迄今为止的旅程:Confluence Agent 回顾
在深入研究 SQL Agent 之前,让我们先简单回顾一下我们开发的 Confluence Agent:
- 元数据提取:捕获我们的知识库的结构。
- 内容提取:提取文档的核心内容。
- 格式处理:分离 HTML 和 PDF 内容以实现最佳处理。
- 图像分析:利用 LLM 解析来提取和理解图像内容。
- 性能提升:实现异步和多线程,速度提高 10 倍。
这些增强功能为强大的信息检索系统奠定了基础。现在,我们正在扩展我们的工具包,以解决数据驱动型组织中最常见的挑战之一:SQL 查询生成。
我为什么要建造这个?
想象一下这样的场景:你是一名新的数据分析师,你的老板突然来到你的办公桌前,提出了一个紧急请求:
“我需要将昨天的游戏指标与去年的数据进行比较分析,重点关注速度和收入。请在 EOD 之前将其送到我的办公桌上。”
当你脸色苍白时,你意识到你面临着几个挑战:
- 你是新手,不知道在哪里可以找到相关数据。
- 您不确定哪些表包含您需要的信息。
- 编写复杂的 SQL 查询还不是你的强项(目前)。
- 你的经理整天都在开会,你不想用基本问题轰炸他们
这一场景凸显了许多组织面临的三大关键挑战:
- 数据量:传统和现代数据仓库中有超过 500 个表,查找正确的数据就像大海捞针。
- 查询复杂性:作为唯一事实来源意味着要处理来自各个部门的复杂查询。
- 知识差距:新团队成员往往缺乏广泛的机构知识,难以浏览庞大的数据库。
我已经考虑这个问题一段时间了,但从来没有想过要开始着手做这件事,直到一个非常正常的早晨,我和总经理进行了一次随意的交谈。
“我们现在可以查询您聊天机器人的数据吗?”
我当时完全没有想到,这句即兴的评论会让我踏上彻底改变我们与数据交互方式的征程。但在我介绍如何构建这个 AI 查询向导之前,让我先解释一下为什么大多数解决方案都无法解决企业级问题。
为什么“谷歌搜索”无法解决企业 SQL 难题
在撸起袖子开始动手之前,我做了任何有自尊心的开发人员都会做的事情:我在互联网上搜索解决方案。我找到的结果是……好吧,只能说它有很多不足之处。
文本到 SQL 的“Hello World”
我发现的大多数文章和教程就像是尝试使用儿童游泳池进行奥运会训练一样:
- 🐣微型表:使用 2-3 个表的示例。很可爱,但我们最小的架构会把这些表当早餐吃掉。
- 📜无限提示滚动:解决方案建议我将整个表格模式粘贴到提示中。祝您在查看无限提示时好运。
- 🏝️孤岛查询:对单个表进行简单查询,忽略真实数据库中的复杂关系。
- 🐌性能?什么性能?:大多数示例都忽略了大数据集中查询性能的关键方面。
我的数据现实
当这些教程在儿童游泳池里玩的时候,我正盯着相当于太平洋的数据:
- 🏙️混乱的表格:超过 300 张表格,其中一些表格的列数超过 150 列
- 🕸️复杂的关系:具有复杂相互依赖关系的数据模型,它是数据仓库建模。
- 🏎️需要速度:需要针对速度和效率进行优化的查询。
- 🔄不断发展的模式:表结构频繁变化的动态环境。
这个图来自 AWS 博客。很酷,但和我们的架构师无关。我们的更酷
很明显:我们需要一个与我们的数据环境一样强大和复杂的解决方案。
实现 SQL 代理
别浪费时间了,赶紧开始吧。现在有一个限制。
我显然可以赋予 SQL Agent 执行 SQL 的能力。事实上,我应该这样做,但是,因为这是 PoC,与数据库交互的 API 密钥在我名下,所以有人可以轻易进入并进行提示注入,说“删除表”。此外,我不能保证代理生成的 SQL 100% 正确且经过优化。随着训练数据越来越多,最终,我们很快就会到达那个阶段。目前,由用户来验证生成的 SQL。
现任高级建筑师
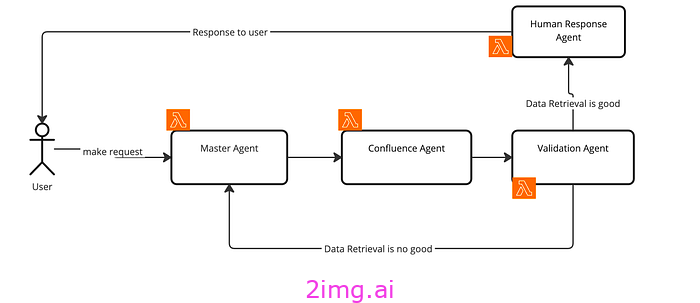
目前我们只有一个代理。Confluence 代理。工作流程保持不变。用户发送请求 -> 发送给主代理进行推理 -> 发送给 Confluence 代理使用 Confluence 知识库查找答案 -> 发送给验证代理验证响应 -> 发送给人工响应代理标记 PII 数据(如果有)并响应用户,否则,调用主代理并要求重新评估,因为数据检索不够好。
数据处理:成功的基础
如果您只是将纯文本转储到矢量数据库中并期望 LLM 能够很好地完成工作,那么您将不会获得良好的结果。我尝试过但失败了,所以您不必自己尝试。任何成功的机器学习系统或 LLM/Gen AI 系统都取决于数据处理。这是至关重要的一步,并且总是占用 80% 以上的时间。如果您的数据正确,那么可以稍后再进行提示工程师。不要试图提示工程师进行数据准备。
1. 数据采集:绘制数据图景
首先,我需要掌握我们庞大的数据格局。我们的数据平台使用 AWS Glue 作为主要数据目录,因此 Glue 始终包含表/数据库/架构的最新更新。
这一步至关重要,因为它为后续的一切奠定了基础。
我编写了一个 Python 脚本,该脚本与 AWS Glue API 交互,以提取有关我们所有数据库和表的信息。这不仅仅是一次简单的数据转储——我必须仔细构建提取的信息,以使其可用于项目的后期阶段。
import boto3
session = boto3.Session(profile_name='<your_profile_name>')
glue_client = session.client('glue')
bedrock_runtime = session.client(service_name='bedrock-runtime')
def list_glue_tables(glue_client):
raw_all_tables = []
filtered_databases = ['<your_db1>','<your_db_2>','<your_db_3>']
paginator = client.get_paginator('get_databases')
for page in paginator.paginate():
for database in page['DatabaseList']:
if database['Name'] not in filtered_databases:
continue
table_paginator = client.get_paginator('get_tables')
for table_page in table_paginator.paginate(DatabaseName=database['Name']):
raw_all_tables.extend(table_page['TableList'])
return raw_all_tables该脚本会遍历每个数据库,然后遍历这些数据库中的每个表,提取关键信息,例如表名、列名和类型、存储位置以及上次更新时间戳。这种全面的方法确保没有遗漏任何表,从而为我提供了完整的数据地形图。
def extract_schema(table):
return {
"DatabaseName": table['DatabaseName'],
"TableName": table['Name'],
"TableDescription": table.get('Description', ''),
"Partition": table.get('PartitionKeys', None),
"TableSchema": [
{
"Name": col['Name'],
"Type": col['Type'],
"Comment": col.get('Comment', '')
} for col in table['StorageDescriptor']['Columns']
],
"CreateTime": table.get('CreateTime', None),
"UpdateTime": table.get('UpdateTime', None),
"SourceSQL": table.get('ViewExpandedText', '')
}
def process_table(table):
print(f"Processing table {table['Name']}")
schema = extract_schema(table)
documentation = generate_documentation(schema) # find this function below
table_name = f"{table['DatabaseName']}.{table['Name']}"
save_documentation(table_name, documentation)
print(f"===Documentation generated for {table['Name']}")2. 语境丰富:为原始数据增添趣味
原始表模式就像未经调味的食物——功能齐全,但并不令人兴奋。我需要为这些数据添加一些背景信息和趣味。这就是事情变得有趣的地方,也是我开始利用大型语言模型 (LLM) 的强大功能的地方。
我开发了一个由 LLM 支持的丰富流程,该流程将获取每个表的原始元数据并生成有意义的上下文。这不仅仅是重述元数据中已有的内容——我希望 LLM 能够对表的用途、与其他表的关系以及可能的用途做出有根据的猜测。
def generate_documentation(schema):
system_prompt = """
You are an expert database and business developer specializing in <place holder for your purpose>
Your task is to review database schemas and generate comprehensive documentation in JSON format.
Focus on providing insights relevant to the betting industry, including table purposes, column descriptions,
and potential use cases. Be concise yet informative, and ensure all output is in valid JSON format.
"""
initial_user_prompt = f"""
Please generate comprehensive documentation for the following database schema in JSON format only.
The documentation should include:
1. A brief overview of the table's purpose and its role in <purpose>
2. Detailed descriptions of each column, including its data type, purpose, and any relevant notes specific to the <your data platform>
3. Any additional insights, best practices, or potential use cases for this table in the context of <your context>
4. Comments on the creation and last update times of the table, if relevant to its usage or data freshness
5. Generate at least 10 common queries that could be run against this table in the context <your context>
Here's the schema:
{json.dumps(schema, indent=2, cls=DateTimeEncoder)}
Please provide the output in the following format:
```json
{{
"DatabaseName": "Name of the database",
"TableName": "Name of the table",
"TableDescription": "Brief overview of the table",
"CreateTime": "Raw creation time of table",
"UpdateTime": "Raw updated time of table",
"Columns": [
{{
"name": "column_name",
"type": "data_type",
"description": "Detailed description and purpose of the column"
}},
// ... all other columns
],
"AdditionalInsights": [
"Insight 1",
"Insight 2",
// ... other insights
],
"CommonQueries": [
{
"natural_language": "Nature english query",
"sql_query": "Detail of SQL query",
}
]
}}
```
If you need more space to complete the documentation, end your response with "[CONTINUE]" and I will prompt you to continue.
"""
full_response = ""
conversation_history = f"{system_prompt}\n\nuser: {initial_user_prompt}\n\nassistant: "
while True:
body = json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"messages": [{"role": "user", "content": conversation_history}],
"max_tokens": 8192,
"temperature": 0,
})
response = bedrock_runtime.invoke_model(body=body, modelId=model_id)
response_body = json.loads(response.get('body').read())
current_response = response_body['content'][0]['text']
full_response += current_response
if response_body['stop_reason'] != 'max_tokens':
break
conversation_history += current_response
conversation_history += "\n\nuser: Please continue the JSON documentation where you left off, maintaining the perspective of an expert in sports and racing betting platforms.\n\nassistant: "
return full_response这一步的提示设计至关重要。我必须精心设计提示,以指导 LLM 提供:
- 该表在我们的业务环境中可能代表的内容的详细描述。
- 该表的潜在用例,思考不同部门可能如何查询它。
- 与其他表的可能关系,有助于映射我们的数据模型。
- 任何数据质量考虑因素,例如潜在的空值或数据类型不一致。
- 建议对大表使用分区键,考虑查询优化。
- 潜在的唯一标识符,这对于以后的连接操作至关重要。
关键在于:
在处理此问题时,Claude 模型通过 Bedrock 仅支持最多 4096 个输出 token。这对于大多数用例来说已经足够了,但是,对于包含超过 100 列的某些特殊表,可能会导致错误。为了处理这个限制,我们首先查看第一个输出的响应是否包含max_token作为stop_reason。如果没有,则继续该过程,但如果存在max_token,则需要向现有响应发送一个带有调整提示的长文本,以要求 LLM 继续从上一步生成。
请记住:上下文 token 是 200k,而输出 token 只有 4096k。
可能存在由于某些故障导致最终输出无法解析为 JSON 的情况。因此我们需要将此错误写入 txt 文件中,以供稍后查看。
def save_documentation(table_name, documentation):
try:
json_content = documentation.split("```json")[1].split("```")[0].strip()
parsed_json = json.loads(json_content)
with open(f"{folder}/table_json/{table_name}.json", "w") as f:
json.dump(parsed_json, f, indent=2)
print(f"===Documentation saved for {table_name}")
except Exception as e:
print(f"===Error parsing documentation for {table_name}: {str(e)}")
with open(f"{folder}/{table_name}_doc_raw.txt", "w") as f:
f.write(documentation)
print(f"===Raw documentation saved for {table_name}")这是存储模式的函数
def process_table(table):
print(f"Processing table {table['Name']}")
schema = extract_schema(table)
documentation = generate_documentation(schema)
table_name = f"{table['DatabaseName']}.{table['Name']}"
save_documentation(table_name, documentation)
print(f"===Documentation generated for {table['Name']}")
3. 双重索引:创造完美融合
我一开始使用普通的向量索引,并进行了基本的修复分块,但结果很糟糕,SQL 生成器经常会得到错误的表名和列名。它没有完整的上下文,因为分块会将其切掉。
为了解决这个问题,我放弃了普通的分块算法,转而采用分层分块方法,并稍微改变了提示。这带来了更好的响应,并修复了第一种方法的所有问题。
但是,向量索引忽略了一个关键方面,即表之间的关系。为此,我使用了知识图谱,结果非常棒。
总而言之,我们有两种索引方法:
向量索引
向量索引最看重的是速度,我使用了 OpenSearch serverless 作为向量数据库,并使用分层分块作为分块算法。
知识图谱
向量索引提高了速度,而知识图谱则提供了深度。我使用 NetworkX 创建了整个数据模型的图形表示。每个表都成为一个节点,边表示表之间的关系。
棘手的部分在于定义这些关系。有些关系很明显,比如外键关系,但其他关系则需要对我们的数据模型有更细致的了解。我根据命名约定、通用前缀和第 2 步中丰富的元数据实现了推断关系的逻辑。
这个知识图谱成为我们系统理解复杂多表查询能力的支柱。它允许 SQL 代理从关系和路径的角度“思考”数据,就像人类数据分析师一样。
4. Magic Brew:将问题翻译成 SQL
现在,最重要的是 SQL Agent 本身。正如您所知,在开发 AI Agent 时,LlamaIndex 始终是我的首选。我使用过 LangChain 和其他开源软件,虽然 LangChain 已经成熟并拥有更大的社区支持,但它有时会增加不必要的复杂性。
以下是 SQL Agent 的实现
def sql_agent_promt():
return """
You are an advanced AI assistant specialized in data analytics for <your domain database> with expert proficiency in Databricks Delta SQL.
Your primary role is to translate natural language queries into precise, executable SQL queries.
Follow these instructions meticulously:
Core Responsibilities:
- Always respond with an executable SQL query.
- Do NOT execute SQL queries; only formulate them.
- Utilize the vector database to access accurate schema information for all tables.
Process:
1. Understand User Input:
- Interpret the user's natural language query to comprehend their data requirements and objectives.
2. Retrieve Relevant Tables:
- Identify and retrieve the most relevant tables from the vector database that align with the user's query.
- Continue this step until you find all necessary tables for the query.
3. Verify Schema:
- For each relevant table, retrieve and confirm the exact schema.
- IMPORTANT: Pay special attention to column names, data types, and relationships between tables.
4. Formulate SQL Query:
- Construct a Databricks Delta SQL query using the confirmed schema information.
- Ensure all table and column names used in the query exactly match the schema.
5. Provide Professional Response
- Draft the SQL query as a seasoned senior business analyst would, ensuring clarity, accuracy, and adherence to best practices.
6. (Optional) Explanation
- If requested, provide a detailed explanation of the SQL query and its logic.
Response Format:
1. Begin with the SQL query enclosed in triple backticks (```).
2. Follow with a brief explanation of the query's purpose and how it addresses the user's request.
3. Include a schema confirmation section, listing the tables and columns used.
Guidelines:
- Prioritize query accuracy and performance optimization.
- Use clear and professional language in all responses.
- Offer additional insights to enhance user understanding when appropriate.
Error Handling:
If you lack information or encounter ambiguity, use the following format:
<clarification_request>
I need additional information to formulate an accurate query. Could you please:
- Provide more details about [specific aspect]?
- Confirm if the following tables and columns are relevant: [list potential tables/columns]?
- Clarify any specific time ranges, filters, or conditions for the data?
</clarification_request>
Schema Confirmation
Before providing the final query, always confirm the schema:
<schema_confirmation>
I'll be using the following schema for this query:
Table: [table_name1]
Columns: [column1], [column2], ...
Table: [table_name2]
Columns: [column1], [column2], ...
Are these the correct tables and columns for your query?
</schema_confirmation>
Example Response
<give your example here>
Remember to maintain a professional, clear, and helpful tone while engaging with users and formulating queries.
"""该过程的工作原理如下:
- 当用户提交查询时,我们首先使用向量索引来快速识别可能相关的表和列。
- 然后,我们查阅知识图谱来了解这些表之间的关系,并确定可能需要回答查询的任何其他表。
- 利用这些信息,我们构建了 LLM 的提示,其中包括:
- 用户原始查询
- 有关相关表和列的信息
- 来自我们的知识图谱和矢量数据库的关于这些表如何相互关联的上下文
- 我们制定的任何具体业务规则或常见做法
然后,LLM 根据此信息生成 SQL 查询。最后,我们通过验证步骤运行查询以捕获任何明显的错误或低效率。
以下是代理的代码:
记住我们上面创建的知识库,我们将其用作此代理中的工具
response_synthesizer = get_response_synthesizer(llm=llm)
query_engine = RetrieverQueryEngine(
retriever=sql_knowledgebase,
response_synthesizer=response_synthesizer,
)
query_engine_tools = [
QueryEngineTool(
query_engine=query_engine,
metadata=ToolMetadata(
name="database_retriever",
description="Have access to data catalog, that have all details about databases, schemas, tables, table columns and its attribute along with description."
),
),
...... <second tool for knownledge graph>
]
agent_worker = FunctionCallingAgentWorker.from_tools(
query_engine_tools,
llm=llm,
verbose=True,
allow_parallel_tool_calls=True,
system_prompt=sql_agent_promt()
)
agent = agent_worker.as_agent(memory=chat_memory)这一步的提示设计是最具挑战性的。我必须创建一个提示,指导 LLM 编写正确、高效的 SQL,同时解释其原因。这个解释部分对于与用户建立信任并帮助他们理解生成的查询至关重要。
结果:永不休息的数据向导
我的 SQL Agent 竟然是我从未想过需要的 MVP。它就像是一个 24/7 全天候数据管家,永远不会弄错你的订单。
现在的高级多智能体架构师
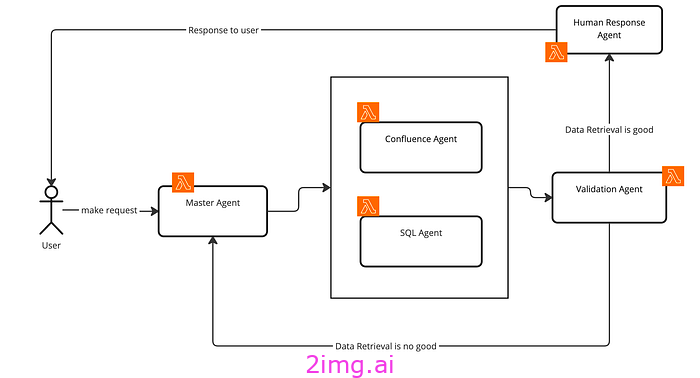
如您所见,矩形框中还有另一个代理。现在我们有 2 个代理不断相互通信以解决用户查询,只要查询是关于生成 SQL 或基于 Confluence 文档的一般问题。
经验教训
在整个过程中,我学到了一些宝贵的经验教训,我认为这些经验教训可以让任何从事类似项目的人受益:
- 上下文为王:理解表上下文和关系是生成准确查询的关键。
- 基于图的方法:知识图谱方法比普通索引更能处理复杂查询。它允许系统以接近人类推理的方式“思考”数据关系。
- 持续学习:我不断将新的查询反馈到我们的系统以提高其性能。
- 可解释性至关重要:让系统解释其推理可以赢得用户的信任,并帮助他们了解数据模型。这就像厨师解释一道复杂菜肴的配料一样。
- 边缘案例是生活的调味品:处理边缘案例和不寻常的查询通常是最有趣的见解的来源。它迫使我深入思考我们的数据模型以及用户如何与之交互。
结论
我从一个随意的评论到一个复杂的 SQL 代理的历程表明,通过正确的技术、创造力和一点咖啡因引发的灵感的结合,我们甚至可以解决最复杂的数据挑战。
我创造的不仅仅是一个工具;我还发明了一种全新的数据交互方式。它使获取见解变得民主化,让每个团队成员都成为潜在的数据美食家