1.红黑树的迭代器
(本篇代码基于我写的红黑树的实现这篇博客)
迭代器的好处是可以方便遍历,是数据结构的底层实现与用户透明。如果想要给红黑树增加迭代器,需要考虑以下问题:
begin()与end(): STL明确规定,begin()与end()代表的是一段前闭后开的区间,而对红黑树进行中序遍历后, 可以得到一个有序的序列,因此:begin()可以放在红黑树中最小节点(即最左侧节点)的位置,end()放在最大节点(最右侧节点)的下一个位置,关键是最大节点的下一个位置在哪块? 能否给成nullptr呢?答案是行不通的,因为对end()位置的迭代器进行--操作,必须要能找最后一个元素,此处就不行,因此最好的方式是将end()放在头结点的位置:
1.2.迭代器的定义
迭代器我们采用类模板的方式来进行,Ref是T的引用,Ptr是T的指针
typedef __RBTreeIterator<T,const T&,const T*> ConstIterator;Node是我们红黑树的节点,Self是我们迭代器类型本身,构造我们也就选一个红黑树的节点进行拷贝构造就好了。
1.3.operator++()
//++ Self operator++() { if (_node->_right) { Node* leftMin = _node->_right; while (leftMin->_left) { leftMin = leftMin->_left; } _node = leftMin; } else { Node* cur = _node; Node* parent = _node->_parent; while (parent && cur == parent->_right) { cur = parent; parent = parent->_parent; } _node = parent; } return *this; }迭代器的出现是为了我们更方便地去进行增删查改,所以我们要能有规律的查找元素,我们来分析++的逻辑,我们的遍历是按照升序的方式,所以,我们要找到比当前节点大的下一个节点,我们先来看一下当前节点是否有右子树,有的话就往右子树的最小左子树去找,那个节点就是我们要找的下一个节点。如果我们的当前节点右子树是空,我们就要一直往上更新,直到为左子树然后它的父亲就是下一个节点了。
1.4*,->,!=
//* Ref operator*() { return _node->_data; } //-> Ptr operator->() { return &_node->_data; } //!= bool operator!=(const Self& s) { return _node != s._node; }解引用就把数据返回去,->就把数据的地址返回去,!=就是判断迭代器访问的与你指定的是否相等。
2.改造红黑树
迭代器构建出来了,我们也要对红黑树进行一些简单的改造,我来讲一些新加入的部分。
类模板
template<class K, class T, class KeyofT> class RBTree { typedef RBTreeNode<T> Node; public: typedef __RBTreeIterator<T, T&, T*> Iterator; typedef __RBTreeIterator<T,const T&,const T*> ConstIterator;我们的类模板新增加了一个类型KeyofT,这是我们map和set要传入的一个仿函数,具体是什么我后面会讲,它的功能是取出key键值。下面,我们重命名红黑树节点,迭代器也重命名了两个,一个是const修饰的,一个是普通的。
构造
//构造函数 RBTree() = default; //拷贝构造函数 RBTree(const RBTree<K, T, KeyofT>& t) { _root = Copy(t._root); } Node* Copy(Node* root) { if (root == nullptr) { return nullptr; } Node* newroot = new Node(root->_data); newroot->_col = root->_col; newroot->_left = Copy(root->_left); if (newroot->_left) newroot->_left->_parent = newroot; newroot->_right = Copy(root->_right); if (newroot->_right) newroot->_right->_parent = newroot; return newroot; }构造方面我们要编写拷贝构造,所以我们在无参构造后面加一个default关键字,让编译器显示默认生成。然后我们的拷贝构造采用递归的方式将每一个节点拷贝下来,我们使用前序遍历的方式将节点拷贝下来就好了。
赋值运算符重载
//赋值运算符重载 RBTree<K, T, KeyofT>& operator=(RBTree<K, T, KeyofT> t) { swap(_root, t._root); return *this; }赋值运算符重载我们复用拷贝构造函数的代码,我们的参数会自动调用拷贝构造,然后我们就只要将两根节点交换就可以了。
析构函数
//析构函数 ~RBTree() { Destroy(_root); _root = nullptr; } void Destroy(Node* root) { if (root == nullptr) { return; } Destroy(root->_left); Destroy(root->_right); delete(root); root = nullptr; }析构我们则是采用后序遍历的方法进行递归删除。
查找
//Find() Iterator Find(const T& data) { KeyofT kot; Node* parent = nullptr; Node* cur = _root; while (cur) { if (kot(data) > kot(cur->_data)) { parent = cur; cur = cur->_right; } else if (kot(data) < kot(cur->_data)) { parent = cur; cur = cur->_left; } else { return Iterator(cur); } } return end(); }查找我们就利用二叉搜索树的规则去查找就可以了(要查找的节点比当前节点小就往左,大就往右),kot是仿函数类型的变量,它的作用是返回key值,因为我们插入的时候是按key值来进行插入的。
begin()/end()
//begin() ConstIterator begin() const { Node* leftMin = _root; while (leftMin && leftMin->_left) { leftMin = leftMin->_left; } return ConstIterator(leftMin); } //end() ConstIterator end() const { return ConstIterator(nullptr); } //begin() Iterator begin() { Node* leftMin = _root; while (leftMin && leftMin->_left) { leftMin = leftMin->_left; } return Iterator(leftMin); } //end() Iterator end() { return Iterator(nullptr); }begin和end我们分别设计了const修饰的和普通的两组,普通的begin我们就找最小的节点,也就是最左边,end我们就是一个空节点,我们返回的时候都是复用迭代器的拷贝构造,const修饰的版本思路也是一模一样的,只不过加上了const修饰。
插入
//插入 pair<Iterator,bool> Insert(const T& data) { if (_root == nullptr) { _root = new Node(data); _root->_col = BLACK; return make_pair(Iterator(_root),true) ; } KeyofT kot; Node* parent = nullptr; Node* cur = _root; while (cur) { if (kot(data) > kot(cur->_data)) { parent = cur; cur = cur->_right; } else if (kot(data) < kot(cur->_data)) { parent = cur; cur = cur->_left; } else { return make_pair(Iterator(cur), false); } } cur = new Node(data); cur->_col = RED; if (kot(data) < kot(parent->_data)) { parent->_left = cur; } else { parent->_right = cur; } cur->_parent = parent; //调整红黑树 //parent是黑的也直接结束 while (parent && parent->_col == RED) { //关键看叔叔 Node* grandf = parent->_parent; if (parent == grandf->_left) { Node* uncle = grandf->_right; //叔叔存在且为红,变色即可 if (uncle && uncle->_col == RED) { uncle->_col = parent->_col = BLACK; grandf->_col = RED; //继续往上处理 cur = grandf; parent = cur->_parent; } else//叔叔不存在,或则存在且为黑 { // g // p u //c if (cur == parent->_left) { parent->_col = BLACK; grandf->_col = RED; RotateR(grandf); } // g // p u // c else { RotateL(parent); grandf->_col = RED; cur->_col = BLACK; RotateR(grandf); } break; } } else { Node* uncle = grandf->_left; //叔叔存在且为红,变色即可 if (uncle && uncle->_col == RED) { uncle->_col = parent->_col = BLACK; grandf->_col = RED; //继续往上处理 cur = grandf; parent = cur->_parent; } else//叔叔不存在,或则存在且为黑 { // g // u p // c if (cur == parent->_right) { parent->_col = BLACK; grandf->_col = RED; RotateL(grandf); } // g // u p // c else { RotateR(parent); grandf->_col = RED; cur->_col = BLACK; RotateL(grandf); } break; } } } _root->_col = BLACK; return make_pair(Iterator(cur), true); }插入大致的思路还是没有变的,我就强调一下改变的部分。
我们先是将插入函数的返回值类型给改变了,将它改成了pair结构体类型,这是为了我们后续对map和set进行封装,然后我们的返回都要用make_pair将数据转变成pair结构体的方式进行返回,然后我们还要创建一个KeyofYT类型的对象,它的作用我前面已经说过了,是利用仿函数来返回key值进行大小比较。其它的代码就跟我红黑树那一篇文章的代码一模一样了。
红黑树方面的代码的改进就以上这些
3.map的模拟实现
map的底层结构就是红黑树,因此在map中直接封装一棵红黑树,然后将其接口包装下即可
#pragma once #include"_RBtree.h" namespace Mybit { template<class K,class V> class map { struct KeyofT { const K& operator()(const pair<K,V>& kv) { return kv.first; } }; public: typedef typename RBTree<K, pair<const K, V>, KeyofT>::Iterator iterator; typedef typename RBTree<K,pair<const K, V>, KeyofT>::ConstIterator const_iterator; iterator begin() { return _t.begin(); } iterator end() { return _t.end(); } const_iterator begin() const { return _t.begin(); } const_iterator end() const { return _t.end(); } pair<iterator, bool> insert(const pair<K, V>& kv) { return _t.Insert(kv); } iterator find(const K& key) { return _t.Find(make_pair(key, V())); } V& operator[](const K& key) { pair<iterator, bool> ret = _t.Insert(make_pair(key, V())); return ret.first->second; } private: RBTree<K, pair<const K, V>, KeyofT> _t; };由于map是key-value模型,所以我们的类模板设置了两个类型,分别是K,和V,在map类里面我们终于看到了KeyOfT这个结构体,这个结构体里面我们就设计了一个括号重载,这就是我们的仿函数的用法,你可以看到它返回的是我们的键值,接下来我们对红黑树的两个迭代器类型再次进行重命名,这样我们在测试主函数里面使用的时候格式就跟使用标准库的时候是一模一样的。接下来还是我们的两组begin,end,我们直接调用红黑树的两组begin和end就可以了,接下来是insert插入,我们还是调用红黑树的插入,find也是如此,最后是我们的方括号重载。
要弄懂方括号重载我们得先知道方括号的作用,方括号我们一般都是把想要让程序员看到的数据给取出来,在map中我们想看到的大多数时候都不是key值,而是value值,value值就在我们的pair结构体中的second变量里;或则说这个区域的数据是空的,那么我们还可以把数据添加进去。因此,我们的方括号重载也是这样去设计的,先添加(如果已经存在了它就会添加失败,直接把原来的数据赋值给ret,不清楚的话,大家可以看红黑树插入的代码就会清楚了),然后我们再返回second数据就可以了。
这就是我们map的简单封装,我们再来总结一点,封装封装,都是封装给其它人看的,目的是让其在使用的时候能够更加规范,更加简单,所以你会发现,我们这里进行封装的时候,他们的接口名称,返回值类型几乎都是一样的。
//利用【】简单计数 void test_map2() { string arr[] = { "字符串", "数组", "指针", "列表", "字典", "字典", "字典", "字符串", "字符串", "字符串", "数组","数组","数组", "数组","数组" }; map<string, int> countMap; for (auto& e : arr) { countMap[e]++; } for (auto& kv : countMap) { cout << kv.first << ":" << kv.second << endl; } cout << endl; map<string, int>::iterator it = countMap.find("字符串"); cout << (*it).first << endl; }上述代码就是我们简单的一个计数测试代码,都是基础的语法,而且大家会发现我们的使用跟标准库是一模一样的。给大家看看运行结果。
由于我们的计数是重零开始的所以它会比我们预想的少一个,但是如果需要的话我们可以自行将他们添加上去。
4.set的模拟实现
set的底层为红黑树,因此只需在set内部封装一棵红黑树,即可将该容器实现出来(具体实现可参考map)。
#pragma once #include"_RBtree.h" namespace Mybit { template<class K> class set { struct KeyofT { const K& operator()(const K& key) { return key; } }; public: typedef typename RBTree<K, const K, KeyofT>::Iterator iterator; typedef typename RBTree<K,const K, KeyofT>::ConstIterator const_iterator; iterator begin() { return _t.begin(); } iterator end() { return _t.end(); } const_iterator begin() const { return _t.begin(); } const_iterator end() const { return _t.end(); } pair<iterator,bool> insert(const K& key) { return _t.Insert(key); } iterator find(const K& key) { return _t.Find(key); } private: RBTree<K,const K,KeyofT> _t; };看完了map的封装再来看set的封装就会发现,封装思路就是一模一样的,唯一有几点改动是因为set的模型是key模型,所以它的仿函数返回有点不一样,因为它不需要我们的pair结构体,【】在此时也不是很需要了,我们直接测试看看。
void test_set() { set<int> s; s.insert(2); s.insert(5); s.insert(3); s.insert(4); s.insert(1); set<int>::iterator it = s.begin(); cout << *it << endl; while (it != s.end()) { cout << *it << " "; ++it; } cout << endl; set<int> copy = s; for (auto e : copy) { cout << e << " "; } cout << endl; cout << *(s.find(1)) << endl; }
总结
我们的map和set的简单封装到这里就结束了,我们要弄清楚红黑树的迭代器的主要功能的实现思想,还要红黑树的一些修改,最重要的还有map和set的封装思想,弄清楚这些,大家在日常生活中对map和set的使用就会更加得心应手。
我们实现map和set的简单封装并不是为了说再造一个跟库里的一样的,这没必要,我们只需要了解主要功能的实现原理就足够了,这样当你再看到map和set的时候就不会看它是一团迷雾了。
红黑树模拟实现STL中的map与set——C++
news2026/2/14 1:21:29




本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/2081133.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
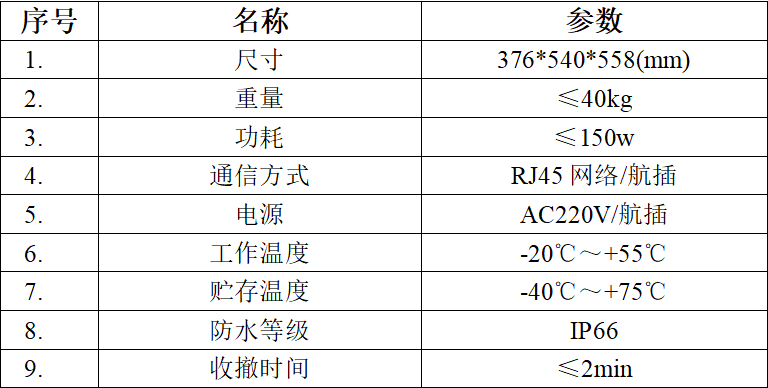
无人机侦测:光电识别追踪设备(双光)技术详解
无人机侦测中的光电识别追踪设备(双光)技术,是一种高效且精准的目标识别与追踪手段,特别适用于无人机平台。以下是对该技术的详细解析:
一、技术概述
光电识别追踪设备(双光)结合了可见光和红…

企业微信iPad协议:自定义接入需求,为行业提供新助力
在当今数字化时代,企业如何有效连接客户、提升营销效率成为了一个重要议题。iPad协议,或称企业微信协议,作为基于微信iPad协议的智能接口服务,优势及其在企业营销中的应用。 什么是iPad协议?
iPad协议是一种智能控制…

<数据集>塑料瓶识别数据集<目标检测>
数据集格式:VOCYOLO格式
图片数量:3331张
标注数量(xml文件个数):3331
标注数量(txt文件个数):3331
标注类别数:1
标注类别名称:[bottle]
使用标注工具:labelImg
标注规则:对…

Swift concurrency 2 — async await的理解与使用
async / await
将函数标记为async会告诉Swift编译器该函数是异步执行的,是可以挂起的。await关键字标记了这些挂起点。当一个函数在await调用时被挂起时,它所执行的线程可以用来执行其他工作。当等待的工作完成时,运行时可以恢复函数的执行。…

Python | Leetcode Python题解之第378题有序矩阵中第K小的元素
题目: 题解:
class Solution:def kthSmallest(self, matrix: List[List[int]], k: int) -> int:n len(matrix)def check(mid):i, j n - 1, 0num 0while i > 0 and j < n:if matrix[i][j] < mid:num i 1j 1else:i - 1return num > …

MS sqlserver备份软件 SQLBackupAndFTP
系列文章目录 提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加 例如:第一章 Python 机器学习入门之pandas的使用 提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目…
Linux—— 配置ssl安全证书
一、实验设计 二、实验配置过程
[studentbogon ~]$ su - root
Password:
[rootbogon ~]# dnf -y install nginx
[rootbogon ~]# vim /etc/selinux/config
[rootbogon ~]# setenforce 0
[rootbogon ~]# systemctl stop firewalld
清空防火墙规则
[rootbogon ~]# iptables -F ^C…

CHARLS数据库挖掘系列教程(1)---数据库下载
CHARLS 是一项具备中国大陆 45 岁及以上人群代表性的追踪调查,旨在建设一个高质量的公共微观数据库,采集的信息涵盖社会经济状况和健康状况等多维度的信息,以满足老龄科学研究的需要。 为利用国际上最佳的数据采集方式,并确保研究…

YOLOv8实例分割推理流程及Python代码
1.YOLOv8_Seg推理流程
2.YOLOv8_Seg推理代码 3.全部代码 """
yolov8:目标检测推理代码 python
"""
import torch
import cv2
import numpy as np
import onnxruntime as ort
import os
import torch.nn.functional as F
def xywh2xyxy(x):"…

【K8S 基本概念】Kubernets的架构和核心概念及集群搭建
一、Kubernets
1.作用:用于自动部署扩展以及管理容器化部署的应用程序,半开源,k8s的底层是基于谷歌go语言开发的,负责自动化运维管理多个容器化的应用的集群,容器编排框架的工具。现在使用的版本1.18-1.24,…

开放式耳机怎么戴?佩戴舒适在线的几款开放式耳机分享
开放式耳机的佩戴方式与传统的入耳式耳机有所不同,它采用了一种挂耳式的设计,提供了一种新颖的佩戴体验,以下是开放式耳机的佩戴方式。
1. 开箱及外观:首先,从包装盒中取出耳机及其配件,包括耳机本体、充电…

java-Mybatis框架02
1.#{} 和${}区别 #{} 是占位符,是采用编译方式向sql中传值,可以防止sql注入,如果往sql中传值,使用#{}${} 是将内容直接拼接到sql语句中,一般不用于向sql中传值,一般用于向sql中动态传递列名。区别ÿ…


【RabbitMQ】快速上手
目 录 一. RabbitMQ 安装二. RabbitMQ 核心概念2.1 Producer 和 Consumer2.2 Connection 和 Channel2.3 Virtual host2.4 Queue2.5 Exchange2.6 RabbitMQ 工作流程 三. AMQP四. web界面操作4.1 用户相关操作4.2 虚拟主机相关操作 五. RabbitMQ 快速入门5.1 引入依赖5.2 编写生产…

简单的jar包解压class文件修改再编译成jar包
简单的jar包解压class文件修改再编译成jar包
1. 需求
我们公司有一个项目演示的环境,这个环境是我们公司其他组的项目,我们组只有这个项目的前端,jar,以及部分数据库结构表信息,现在我们已经启动服务可以正常访问&am…

Python中PDF文件的编辑与创建
目录
安装必要的库
编辑现有PDF文件
合并PDF文件
拆分PDF文件
添加水印
注意
创建新的PDF文件
使用reportlab创建PDF
使用Spire.PDF for Python创建PDF
结论 在数字化办公和学习环境中,PDF(Portable Document Format)文件因其跨平台…

【免费分享】1982-2015华北平原农田蒸散发数据集
华北平原是中国最重要的产粮基地之一,然而该地区水资源缺乏、供需矛盾突出。 在全球气候变化及用水需求日益增加的背景下, 该地区水循环过程变得愈加脆弱。 因此如何准确估算蒸散发、 掌握蒸散发的时空变化规律, 进而合理配置水资源、提高农业…


《网络安全自学指南》
《网络安全自学教程》 《网络安全自学》 1、网络协议安全1.1、OSI七层模型1.2、TCP/IP协议栈1.3、Wireshark使用1.4、802.1x协议1.5、ARP协议1.6、ARP欺骗1.7、IP协议1.8、ICMP协议1.9、TCP协议1.10、SYN Flood1.11、SSL协议1.12、HTTP协议1.13、DHCP协议 2、操作系统安全2.1、…