幂等性介绍
幂等是一个数学上的概念 f(n) = 1^ n 无论n为多少 f(n)的值永远为1
在我们的编程中定义为: 无论对某一个资源操作了多少次,其影响都应是相同的。
以SQL为例:
select * from table where id=1。此SQL无论执行多少次,虽然结果有可能出现不同,都不会对数据产生改变,具备幂等性。
insert into table(id,name) values(1,‘heima’)。
此SQL如果id或name有唯一性约束,多次操作只允许插入一条记录,则具备幂等性。如果不是,则不具备幂等性,
多次操作会产生多条数据。
update table set score=100 where id = 1。此SQL
无论执行多少次,对数据产生的影响都是相同的。具备幂等性。
update table set score=50+score where id = 1。
此SQL涉及到了计算,每次操作对数据都会产生影响。不具备幂等性。
delete from table where id = 1。此SQL多次操作,产生的结果相同,具备幂等性
接口幂等
对于幂等的考虑,主要解决两点前后端交互与服务间交互。这两点有时都要考虑幂等性的实现。从前端的思路解决的话,主要有三种:前端防重、PRG模式、Token机制
前端防重
通过前端防重保证幂等是最简单的实现方式,前端相关属性和JS代码即可完成设置。可靠性并不好,有经验的人员可以通过工具跳过页面仍能重复提交。主要适用于表单重复提交或按钮重复点击。
PRG模式
PRG模式即POST-REDIRECT-GET。当用户进行表单提交时,会重定向到另外一个提交成功页面,而不是停留在原先的表单页面。这样就避免了用户刷新导致重复提交。同时防止了通过浏览器按钮前进/后退导致表单重复提交。是一种比较常见的前端防重策略。
token机制
通过token机制来保证幂等是一种非常常见的解决方案,同时也适合绝大部分场景。该方案需要前后端进行一定程度的交互来完成。
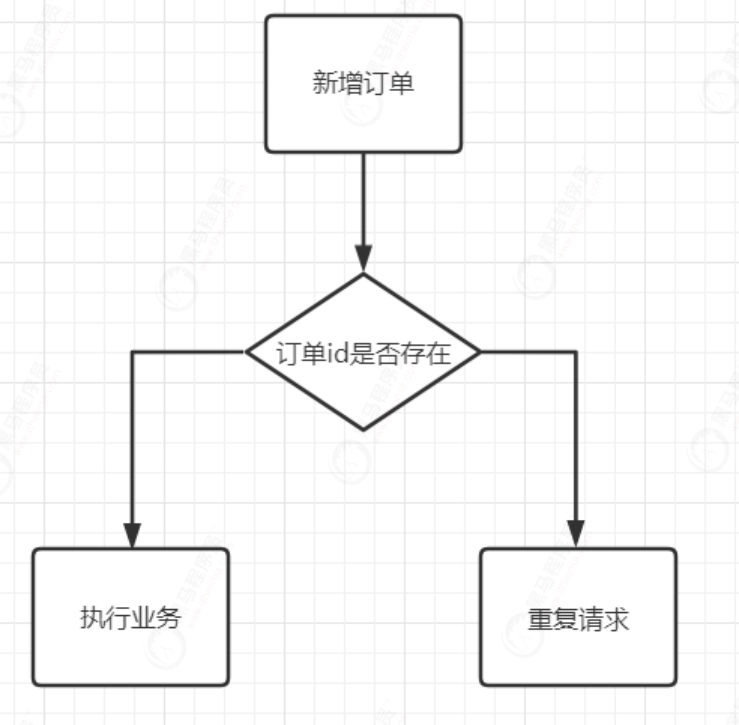
流程图
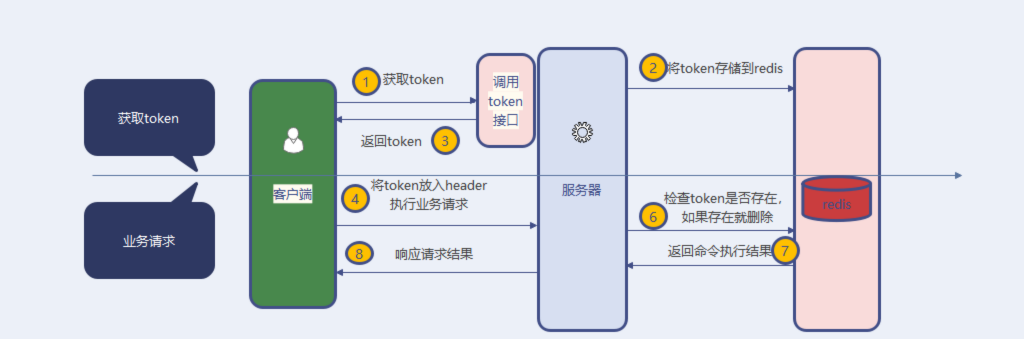
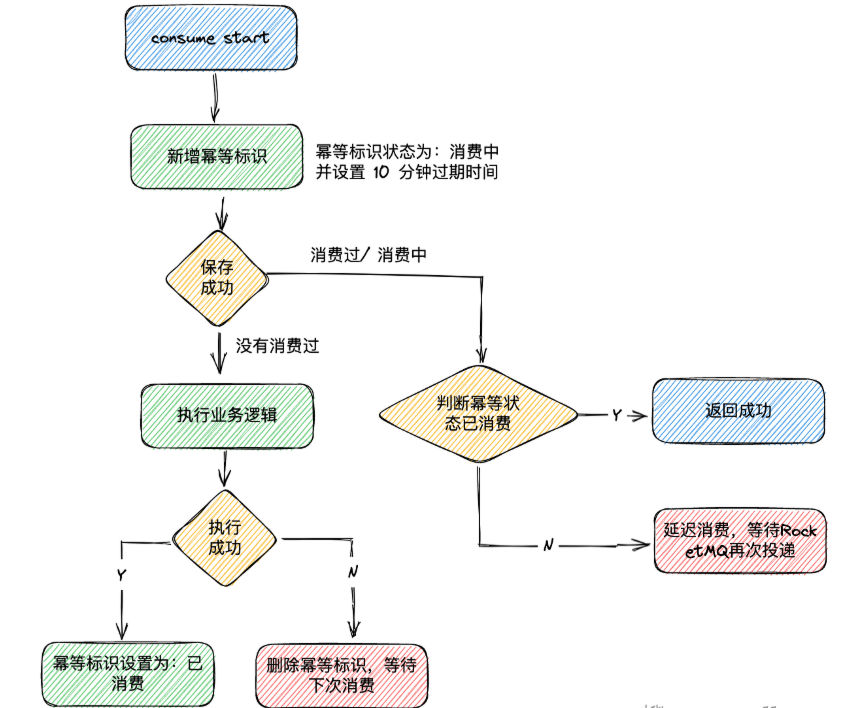
1)服务端提供获取token接口,供客户端进行使用。服务端生成token后,如果当前为分布式架构,将token存放于redis中,如果是单体架构,可以保存在jvm缓存中。
2)当客户端获取到token后,会携带着token发起请求。
3)服务端接收到客户端请求后,首先会判断该token在redis中是否存在。如果存在,则完成进行业务处理,业务处理完成后,再删除token。如果不存在,代表当前请求是重复请求,直接向客户端返回对应标识。
先执行业务再删除token带来的问题
但是现在有一个问题,当前是先执行业务再删除token。在高并发下,很有可能出现第一次访问时token存在,完成具体业务操作。但在还没有删除token时,客户端又携带token发起请求,此时,因为token还存在,第二次请求也会验证通过,执行具体业务操作。
解决办法
对于这个问题的解决方案的思想就是并行变串行。会造成一定性能损耗与吞吐量降低。
第一种方案:对于业务代码执行和删除token整体加线程锁。当后续线程再来访问时,则阻塞排队。
第二种方案:借助redis单线程和incr是原子性的特点。当第一次获取token时,以token作为key,对其进行自增。然后将token进行返回,当客户端携带token访问执行业务代码时,对于判断token是否存在不用删除,而是对其继续incr。如果incr后的返回值为2。则是一个合法请求允许执行,如果是其他值,则代表是非法请求,直接返回。
那如果先删除token再执行业务呢?其实也会存在问题,假设具体业务代码执行超时或失败,没有向客户端返回明确结果,那客户端就很有可能会进行重试,但此时之前的token已经被删除了,则会被认为是重复请求,不再进行业务处理。
这种方案无需进行额外处理,一个token只能代表一次请求。一旦业务执行出现异常,则让客户端重新获取令牌,重新发起一次访问即可。推荐使用先删除token方案
但是无论先删token还是后删token,都会有一个相同的问题。每次业务请求都回产生一个额外的请求去获取token。但是,业务失败或超时,在生产环境下,一万个里最多也就十个左右会失败,那为了这十来个请求,让其他九千九百多个请求都产生额外请求,就有一些得不偿失了。虽然redis性能好,但是这也是一种资源的浪费
服务幂等
防重表
对于防止数据重复提交,还有一种解决方案就是通过防重表实现。防重表的实现思路也非常简单。首先创建一张表作为防重表,同时在该表中建立一个或多个字段的唯一索引作为防重字段,用于保证并发情况下,数据只有一条。在向业务表中插入数据之前先向防重表插入,如果插入失败则表示是重复数据。
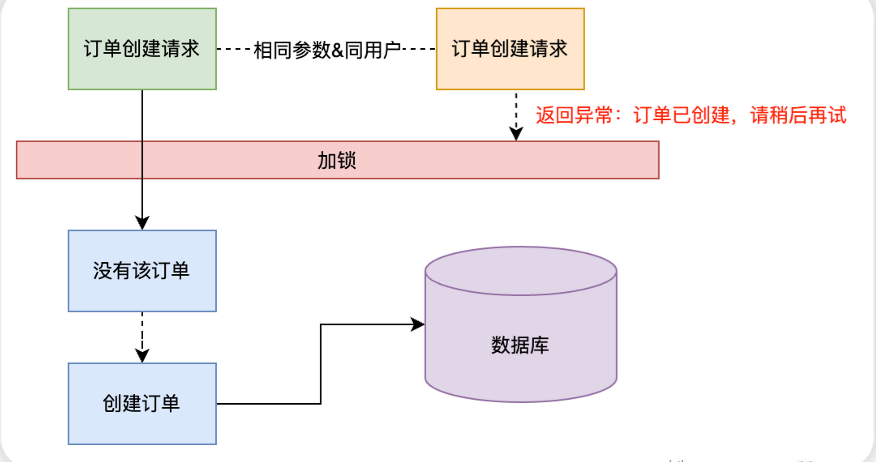
select+insert防重提交
对于一些后台系统,并发量并不高的情况下,对于幂等的实现非常简单,通过select+insert思想即可完成幂等控制。在业务执行前,先判断是否已经操作过,如果没有则执行,否则判断为重复操作。
Mysql乐观锁
版本号
基于条件
通过版本号控制是一种非常常见的方式,适合于大多数场景。但现在库存扣减的场景来说,通过版本号控制就是多人并发访问购买时,查询时显示可以购买,但最终只有一个人能成功,这也是不可以的。其实最终只要商品库存不发生超卖就可以。那此时就可以通过条件来进行控制。
Redis分布式锁
单节点的Redis实现分布式锁
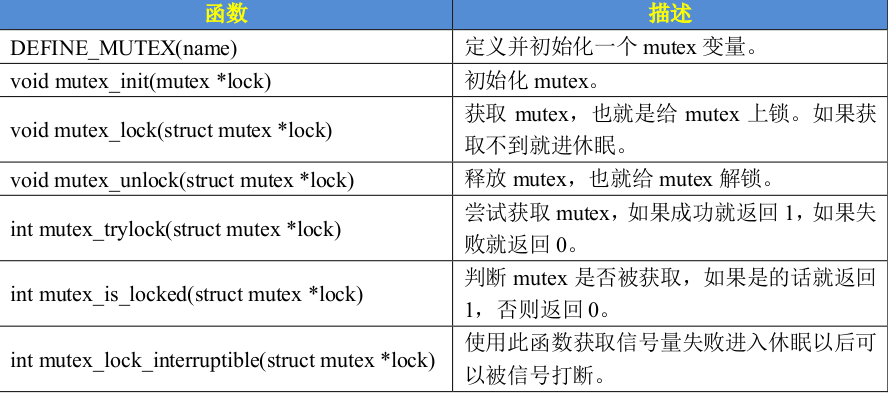
redis实现分布式锁也很简单,基于客户端的几个API就可以完成,主要涉及三个核心API:
setNx():向redis中存key-value,只有当key不存在时才会设置成功,否则返回0。用于体现互斥性。
expire():设置key的过期时间,用于避免死锁出现。
delete():删除key,用于释放锁。
但是也带来一个问题
锁误删
解锁时,要避免当前线程将别人的锁释放掉。假设线程A加锁成功,当过了一段时间线程A来解锁,但线程A的锁已经过期了,在这个时间节点,线程B也来加锁,因为线程A的锁已经过期,所以线程B时可以加锁成功的。此时,就会出现问题,线程A将线程B的锁给释放了。对于这个问题,就需要使用到加锁时的requestId。当解锁时要判断当前锁键的value与传入的value是否相同,相同的话,则代表是同一个人,可以解锁。否则不能解锁。
锁续期
当对业务进行加锁时,锁的过期时间,绝对不能想当然的设置一个值。假设线程A在执行某个业务时加锁成功并设置锁过期时间。但该业务执行时间过长,业务的执行时间超过了锁过期时间,那么在业务还没执行完时,锁就自动释放了。接着后续线程就可以获取到锁,又来执行该业务。就会造成线程A还没执行完,后续线程又来执行,导致同一个业务逻辑被重复执行。因此对于锁的超时时间,需要结合着业务执行时间来判断,让锁的过期时间大于业务执行时间。上面的方案是一个基础解决方案,但是仍然是有问题的。业务执行时间的影响因素太多了,无法确定一个准确值,只能是一个估值。无法百分百保证业务执行期间,锁只能被一个线程占有。如想保证的话,可以在创建锁的同时创建一个守护线程,同时定义一个定时任务每隔一段时间去为未释放的锁增加过期时间。当业务执行完,释放锁后,再关闭守护线程。 这种实现思想可以用来解决锁续期
服务单点 集群问题
在单点redis虽然可以完成锁操作,可一旦redis服务节点挂掉了,则无法提供锁操作。在生产环境下,为了保证redis高可用,会采用异步复制方法进行主从部署。当主节点写入数据成功,会异步的将数据复制给从节点,并且当主节点宕机,从节点会被提升为主节点继续工作。假设主节点写入数据成功,在没有将数据复制给从节点时,主节点宕机。则会造成提升为主节点的从节点中是没有锁信息的,其他线程则又可以继续加锁,导致互斥失效
单机Redisson实现分布式锁
基于redisson实现分布式锁很简单,直接基于lock()&unlock()方法操作即可
锁续期之看门狗
所谓的看门狗是redisson用于自动延长锁有效期的实现机制。其本质是一个后台线程,用于不断延长锁key的生存时
间
要开启看门狗机制也很简单,只需要将加锁时使用lock()改为
tryLock()即可。
红锁
当在单点redis中实现redis锁时,一旦redis服务器宕机,则无法进行锁操作。因此会考虑将redis配置为主从结构,但在主从结构中,数据复制是异步实现的。假设在主从结构中,master会异步将数据复制到slave中,一旦某个线程持有了锁,在还没有将数据复制到slave时,master宕机。则slave会被提升为master,但被提升为slave的master中并没有之前线程的锁信息,那么其他线程则又可以重新加锁
消息幂等
在系统中当使用消息队列时,无论做哪种技术选型,有很多问题是无论如何也不能忽视的,如:消息必达、消息幂等等。
消息队列的消息幂等性,主要是由MQ重试机制弓I起的。因为消息生产者将消息发送到MQ-Server后,MQ-Server会将消息推送到具体的消息消费者。假设由于网络抖动或出现异常时,MQ-Server根据重试机制就会将消息重新向消息消费者推送,造成消息消费者多次收到相同消息,造成数据不一致。
消息防重表
解决思路与服务间幂等的防重表一致
redis