词向量及知识库介绍
1.词向量
1.1 什么是词向量
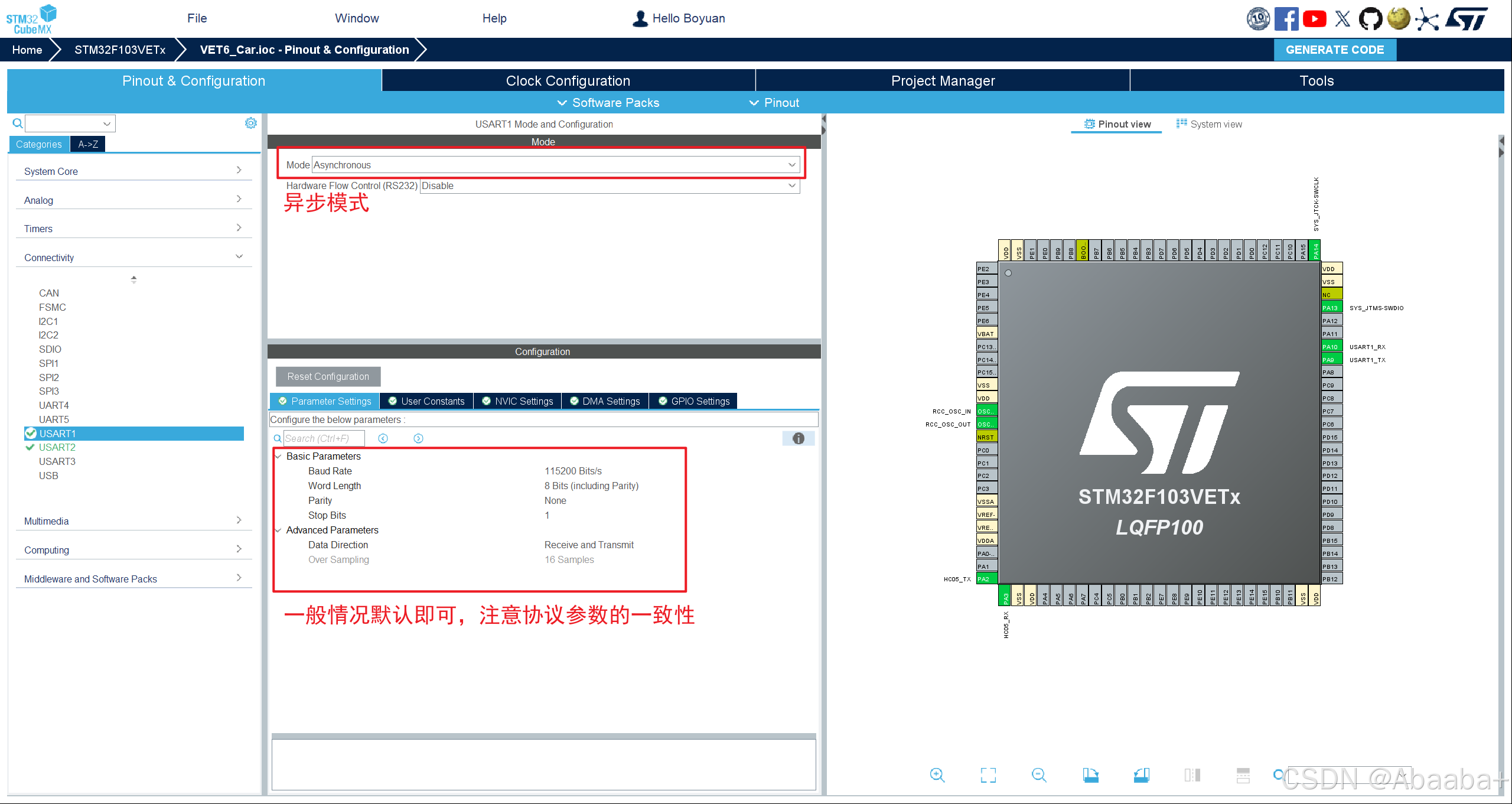
词向量是一种将单词表示为实数向量的方式。每个单词通过一个高维向量来表示,向量的每一维都是一个实数,这些向量通常位于一个高维空间中。词向量的目标是将语义相似的单词映射到相邻的向量空间中,即距离越近的向量表示的单词之间的语义相似度越高。

在机器学习和自然语言处理(NLP)中,词向量(Embeddings)是一种将非结构化数据,如单词、句子或者整个文档,转化为实数向量的技术。这些实数向量可以被计算机更好地理解和处理。
嵌入背后的主要想法是,相似或相关的对象在嵌入空间中的距离应该很近。

举个例子,我们可以使用词嵌入(word embeddings)来表示文本数据。在词嵌入中,每个单词被转换为一个向量,这个向量捕获了这个单词的语义信息。例如,“king” 和 “queen” 这两个单词在嵌入空间中的位置将会非常接近,因为它们的含义相似。而 “apple” 和 “orange” 也会很接近,因为它们都是水果。而 “king” 和 “apple” 这两个单词在嵌入空间中的距离就会比较远,因为它们的含义不同。
1.2 词向量的优势
词向量的优势在于其强大的语义表示能力、处理稀疏性问题的能力、支持语义类推、扩展到更高层次文本表示的灵活性、跨语言和跨模态的应用潜力,以及高效的计算与存储方式。这些优势使得词向量成为现代 NLP 系统中不可或缺的基础技术。
1. 语义表示能力
词向量通过将词语嵌入到一个高维向量空间中,可以有效捕捉词语之间的语义关系。相比于传统的词袋模型(Bag of Words)或 TF-IDF 方法,词向量能够反映词与词之间的语义相似度。这意味着相似的词语在向量空间中距离更近,而意义不同的词语则距离更远。通过这种语义表示,模型可以更好地理解和处理语言中的复杂关系。
2. 处理词汇稀疏性
传统的方法通常会面临词汇稀疏性的问题,即在处理大规模文本数据时,很多词语可能只出现一次或很少几次,导致模型难以学习有用的模式。词向量通过将语义相似的词映射到相似的向量,可以在一定程度上缓解这一问题,使得模型在遇到稀有词语时仍能利用与其语义相近的其他词的向量信息进行推理。
3. 支持语义类推
词向量具备语义类推能力,可以解决类推任务,例如:向量("国王") - 向量("男人") + 向量("女人") ≈ 向量("女王")。这表明词向量不仅可以捕捉单词之间的语义相似性,还可以捕捉它们之间的关系。这种能力在很多 NLP 任务中(如问答系统、推理任务等)都非常有用。
4. 扩展到句子和文档级别的表示
虽然词向量最初是用于表示单词的,但它们也可以扩展用于表示句子、段落甚至整个文档。这种扩展通常通过将词向量进行组合(如平均、加权求和、或者通过更复杂的模型如 Transformer 等)来实现。这使得词向量能够广泛应用于文本分类、摘要生成等更高层次的 NLP 任务中。
5. 跨语言和跨模态的应用
词向量还具有跨语言和跨模态的应用潜力。通过对不同语言或不同模态(如图像、声音)的数据进行向量化,可以将不同类型的数据统一到同一个向量空间中,从而实现跨语言、跨模态的理解和处理。这对于构建多语言模型或集成多种数据类型的系统具有重要意义。
6. 高效的计算和存储
词向量可以通过预训练模型生成,并且一旦生成,可以在后续的计算中重复使用。这种方法不仅提高了计算效率,还减少了对存储的要求,因为每个词仅需存储一个向量。与传统的 NLP 方法相比,词向量的方法更具计算和存储上的优势,尤其在处理大规模数据时。
1.2 如何生成词向量
词向量通常通过训练模型生成,模型会学习如何将词语嵌入到一个向量空间中,使得相似词语之间的距离尽可能地近。两种常用的方法是Word2Vec 和 GloVe:
- Word2Vec: 这是一种基于神经网络的模型,通常有两种变体:Skip-Gram 和 CBOW(Continuous Bag of Words)。Skip-Gram 通过给定一个词来预测上下文中的词语,而 CBOW 则是给定上下文词语来预测目标词。
- GloVe: 这是一种基于矩阵分解的方法,通过全局统计信息(如词共现矩阵)来学习词向量。它旨在使得词向量能够同时捕捉局部和全局的词语关系。
1.3 词向量的作用
词向量有几个重要的作用:
- 语义相似度: 词向量能够捕捉到词语之间的语义相似度。例如,“国王”(king)和“女王”(queen)的向量距离会比“国王”和“车”(car)的向量距离近。
- 词类推: 词向量还支持词类推任务,如
向量(king) - 向量(man) + 向量(woman) ≈ 向量(queen),这表明词向量能够捕捉到词之间的关系。 - 下游任务的特征输入: 词向量可以作为各种 NLP 任务(如情感分析、机器翻译、命名实体识别等)的输入特征。
1.4 词向量的应用
词向量广泛应用于各种 NLP 任务中,例如:
- 文本分类: 通过词向量对文本进行特征表示,进而分类。
- 机器翻译: 词向量在跨语言中映射相似概念,提高翻译质量。
- 问答系统: 通过词向量理解用户的问题,并检索相关
2.向量数据库
向量数据库是为了应对现代数据需求而设计的数据库系统,特别适用于需要处理高维数据和执行相似性搜索的场景。它们在大规模数据管理、实时性和可扩展性方面表现出色,广泛应用于推荐系统、图像检索、NLP 等领域。
2.1 什么是向量数据库
- 向量数据库是一种专门设计用于存储、管理和查询高维向量数据的数据库系统。与传统关系型数据库不同,向量数据库主要处理的是以向量形式表示的数据,例如通过词向量、图像特征向量、用户行为嵌入等形式存在的高维度数据。
- 向量数据库是用于高效计算和管理大量向量数据的解决方案。
- 向量数据库是一种专门用于存储和检索向量数据(embedding)的数据库系统。它与传统的基于关系模型的数据库不同,它主要关注的是向量数据的特性和相似性。
- 在向量数据库中,数据被表示为向量形式,每个向量代表一个数据项。这些向量可以是数字、文本、图像或其他类型的数据。向量数据库使用高效的索引和查询算法来加速向量数据的存储和检索过程。
2.2 向量数据库的关键特点
-
高维数据管理:向量数据库能够高效地存储和管理数百万甚至数十亿的高维向量数据。这些向量通常来自机器学习或深度学习模型的嵌入层,用于表示文本、图像、音频或其他复杂数据。
-
相似性搜索:向量数据库的核心功能是执行相似性搜索,即在数据库中找到与查询向量最相似的向量。这通常通过计算向量之间的距离(如欧几里得距离、余弦相似度等)来实现。
-
可扩展性:向量数据库通常被设计成能够处理非常大规模的数据集,支持水平扩展,以满足大数据应用的需求。
-
实时性:一些向量数据库支持实时的数据插入和查询,使得它们非常适合用于需要实时响应的应用场景,如推荐系统、在线搜索、个性化服务等。
2.3 向量数据库的应用场景
-
推荐系统:通过存储用户行为的向量表示,可以快速查找与用户当前行为最相似的其他用户或产品,从而实现个性化推荐。
-
图像检索:将图像特征表示为向量,通过向量数据库查找与查询图像最相似的图像,实现快速的图像搜索和分类。
-
自然语言处理:词向量和句子向量在向量数据库中存储后,可以用于相似文本检索、语义搜索、问答系统等应用。
-
生物信息学:在基因序列或蛋白质结构的向量化表示中,向量数据库可以用来查找相似的基因序列或蛋白质结构,辅助科学研究。
2.4 原理及核心优势
向量数据库中的数据以向量作为基本单位,对向量进行存储、处理及检索。向量数据库通过计算与目标向量的余弦距离、点积等获取与目标向量的相似度。当处理大量甚至海量的向量数据时,向量数据库索引和查询算法的效率明显高于传统数据库。
2.5 主流的向量数据库
- Chroma:适合初学者、小型项目,轻量、简单但功能有限。
- Weaviate:功能丰富,适合复杂的搜索需求,尤其是混合搜索和 MMR 搜索。
- Qdrant:高性能、高并发,支持多种部署模式,适合需要强大检索能力的大规模应用场景。
1. Chroma
Chroma 是一个轻量级向量数据库,拥有丰富的功能和简单的 API,适合初学者使用。其主要特点如下:
- 简单易用:Chroma 以简单的设计和轻量的实现为核心,方便用户快速上手。
- 轻量化:数据库体积较小,功能相对简单,适合用于小型项目。
- 无 GPU 加速:由于不支持 GPU 加速,Chroma 处理大规模数据时的性能可能有限。
适用于入门级用户和对复杂性能要求较低的应用场景。
2. Weaviate
Weaviate 是一个开源的向量数据库,支持复杂查询功能,具有以下特点:
- 相似度搜索:支持基于向量的相似度搜索,可快速找到相似项。
- MMR 搜索:最大边际相关性(MMR)搜索功能能够提高结果的多样性和相关性。
- 混合搜索:支持结合词法搜索和向量搜索的混合模式,提升搜索的准确性。
Weaviate 适合需要结合多种搜索方法的复杂场景,如文本、图像或其他高维数据的精确检索。
3. Qdrant
Qdrant 使用 Rust 语言开发,以高性能和高并发著称,其主要特点包括:
- 高检索效率:Qdrant 在高并发的情况下仍然具有很高的请求处理速度(RPS)。
- 灵活部署:支持本地运行、本地服务器部署和云端 Qdrant 服务,灵活满足不同的部署需求。
- 数据复用:通过为页面内容和元数据制定不同的键,支持多种查询任务的数据复用,提高系统灵活性。
Qdrant 适合需要高性能、低延迟和高扩展性的场景,尤其是大规模向量数据的实时处理。
参考
https://datawhalechina.github.io/llm-universe/#/C3/1.词向量及向量知识库介绍