摘要
本报告利用Java和Selenium爬虫技术获取数据,并使用ECharts库对薪资数据进行可视化分析,旨在探究不同经验和学历的薪资分布情况。
数据来源
数据来源于Boss直聘,使用Java结合Selenium库进行数据抓取。
- 数据总数:约2000家企业数据
- 数据类型:java岗位、全栈、前端
- 数据地区:深圳、广州
数据清洗
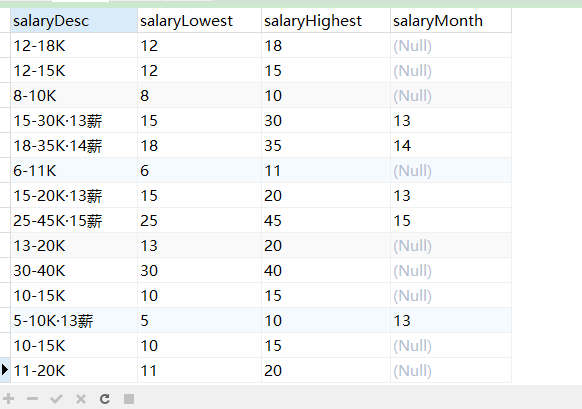
- 比如15-30K·13薪,清洗为3个字段分别存储
UPDATE boss_index
SET
salaryLowest = (
SUBSTRING_INDEX(salaryDesc, '-', 1)
),
salaryHighest = (
SUBSTRING_INDEX(SUBSTRING_INDEX(salaryDesc, '-', -1), 'K', 1)
),
salaryMonth = (
CASE
WHEN salaryDesc LIKE '%·%' THEN
REPLACE(SUBSTRING_INDEX(salaryDesc, '·', -1), '薪', '')
ELSE
NULL
END
);
数据分析
- 不同学历、不同经验、不同地区薪资分布,使用中位数和众数进行可以实话展示
- 中位数
- 众数
结果展示
tips:数据y轴大于100,结果为xx元/天










核心代码
爬虫
ChromeOptions ops = new ChromeOptions();
ops.addArguments("--remote-allow-origins=*");
System.setProperty("webdriver.chrome.driver", "driver/chromedriver.exe"); //chromedriver.exe存放的路径
System.setProperty("webdriver.chrome.whitelistedIps", "");
ChromeDriver driver = new ChromeDriver(ops);
driver.get("https://www.zhipin.com/web/geek/job?query=%E5%85%A8%E6%A0%88%E5%B7%A5%E7%A8%8B%E5%B8%88&city=101280100");
driver.manage().window().maximize();
数据分析sql
中位数
<select id="getModeSalaryHighest" resultType="com.example.springboot.dto.MedianSalaryResultDTO">
SELECT
tag AS group_tag_inner,
salaryHighest AS mode_salaryHighest
FROM
(SELECT
tag,
salaryHighest,
COUNT(*) AS count
FROM
boss_index
WHERE
salaryHighest IS NOT NULL
GROUP BY
tag,
salaryHighest
) AS salary_highest_counts
JOIN
(SELECT
tag AS tag_max_count,
MAX(count) AS max_count
FROM
(SELECT
tag,
salaryHighest,
COUNT(*) AS count
FROM
boss_index
WHERE
salaryHighest IS NOT NULL
<if test="jobName != null">
and jobName like concat('%', #{jobName}, '%')
</if>
<if test="areaDistrict != null">
and areaDistrict like concat('%', #{areaDistrict}, '%')
</if>
<if test="educationLabel != null">
and education_label like concat('%', #{educationLabel}, '%')
</if>
GROUP BY
tag,
salaryHighest
) AS subquery
GROUP BY
tag
) AS max_count_highest ON salary_highest_counts.tag = max_count_highest.tag_max_count AND salary_highest_counts.count = max_count_highest.max_count
GROUP BY
salary_highest_counts.tag,
salary_highest_counts.salaryHighest
</select>
众数
<select id="getMedianSalarieshigh" resultMap="MedianSalaryResultMap">
SELECT
tag AS group_tag_inner,
salaryHighest AS median_salaryHighest
FROM
(
SELECT
tag,
salaryHighest,
@rowindex := IF(@group_tag = tag, @rowindex + 1, 1) AS rowindex, -- 按tag分组累加行号
@group_tag := tag AS group_tag -- 更新tag
FROM
boss_index,
(SELECT @rowindex := 0, @group_tag := '') var_init -- 初始化变量
WHERE
salaryHighest IS NOT NULL
ORDER BY
tag,
salaryHighest
) AS ranked_salaries
JOIN
(
SELECT
tag AS tag_total_rows,
COUNT(*) AS total_rows
FROM
boss_index
WHERE
salaryHighest IS NOT NULL
<if test="jobName != null">
and jobName like concat('%', #{jobName}, '%')
</if>
<if test="areaDistrict != null">
and areaDistrict like concat('%', #{areaDistrict}, '%')
</if>
<if test="educationLabel != null">
and education_label like concat('%', #{educationLabel}, '%')
</if>
GROUP BY
tag
) AS total_rows ON ranked_salaries.tag = total_rows.tag_total_rows
WHERE
rowindex IN (FLOOR((total_rows + 1) / 2), FLOOR((total_rows + 2) / 2)) -- 使用总行数变量来确定中间的行号
GROUP BY
group_tag_inner
</select>

![[WUSTCTF2020]spaceclub(我把输入的字符切片研究了)](https://i-blog.csdnimg.cn/direct/8151559ca3fe49849543b1a3ec4dc783.png)