在本文中,我将讨论 Segment Anything - 例如分割的神经网络,可用于从图像中分割任何对象而无需知道其类型。但是,这不是关于如何使用它的教程,因为它已经在官方存储库和其他类似文章中进行了描述。在这里,我将解释如何使用它来解决一个问题,这个问题没有在任何地方描述 - 导出到 ONNX 函数的问题。

NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
1、问题是什么?
如果你尝试将 Segment Anything 模型导出到 ONNX,然后使用官方笔记本中的指南将其部署到生产中,你会发现不能只使用导出的 ONNX 模型,仍然还需要使用带有 PyTorch 的 Segment Anything 包来准备来自输入图像的嵌入,并且仍然需要使用此包中的函数来编码提示。
当我第一次遇到这种情况时,我问自己:“如果我仍然需要使用原始的 PyTorch 模型,为什么要将模型导出到 ONNX?”。
ONNX 的主要优势之一是能够在没有 Python 和 PyTorch 的环境中运行模型。但是,根据官方文档,我无法使用 Segment Anything 做到这一点。即使使用 ONNX,我也需要在生产服务器或设备上安装整个 PyTorch 环境。
我不是唯一遇到这个问题的人,很多人在论坛或项目 GitHub 中寻求解决方案,但没有明确的答案。最后,我决定自己深入研究 Segment Anything 源代码并填补这个空白。
在本文中,我将展示如何导出完整的 SAM 模型以及如何仅使用 ONNX 模型而不使用其他繁重的依赖项来分割图像。
2、深入研究 SAM 模型结构
在介绍 ONNX 之前,让我们使用其官方 API 了解 SAM 模型结构。
Segment Anything 具有transformer神经网络架构,包含以下部分:图像编码器、提示编码器和掩码解码器。
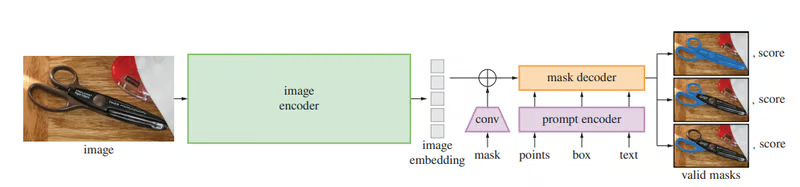
这张来自 SAM 官方论文的图片展示了分割掩码推理过程。现在让我们看看使用官方 API 实现此流程的代码。
本文中的所有代码示例都使用以下图像,名为 cat_dog.jpg:

from segment_anything import sam_model_registry, SamPredictor
import numpy as np
import cv2
# 1. Load the image
img = cv2.imread("cat_dog.jpg")
img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
# 2. Load the Segment anything model
sam = sam_model_registry["vit_b"](checkpoint="./sam_vit_b_01ec64.pth")
# 3. Put the model to the SamPredictor helper object
predictor = SamPredictor(sam)
# 4. Encode the image to embeddings.
predictor.set_image(img)
# 5. Prepare the prompt
input_point = np.array([[321,230]])
input_label = np.array([1])
# 6. Decode masks
masks = predictor.predict(input_point, input_label)以下是此流程的分解说明:
- 首先,它使用 OpenCV 将图像加载为 HWC 形状(高度、宽度、通道)的 Numpy 数组。你也可以使用任何其他库(如 Pillow)执行此操作。
- 然后,它将 SAM 模型加载到
sam变量。sam是Sam类的对象,在 sam.py 文件中定义。这个类包含图像编码器和掩码解码器部分。如果打开此文件并查看__init__构造函数,你会发现编码器在image_encoder属性中初始化,解码器在mask_decoder属性中初始化。它们都是标准的 PyTorch 神经网络模块。 - 然后,代码初始化辅助
SamPredictor对象,该对象用作创建的 Sam 模型的包装器。它包含辅助方法来准备输入图像、将图像编码为嵌入、对提示进行编码并将它们都传递给mask_decoder以获取分割掩码。 - 整个代码中最重要的一行是
predictor.set_image(img)。此方法用于预处理输入图像并使用它运行 SAM 编码器网络。在底层,它使用预处理后的图像运行以下行:predictor.features = sam.image_encoder(input_image)。此行将图像传递通过编码器神经网络以获取嵌入并将其保存到SamPredictor对象的features属性。官方导出到 ONNX 函数不会导出此神经网络,因此即使使用导出的 ONNX 模型,你仍然需要运行它。 - 然后,你在图像上定义点,该点将用作解码分割掩码的提示和该点的标签:1 表示该点属于你要提取的对象,0 表示该点不属于该对象。
- 最后,你执行了
predictor.predict(input_point, input_label)方法。此时,预测器对提示进行编码,并将保存在features属性中的两个图像嵌入和编码的提示传递给掩码解码器,这是一个sam.mask_decoder神经网络。然后,此方法返回生成的输出张量,然后对其进行后处理以返回掩码。
这就是官方 API 的工作原理。Segment Anything 实际上是两个神经网络: image_encoder 和 mask_decoder,它们一个接一个地单独执行。它首先运行 sam.image_encoder 网络将图像编码为嵌入,然后运行 sam.mask_decoder 网络使用提示将嵌入解码为掩码。提示也使用提示编码器进行编码,但在许多情况下,提示可以在没有神经网络的情况下进行编码。但是,当你将 sam 模型导出到 ONNX 时,它只导出 mask_decoder,你仍然需要使用官方 API 为导出的 ONNX 模型准备图像嵌入并对提示进行编码。
幸运的是, image_encoder 是一个普通的 PyTorch 神经网络模块,可以使用此处介绍的标准 PyTorch 功能自行将其导出到 ONNX。该提示也可以仅使用 Numpy 进行编码。我将在下一节中为你填补这些空白。
将 SAM 导出到 ONNX - 正确的方法
要独立于 PyTorch 和/或 Python 使用 Segment Anything 网络,你需要将两个模型导出到 ONNX:图像编码器和掩码解码器。官方文档显示了如何仅导出掩码解码器。在本教程中,我将向你展示如何导出和使用这两个部分,而不依赖于 PyTorch 和 SAM 官方 API。
3、导出图像编码器
要将任何 PyTorch 模型导出到 ONNX,你需要知道此模型所需的输入张量的形状。Segment Anything 中使用的图像编码器模型是 ViT 神经网络的经过修改的编码器部分。它在 image_encoder.py 中的 ImageEncoderViT 类中定义。通过分析此文件的源代码,很容易理解这个神经网络模块需要以下形状 (1,3,1024,1024) 的输入张量,这是一批 1024x1024 大小的图像。因此,要将单个图像传递给图像编码器,你需要将其编码为此形状的浮点张量。
这是将图像编码器导出到 ONNX 的完整代码。我假设你将在 Jupyter Notebook 中运行它:
!pip install git+https://github.com/facebookresearch/segment-anything.git
!pip install onnx
!pip install torch
from segment_anything import sam_model_registry
import torch
# Download SAM model checkpoint
!pip install wget
!python -m wget https://dl.fbaipublicfiles.com/segment_anything/sam_vit_b_01ec64.pth
# Load SAM model
sam = sam_model_registry["vit_b"](checkpoint="./sam_vit_b_01ec64.pth")
# Export images encoder from SAM model to ONNX
torch.onnx.export(
f="vit_b_encoder.onnx",
model=sam.image_encoder,
args=torch.randn(1, 3, 1024, 1024),
input_names=["images"],
output_names=["embeddings"],
export_params=True
)- 此代码首先安装并导入所有必需的包。也许你已经拥有所有这些包,但我添加了这些行以防万一。
- 然后,它会下载模型权重并用它们加载 sam 模型。我使用了最小的
Vit-B版本,但你可以将其替换为Vit-L或Vit-H,然后从此处下载适当的权重。 - 最后,标准
torch.onnx.export函数用于将sam.image_encoder导出到vit_b_encoder.onnx文件。生成的 ONNX 模型有一个名为images的输入,它接受(1,3,1024,1024)形状的输入张量。此外,它将有一个名为embedddings的单个输出,其中包含提供的输入图像的嵌入。
太棒了!运行此文件后,你将获得 vit_b_encoder.onnx 文件。导出工作的最大部分已经完成!
4、导出掩码解码器
在本节中,我基本上是重复官方笔记本中已经写好的代码。为了保持一致性,我对其进行了少许修改:
!pip3 install git+https://github.com/facebookresearch/segment-anything.git
!pip3 install onnx
!pip3 install torch
from segment_anything import sam_model_registry
from segment_anything.utils.onnx import SamOnnxModel
import torch
# Download SAM model checkpoint
!pip install wget
!python -m wget https://dl.fbaipublicfiles.com/segment_anything/sam_vit_b_01ec64.pth
# Load SAM model
sam = sam_model_registry["vit_b"](checkpoint="./sam_vit_b_01ec64.pth")
# Export masks decoder from SAM model to ONNX
onnx_model = SamOnnxModel(sam, return_single_mask=True)
embed_dim = sam.prompt_encoder.embed_dim
embed_size = sam.prompt_encoder.image_embedding_size
mask_input_size = [4 * x for x in embed_size]
dummy_inputs = {
"image_embeddings": torch.randn(1, embed_dim, *embed_size, dtype=torch.float),
"point_coords": torch.randint(low=0, high=1024, size=(1, 5, 2), dtype=torch.float),
"point_labels": torch.randint(low=0, high=4, size=(1, 5), dtype=torch.float),
"mask_input": torch.randn(1, 1, *mask_input_size, dtype=torch.float),
"has_mask_input": torch.tensor([1], dtype=torch.float),
"orig_im_size": torch.tensor([1500, 2250], dtype=torch.float),
}
output_names = ["masks", "iou_predictions", "low_res_masks"]
torch.onnx.export(
f="vit_b_decoder.onnx",
model=onnx_model,
args=tuple(dummy_inputs.values()),
input_names=list(dummy_inputs.keys()),
output_names=output_names,
dynamic_axes={
"point_coords": {1: "num_points"},
"point_labels": {1: "num_points"}
},
export_params=True,
opset_version=17,
do_constant_folding=True
)- 此代码首先安装并导入所有必需的包。也许你已经拥有所有这些包,但我添加了这些行以防万一。
- 然后,它会下载模型权重并用它们加载 sam 模型。我使用了最小的
Vit-B版本,但你可以将其替换为Vit-L或Vit-H,然后从此处下载适当的权重。 - 最后,它使用标准
torch.onnx.export函数将sam.mask_decoder导出到vit_b_decoder.onnx文件。生成的 ONNX 模型有六个输入。其中最重要的是:image_embeddings将接收vit_b_encoder.onnx模型的输出作为图像嵌入,point_coords和point_masks将接收编码提示。此外,解码器模型需要orig_im_size,它是一个原始输入图像大小,作为 Numpy 数组,包含两个项目:[height, width],以正确缩放生成的掩码。
太棒了!现在,我们已经掌握了拼图的所有部分:
vit_b_encoder.onnx- 创建图像嵌入vit_b_decoder.onnx- 使用嵌入和提示解码分割掩码。
为了方便起见,我将所有 ONNX 导出代码放入了 sam_onnx_export.ipynb 笔记本中。
但是,在没有官方 API 的情况下使用这些模型有点复杂,因为你需要自己预处理输入图像并编码提示。没有关于这些要点的任何文档。我将在下一节中展示如何执行此操作。
使用 ONNX 生成图像分割蒙版
要使用上面导出的 ONNX 模型获取图像中感兴趣对象的分割蒙版,你需要执行以下操作:
- 预处理输入图像
- 将预处理后的图像传递给
vit_b_encoder.onnx模型以生成图像嵌入 - 创建提示并对其进行编码
- 将图像嵌入和提示传递给
vit_b_decoder.onnx模型并接收分割蒙版 - 对蒙版进行后处理并可选择将其可视化
在接下来的部分中,我将逐一实现这些步骤。我假设你将使用 Jupyter Notebook 按照我的代码进行操作,并且你的笔记本文件夹中有 vit_b_encoder.onnx 和 vit_b_decoder.onnx 文件。此外,在示例中,我将使用 cat_dog.jpg 图像,您可以在本文开头下载该图像并将其放在同一文件夹中。
5、预处理输入图像
如上所述,编码器模型需要 (1,3,1024,1024) 大小的输入张量。因此,你需要正确调整输入图像的大小为 1024x1024 并保留纵横比,将其转换为数字张量并规范化该张量。
让我们首先加载图像,我们将为此使用 Pillow 包:
!pip install Pillow
from PIL import Image
img = Image.open("cat_dog.jpg")
img = img.convert("RGB")
img.size
orig_width, orig_height = img.size
print(img.size)(612, 415)此代码加载图像,将其转换为 RGB 并保存原始大小,稍后你将需要它。
然后,我们需要调整此图像的大小,并使用 1024 作为长边保留纵横比。这意味着,我们需要将长边设置为 1024,然后设置短边以保持纵横比。以下代码可用于此目的:
resized_width, resized_height = img.size
if orig_width > orig_height:
resized_width = 1024
resized_height = int(1024 / orig_width * orig_height)
else:
resized_height = 1024
resized_width = int(1024 / orig_height * orig_width)
img = img.resize((resized_width, resized_height), Image.Resampling.BILINEAR)
print(img.size)(1024, 694)因此,此代码确定了哪条边最长,并据此计算出最短边的新大小。在这种情况下,最长边是宽度,最短边是高度,它们缩放到 (1024,694) 并保存到 resized_width 和 resized_height 变量中。
然后,需要将其转换为张量。Numpy 允许在一行中完成此操作:
!pip install numpy
import numpy as np
input_tensor = np.array(img)
input_tensor.shape(694, 1024, 3)input_tensor 包含三个图像像素颜色矩阵。第一个矩阵包含红色分量,第二个矩阵包含绿色分量,第三个矩阵包含蓝色分量。每种颜色的范围是 0 到 255。但是,Segment Anything 模型需要标准化数字。要获得标准化数字,我们需要从每个数字中减去平均颜色,然后将其除以标准差。有多种计算平均颜色和标准差的方法,但 Segment Anything 包已为每个颜色分量提供了计算好的平均值和偏差。我们需要初始化它们:
mean = np.array([123.675, 116.28, 103.53])
std = np.array([[58.395, 57.12, 57.375]])因此,现在我们需要从每个红色分量中减去 123.765,然后除以 58.395。同样,对于蓝色,你需要从绿色矩阵的每个分量中减去 116.28,然后除以 57.12,依此类推。可以使用 Numpy 在一行代码中完成所有这些操作:
input_tensor = (input_tensor - mean) / std现在我们已经标准化了输入张量,但其形状不正确: (694, 1024, 3)。你需要将其更改为 (1,color_channels,height,width) 的形式。在本例中,它应该是 (1, 3, 694, 1024):
input_tensor = input_tensor.transpose(2,0,1)[None,:,:,:].astype(np.float32)
input_tensor.shape(1, 3, 694, 1024)最后一步是将其转换为 (1, 3, 1024, 1024)。为此,我们需要用零填充短边:
if resized_height < resized_width:
input_tensor = np.pad(input_tensor,((0,0),(0,0),(0,1024-resized_height),(0,0)))
else:
input_tensor = np.pad(input_tensor,((0,0),(0,0),(0,0),(0,1024-resized_width)))
input_tensor.shape(1, 3, 1024, 1024)np.pad 函数接收需要用零填充的输入张量,然后,对于每个轴,它接收在现有值之前和之后添加多少个零。在这种情况下,你需要在末尾添加 1024-resized_height 行的零。如果最短边是宽度,那么必须对最后一个轴执行此操作。
就是这样,现在我们有了图像编码器模型的正确 input_tensor。
6、从输入图像生成嵌入
需要做的第一件事是导入 onnxruntime 库并使用它加载 vit_b_encoder.onnx 模型:
!pip install onnxruntime
import onnxruntime as ort
encoder = ort.InferenceSession("vit_b_encoder.onnx")然后,以 input_tensor 作为输入图像运行模型以生成嵌入:
outputs = encoder.run(None, {"images": input_tensor})
embeddings = outputs[0]
embeddings.shape(1, 256, 64, 64)如果你还记得,在将图像编码器导出到 ONNX 时,我们指定此模型应具有一个名为“images”的输入和一个名为“embeddings”的输出。在这里,我们已将 input_tensor 作为“images”输入传递。ONNX 模型的 run 方法将输出作为数组返回,即使输出是单个的。这就是为什么嵌入位于此数组的第一项中的原因。
太好了,现在我们有了嵌入。这是第一个输入,我们将需要它用于掩码解码器模型。下一个输入是提示,我们也需要准备它。
7、对提示进行编码
提示有助于正确找到所需对象的分割掩码。提示可以是属于对象的单个图像点,也可以是该对象周围的边界框,也可以是多个点。为了对所有这些选项进行编码,Segment Anything 使用类似的算法。让我们从一个点开始:
input_point = np.array([[321,230]])
input_label = np.array([1])在此代码中,我们定义了一个 x=321, y=230 的点。此外,我们还为此点定义了一个标签,即 1。此标签表示该点属于该对象。使用此定义,掩码解码器将尝试找到包含此点的对象的分割掩码。但是,我们需要将此点编码为掩码解码器所需的格式。为此使用下一行代码:
from copy import deepcopy
onnx_coord = np.concatenate([input_point, np.array([[0.0, 0.0]])], axis=0)[None, :, :]
onnx_label = np.concatenate([input_label, np.array([-1])])[None, :].astype(np.float32)
coords = deepcopy(onnx_coord).astype(float)
coords[..., 0] = coords[..., 0] * (resized_width / orig_width)
coords[..., 1] = coords[..., 1] * (resized_height / orig_height)
onnx_coord = coords.astype("float32")
onnx_coordarray([[[537.098 , 384.6265],
[ 0. , 0. ]]], dtype=float32)SAM 掩码解码器需要将输入点缩放为 1024x1024 图像大小,并将其转换为浮点张量。这里我使用图像的 original_width、 original_height、 resized_width 和 resized_height 来缩放坐标。
我不会详细解释此代码的每一行,因为我只是从源代码的 transform.apply_coords 函数中重用了它,并进行了一些修改以使其更简单。这只是掩码解码器模型的要求。
如果你需要发送边界框作为提示,则可以使用类似的代码:
input_box = np.array([132, 157, 256, 325]).reshape(2,2)
input_labels = np.array([2,3])
onnx_coord = input_box[None, :, :]
onnx_label = input_labels[None, :].astype(np.float32)
coords = deepcopy(onnx_coord).astype(float)
coords[..., 0] = coords[..., 0] * (resized_width / orig_width)
coords[..., 1] = coords[..., 1] * (resized_height / orig_height)
onnx_coord = coords.astype("float32")
onnx_coordarray([[[220.86275, 262.5494 ],
[428.33987, 543.49396]]], dtype=float32)此代码用于对提示进行编码,以获取位于框内的对象的掩码,该框的左上角位于 x=132,y=157,右下角位于 x=256,y=325。
如果想要对包含边界框和点的提示进行编码,则可以使用以下代码:
input_box = np.array([132, 157, 256, 325]).reshape(2,2)
box_labels = np.array([2,3])
input_point = np.array([[140, 160]])
input_label = np.array([0])
onnx_coord = np.concatenate([input_point, input_box], axis=0)[None, :, :]
onnx_label = np.concatenate([input_label, box_labels], axis=0)[None, :].astype(np.float32)
coords = deepcopy(onnx_coord).astype(float)
coords[..., 0] = coords[..., 0] * (resized_width / orig_width)
coords[..., 1] = coords[..., 1] * (resized_height / orig_height)
onnx_coord = coords.astype("float32")
onnx_coord此代码包括 input_box 和 input_point 以及它们的标签。请注意,此处的 input_label 包含 0,这意味着点 (140,160) 不属于你要提取的对象。此提示将引导模型分割位于 (132,157,256,325) 框内但不在 (140,160) 点中的对象。
你可以构建非常具体的提示来获得所需的结果(就像使用 ChatGPT 一样 )。
所以,现在我们已经正确编码了 onnx_coord 和 onnx_label 以传递给掩码解码器。我们现在就开始吧。
8、运行掩码解码器
现在,当我们有了嵌入 onnx_coord 和 onnx_label 时,没有什么可以阻止我们运行掩码解码器模型来获取分割掩码。
让我们先加载模型:
decoder = ort.InferenceSession("vit_b_decoder.onnx")并将所有编码数据传递给它:
onnx_mask_input = np.zeros((1, 1, 256, 256), dtype=np.float32)
onnx_has_mask_input = np.zeros(1, dtype=np.float32)
outputs = decoder.run(None,{
"image_embeddings": embeddings,
"point_coords": onnx_coord,
"point_labels": onnx_label,
"mask_input": onnx_mask_input,
"has_mask_input": onnx_has_mask_input,
"orig_im_size": np.array([orig_height, orig_width], dtype=np.float32)
})
masks = outputs[0]
masks.shape(1, 1, 415, 612)此代码使用编码的 image_embeddings、 point_coords 和 point_labels 运行模型。此外,我为 mask_input 和 has_mask_input 提供了虚拟掩码,并为 orig_im_size 参数提供了原始图像大小。
该模型返回 3 个输出,分割掩码数组是其中的第一个。对于输入图像,它返回 (1, 415, 612) 形状的张量,这是一个单通道分割掩码。
剩下的唯一步骤是对其进行后处理。
9、后处理和可视化分割掩码
分割掩码是一个像素数组,但是,每个像素不包含颜色,而是包含一些数字。如果这个数字大于 0,则该像素属于对象,否则不属于对象。因此,要将其转换为真实像素颜色,你可以运行以下代码:
mask = masks[0][0]
mask = (mask > 0).astype('uint8')*255此代码从掩码 (415x612) 中提取像素矩阵,将所有正值转换为 True,将所有负值转换为 False。然后它将所有数字转换为 8 位整数。此后,所有 True 值变为 1,所有 False 值变为 0。然后,我将矩阵乘以 255,将所有 True 像素转换为白色。最后,我们将得到一个单通道黑白图像,可以通过许多图像库轻松可视化。例如,可以使用 Pillow 以这种方式对其进行可视化:
img = Image.fromarray(mask,'L')
img
万岁!现在我们可以仅使用 ONNX 进行 Segment Anything 图像分割。
这是我们旅程的结束。你可以在存储库中的 sam_onnx_inference.ipynb 笔记本中找到本节的所有源代码。
10、结束语
在本文中,我展示了如何填补 Segment Anything 模型的 ONNX 导出功能官方实现中的空白。然后,我们学习如何使用导出的 ONNX 模型进行基于提示的图像分割。
你可以在此存储库中找到所有源代码。
在这里我只使用了 Python,但现在,有了完整的 ONNX 模型,你可以做更多的事情。你可以在 ONNX 运行时支持的任何编程语言上运行 Segment Anything 模型。如果你知道如何预处理输入和后处理输出的算法,则可以将此模型集成到用任何编程语言编写的大多数生产系统中。例如,你可以将其嵌入到用 C/C++、Go 或 Rust 编写的软件中,或用 JavaScript 编写的网站中。
原文链接:SAM导出完整ONNX - BimAnt