随着ChatGPT等大模型(Large Language Model)的爆火,而且目前业界已经发现只有当模型的参数量达到100亿规模以上时,才能出现一些在小模型无法得到的涌现能力,比如 in_context learing 和 chain of thougt。深度学习似乎朝着模型越来越大的方向一去不复。
而对于这些通用的大模型如何进行 任务微调呢,或者想增加大模型某方面的能力,会遇到很多的问题。
(1)对于动则百亿级别的参数,如何更高效,低资源的微调大模型呢
(2)当样本量很小的时候,如何微调大模型能得到较好的效果呢
等等等等,为解决上面大模型微调的一些问题,学术界提出了很多方法,下面我介绍huggface 开源的一个高效微调大模型的库PEFT里面实现的四种方法(这里笔者的介绍只基于文本分类任务微调),主要是针对transformer 架构的大模型进行微调,当然repo中有对diffusion模型进行微调的案例。

PEFT
LORA
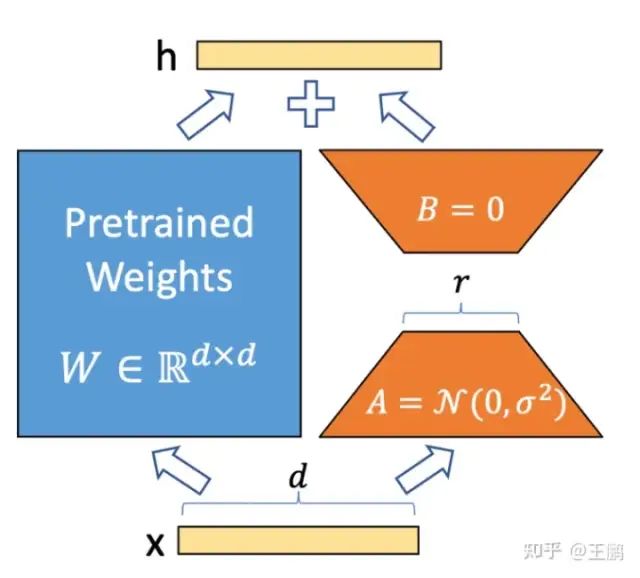
LORA算法是在 每层 transfomer block 旁边引入一个并行低秩的支路,支路的输入是transfomer block 的输入,
然后将输出和 transfomer block 的输出相加,在固定主pretrian model参数的情况下,用支路去学习特定任务知识,来完成特定任务。同时lora现在已经在stable diffusion 图像个性化定制风格和实例这个领域得到了很好的应用,不用动原模型的参数,就可以为ai作画师注入新的知识。
LORA
lora 微调需要设置两个参数一个是r,即中间层神经元的个数。alpha是一个scale参数。
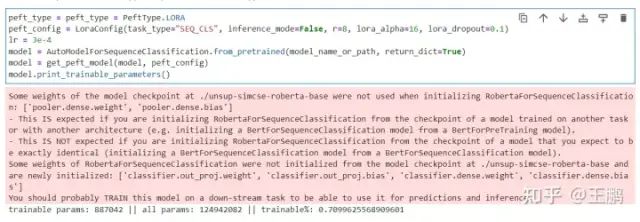
model_name_or_path = "./unsup-simcse-roberta-base"
peft_type = peft_type = PeftType.LORA
peft_config = LoraConfig(task_type="SEQ_CLS", inference_mode=False, r=8, lora_alpha=16, lora_dropout=0.1)
lr = 3e-4
model = AutoModelForSequenceClassification.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
LORA
PREFIX_TUNING
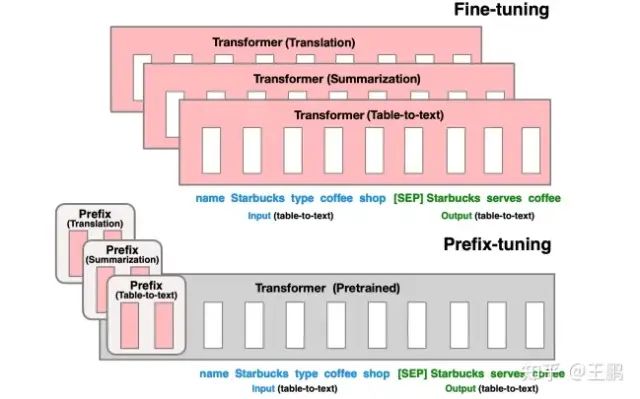
PREFIX_TUNING算法是根据 下游任务 “前缀指令文本” 的所有层的embeding表示,学习到的前缀指令文本向量可以挖掘大模型的潜力去引导模型完成特定任务。
PREFIX_TUNING
PREFIX_TUNING 微调需要设置一个参数,即 指令文本的长度 num_virtual_tokens,研究表明这个数量一般设置在10-20之间。
model_name_or_path = "./unsup-simcse-roberta-base"
peft_type = PeftType.PREFIX_TUNING
peft_config = PrefixTuningConfig(task_type="SEQ_CLS", num_virtual_tokens=20)
lr = 1e-2
model = AutoModelForSequenceClassification.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
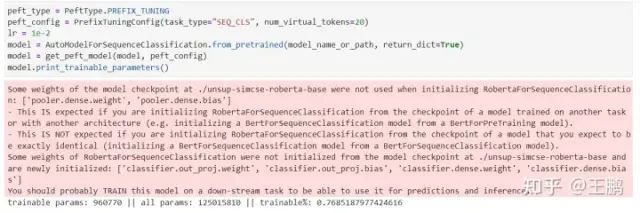
PREFIX_TUNING
P_TUNING
P_TUNING算法和PREFIX_TUNING的想法很相似,想通过微调"指令文本",让指令文本去挖掘大模型的潜力去完成特定的任务。但是P tuning 只学习 “指令文本” 输入层embeding的的表示。为了增强 "指令文本"的连续性,采用了一个 MLP(LSTM) 的结果去encoding “指令文本”。从微调参数量来看只有 0.65% 比 PREFIX_TUNING 和LORA 这些在所有层都增加参数的方法要少。需要提醒的是这里的指令文本是伪文本,可能就是 unused1, unused2…等,目前源代码里面就是随机初始化的一个embeding.
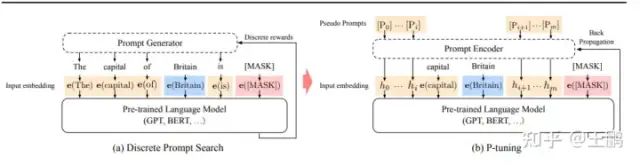
P_TUNING

P_TUNING微调需要设置2个参数,一个是MLP中间层的参数encoder_hidden_size,第二个依然是 指令文本的长度 num_virtual_tokens。
model_name_or_path = "./unsup-simcse-roberta-base"
peft_type = PeftType.P_TUNING
peft_config = PromptEncoderConfig(task_type="SEQ_CLS", num_virtual_tokens=20, encoder_hidden_size=128)
lr = 1e-3
model = AutoModelForSequenceClassification.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()

P_TUNING
PROMPT_TUNING
PROMPT_TUNING算法和P_TUNING很像,且更简单,就是是根据 下游任务 “指令文本” 输入层embeding的的表示。PROMPT_TUNING没有增加任何的层,直接使用微调指令文本(prompt) 的embeding向量。同时文章提出了目前语言模型微调的最新范式,我感觉这篇的思想和chatgpt指令微调的很像。
就是对不同的任务,我们的输入都是不同的指令(都是自然文本),不同的指令去指导模型完成不同的任务。
摆脱了以前不同的任务需要不同的输入和输出,导致任务之间模型隔离的问题。
从微调参数量来看只有 0.48%,是三种方法中微调参数量最少的一种。并且文章表明随着模型越大,PROMPT_TUNING 的效果几乎能和模型整个微调的效果一样。形成了只是学习一个指令然后去模型中检索某种能力的范式。

PROMPT_TUNING

PROMPT_TUNING
PROMPT_TUNING微调需要设置1个参数, 指令文本的长度 num_virtual_tokens。
model_name_or_path = "./unsup-simcse-roberta-base"
peft_type = PeftType.PROMPT_TUNING
peft_config = PromptTuningConfig(task_type="SEQ_CLS", num_virtual_tokens=20)
lr = 1e-3
model = AutoModelForSequenceClassification.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
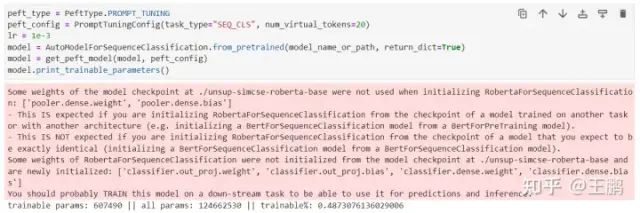
PROMPT_TUNING
结语
从repo的介绍中我们发现直接微调大模型需要耗费大量的计算资源,而直接使用lora 可以在少量GPU的资源情况微调大模型,且能够达到比全量微调差一点的效果,确实很强大。我们可以发现这些PEFT的方法有如下优势。
- 少量的计算资源,就能撬动大模型的微调。就能达到不错的效果
- 同时PROMPT_TUNING 等方法的指令微调方式和预训练任务的训练方式达成了统一,可以在小样本情况小取得不错的成绩
- 采用训练prompt指令,充分挖掘预训练模型潜力的范式也相对来说比较合理
也许未来某一天很多小公司就是采用这些方法去微调一个超大的模型去完成自己的任务。
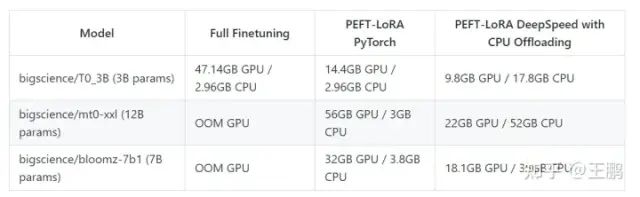
PEFT
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。