.split(":");
HttpHost proxy = new HttpHost(proxyParts[0], Integer.parseInt(proxyParts[1]), "http");
RequestConfig config = RequestConfig.custom()
.setProxy(proxy)
.build();
CloseableHttpClient httpClient = HttpClients.custom()
.setDefaultRequestConfig(config)
.build();
// 发送请求
HttpGet request = new HttpGet("http://example.com");
CloseableHttpResponse response = httpClient.execute(request);
BufferedReader in = new BufferedReader(new InputStreamReader(response.getEntity().getContent()));
String inputLine;
while ((inputLine = in.readLine()) != null) {
System.out.println(inputLine);
}
in.close();
response.close();
httpClient.close();
}
}
通过这种方式,每次请求都会随机选择一个代理IP,从而使爬虫更加难以被检测到。
代理IP的验证
在使用代理IP之前,我们需要验证这些代理IP是否可用。以下是一个简单的验证代码:
import org.apache.http.HttpHost;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import java.io.IOException;
public class ProxyValidator {
public static boolean isValidProxy(String proxyAddress) {
String[] proxyParts = proxyAddress.split(":");
HttpHost proxy = new HttpHost(proxyParts[0], Integer.parseInt(proxyParts[1]), "http");
RequestConfig config = RequestConfig.custom()
.setProxy(proxy)
.setConnectTimeout(5000)
.setSocketTimeout(5000)
.build();
try (CloseableHttpClient httpClient = HttpClients.custom()
.setDefaultRequestConfig(config)
.build()) {
HttpGet request = new HttpGet("http://example.com");
CloseableHttpResponse response = httpClient.execute(request);
return response.getStatusLine().getStatusCode() == 200;
} catch (IOException e) {
return false;
}
}
public static void main(String[] args) {
String proxy = "123.123.123.123:8080";
if (isValidProxy(proxy)) {
System.out.println("Proxy " + proxy + " is valid.");
} else {
System.out.println("Proxy " + proxy + " is invalid.");
}
}
}
通过这种方式,我们可以确保使用的代理IP是有效的,从而避免在爬虫过程中遇到不必要的麻烦。
<a href="https://www.tianqiip.com/">天启代理</a>总结
代理IP在Java爬虫中的应用不仅可以提高爬虫的效率,还能有效地防止IP被封禁。通过合理地选择和使用代理IP,你的爬虫将变得更加灵活和强大。希望这篇文章能帮助你更好地理解和使用代理IP,让你的爬虫之旅更加顺利。


![World of Warcraft [CLASSIC][80][Grandel] Call to Arms: Strand of the Ancients](https://i-blog.csdnimg.cn/direct/1e38bfb295194ea2bd7f2977693137c1.jpeg)